
Abstract
Mobile Agent (MA) technology has been recently proposed in Wireless Sensors Networks (WSNs) literature to answer the scalability problem of client/server model in data fusion applications. Herein we present CBID, a novel algorithm that calculates near-optimal routes for MAs that incrementally fuse the data as they visit the Sensor Nodes (SNs) while also enabling fast updates on the designed itineraries upon changes of network topology. CBID dispatches in parallel a number of MAs that sequentially visit sensor nodes arranged in tree structures and upon visiting an SN with two or more child SNs, the MAs (master MAs) clone of themselves with each clone (slave MA) visiting a tree branch. When all slave MAs return to that SN, they deliver their collected data to the master MA and are then disposed of. This results in a significant reduction of the overall energy expenditure and response time. Simulation results prove the high effectiveness of CBID in data fusion tasks compared to other alternative algorithms.
1. Introduction
Wireless Sensor Networks (WSNs) typically comprise hundreds or even thousands of Sensor Nodes (SNs). These SNs are often randomly deployed in a sensor field and form an infrastructureless network. Each SN has the capability to collect data and route it back to a Processing Element (PE) or sink via ad hoc connections, using neighbor nodes as relays. A sensor consists of five basic parts: sensing unit, central processing unit (CPU), storage unit, transceiver unit, and power unit [1].
Unlike other types of networks WSNs are subject to a set of resource constraints such as limited energy availability of SNs [2, 3] since in most cases they are only dependant on battery supply, limited network communication bandwidth and hardware-network heterogeneity. In a typical WSN, SNs are equipped with restricted computational power and limited amount of memory for data-signal processing and task scheduling. Furthermore, as SNs are usually deployed to hostile environments they are prone to failures and the replacement of failed SNs is practically impossible in case of large-scale WSNs or embedded sensors. Given the fact that WSNs can be used in security sensitive applications (e.g., secure area monitoring and target detection [1]) the above-mentioned limitations represent critical challenges.
WSNs can be used in a variety of applications, including environment monitoring, automatic target detection and tracking, battlefield surveillance, remote sensing, and global awareness [1]. Quite a few of the above applications require remote retrieval of sensor readings and are known to be data-intensive. An efficient method to reduce the volume of data communicated within a WSN is data fusion. In data fusion, readings from multiple SNs are combined and processed leading to more accurate data with significant smaller size, since redundant readings for neighbor SNs are filtered [4]. However suitable middleware solutions are required to utilize data fusion in WSNs. In this context, middleware is defined as a software layer, which functions as an interface between sensor nodes and the data fusion logic [5].
Data fusion tasks involve processing and aggregation of data and knowledge from different sources with the aim of maximizing the useful information content [4]. They improve reliability while offering the opportunity to minimize the data retained. Multiple sensor data fusion is an evolving technology, concerning the problem of how to fuse data from multiple sensors in order to make a more accurate estimation of the environment [6]. Applications of data fusion cross a wide spectrum including automated target recognition, guidance and control of autonomous vehicles, medical diagnosis, and smart buildings [7]; they are usually time-critical, cover a large geographical area and require reliable delivery of accurate information for their completion. Most energy-efficient proposals are based on the traditional client/server computing model to handle multisensor data fusion in Wireless Sensor Networks (WSNs) [8–10]; in that model, each sensor sends its sensory data to a back-end processing element (PE) or sink. However, as advances in sensor technology and computer networking allow the deployment of large amount of smaller and cheaper sensors, huge volumes of data need to be processed in real-time giving rise to serious scalability concerns.
Herein we present CBID (Clone-Based Itinerary Design), a novel algorithm that addresses the itinerary optimization problem for MAs that incrementally fuse the data as they visit the WSN nodes. An inviting side-effect of CBID is that it enables a fast update of designed itineraries which is a crucial issue for highly dynamic topologies. For instance, the fast execution of CBID makes it suitable for responding to jamming/interference [11] and also in applications that include tracking and monitoring of moving objects. CBID not only determines the proper number of MAs for minimizing the total data fusion cost but also constructs low-cost itineraries for each of them.
