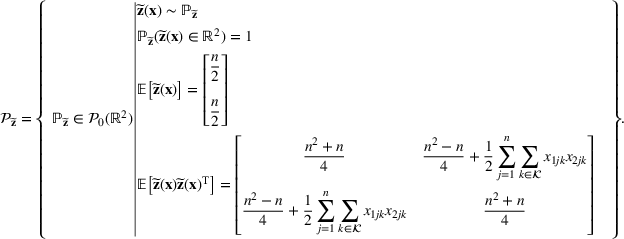
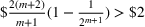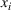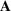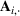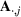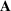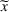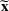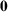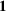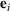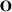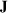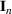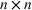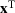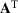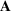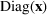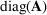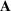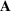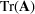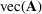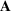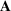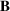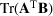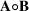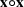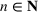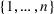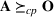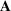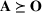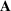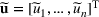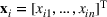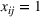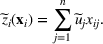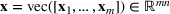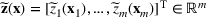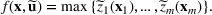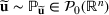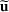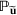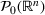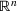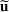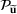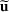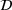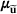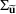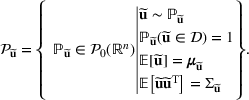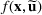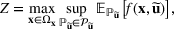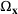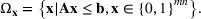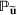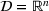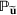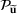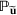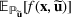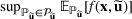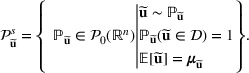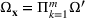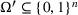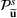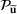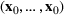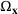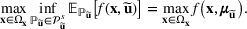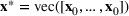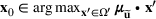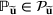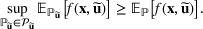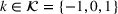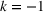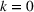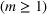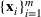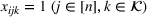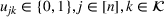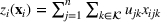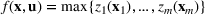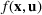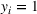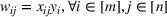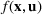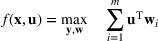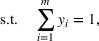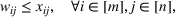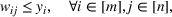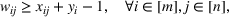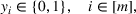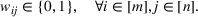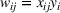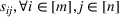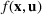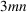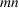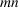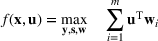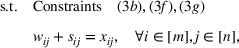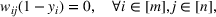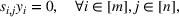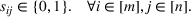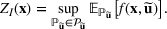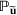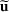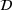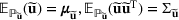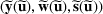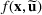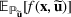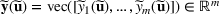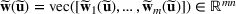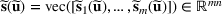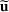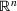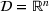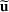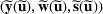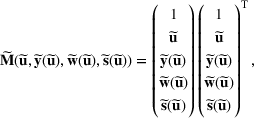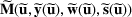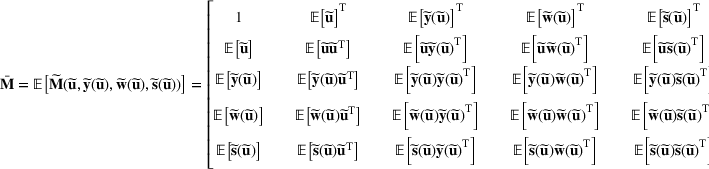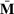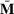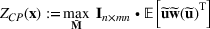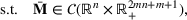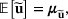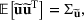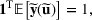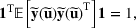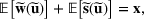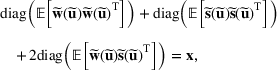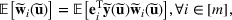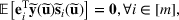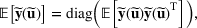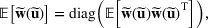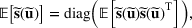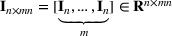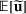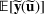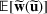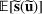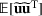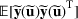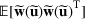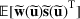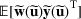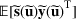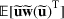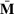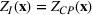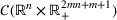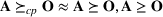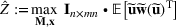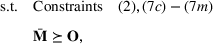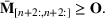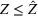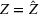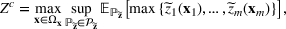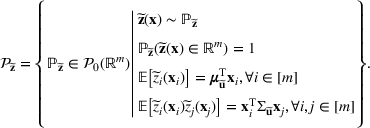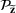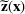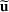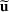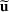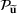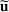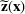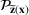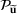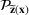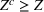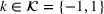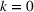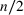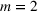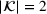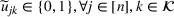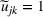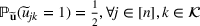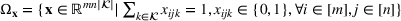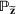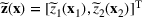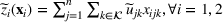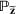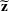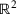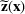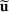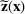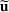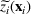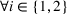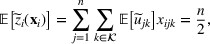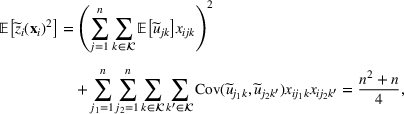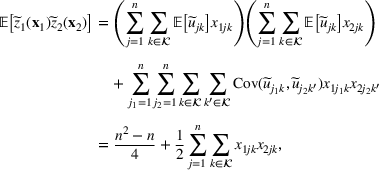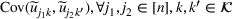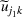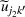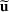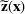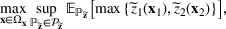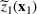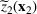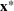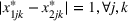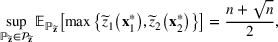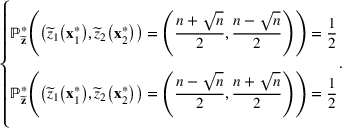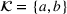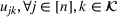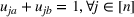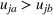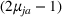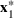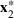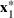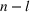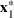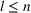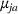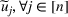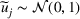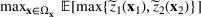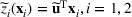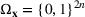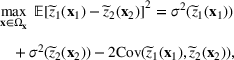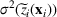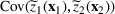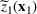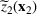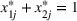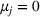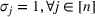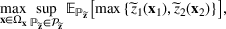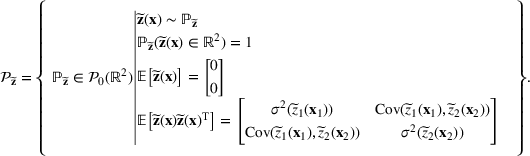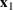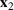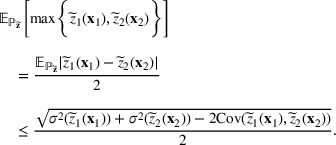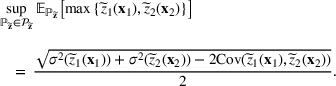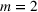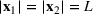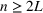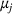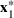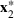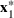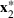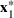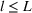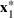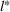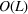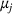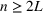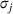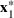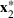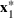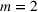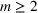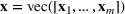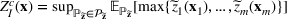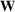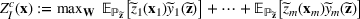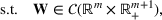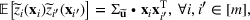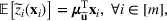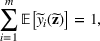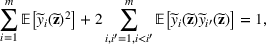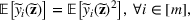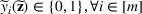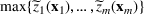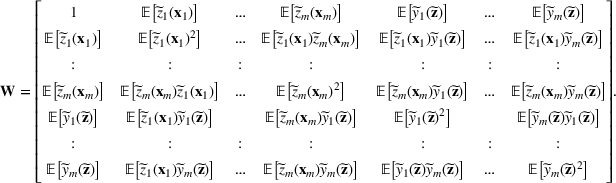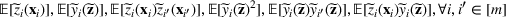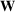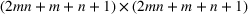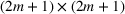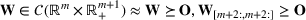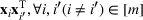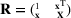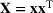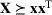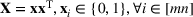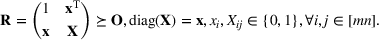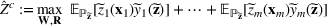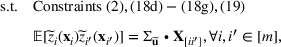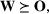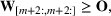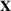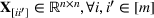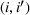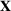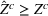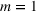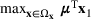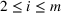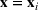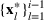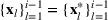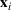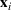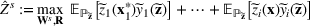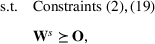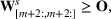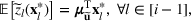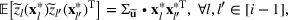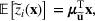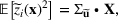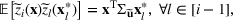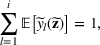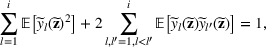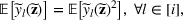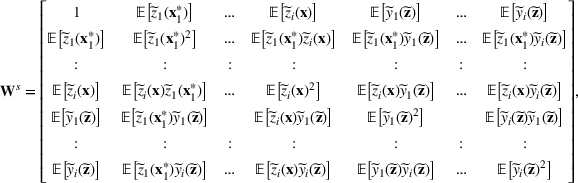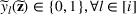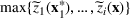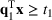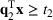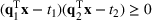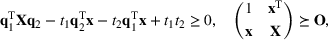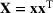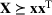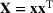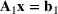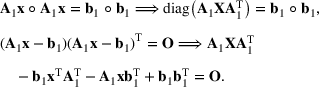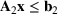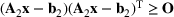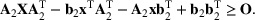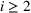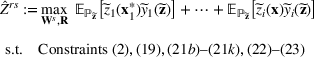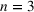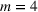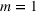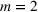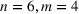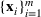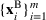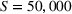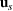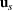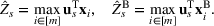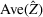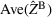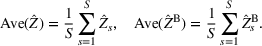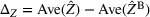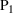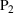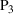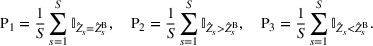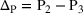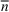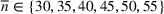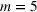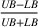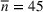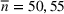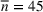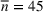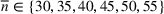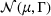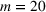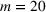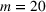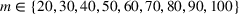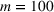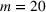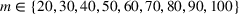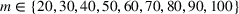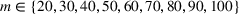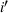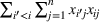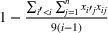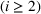We develop a general framework for selecting a small pool of candidate solutions to maximize the chances that one will be optimal for a combinatorial optimization problem, under a linear and additive random payoff function. We formulate this problem using a two‐stage distributionally robust model, with a mixed 0–1 semidefinite program. This approach allows us to exploit the “diversification” effect inherent in the problem to address how different candidate solutions can be selected to improve the chances that one will attain a high ex post payoff. More interestingly, using this distributionally robust optimization approach, our model recovers the “evil twin” strategy, well known in the field of football pool betting, under appropriate settings.