The remainder of the paper is organized as follows. Section 2 introduces the MA computing model and makes a reference to suitability, constraints and application fields of MAs in the context of WSNs. Section 3 reviews works related to our research. Section 4 discusses the design and functionality of our heuristic algorithm for designing near-optimal itineraries for MAs performing data fusion and security tasks in WSNs. Simulation results are presented in Section 5, while Section 6 concludes the paper and suggests future directions for our work.
2. Mobile Agents
MAs represent a relatively recent trend in distributed computing, which address more efficiently the flexibility and scalability problems of centralized models. The term MA [12] refers to an autonomous application program able to move among network nodes and act on behalf of users towards the completion of an assigned task. In addition MAs are able to interact with legacy systems. An MA can be programmed to locally perform data processing and filtering on each SN according to the data it already carries. The fused data are then carried by the MA to the next SN repeating the same procedure (see Figure 1(a)).

Centralized versus Mobile Agents-based data fusion in WSNs.
Recently MAs have been proposed for efficient data dissemination in WSNs [6, 13–15]. In a traditional client/server-based computing scheme, data from multiple nodes is transferred to a processing system (see Figure 1(b)). Due to the bandwidth limitations of contemporary WSNs (e.g., wired networks), the data traffic derived from remote interactions may far exceed the capacity of a WSN. This serious scalability problem may be sufficiently addressed through MAs. The key idea is to delegate multiple MAs to the SNs of a WSN; these MAs can perform local rather than remote interactions with legacy systems, apply intelligent filtering operations thereby eliminating redundancy in the transferred data and decreasing the network overhead associated with data transfer. This approach also implies more reasonable usage of the nodes' radio unit (i.e., their most energy consuming part), hence prolonged network lifetime.
It should be stressed that when MAs are employed for data fusion tasks in WSNs the choice of agents' itineraries (order of visited sensors) is crucial since it considerably affects the overall energy consumption and data fusion cost. Itinerary scheduling can be classified as dynamic, static or hybrid. (A dynamic itinerary is determined on the fly at each hop of the MA while a static itinerary is computed at the PE prior to the MA migration. In a hybrid approach the SNs to be visited are selected by the PE but the visiting order is decided on the fly by the MA. Although improving the optimality of the MA's itinerary compared to hybrid and static approaches, the dynamic approach is more time-expensive (the “find-next-SN” function is executed on each migration step), it consumes valuable sensor nodes energy resources and implies larger MA sizes (the more intelligence integrated within the agent, the larger its size.) The most notable drawback of existing solutions that have been proposed in the literature for determining the routes of the MAs [16–19] is that they rely on a single MA to visit and fuse the data from the entire network. However, this approach is not efficient for large-scale WSNs since the MA accumulates large amounts of data and experiences prolonged response time.
2.1. Suitability, Constraints, and Application Fields of MAs in the Context of WSNs
Lange and Oshima listed seven good reasons to use MAs [20]: reducing network load, overcoming network latency, robust and fault-tolerant performance. The MA-based computing model enables moving the code (processing) to the data rather than transferring raw data to the processing module. By transmitting the computation engine instead of data, this model offers decreased network overhead, distribution of network load, adaptability, stability and autonomy.
Although the role of MAs in distributed computing is still being debated mainly because security concerns [21], several applications have shown clear evidence of benefiting from the use of MAs [22], including e-commerce and m-commerce trading [23], distributed information retrieval [24], network awareness [25], network and systems management [21, 26, 27], and so forth. Network-robust applications are also of great interest in military situations today. MAs are used to monitor and react instantly to the continuously changing network conditions and guarantee successful performance of the application tasks.
MAs have also found a natural fit in the field of distributed sensor networks; hence, a significant amount of research has been dedicated in proposing ways for the efficient usage of MAs in the context of WSNs. In particular, MAs have been proposed for enabling dynamically reconfigurable WSNs through easy development of adaptive and application-specific software for SNs [28], for separating SNs in clusters [29], in multiresolution data integration [14] and fusion [15], data dissemination [16] and location tracking of moving objects [14, 30, 31]. These applications involve the usage of multihop MAs visiting large numbers of SNs.
Security has been identified as the main reason that hinders the adoption of MAs as the next generation distributed computing paradigm. In the context of WSNs, the most crucial security risk in using MAs is the possibility of tampering an agent. The MA's code can be modified while migrating among SNs by a malicious SN. To address this security risk several countermeasures can be utilized to detect any manipulation made by an adversary, for instance Encrypted Functions (EF) [32], Cryptographic Traces [33, 34], Chained MAC protocol [35], Watermarking [36], Fingerprinting [36], Zero-knowledge proofs [37] and the Secure secret sharing scheme [37].
3. Related Work
WSNs pose new challenges due to their scarce bandwidth and energy limitations. To solve the problem of the overwhelming data traffic Qi et al. in [6, 18] proposed the MA-based Distributed Sensor Network (MADSN) for scalable and energy-efficient data aggregation. By transmitting the software code (MA) to sensor nodes, a large amount of sensory data may be filtered at the source by eliminating the redundancy. An MA may visit a number of sensors and progressively fuse retrieved sensory data, prior to returning back to the PE to deliver the data. This scheme may be more efficient than traditional client/server model; within the latter model, raw sensory data are transmitted to the PE where data fusion takes place. In [15, 38] the higher performance of the MASDN over the client/server model is demonstrated through both analytical study and simulations. A misconception shared among these studies is that they both assume constant MA size, a nonrealistic assumption since MAs grow larger as they collect data from distributed nodes [39].
Chen et al. proposed the Mobile Agent-Directed Diffusion (MADD) in [17] as an improvement to MA-Based Distributed Sensor Network (MADSN) and Multiresolution Integration (MRI) algorithm. The limitation of clustering in MASDN is addressed by using a flat network architecture, which, as the authors claim, is more suitable for a wide range of WSNs applications compared to cluster-based architectures. Although MADD addressed many constraints of MASDN, it failed to address the poor scalability of the approach wherein a single MA object visits sequentially the SNs for data collection. This renders both algorithms inappropriate for large-scale WSNs wherein the end-to-end delay and the size of the MA would exhibit quadratic growth with the number of visited SNs.
Xu and Qi in [40] study the problem of determining MA itinerary for collaborative processing and models the Dynamic Mobile Agent Planning (DMAP) problem. They present two itinerary planning algorithms, ISMAP and IDMAP. The main drawback of these algorithms is their poor scalability as they both rely on a single MA.
Chen et al. in [16] proposed the Mobile Agent-Based Wireless Sensor Network (MAWSN) architecture for filtering and aggregating data in planar sensor network architectures. In MAWSN according to the authors, MAs are used to: (a) eliminate data redundancy among SNs; (b) eliminate spatial redundancy among neighbor SNs by MA-assisted data aggregation; (c) reduce communication overhead. The authors proved via simulations that MAWSN improved the performance over the client/server model in terms of energy consumption and packet deliver ratio. However, as the authors admit, MAWSN involve longer end-to-end latency under certain conditions due to the fact that only a single MA is employed in MAWSN.
The work presented in [18, 19] is more directly related to the research described herein since they both propose methodologies for optimizing static MA itineraries. Qi and Wang in [18] proposed two heuristics to optimize the itinerary of MAs performing data fusion tasks. In Local Closest First (LCF) algorithm, each MA starts its route from the PE and searches for the next destination with the shortest distance to its current location. In Global Closest First (GCF) algorithm, MAs also start their itinerary from the PE node and select the SN closest to the center of the surveillance region as the next-hop destination.
The output of LCF-like algorithms though highly depends on the MA original location, while the nodes left to be visited last are typically associated with high migration cost [41] the reason for this is that they search for the next destination among the nodes adjacent to the MA's current location, instead of looking at the “global” network distance matrix. On the other hand, GCF produces in most cases messier routes than LCF and repetitive MA oscillations around the region center, resulting in long route paths and unacceptably poor performance [15, 19]. Wu et al. proposed a genetic algorithm-based solution for computing routes for an MA that incrementally fuses the data as it visits the nodes in a WSN [19]. Although providing superior performance (lower cost) than LCF and GCF algorithms, this approach implies a time-expensive optimal itinerary calculation (genetic algorithms typically start their execution with a random solution “vector” which is improved as the execution progresses), which is unacceptable for time-critical applications, for example, in target detection and tracking.