We also address the computational challenges of scaling up our approach to construct a moderate number of candidate solutions to increase the chances of finding one that performs well. To this end, we develop a sequential optimization approach based on a compact semidefinite programming reformulation of the problem. Extensive numerical results show the superiority of our approach over existing methods.
In the picking winners problem, the goal is to select a portfolio of candidate solutions to maximize the expected “score” of the ex post best‐performing solution (Hunter et al., 2016). The score of each solution is determined by a linear and additive random payoff function, which is based on the solution selected, and the realized payoffs/outcomes in a series of (random) events. This framework can be used to model a variety of problems in “high reward, low probability” winner‐take‐all contests. For example, a venture capital fund selects a set of start‐up companies to invest in, hoping that one of them will achieve huge success in the market. In a similar vein, a contestant in a daily fantasy sports contest chooses multiple lineups (of players) and hopes that one of the lineups selected will obtain a sufficiently high aggregate score to win the contest. Similarly, a contestant enters a sports betting pool with predictions on the outcomes of a series of games, hoping to have the highest number of correct predictions. In all these problems, an ensuing question is to construct a portfolio of candidate solutions so that the ex post performance of the best‐performing candidate is optimal. To this end, we develop a new approach in this paper to capture the “diversification effect” inherent in the portfolio selection problem, overcoming the technical difficulties of performance evaluation using a convex reformulation to approximate the problem.
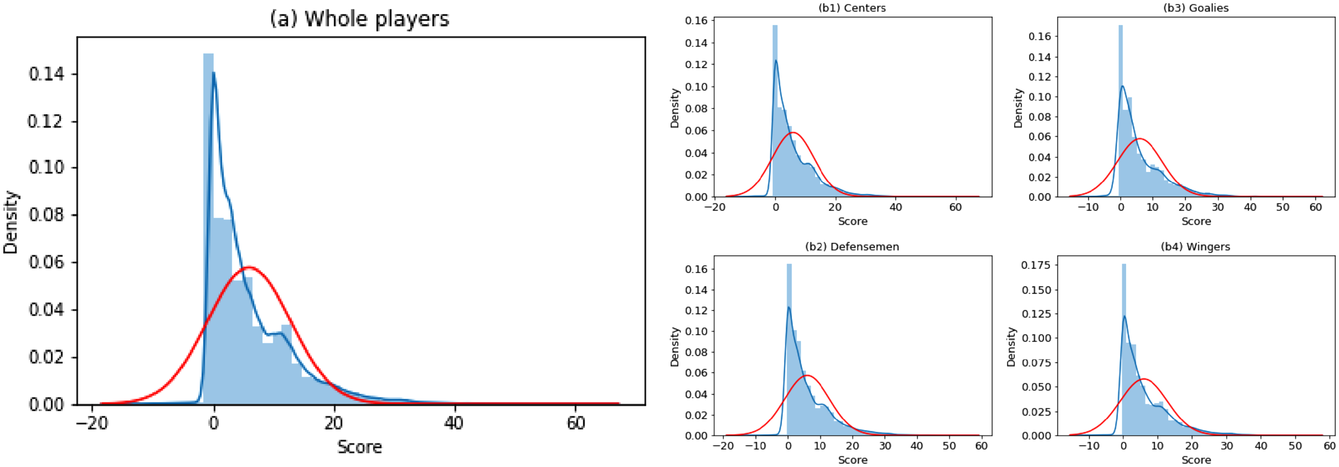
DeStefano et al. (1993) studied a related problem in football pool betting. The goal is to predict the outcome in a series of games (win or lose for the home team), and the punter in the pool with the most number of correct predictions wins the contest. By submitting two entries ($1 for each entry), with the second being the “evil twin” of the first (i.e., bet on the opposite outcome in each game), DeStefano et al. (1993) found that under the independently and identically distributed setting (i.e., outcomes in each game are independent and equally likely), the evil twin strategy can reap significant advantage—when m other punters choose their bets independently in each game with equal probability, the expected return to the evil‐twin strategy is
. By exploiting the diversification effect in this portfolio with two candidate solutions, the evil twin strategy is able to improve the expected returns from a naive strategy (choosing the outcome in each game randomly).
However, this evil twin strategy does not work well in general situations, especially when the utilities/payoffs for the items are nonidentical and possibly correlated. For the more general case, by assuming that the random payoffs are normally distributed, Hunter et al. (2016) constructed a portfolio guided by a mixed‐integer linear programming model. The goal of this model is to maximize the probability that one of the candidate solutions will win the contest. They used a sequential integer program to construct the portfolio based on the following heuristic: “First, the entries' scores should have a large expected value and variance, which increases the marginal probability of an entry winning. Second, the entries should also have a low correlation with each other to make sure that they cover a large number of possible outcomes.” This inspired the recent work of Bergman et al. (2023), who focused on the construction of two candidate solutions in a portfolio. Under the assumption of normality, they used an associated closed‐form expression of the expected maximum of two (normal) random variables to solve the problem. Based on this result, they designed a branch‐and‐cut algorithm to construct the optimal portfolio in this special case.
The normality assumption helped simplify the problem and resulted in elegant structural properties. However, extending these insights beyond two candidate solutions appears to be intractable. Furthermore, this assumption may not hold in practice. Take fantasy sports for example. As shown in Figure 1, which plots the fitting probability distributions of the fantasy scores for players using real data. Unfortunately, the best‐fit distribution (colored blue) is clearly different from the normal distribution (colored red).
The fitting distribution of the scores for athletes (whole athletes and the athletes under different positions, including center, defensemen, winger, and goalie) using data from October 2, 2019, to January 31, 2021 (https://fantasydata.com/). The blue and red lines correspond to the best‐fit distribution and normal distribution.
In this study, we use a more direct moment‐based distributionally robust optimization method to construct candidate solutions. This allows us to tap into recent results in the theory of moments by constructing a convex approximation for the problem. More specifically, we use a completely positive cross‐moment model (CPCMM) based on Natarajan et al. (2011). Using this model, we obtain a tight upper bound for the expected value of the stochastic order statistic problem for a given portfolio. Interestingly, this distributionally robust optimization problem can be formulated as a generalized completely positive program (CPP). This approach decomposes the moments matrix (with given means and covariances) into a convex combination of a finite number of rank‐one matrices. This can be viewed as a set of scenarios (with probabilities given by coefficients in the convex combination) that gives rise to the “best‐case” performance of the portfolio. The diversification effect arises because we are constructing a portfolio of solutions that work well in a diverse set of scenarios. This is analogous to Scarf's famous approach to the robust newsvendor solution. By fixing the mean and variance of the demand distribution, Scarf obtained the robust newsvendor solution based on a 2‐point distribution in the worst case (Scarf, 1957). The difference here is that instead of searching for the worst‐case performance (conservative), we solve for the best‐case performance. More importantly, this naturally leads to a tractable mixed 0–1 semidefinite programming (SDP) approximation algorithm, which is used to construct a good portfolio for the picking winners problem.
Notation
We use bold letters to denote the vectors, such as
, and use bold capital letters to denote the matrices, such as
;
denotes the ith element of vector
, and
represents the element in the ith row, jth column of the matrix
. We use
(or
) to denote the ith row (or jth column) of the matrix
. A random variable or random vector is denoted by a letter with the tilde notation, such as
and
. Specifically, let
and
denote a vector of all zeros and ones with appropriate size; let
represent a vector with one in the ith entry and zeros elsewhere. We use
and
to denote a matrix of zeros and ones, respectively.
denotes an
identity matrix. Let
and
denote the transpose of a vector
and matrix
. We use
to denote a diagonal matrix with the entries of
along the diagonal. Let
represent a vector formed by the diagonal entries of the matrix
. The trace of a matrix
is denoted by
. Let
denote the vector obtained by stacking the columns of matrix
. Let
denote the inner product between matrices
and
, which is also equivalent to
. We use the notation ○, such as
and
, to denote the Hadamard product between two matrices or two vectors. The cardinality of a set is denoted by
. For any integer
, [n] is shorthand for set
. We use
to represent that
is a completely positive matrix and
to denote that
is a positive semidefinite matrix.
LITERATURE REVIEW
Our problem is related to the picking winners problem, sports betting pools, fantasy sports, and SDP‐based approximation methods. We provide a brief review of the literature related to these issues.
The picking winners problem
Our study is inspired by the work of Hunter et al. (2016). They used a greedy heuristic to construct the candidate solutions in a sequential manner, based on the following design principles: maximize the mean and variance of the performance of a solution and minimize the covariance between any two solutions. Hunter et al. (2017) applied this framework to evaluate and choose portfolios of start‐up companies, maximizing the probability that at least one company succeeds. They showed that the objective function in the picking winners problem is submodular and then designed an efficient greedy algorithm to solve the problem. Related applications are discussed in El‐Arini et al. (2009) and Khuller et al. (1999). All the methods proposed thus far exploit properties of normal distribution in the analysis. Our work is different as we relax the assumption of normality for the resources' payoffs and also obtain the diversification effect in the solutions naturally instead of using constraints to enforce this effect.
The problem is also related to the order statistic optimization problem. We refer the interested readers to Ahsanullah and Nevzorov (2005), Bertsimas et al. (2006), and Mehta et al. (2020) for details. More recently, Bergman et al. (2023) focused on the case with two solutions and used results in order statistics (for two normal random variables) to devise cutting plane algorithms for these problems. Our framework is more versatile and can be extended to handle problems with more than two candidate solutions.
Sports betting pools
Kvam and Sokol (2006) and Brown and Sokol (2010) both built linear regression Markov chain models to forecast the outcome of each game in a sports betting pool. Caudill (2003) adopted a maximum score estimator to predict the game outcomes of the NCAA men's basketball tournament. We use these as input in our model to investigate the performance of different sports betting pool strategies. Interestingly, DeStefano et al. (1993) observed that the evil twin strategy has significant advantages when the games in the pool are fair and independent. Kaplan and Garstka (2001) showed how to calculate the mean and variance of the number of accurate guesses for single‐elimination tournaments. They designed a sports betting prediction strategy to maximize the expected total score in an office pool, and they found that the strategy could predict winners in about 58% of games in actual basketball tournaments. Clair and Letscher (2007) developed a new prediction model incorporating pool participant behavior to maximize the expected return in both football pools and tournament‐style pools.