Most importantly, all the approaches proposed in [15–17, 19, 40] involve the use of a single MA object launched from the PE that sequentially visits all sensors, regardless of their physical location on the plane. Their performance is satisfactory for small WSNs; however, it deteriorates as the network size grows and the sensor distributions become more complicated. This is because both the MA's round-trip delay and the overall migration cost increases exponentially with network size, as the traveling MA accumulates into its state data from visited sensors [27, 39]. The growing MA's state size not only results in increased consumption of the limited wireless bandwidth, but also consumes the limited energy supplies of sensor nodes.
To address the above-mentioned problems we have proposed the Near Optimal Itinerary Design (NOID) algorithm in a previous work [42]. This algorithm adapts a method usually applied in network design problems, namely the Esau-Williams (E-W) heuristic [43], in the specific requirements of the MA itinerary optimization problem, suggesting a number of near-optimal MA itineraries that minimize the overall data fusion cost. To keep the energy consumption low NOID recognizes that MAs become “heavier” while visiting SNs without returning back to the PE to deliver the collected data so it restricts the number of migrations performed by individual MAs, thereby promoting the parallel employment of multiple cooperating MAs, each visiting a subset of sensors.
NOID has been shown to perform better than LCF and GCF at the expense of higher algorithmic complexity (i.e., prolonged execution time). Apart from its increased complexity, NOID performs worse than CBID as it does not take advantage of the MAs' cloning capability. Furthermore, CBID follows a more direct approach to the problem of determining low-cost MA itineraries. Specifically, based on an accurate formula for the total energy spending during MA migration, CBID follows a greedy-like approach for distributing SNs in multiple MA itineraries. Essentially CBID determines a spanning forest of trees in the network calculates efficient itineraries and eventually assigns these itineraries to individual MAs. Like NOID, CBID assumes a general aggregation model where data size post aggregation is not necessarily constant. Hence, unlike existing MA heuristics that employ a single MA (i.e., LCF, GCF), CBID pays attention to the fact that the data load of MAs is increasing as they move along their itineraries. To further decrease the data load of the MAs, in CBID data collection starts from the outer leaf nodes of the spanning trees in contrast with NOID where MAs start data collection immediately from the first nodes of the itineraries.
4. The CBID Algorithm
In this section we present CBID, a novel algorithm that determines the number of MAs that should be involved in data fusion tasks as well as their corresponding near-optimal itineraries in WSN environments. CBID's execution comprises three phases. In the first phase a heuristic algorithm is used to separate WSN nodes in tree structures rooted at the PE, depending on the WSN deployment pattern. The second phase builds upon the trees derived during the first phase to design the actual itineraries followed by MAs, exploiting their cloning capability wherever appropriate to achieve extra data fusion cost gains. The third phase is activated in the event of WSN topology changes to enable cost-effective updates of MA itineraries.
The overall cost per polling interval over all itineraries is calculated according to the following cost function:

4.1. Tree Construction Phase
The tree construction phase is completed in two steps. On the first step (initialization) the PE is “connected” with all sensor nodes located within the PE's transmission range (nodes h and e illustrated in Figure 2). These nodes represent the starting point of the corresponding MA itineraries; namely, the number of these nodes equals the number of MA itineraries.

Tree structures derived by CBID.
To dynamically adjust the number of itineraries, we use the parameter
The three basic rules that should be taken into account to establish each connection are as follows: (a) the candidate for attachment SN must not be already attached to another tree; (b) the candidate SN is attached to an in-range SN that provides a connecting path back to the PE; (c) the SN to be connected must keep the itinerary cost to minimum compared to other candidate SNs. The connection cost is calculated in an efficient way, as defined in definition (1) and shown in (2).
Let us now assume a WSN with the PE connected to a tree with 5 nodes (nodes
Definition 1.