Fantasy sports
A branch of this literature focuses on developing a prediction methodology to estimate player performance based on historical data (see King et al., 2017; Robinson, 2020). Multiple studies have sought to provide an optimization method for sports league drafts. Fry et al. (2007) employed a stochastic program to model the team decision‐making process. Becker and Sun (2016) provided a methodology for predicting athlete and team performance, and they then formulated a mixed 0–1 integer optimization model for draft selection. Readers can refer to Beliën et al. (2017) and Summers et al. (2007) for more details. There are relatively few studies trying to construct portfolios for daily fantasy sports. One notable work is Hunter et al. (2016) mentioned above, which provided a greedy heuristic to construct lineups and achieved great success in actual contests. On this basis, Haugh and Singal (2021) provided an optimization framework to account for an opponent's team selection behavior in daily fantasy sports (DFS). Bergman et al. (2023) also applied their methodology, namely maximizing the expectation of the largest order statistics, to select lineups for DFS.
SDP‐based approximation methods for solving a two‐stage distributionally robust optimization problem
Algorithms for solving a two‐stage distributionally robust optimization problem have been widely studied. Here, we focus specifically on the SDP‐based approximation method, which is closely related to our study. The basic idea of this method is to equivalently reformulate the infinite‐dimensional optimization problem into a finite‐dimensional linear conic program. This method further approximates this cone as a positive semidefinite cone, thus leading to a tractable SDP. For example, G. Xu and Burer (2018) constructed a copositive reformulation to equivalently express the two‐stage robust optimization problem with uncertain right‐hand sides under certain conditions and provided a tractable SDP‐based approximation method to address this problem. Hanasusanto and Kuhn (2018) demonstrated that a two‐stage distributionally robust linear program can be equivalent to a copositive program when the ambiguity set is constructed based on a 2‐Wasserstein ball, leading to a natural SDP approximation. H. Xu et al. (2018) studied a max–max formulation and proved that it can also be equivalent to a copositive program under certain conditions.
Our study focuses on a moment‐based ambiguity set instead of a distance‐based ambiguity set. Applying a moment‐based ambiguity set, Bertsimas et al. (2010) proposed an SDP‐based model for the class of two‐stage minimax distributionally robust linear optimization problems given the first and second moments. Natarajan et al. (2011) proposed a CPCMM to address a two‐stage distributionally robust framework. Their model focuses on a distribution that attains the best‐case expected performance. This model proved that the best‐case expected value of the maximum of a mixed 0–1 linear program was equivalent to a CPP when the decision‐maker knows the first and second moments of the nonnegative uncertain parameters. Since then, the CPCMM model has been applied to many topics (see Gao et al., 2019; Kong et al., 2020; Yan et al., 2018). Note that reformulating into a CPCMM does not immediately make this problem tractable, but it shifts the problem complexity into understanding the facial structure of the completely positive cone or its dual cone (copositive cone). We refer readers to Berman and Shaked‐Monderer (2003) for more information about the two convex cones. One common method is to approximate the completely positive cone as a positive semidefinite cone with nonnegative entries. Therefore, the two‐stage distributionally robust optimization problem can be reduced to a tractable SDP.
We contribute to this literature in two ways. First, we apply the CPCMM to address the portfolio optimization problem in the context of the picking winners problem, which can help naturally exploit the diversification effect via cross‐moments. Second, to overcome the computational inefficiency caused by the high‐dimensional generalized completely positive cone, we collapse the whole optimization problem into a more compact form with a low‐dimensional generalized completely positive cone, thus leading to a tractable mixed 0–1 SDP.
BASIC FRAMEWORK
In this section, we first formally define the picking winners problem and reformulate it into a mixed 0–1 SDP by using a distributionally robust optimization approach. Then we reformulate the basic model using a conic reformulation.
Picking winners: A distributionally robust optimization approach
Consider the problem of constructing a portfolio that includes m solutions from n potential resources—the payoff/utilities of which are random and possibly correlated (denoted by
). We denote the ith solution by a binary decision vector
, where
if resource j is selected in solution i and 0 otherwise. The payoff is determined by the sum of payoffs of the resources selected, defined as
Let
be a binary vector, and let
. The uncertain maximum‐valued solution can be represented as
Let
. This means that the n‐dimensional random variable,
, is governed by a probability distribution
, where
represents the set of all probability distributions in
. Assume that only the first‐two moments information of
is known. Let
denote a set of all feasible distributions of
supported on
with finite mean
and second moment matrix
, that is,
Under this assumption, the picking winners problem of our interest is to optimize the selection decision
for constructing m solutions so that the best‐case expected performance of the maximum‐valued solution
is maximized. The picking winners problem is formulated as follows:
where
denotes the feasible region of
that can be written in terms of
through a set of linear constraints, represented by
Note that if we restrict
further to contain only the family of normal distributions, and
, then
is a singleton set. This is because the normal distribution is uniquely determined by the means and covariance conditions. The problem, therefore, reduces to the one studied in the literature. However, with only moments conditions, in general
is not a singleton.
For a fixed distribution
, there is no closed‐form expression for
, which makes the analysis of the picking winners problem intractable. That is, the main challenge of addressing problem (1) lies in its inner problem
.
Why max‐sup over max‐inf
Problem (1) is different from the standard robust optimization approach, where the focus is on constructing a “safe” solution that will work well in most scenarios. Instead, the problem in (1) focuses on finding an “optimistic” solution to encourage risk taking and diversification of the solutions constructed. Hence, rather than using an inf formulation to model the second stage performance (as in the traditional robust approach), we use a sup formulation instead. In the following, we show that the inf formulation does not work in this picking winners problem because it does not result in diversification. First, two assumptions are introduced.
The distribution ambiguity set is defined as
, where
.
Note that the distribution ambiguity set
is the same as
we study later, except that it relaxes the second moment condition. Assumption 2 ensures that solutions like
belong to
.
Under Assumptions 1 and 2, the max‐inf formulation reduces to
Furthermore, the optimal portfolio strategy for constructing m solutions satisfies
, where
.
Theorem 1 shows that a max‐inf formulation always generates the same m candidate solutions, where any one feasible candidate solution is obtained by maximizing the mean of a portfolio. Therefore, this validates that a max‐inf formulation does not result in diversification. As such, there is no incentive to diversify the portfolio with this model.
On the other hand, the sup formulation has some inherent advantages for this class of problems. For any
, it is easy to see that
As will be shown later, the left‐hand side can be modeled by a class of conic programs with nice properties—the extremal distribution is obtained from a convex combination of a finite number of outcome “scenarios.” By seeking an “optimistic” solution in this formulation, the diversification effect comes naturally from the risk‐seeking tendency to find a better portfolio. In fact, in the case of sports betting, this model can recover the “evil twin” strategy, where two directly opposing strategies are used to hedge against bad outcomes in a series of sporting contests. For further justifications for using the sup framework, we refer readers to Natarajan et al. (2011) and Natarajan and Teo (2017).
Sports betting pool: Discrete payoffs
In a sports betting pool, each punter places bets based on the outcome of each sporting event in the pool. There are two types of betting pools (Bender, 2013). One is an office pool, where the participants with the maximum number of correct predictions on the outcomes win the entire pool (i.e., a winner‐take‐all payoff structure). The other is a for‐profit pool, where the amount of prize money awarded depends on the number of correct predictions and the payoff structure. In this study, we focus on the office pool version.
Consider n upcoming sports games, in which each game involves two teams (i.e., a home team and an away team). Only one of three outcomes—win, draw, or lose—can occur in each game. Let
denote the possible outcomes of a game. Specifically, if
(or 1), the home team loses (wins resp.); otherwise,
indicates a draw. Note that the possible outcomes may only include −1 and 1 in some cases, such as basketball games. In a sports betting pool, punters can submit multiple m
entries and the entry with the most correct guesses wins the game.
In the first stage, the punter chooses the outcome of each game, denoted by
, where
implies that the ith bet of the punter is outcome k in game j. Let
, denote the realized outcome, where
if the actual result of game j is outcome k and 0 otherwise. Thus, the realized correct guesses of each entry can be depicted as
and the corresponding realized correct guesses of the maximum‐valued entry from a punter is
.
Reformulation of
Given
and realized utilities
, the second stage problem aims to select the maximum‐valued solution among m solutions. Let
imply that the ith solution is the maximum‐valued solution and 0 otherwise. For linearization purposes, let us introduce the auxiliary variables
. Then we can equivalently reformulate
as follows:
Constraint (3b) assures that only one maximum‐valued solution can be selected. Inequalities (3c)–(3e) are introduced to equivalently express
.
For better computational efficiency (and to ensure tractable formulations later), we further reformulate the above model into a quadratic‐constrained binary program by introducing binary slack variables
. Note that the reformulations that will be developed later will require
to be representable as a quadratic binary program with only equality constraints. By reformulating the linear constraints into a quadratic form, we not only reduce the scale of model constraints in the reformulated conic program but also avoid introducing more slack variables. Specifically, if we solve problem (3) directly, we need to introduce
slack variables (constraints (3c)–(3e) all require
slack variables). However, for the quadratic‐constrained binary program below, we only introduce
slack variables. Thus, the equivalent quadratic‐constrained binary program is given by
We have equivalently transformed the inequality constraints (3c)–(3e) into linear and quadratic constraints (4b)–(4d).
Conic reformulation
This section aims to reformulate problem (1) into a mixed‐integer conic program with a tractable SDP relaxation. The main challenge of addressing this problem lies in its inner problem:
The above formulation aims to find a distribution,
, for the random variable
supported on
that satisfies the given first‐two moments (i.e.,
). It must satisfy the corresponding optimal solution,
, of the quadratic‐constrained binary program,
, so that the term
achieves the maximum, or to find a sequence of distributions to asymptotically achieve the maximum. Here, we define
,
, and
as binary vectors.