The Connection Cost (
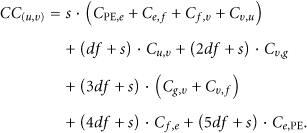
In (2) the individual costs are calculated taking into account only the spatial distance
With the use of (2) we choose the SN pairs to be connected in step 2 among all candidate SNs. On each iteration of the tree construction phase we connect the SN that provides the smallest
4.2. Itinerary Design Phase
The end result of the first phase is a number of trees, all rooted at the PE. The itinerary design uses those tree structures to build cost-effective itineraries assigned to MAs, wherein the nodes of each tree are assigned to an individual MA. Each MA (master MA) starts its itinerary from the PE following its assigned tree structure. When it reaches a “parent” SN with two or more children SNs (e.g., SN k in Figure 3(a)) it clones itself (see Figure 3(b)) with each clone (slave MA) assigned to visit a child SN (tree branch) while the master MA remains on the “parent” SN.

CBID MA cloning and data collection.
When the slave MAs reach the more distant—from the PE—leaf nodes (n and q nodes in Figure 3(c)), they commence data retrieval. On the way back to the route, the slave MAs that return to the “parent” SN deliver their collected data to the master MA and are subsequently self-destroyed (Figure 3(d)). The master MA waits for a fixed time period for the arrival of all slave MAs. If this time period elapses with no return of all slave MAs, it assumes SN failure or communication disconnection and returns back to the PE following the same route (Figure 3(e)). It should be emphasized that the above-described procedure is recursive, that is if a slave MA, on its way to the more distant leaf SN, visits another “parent” SN, it changes its status to master MA and the same process is repeated.
Using the above-mentioned method the overall data fusion cost and response time (MA round trip delay) are considerably reduced. This is because CBID enables the parallel employment of multiple MAs carrying small loads of data instead of a single MA traveling longer distances and growing heavy, especially in the last hops of its itinerary [39].
As an example (3) calculates the total cost of CBID for the itinerary that starts from SN h in Figure 3(a) while (4) calculates the total cost of the same itinerary without utilizing MAs cloning feature. In the latter case the MA performs a postorder tree traversal (i.e., it “visits” the left SN first, then the right SN and then the root:

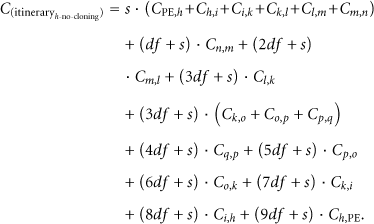
As we can see from (3) (CBID) the cost for traversing and collecting data from nodes

For (4) (without MA cloning) the cost for traversing and collecting data from the same nodes is highly increased since the MA has to carry besides its own data code and the data that has already collected from nodes

It is obvious that in trees with more nodes the increase in cost will be proportional.
4.3. Tree Update Phase
The tree update phase takes effect in the likely event of WSN topology changes (e.g., due to new code deployments, SN failures or interference) to enable cost-effective and low complexity updates of MA itineraries. The PE is assumed to periodically ping all SNs (e.g., broadcast energy status queries) and logs possible topology changes (e.g., not responding nodes or nodes that report low energy level). When an SN is marked as problematic (i.e., SN l in Figure 4(a)) the PE takes immediate action and initiates the tree update phase (in this example for simplicity reasons we assume the failure of only one SN). All the edges starting or ending at the problematic SN are deleted (see Figure 4(b)). Then nodes with limited connectivity (part of cut-off trees) are identified (nodes m and n in Figure 4(b)). All the cut-off trees nodes having in range working nodes are examined (see Figure 4(c)) and the corresponding

Tree update phase of CBID.
Tree update phase is of low complexity compared to the tree construction phase. Hence, it ensures itineraries rescheduling in the face of WSN topology changes.
5. Simulation Results
Simulations have been conducted using a Delphi-based tool [44] and compare the performance of CBID against NOID, LCF and GCF algorithms in terms of the overall itinerary length, data fusion cost and response time. Unless otherwise specified, the parameters used throughout the simulation tests are those shown in Table 1. To measure the overall data fusion cost for all algorithms we used the cost function given in (1) which takes into account the overall number of agent itineraries, the amount of data collected from each node, the MA initial size and the physical distance of wireless links. The simulation results presented herein have been averaged over fifty simulation runs (i.e., fifty different network topologies).
Simulation parameters.

Figure 5 illustrates representative screens of our Delphi-based simulator that draw the output of the four MA-based-distributed data fusion algorithms. The settings used in the simulation illustrated in Figure 5 are those shown in Table 1. The circle in Figure 5(b) denotes the network center. Notably, GCF typically suggests wireless hops among distant sensor nodes which are not within mutual transmission range and, hence, should be routed through intermediate nodes, thereby frequently requiring complex routing decisions and increasing the overall latency and energy consumption. The same usually applies for the last hops of MA itineraries suggested by LCF (which has the smaller total itinerary length).
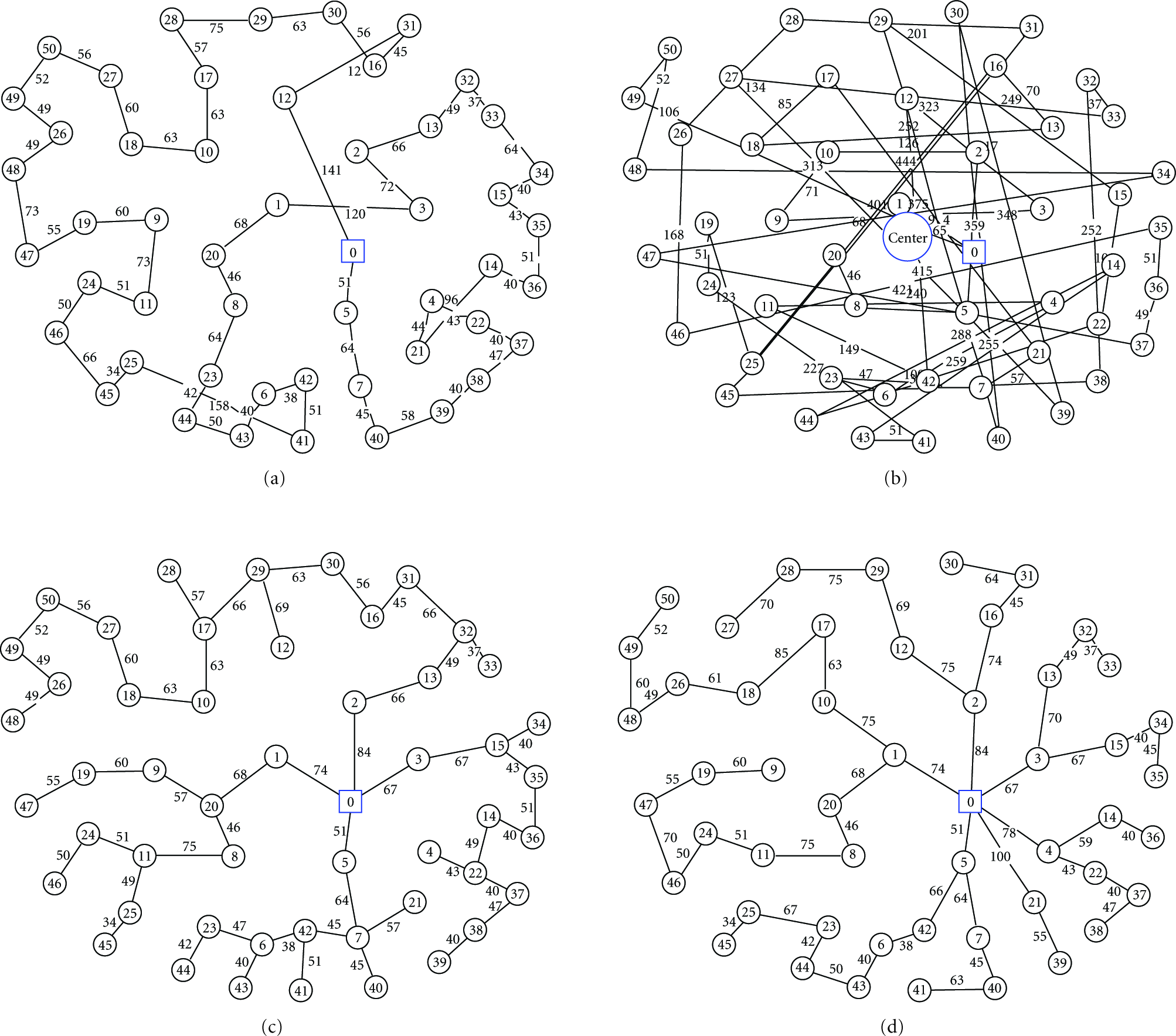
Delphi-based simulation of MA-based-distributed data fusion algorithms: (a) LCF output (total itinerary length: 3079 m; overall cost: 390,600 units; execution time: 770940.42 μs); (b) GCF output (total itinerary length: 8628 m; overall cost: 1,116,786 units; execution time: 784021.74 μs); (c) the trees constructed by NOID (four trees, each assigned to an individual MA; NOID output, where the four trees created on the previous step are traversed in postorder (total itinerary length: 2676 m; overall cost: 445,080 units; execution time: 3597592.61 μs). (d) the trees constructed by CBID (six trees, each assigned to an individual MA; CBID output; where the six trees created on the previous step are traversed in postorder (total itinerary length: 2947 m; overall cost: 600,968 units; execution time: 798335.74 μs).