In the following, we consider random vector
supported on
(i.e.,
). In this case, it has been established that the inner optimization problem for a set of distributions with prescribed moments is equivalent to a generalized CPP, where the objective function can be written as a linear function of the (conditional) moments and the linear conic constraints are enforced to define the feasible region in the space of moments (Gao et al., 2019; Natarajan et al., 2011; Yan et al., 2018). The advantage of this transformation is that it shifts the difficulty into the convex generalized completely positive cone so that more knowledge about the cone can be applied to multiple types of nondeterministic polynomial time (NP)‐hard problems (Burer, 2009). Specific definitions and properties of the cones of interest, such as generalized completely positive cone and explicit formulations of the CPP, are provided in Appendix EC.1.1 in the Supporting Information.
Define the following rank‐one matrix consisting of the random vector
and the corresponding uncertain nonnegative optimal decision vector
as,
which is a generalized cone of completely positive matrices, that is,
, since
and
. We take the expectation of
as
which is used as the decision variable for building the conic program. Note that the decision variable
still preserves the property of the generalized completely positive cone due to its convexity.
Following the reformulation process of Natarajan et al. (2011), Yan et al. (2018), and Gao et al. (2019), we can get an equivalent generalized CPP for the inner problem (5) of picking winners in terms of decision variable
, shown in the following problem (7). For the detailed reformulation process, we refer the readers to Appendix EC.1.2 in the Supporting Information.
where the matrix
. Note that all the expected terms, including
,
,
,
,
,
,
,
,
,
, and
, are the elements of the decision variable
.
For a given
,
.
Proposition 1 indicates the equivalence between problems (5) and (7). Based on Proposition 1, we can directly solve problem (7) instead of solving problem (5), which leads to a convex optimization problem.
However, formulating this problem as a generalized CPP (7) does not resolve the difficulty of the problem. Solving problem (7) is still NP‐hard (Natarajan & Teo, 2017). The difficulty of this problem lies in characterizing the generalized completely positive cone
(Bomze et al., 2000; Dür & Still, 2008). A simple relaxation method is to approximate the completely positive cone as a “doubly non‐negative cone,” which is defined as a positive semidefinite cone with nonnegative entries, that is,
. Then by replacing the constraint (7b) with (8b)–(8c) and combining it with the first‐stage optimization problem, the whole picking winners problem (1) can be approximated as a mixed 0–1 SDP program as follows:
Clearly, every completely positive cone is doubly nonnegative, but the converse is not necessarily true. Hence, this brings us to the following key result.
Problem (8) provides an upper bound of problem (1), that is,
.
Note that the equation
holds when the dimension of the matrix
is less than four (Berman & Shaked‐Monderer, 2003). The performance of this relaxation has been shown to work well using simulation (Natarajan et al., 2011). The above framework can also be extended to consider a case with more general support, such as the binary payoff structure in the sports betting pool problem of Subsection 3.1.2. Please refer to Appendix EC.1.3 for more specific details in the Supporting Information.
COMPACT REFORMULATION
In many cases, the number of entries submitted by a punter in a contest is relatively small, compared to the number of resources/players available for selection. For example, there are thousands of start‐up companies every year, but venture capitalists invest in a dozen at most because of cost constraints (Hunter et al., 2017). This motivates us to collapse the above conic program into a more compact form by directly modeling the first and second moment of the payoff of each entry, rather than that of the resources/players.
More specifically, the compact reformulation of interest is defined as follows:
where
Note that in the above compact reformulation, we actually focus on the ambiguity set,
, of the utilities of entries
rather than
of the resources,
. To avoid confusion, it is worth emphasizing that, in Section 3, the uncertainty always comes from the distribution of
and the distribution of
is described by moment‐based ambiguity set
. However, the setup of this section is somewhat different. Namely, rather than modeling the distribution of
, the goal of this section is to model the distribution of
, which is described by the above moment‐based ambiguity set
in (10). The following proposition further provides the relationship between the original optimizing problem, (1), and ambiguity set
as well as the relationship between compact formulation (9) over ambiguity set
.
Problem (9) provides an upper bound to the original problem (1), that is,
.
To better understand the motivation of our compact formulation, we take the following sports betting pool with only two outcomes
(i.e., ignoring
) as an example in the next subsection.
Evil twin strategy: Two outcomes per game
The evil twin strategy is to avoid betting on the same outcome in two different entries submitted by the same punter. In this way, one of the entries will always get at least
bets correct. This simple strategy raises the chances that one of the two bets will ultimately win the office pool. DeStefano et al. (1993) verified the significant advantage of the evil twin strategy in their probability model by calculating the associated expected profit of the evil twin strategy. We take this one step further and show that the evil twin strategy is actually the optimal solution in a related distributionally robust optimization model. In the following, we focus on a case of
.
Special case: Equal chance
We consider a special case of the sports betting pool problem that has the following characteristics. For the definition of notations, please refer to Subsection 3.1.2. There are n sport games indexed by
, and each game j has only two different outcomes (i.e.,
): win or lose. Recall that
indicates the uncertain outcomes of each game, where
denotes that the outcome of game j is k and 0 otherwise. We assume that each team has an equal chance of being the winner for each game (i.e.,
). We also assume that the outcomes in different sports games are independent. In addition, regarding the requirements for betting selection
, according to realistic rules for sports betting pools, in each bet, the punter can only bet on exactly one outcome per game (i.e.,
).
Under the above problem settings and based on general compact formulation (9), we can formulate the compact formulation for this special case of the sports betting pool problem. Note that here we actually focus on modeling the joint distribution
of the number of correct guesses
, where
. More precisely, we assume that the distribution
of
lies in a set of potential joint distributions supported on
, with the finite first moment and second moment.
Since
is determined by
and
, the first‐two moment conditions on
are also determined by the moments conditions on
and the feasible decision
. Thus, given
, the first and second moment of
,
, can be expressed as
where
denotes the covariance between
and
. For the detailed derivation, we refer the readers to Appendix EC.2.10 in the Supporting Information. We must point out that the independence assumption is not required in Subsection 3.1.2. However, here, the independence assumption for
is added to further simplify the first and second moments of
. This allows us to derive the evil twin strategy as the optimal solution in this special case.
Therefore, based on the above analysis, in this special case, the compact formulation of the sports betting pool problem can be reduced to the following optimization problem:
where
Due to the basic settings of an equal chance of winning and independent outcomes, it is intuitive that the correct guesses for two bets (i.e.,
and
) will have the same mean and standard deviation. Lemma 1 demonstrates the performance of the evil twin strategy in our moment‐based model.
, and the corresponding best‐case expected performance of the maximum‐valued bet equals
which can be exactly achieved by the following extreme two‐point distribution:
The above result indicates that under this special case, evil twin is the optimal strategy, namely, the optimal solution to problem (12). This affirms the importance of the diversification effect on the performance of the portfolio solution. Even though our moment‐based model is less refined compared to the probability model provided by DeStefano et al. (1993), it still obtains the strategically interesting evil twin strategy as the optimal solution.
General case: Unequal chance
In a more general case, suppose the two outcomes are labeled a and b, that is,
, with winning probability
, for each game j, where
, and
. Thus, we have the following optimal betting strategy in this general case.
If each game has two outcomes per game, and the outcomes are independent across games, then the optimal strategy to problem (9) is to sort the games based on
in nonincreasing order:
places a bet on the most likely outcome in each game,
bets the same as
in the first
games while then bets against
in the last l games, for some
.
Theorem 2 shows that the optimal betting strategy is a “partial” evil twin, balancing between exploitation (for higher winning probabilities) and diversity (evil twin). Note that the complexity of this problem is polynomial‐time
solvable since we can compute the optimal
by a simple search in nonincreasing order of
.
Continuous outcomes
It is useful to compare the results obtained above to the continuous outcome case. Suppose that the outcome
, of each game is continuous, which follows the standard normal distribution
, then the similar problem is defined to solve
, where
. Assuming
, Bergman et al. (2023) have shown that this optimization problem is equivalent to
where
denotes the variance of the payoff of the ith solution and
represents the covariance between
and
. Furthermore, under a special covariance structure, the problem above reduces to a general cut minimization problem (and is therefore NP‐hard!), as the optimal solution satisfies
for all
(Bergman et al., 2023). In the following, we show that our compact formulation can still obtain the same result.
Using the same moment condition as that of Bergman et al. (2023), we set
and
. In this problem setting, similar to problem (12), the compact formulation for the case of continuous outcomes can be described by
where
Before analyzing this compact formulation (15), we first give the following important result.
Moreover, the right‐hand side of inequality (17) is tight since there exists a sequence of random vectors that asymptotically achieves this upper bound, that is,
Proposition 4 indicates that our compact formulation reduces to solving problem (14). Therefore, by referring to Bergman's result mentioned above, the problem of finding the optimal diversification strategy for a portfolio of two or more lineups is NP‐hard in compact reformulation (9), which is formally stated in the following theorem.
This analysis shows that the solution under distributionally robust model (9) is at least as rich as the version considered by Bergman et al. (2023), who used a closed‐form expression for the maximum of two normal random variables to develop a cutting plane algorithm. Our distributionally robust model transforms the problem into a mixed 0–1 SDP, and this allows us to construct a portfolio with three or more lineups, overcoming a key limitation in Bergman et al. (2023). The above also shows a drastic difference in complexity when the outcomes across games change from independent to highly correlated. The latter holds especially for fantasy sports games. We expect that the ability of our model to capture this correlational structure will be extremely valuable for these types of games.
In the case of
, we want to pick two solutions, each with cardinality L (i.e.,
). Assume that
. The outcomes are independent and have different means but identical variances. The problem then becomes tractable. The optimal solution follows Theorem 4.