A first set of simulation experiments compares the performance of LCF, GCF, NOID and CBID algorithms in terms of their total itinerary length. As illustrated in Figure 6(a) (drawn on logarithmic scale), CBID and NOID have the smaller itinerary length, followed by LCF. GCF derives far the longer itinerary because it suggests wireless hops among distant sensor nodes. Figure 6(b) shows that

Delphi-based simulation of MA-based-distributed data fusion algorithms: (a) total itinerary length of LCF, GCF, NOID and CBID, (b) total itinerary length of NOID and CBID (
Figure 7(a) (drawn on logarithmic scale) compares LCF, GCF, NOID and CBID algorithm in terms of their respective overall data fusion cost. GCF is shown to result in the higher overall cost, followed by LCF. NOID performs better than LCF and GCF, while CBID is shown to provide significantly lower data fusion cost than NOID as: (a) agent itineraries are designed paying “respect” to the tree structures (i.e., MAs migrations follow the tree edges, unlike NOID which designs similar tree structures but then constructs agent routes that correspond to a postorder traversal of these trees), (b) NOID fails to exploit the cloning capability of MAs; on the contrary, CBID enables agent cloning whenever this can reduce the fusion cost.
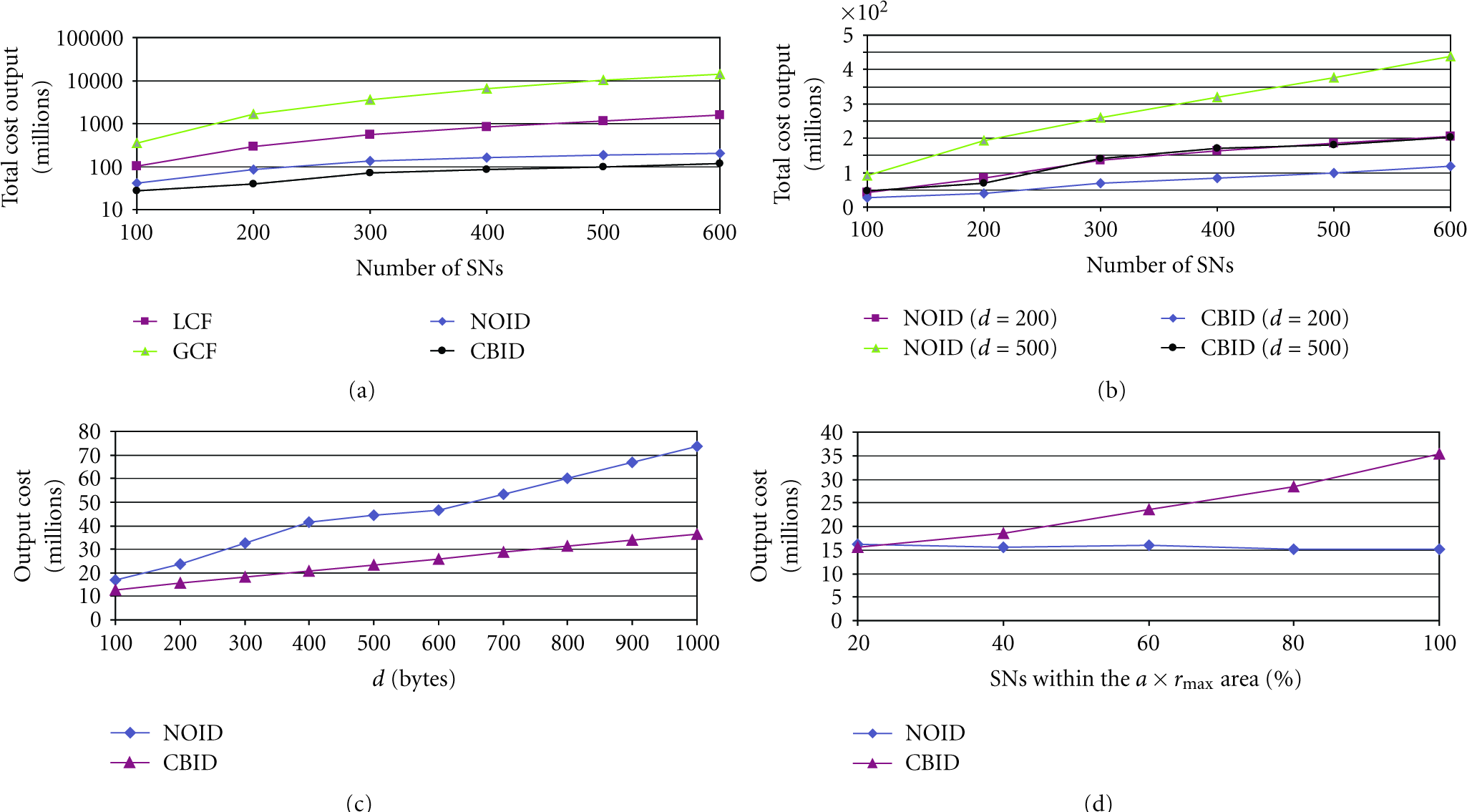
Comparison of LCF, GCF, NOID and CBID in data fusion cost for (a)
In Figure 7(b) we compare NOID and CBID for
Finally, Figure 7(d) compares the total cost output of CBID and NOID with variable number of nodes within the PE's range (we set
A last set of experiments evaluates the overall response time of LCF, GCF, NOID and CBID algorithms for completing data fusion tasks. Response time is calculated as the sum of MAs instantiation delay, processing delay, MAs transmission delay and propagation delay:
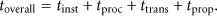