If the outcomes are independent and continuous with different means but the same variance across resources, the optimal strategy for solving Problem (9) is to sort the resources based on
in nonincreasing order:
places a bet on L resources with the highest mean outcome,
bets the same as
in the first
resources, while
differs from
in the last l (
) resources and bets on the last l resources with the highest mean outcomes outside of those chosen by
.
Theorem 4 extends the conclusion in Theorem 2 to the case of continuous payoffs, that partial evil twin is the optimal betting strategy under this special case. Note that the optimal
can be computed in polynomial‐time
by a simple line search in nonincreasing order of
.
Furthermore, we consider another special case in which the outcomes for each game have identical mean but have different variances. The optimal betting strategy is formally stated as follows.
Assume
, If the outcomes are independent and continuous with the same mean and different variance across resources, then the optimal strategy for problem (9) is to sort the resources based on
in nonincreasing order:
bets on L resources, which are randomly selected from the first 2L highest variance outcome and
bets on the remaining L resources, which are outside of those chosen by of
.
Corollary 1 shows that full evil twin betting on the resources with the highest variances is the best betting strategy in this special case. Recall that the previous evil twin strategies in Theorems 1 and 4 mainly utilize the heterogeneous mean information of each resource (or game) to capture the diversification effect. However, in this case of equal means, the heterogeneous variance is considered to reap the diversification effect.
Reformulation
Note that we have shown the effectiveness of the compact formulation for
in the previous subsection, which can recover the evil twin strategy in both discrete and continuous cases under appropriate settings. In this subsection, we attempt to solve the more general compact formulation (9) for
. To do this, by applying similar techniques in Subsection 3.3, we can further approximate the compact formulation (9) as a low‐dimensional mixed 0–1 SDP.
For a fixed
, based on the result of Proposition 1, we can equivalently reformulate the inner problem
of problem (9) as a generalized CPP in terms of the decision variable
, shown as below:
where
is defined as the stochastic optimal decision of problem
, and
In the formulation above, similar to problem (7), all the expected terms, including
, are the elements of the decision variable
. Compared with the high‐dimensional
generalized completely positive cone of problem (7), here the inner problem of the compact formulation (18) leads to a low‐dimensional
generalized CPP. The corresponding SDP relaxation (i.e.,
) can now be solved efficiently.
We note that the first stage decisions
appear in a bilinear form
in the above formulation (18). The overall compact formulation (9) is therefore nonconvex in the first stage decision. To speed up the computation further, we convexify the bilinear term based on a semidefinite program. Specifically, the problem is first lifted into a higher dimensional space
by setting
and then relaxing the rank‐one constraint by imposing
. But in our first‐stage problem, in order to obtain binary candidate decision, we retain the binary property of
. Thus, the constraint
can be equivalently expressed as follows:
Based on the above conic reformulation to the inner problem and the adoption of the convexification technique, we can further approximate the overall compact formulation (9) as the following mixed 0–1 SDP:
where the matrix
can be partitioned into
blocks, and
is the
entry of the original matrix
.
Problem (20) provides an upper bound to problem (9), that is,
.
The quality of this compact formulation is examined in Appendix EC.4.1 compared to the original formulation in the Supporting Information.
A sequential optimization algorithm
Although formulation (20) provides a lower dimensional SDP relative to the original formulation (8), it is still computationally costly when we need to construct a large number of entries (i.e., candidate solutions) for the pool. To overcome this issue, we design a sequential optimization algorithm for multiple solutions.
For the first solution, we solve problem (20) by setting
, which is reduced to a 0–1 integer program, that is,
.
We calculate the ith (
) solution
based on the first
solutions
. By substituting
into the problem (20), we obtain the following formulation to obtain
. For notational convenience, we use
in place of
in the rest of the discussion.
where
and
, is defined as the optimal solution of the problem
.
In order to further improve the computational efficiency, we introduce a set of valid inequalities based on a reformulation–linearization technique (RLT) (Sherali & Adams, 2013). Note that an inequality is said to be valid if it is satisfied by all the feasible solutions of problem (21) (Ashraphijuo et al., 2016).
The idea of generating valid inequalities based on RLT is to first generate valid nonconvex quadratic inequalities and then relax them to valid convex inequalities in a lifted space. For example, if
and
are two valid inequalities, then the redundant nonconvex quadratic constraint
can be relaxed to the following valid convex inequalities:
which is obtained by relaxing
to
. Similar treatments can be done for the linear constraints on the original decision variable
in our problem (21). The difference is that in our case, under the constraint (19),
always holds.
For linear equality constraints
, a set of lifting equalities are valid, which is given by
For linear inequality constraints
, the redundant nonconvex quadratic constraint
can be relaxed to
Thus, the resulting mixed 0–1 SDP formulation for the ith (
) iteration is shown as follows:
Comparison between sequential optimization and compact formulation
We use a simple sports betting pool to examine the performance of our sequential optimization method proposed in Section 4.4. We use a dataset of NBA games from November 12, 2020, to November 16, 2020, to obtain the odds for each team, which are used as input for our model. We assume the outcomes of each game are independent to simulate the performance of the solutions obtained. For more details related to the dataset and input estimation, we refer readers to Appendix EC.5.1 in the Supporting Information.
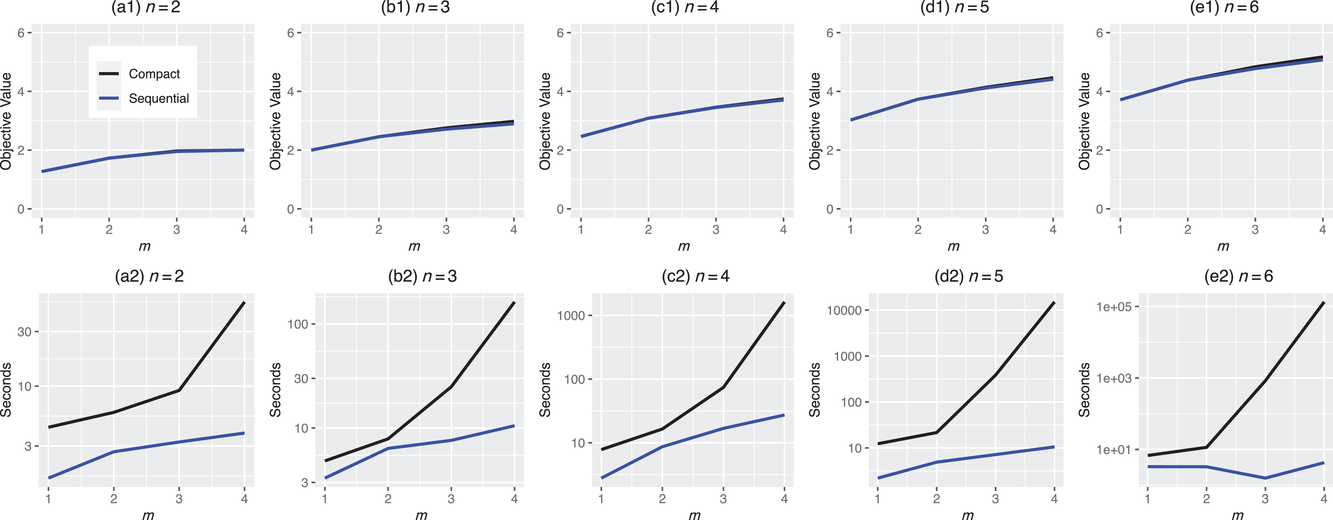
In the test, we vary the number of games (n) from 2 to 6 and the sizes of bets (m) from 1 to 4. Figure 2 reports the results of the objective values and computational times obtained by the two methods (sequential optimization versus compact formulation) under different circumstances. We can observe that the gaps in the objective values obtained by the two methods are quite small, while the computational advantage of our method is significant. Specifically, most of the gaps are within 1%, and the largest gap is 2.82% when
and
. Furthermore, the sequential optimization method obtains the same solution as the compact formulation when
or 2. This is because the sequential optimization method will bet on the most likely outcome in each game in the first iteration, which is one of the optimal solutions when
(as proved in Theorem 2). For the computational time, the sequential optimization method can solve all the scenarios within half a minute, while solving using the compact formulation directly requires an exceedingly long time. For example, it takes more than 36 h to solve
to optimality. Overall, the sequential optimization method can provide a good approximation for the compact formulation while greatly reducing computational time.
Comparisons between sequential optimization and compact formulation. The top and bottom five figures show the results of objective values and computational times, respectively.
Comparison with Hunter's method
To validate the effectiveness of our method, we also compare the performance of sequential optimization in sports betting with a benchmark proposed by Hunter et al. (2016).
Sequential optimization method. We obtain the betting solution
by applying sequential optimization method (21).
Hunter's method. We apply the framework in Appendix EC.3.2 (in the Supporting Information) to obtain a benchmark solution
.
In the numerical experiments, we assume the outcomes of each game are independent. This is the setting in which heuristics like those in the Hunter method are expected to perform well. Before reporting the results, we first introduce two metrics, the average top‐performing bets and winning probability, to evaluate the out‐of‐sample performance of the solutions obtained. More specifically, we randomly generate
runs of the games in the sports betting pool using the outcomes of each game determined by the prescribed odds in the dataset. Each run s is represented by
. Based on
, we can calculate the top‐performing bet (i.e., the maximum number of correct guesses in the solutions submitted) under the two methods as
Then, we can compute the two metrics as follows:
Average top‐performing bets. Let
and
denote the average number of the top‐performing bet for our method and the benchmark, which can be calculated as
We use
to measure the improvement of our solution compared to the benchmark.
Winning probability. We use
,
, and
to denote the probability that our maximum‐valued bet is equal to, better, and worse than that of benchmark solutions, which is calculated as
We define
to measure the improvement in the winning probability of our top‐performing bet over the benchmark solution. Note that the larger ΔP, the better our solution is vis‐a‐vis the benchmark.
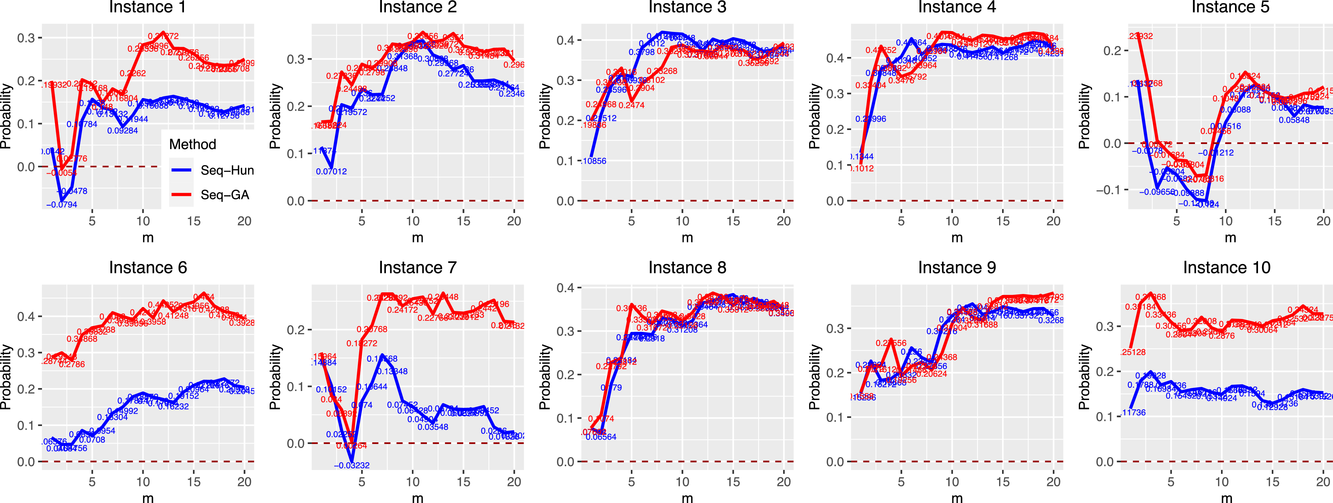
In this test, we vary the number of games (n) from 2 to 7 and the different number of bets (m) from 1 to 8. From Figure 3, we observe that the sequential optimization algorithm performs as well, if not better, than the benchmark in terms of the two metrics. We refer the readers to Appendices EC.5.2 and EC.5.3 (in the Supporting Information) for details on more numerical experiments with this sports betting problem.
The results of the comparison between sequential optimization and Hunter's method using NBA games. The top six figures show the average top‐performing bets under the different values of n for the two methods. The bottom two figures report the improvement in the top‐performing bet and the winning probability.
DAILY FANTASY SPORT
In this section, we solve the lineup construction problem for Daily Fantasy Hockey Sports (DraftKings), using data from https://fantasydata.com. We use data from October 2, 2019, to January 31, 2021, as the training set to estimate the parameters for our models. We then use contests from March 1, 2021, to March 10, 2021, as the test set to validate the effectiveness of our method. Specific contest information is shown in Table EC.4 in the Supporting Information.
Problem statement and input estimation
In DraftKings, nearly all winnings go to the top‐performing entry. In the game, each participant can submit multiple hockey lineups (candidate solutions) and the total fantasy score of a lineup is equal to the sum of the real‐world athletes' actual fantasy scores. Each hockey lineup is required to select nine athletes: two centers, three wingers, two defensemen, one goalie, and one utility athlete. Note that the utility athlete can be selected from any of the skaters. Moreover, all the selected athletes of in each hockey lineup must be from at least three different teams, with a budget limit of 50,000 fantasy dollars.
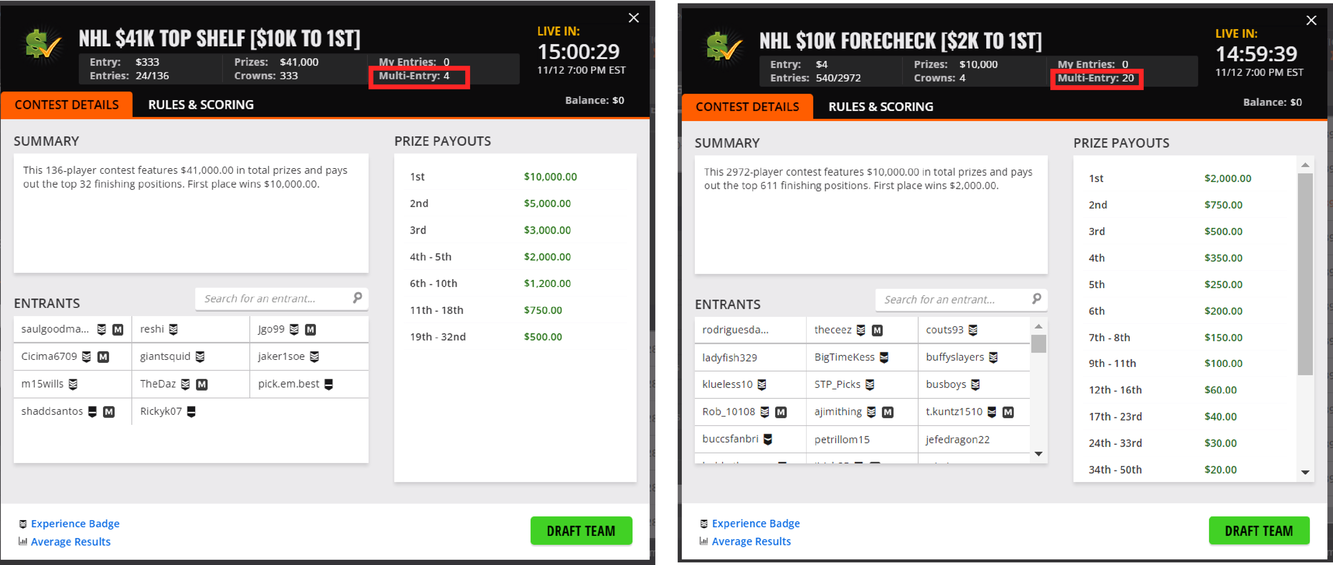
While it is natural to submit as many entries (lineups) as possible in the game, we note that there is a trade‐off between the entry fee and the number of lineups. Hence, it is useful to find a smaller number of lineups with competitive performance. This is particularly relevant, especially for contests with a maximum number of multiple lineup restrictions and high entry fees. As shown in Figure 4, games may restrict the maximum number of lineups. The left one only allows four entries, while the right one allows at most 20 entries. In this case, the ability to generate a moderate number of lineups with high‐quality performance in a reasonable amount of time becomes critical. More examples can be found at https://www.draftkings.com/. For the model formulation and parameters estimations parts, we refer the readers to Appendix EC.6.2 in the Supporting Information.
Two examples which set a maximum number of multiple lineup restrictions.
Preprocessing technique
In practice, because there are often hundreds of potential athletes in each contest, it is time‐consuming and not practical to use the sequential optimization method to construct the lineups directly using this universal set of athletes. As shown in Table EC.4 in the Supporting Information, the universal set includes from 123 to 474 athletes for the 10 scenarios we tested. To overcome this problem, we use a simple preprocessing technique to reduce the number of candidate athletes for our method; that is, we simply select the top
athletes based on their projected scores. The reason we do not select players proportionally is that the size of the universal set is different for different contests, which would lead to a huge difference in computation time if we were submitting the same number of lineups in every contest.
Here, we describe how we tune parameter
based on both the solution quality (i.e., objective function) and computational efficiency (i.e., CPU times). In other words, we want to determine an appropriate
that will allow us to generate good solutions with minimal computational time. To do this, we first solve 10 scenarios with
to construct a solution with
lineups. Experiments with other choices of m show a similar trend. We use “BNB” in YALMIP to solve the mixed 0–1 SDP. In YALMIP, the gap is defined as
, where UB and LB represent the upper and lower bounds in the branch‐and‐bound algorithm. We set the termination gap as 5% to reduce the CPU times in each iteration of the sequential optimization algorithm.
Figure 5a reports the average performance, that is, objective and CPU times, for obtaining five lineups across 10 instances. The objective value increases gradually up till
, after which adding more players to the candidate set no longer improves the performance. This is caused by the 5% gap in the termination criterion in each iteration. As shown in Figure 5b, the optimality gaps in each iteration obtained under the case
are larger than those achieved under the case of
or lower. We, therefore, select
for the computational experiments performed later. This helps to reduce the computational times, without adversely affecting the solution quality. In practice, as mentioned in Hunter et al. (2017), the goalie information may only be made available about 30 min before games begin, and ideally one should be able to select all the lineups within that time window. This preprocessing technique helps to ensure that our method can generate sufficient lineups within 1800 s. For the detailed results on the 10 instances, we refer the readers to Appendix EC.6.3 in the Supporting Information.
Results of preprocessing technique. The left one reports the average objective and total CPU times for five lineups across 10 instances with
. The right one shows the optimality gaps in each iteration. CPU, central processing unit.
Comparison with two benchmarks
We compare the performance of our method with two existing benchmarks. The first one is Hunter's method (Hunter et al., 2016) (see Appendix EC.3.3 for more details in the Supporting Information). The second one is a genetic algorithm (GA) proposed by Jarvis Nederlof (see https://levelup.gitconnected.com/dfs‐lineup‐optimizer‐with‐python‐296e822a5309). We solve the solutions for the two benchmarks using all the athletes in the ground set. For our method, we select the 45 athletes with the highest projected scores.
We vary the size of lineups m from 1 to 20 in each scenario. When calculating the out‐of‐sample performance, we assume the true distribution is a multivariate normal distribution,
. Note that here the estimated mean of each selected athlete is set as the mean μ of the true distribution. Similarly, the estimated standard deviation of each selected athlete and the estimated correlation matrix together form covariance matrix Γ of the true distribution. Fifty thousand samples are generated to calculate the average score of the top‐performing lineup and winning probability.