The MAs instantiation delay is related to the number of MAs involved in the data fusion task (in our experiments we assume 10 msec to instantiate each MA object). Hence, it is constant for LCF and GCF algorithms that always instantiate a single MA that visits the whole set of SNs, while for NOID it depends on the network scale and the
Response time measurements are depicted in Figures 8(a) and 8(b). In both graphs, the response times of LCF and GCF almost coincide: LCF only involves slightly decreased propagation delay compared to GCF since it derives shorter itinerary lengths (see Figure 6(a)). It is demonstrated that as the

Comparison of LCF, GCF, NOID and CBID algorithms in terms of the overall response time for (a)
6. Conclusion
In this article we presented CBID, an efficient heuristic algorithm that derives near-optimal itineraries for MAs performing incremental data fusion in WSN environments.
Our simulation tests indicate the following.
CBID achieves lower data fusion cost (thus lower energy consumption for the nodes) and smaller response time, compared to alternative approaches; CBID represents a low-complexity algorithmic approach, that is, it involves a construction of tree structures much faster than NOID; CBID in case(s) of possible topology change(s) in a WSN is able to update the itineraries followed by the MAs very fast.
However, the above-mentioned advantages are offered at the expense of more complex manageability of the data fusion task due to the involvement of multiple slave MAs. That is, an effective interagent communication protocol should be devised to allow exchange of data among the individual clones (e.g., through a “message” board abstraction). In addition, the creation of multiple MA clones increases the requirement upon SN resources.
As a future work, we intend to implement CBID in real WSN environments and evaluate its performance in various applications. A set of sensor nodes (Sunspots) capable of hosting and providing an execution environment for MAs programmed in Java [45] will form the basis of our field trials.