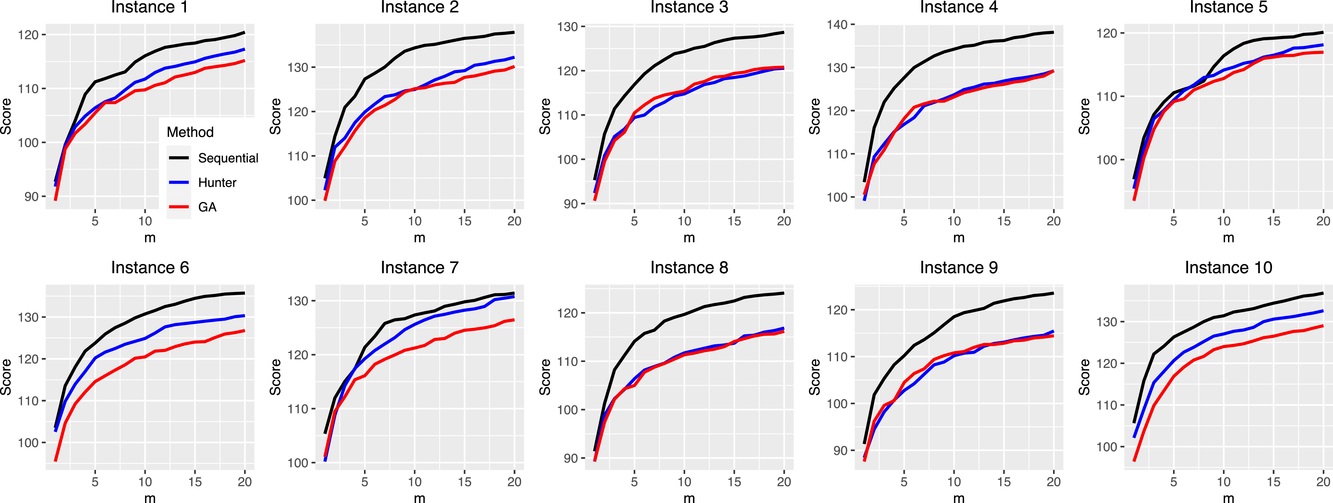
Figures 6 and 7, respectively, report the results of the fantasy score comparisons and the improvement in the winning probability. Our method significantly outperforms the other two benchmarks in terms of various metrics. Specifically, our method produces solutions with the highest score among the three methods in all the 10 scenarios tested when
. Interestingly, the improvement in the fantasy score actually increases as the portfolio size increases. This indicates that the advantage of our sequential optimization method becomes more significant as m increases.
Results of fantasy score comparisons using daily fantasy hockey contests.
Results of winning probability improvement (%) using daily fantasy hockey contests.
To ensure that the outstanding performance of our method originates from the model itself, rather than the selection of the candidate athlete set, we also restrict the ground set for the two benchmarks to the same athlete set as ours (i.e., 45 athletes). Figure 8 plots the fantasy scores obtained by the three methods using 20 lineups. Our method dominates the two benchmarks comprehensively. Note that the Hunter method cannot obtain 20 lineups in some instances because of the hard‐coded overlap constraint used in their approach to diversify the portfolio of solutions. For the detailed results, we refer readers to Appendix EC.6.5 in the Supporting Information.
Results of fantasy score comparisons between our method and two benchmarks with
. Here we solve the two benchmarks using the whole athlete set and 45 athletes, respectively.
To show the competitiveness of our model, we also compare our method for
, with the other two benchmarks using more than 20 lineups. That is, we solve the two benchmarks for
lineups. Figure 9 reports the average performance across 10 instances. For the average fantasy score, we observe that our method with 20 lineups can outperform Hunter's method with 50 lineups and is on par with GA with about 70 lineups. Furthermore, our average score is 5.37 points higher than that of Hunter's method with 20 lineups and only 2.60 points smaller than that of Hunter's method with
.
Comparisons between our sequential optimization method with
and two benchmarks with
. The left figure reports the average score, and the right one presents the average winning probability improvement (%), that is, ΔP, across 10 instances.
We observe that the initial set of lineups can be augmented easily with other lineups to deliver superior performance in this problem. To this end, we develop a hybrid algorithm that combines our sequential optimization algorithm and the GA method. Specifically, we generate the first 20 solutions using the sequential optimization algorithm and add the other solutions using the GA proposed by Jarvis Nederlof. In this way, we can obtain many solutions in a reasonable time. We compare this hybrid method with the other two benchmarks with
. Figure 10 reports the average performance across 10 scenarios. We observe that the hybrid algorithm outperforms the other two benchmarks in a comprehensive manner—the initial set of lineups is fundamental to the performance of any algorithm that constructs the full lineups using an incremental method. Our sequential optimization algorithm is particularly useful in this regard. In fact, using an additional 20 lineups constructed using the GA, our hybrid method using 40 lineups can already perform as well as the two benchmarks using 100 lineups.
Comparisons between the hybrid algorithm (sequential optimization method + GA) and two benchmarks with
We use the concept of cosine similarity between two bets to measure the diversity effect. This approach is widely used in the machine learning field. Formally, if the candidate set contains n athletes, for any two lineups i and
, their similarity is defined as,
. Based on this, we can define the diversity of ith lineup in the portfolio as
, where “9” denotes the total number of athletes selected in each lineup.
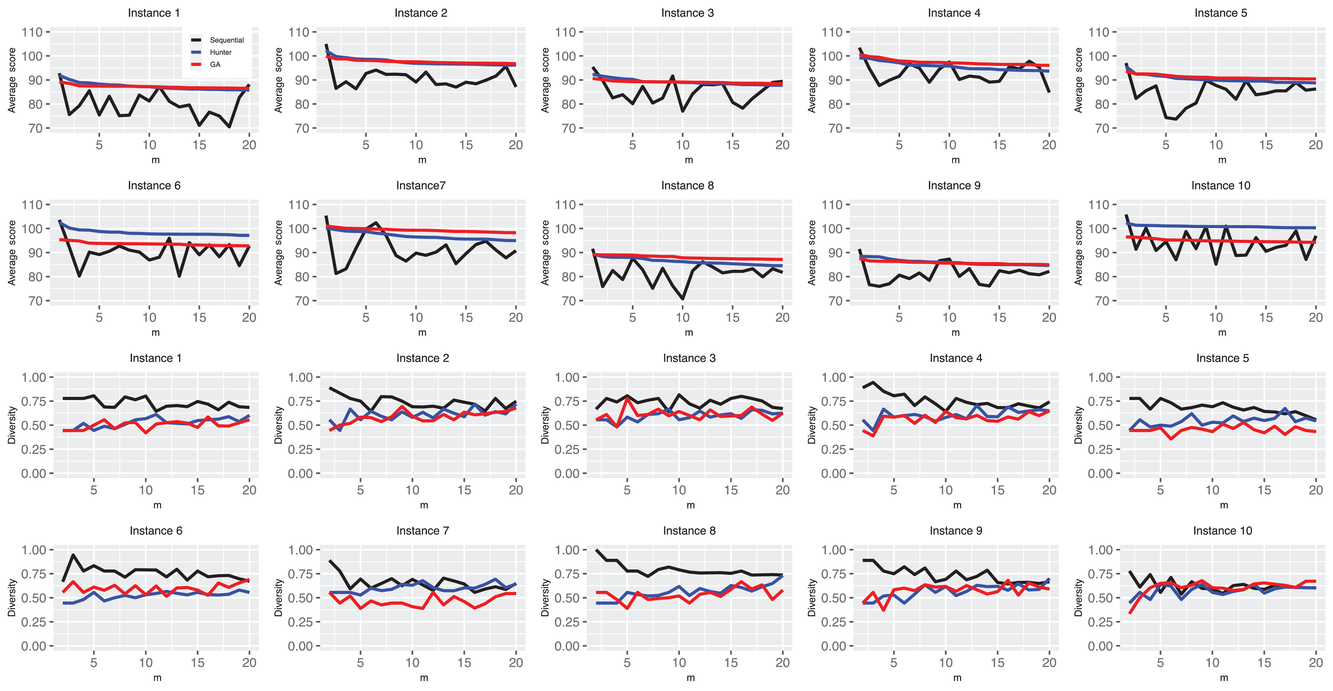
Figure 11 shows the average scores and diversity results for each added lineup. Remarkably, each of our added lineups attains (i) a higher degree of diversity (with the previous lineups) compared with that of the two benchmarks but (ii) each achieves a smaller average fantasy score. This result shows that the existing benchmarks focus more on the marginal score of a lineup for selection, at the expense of diversity, whereas our method focuses more on exploiting the diversification effect, at the expense of individual scores. The former leads to a higher average fantasy score for each added lineup, but the latter has better out‐of‐sample performance for the picking winners problem. In other words, our method improves the portfolio's performance by better exploiting the diversification effect.
The results of average scores and diversity for each added lineup. The top 10 graphs report the individual out‐of‐sample performance of each added lineup and the bottom 10 to show the diversity between the lineup added each time and the lineups already in the portfolio.
Note that the method in Hunter et al. (2016) handles diversification using a constraint to limit the amount of overlap with previous lineups selected. For current lineup i
, and any previous lineup from 1 to
, they add the constraint,
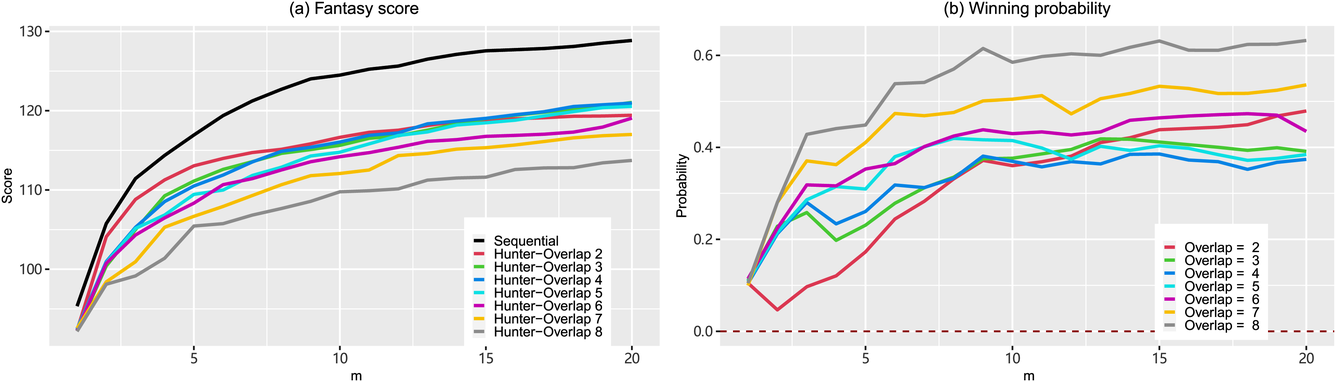
They control the degree of diversification effect by adjusting γ. Next, we vary γ from 2 to 8 in game scenario 3, to investigate how the Hunter method captures the diversification effect. This demonstrates the advantage of our method, in which the diversification effect comes naturally from the model setup. Figure 12 shows the comparison results between our method and the Hunter method with different overlap levels. We can observe that no matter how we control the overlap level, the Hunter method cannot beat our method with the same lineup size.
Comparisons between our sequential optimization method and Hunter's method with different overlaps, that is, γ. The left figure reports the average score, and the right one presents the winning probability improvement, that is, ΔP.
CONCLUDING REMARKS
In this study, we examine portfolio construction under the picking winners framework. Motivated by the good performance of the evil twin strategy in the construction of two‐solution portfolios, we derive a general approach to exploit the diversification effect using a moment‐based two‐stage distributionally robust model. Although this basic framework can be relaxed as a mixed 0–1 SDP, solving an optimal portfolio is still intractable because of the SDP's high dimensionality. To address this issue, we provide a compact reformulation with a lower dimensional SDP. We used these models to “recover” the (partial) evil twin strategy under appropriate settings. To scale up the performance of our approach, we design a sequential optimization method based on the compact formulation. Extensive numerical experiments for sports betting pools and daily fantasy sports using real data demonstrate the superiority of our method compared to the existing benchmarks. The computational results for daily fantasy sports show that our moment‐based model can better exploit the diversification effect compared with other heuristics, thus yielding better out‐of‐sample performance. This implies that adding the diversification effect in building portfolio solutions can help to reduce the risk of uncertainty and thus improve the chances of winning under the framework of the picking winners problem.
The method we propose is not limited to sports betting pools and daily fantasy sports but can be applied to any industry facing a similar portfolio construction problem with a “high reward, low probability” winner‐take‐all structure. Our work can be extended in several directions. One direction is to consider the opponents' behavior when building multiple solutions under the picking winners framework (Haugh & Singal, 2021). This would provide additional insights into the portfolio construction problem and help in building better solutions. Furthermore, the techniques developed in this study can contribute to other related fields, such as product line (Bertsimas & Mišić, 2017) and bundle design (Li et al., 2022). Specifically, the sequential optimization framework based on a low‐dimensional mixed 0–1 SDP can also be applied to the design of product lines or product bundles under appropriate problem settings. We leave these extensions for future research.
Footnotes
ACKNOWLEDGMENTS
The authors gratefully thank the review teams for their constructive comments to improve the paper. This research is supported by the Natural Science Foundation of Chongqing, China (Grant No. CSTB2022NSCQ‐MSX1667), National Research Foundation, Singapore and A*STAR, under its RIE2020 Industry Alignment Fund—Industry Collaboration Projects grant call (Grant No. I2001E0059), and the National Natural Science Foundation of China (Grant No. 71904021).
ORCID
Changchun Liu
References
1.
AhsanullahM.NevzorovV. B. (2005). Order statistics: Examples and exercises. Nova.
2.
AshraphijuoM.FattahiS.LavaeiJ.AtamtürkA. (2016). A strong semidefinite programming relaxation of the unit commitment problem. In 2016 IEEE 55th conference on decision and control (CDC) (pp. 694–701). IEEE.
3.
BeckerA.SunX. A. (2016). An analytical approach for fantasy football draft and lineup management. Journal of Quantitative Analysis in Sports, 12(1), 17–30.
4.
BeliënJ.GoossensD.Van ReethD. (2017). Optimization modelling for analyzing fantasy sport games. INFOR: Information Systems and Operational Research, 55(4), 275–294.
5.
BenderE. A. (2013). Betting on football pools. https://mathweb.ucsd.edu/∼ebender/87/pools.pdf
6.
BergmanD.CardonhaC.ImbrognoJ.LozanoL. (2023). Optimizing the expected maximum of two linear functions defined on a multivariate Gaussian distribution. INFORMS Journal on Computing, 35(2), 304–317.
7.
BermanA.Shaked‐MondererN. (2003). Completely positive matrices. World Scientific.
8.
BertsimasD.DoanX. V.NatarajanK.TeoC.‐P. (2010). Models for minimax stochastic linear optimization problems with risk aversion. Mathematics of Operations Research, 35(3), 580–602.
9.
BertsimasD.MišićV. V. (2017). Robust product line design. Operations Research, 65(1), 19–37.
10.
BertsimasD.NatarajanK.TeoC.‐P. (2006). Tight bounds on expected order statistics. Probability in the Engineering and Informational Sciences, 20(4), 667.
11.
BomzeI. M.DürM.De KlerkE.RoosC.QuistA. J.TerlakyT. (2000). On copositive programming and standard quadratic optimization problems. Journal of Global Optimization, 18(4), 301–320.
12.
BrownM.SokolJ. (2010). An improved LRMC method for NCAA basketball prediction. Journal of Quantitative Analysis in Sports, 6(3), 1202.
13.
BurerS. (2009). On the copositive representation of binary and continuous nonconvex quadratic programs. Mathematical Programming, 120(2), 479–495.
14.
CaudillS. B. (2003). Predicting discrete outcomes with the maximum score estimator: The case of the NCAA men's basketball tournament. International Journal of Forecasting, 19(2), 313–317.
DeStefanoJ.DoyleP.SnellJ. L. (1993). The evil twin strategy for a football pool. The American Mathematical Monthly, 100(4), 341–343.
17.
DürM.StillG. (2008). Interior points of the completely positive cone. The Electronic Journal of Linear Algebra, 17, 48–53.
18.
El‐AriniK.VedaG.ShahafD.GuestrinC. (2009). Turning down the noise in the blogosphere. In Proceedings of the 15th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 289–298). ACM.
19.
FryM. J.LundbergA. W.OhlmannJ. W. (2007). A player selection heuristic for a sports league draft. Journal of Quantitative Analysis in Sports, 3(2), 1–35.
20.
GaoS. Y.Simchi‐LeviD.TeoC.‐P.YanZ. (2019). Disruption risk mitigation in supply chains: The risk exposure index revisited. Operations Research, 67(3), 831–852.
21.
HanasusantoG. A.KuhnD. (2018). Conic programming reformulations of two‐stage distributionally robust linear programs over Wasserstein balls. Operations Research, 66(3), 849–869.
22.
HaughM. B.SingalR. (2021). How to play fantasy sports strategically (and win). Management Science, 67(1), 72–92.
23.
HunterD. S.SainiA.ZamanT. (2017). Picking winners: A data driven approach to evaluating the quality of startup companies. arXiv. https://doi.org/10.48550/arXiv.1706.04229
24.
HunterD. S.VielmaJ. P.ZamanT. (2016). Picking winners in daily fantasy sports using integer programming. arXiv. https://doi.org/10.48550/arXiv.1604.01455
25.
KaplanE. H.GarstkaS. J. (2001). March madness and the office pool. Management Science, 47(3), 369–382.
26.
KhullerS.MossA.NaorJ. S. (1999). The budgeted maximum coverage problem. Information Processing Letters, 70(1), 39–45.
27.
KingN. A. (2017). Predicting a Quarterback's fantasy football point output for daily fantasy sports using statistical models (Doctoral dissertation). University of Texas at Arlington.
KvamP.SokolJ. S. (2006). A logistic regression/Markov chain model for NCAA basketball. Naval Research Logistics, 53(8), 788–803.
30.
LiX.SunH.TeoC. P. (2022). Convex optimization for bundle size pricing problem. Management Science, 68(2), 1095–1106.
31.
MehtaA.NadavU.PsomasA.RubinsteinA. (2020). Hitting the high notes: Subset selection for maximizing expected order statistics. Advances in Neural Information Processing Systems, 33, 15800–15810.
32.
NatarajanK.TeoC.‐P. (2017). On reduced semidefinite programs for second order moment bounds with applications. Mathematical Programming, 161(1), 487–518.
33.
NatarajanK.TeoC. P.ZhengZ. (2011). Mixed 0‐1 linear programs under objective uncertainty: A completely positive representation. Operations Research, 59(3), 713–728.
34.
RobinsonC. (2020). The prediction of fantasy football (Mathematics Senior Capstone Papers. 20). Louisiana Tech University. https://digitalcommons.latech.edu/mathematics‐senior‐capstone‐papers/20
35.
ScarfH. E. (1957). A min‐max solution of an inventory problem. Santa Monica: Rand Corporation.
36.
SheraliH. D.AdamsW. P. (2013). A reformulation‐linearization technique for solving discrete and continuous nonconvex problems. Nonconvex Optimization and Its Applications, Vol. 31. Springer Science & Business Media.
37.
SummersA. E.SwartzT. B.LockhartR. A. (2007). Optimal drafting in hockey pools. Chapman and Hall/CRC.
38.
XuG.BurerS. (2018). A copositive approach for two‐stage adjustable robust optimization with uncertain right‐hand sides. Computational Optimization and Applications, 70(1), 33–59.
39.
XuH.LiuY.SunH. (2018). Distributionally robust optimization with matrix moment constraints: Lagrange duality and cutting plane methods. Mathematical Programming, 169(2), 489–529.
40.
YanZ.GaoS. Y.TeoC. P. (2018). On the design of sparse but efficient structures in operations. Management Science, 64(7), 3421–3445.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.