
Abstract
Limited information about the demand for some of the resources needed to produce goods and services (e.g., incomplete and imperfect bills of materials) forces firms to use heuristics when planning resource capacity. We examine the performance of five heuristics: two drawn from practice, two that modify observed approaches, and one motivated by theory. We measure performance as the ratio of the expected cost of supply–demand mismatch from using a heuristic to the value in the full‐information solution. Numerical analysis shows that a simple heuristic that is common in practice—plan rigorously for a few “driver” resources with high‐quality information and use ratios (e.g., 0.25 indirect labor hours per machine hour) to project the capacities for the remaining “non‐driver” resources—is robust and efficient. Using more than one driver resource to plan for the same non‐driver resource delivers significant gains. Reducing measurement error with respect to the consumption of driver resources dominates the gain from reducing errors in other aspects. Indeed, with high measurement error, collecting information that reduces other sources of error could decrease overall performance. Finally, a greedy algorithm of choosing the most expensive resources as drivers is optimal.
Keywords
INTRODUCTION
Resource planning—how much of a resource to stock to meet uncertain demand—is a central problem in operations. Firms decide on inventory levels, and caterers figure out how much food to prepare and staff to provide for a reception. While the classic newsvendor formulation (Morse & Kimball, 1951) provides an elegant solution, difficulties in measuring opportunity costs and estimating resource demand distributions confound its application. The problem is acute when decision makers must plan for multiple resources simultaneously and when demands are correlated. An example is a firm setting up a factory to make many products with a common set of resources. Similarly, deciding on inventory levels of offerings within a product line requires consideration of how they affect each other's demands. The research 1 on applying the newsvendor problem to such complex settings typically assumes that the decision‐maker has complete information regarding problem parameters. We add to this literature by considering the effects of limited information: How to plan for resource capacity when firms know the demand distribution of only a subset of resources?
Settings with limited information are ubiquitous. When a firm plans a new production facility, it is likely to have good demand estimates for some resources such as materials, machines, and labor but coarser data for other resources such as the tool crib and production supervisors. A restauranteur might have a good sense of the number of waitstaff needed for the anticipated volume, but not the number of dishwashers and other support resources. In the context of planning inventories, an incomplete bill of materials (BOM) raises similar concerns. 2
With limited information, the decision maker has no choice but to extrapolate known data to fill in gaps. A review of practices suggests that firms first pick the capacities of their high‐value resources—the number of machines, server capacity, or the number of wait staff—for which they obtain good demand data. They then employ heuristics to estimate the capacities required for other resources for which they have coarser information. 3 A restaurant might use a rule of thumb such as hire one dishwasher and one kitchen helper for every six waiters. A manufacturing firm might plan for 100 maintenance hours per 10,000 h of operation and hire one technician for each 1000 h of maintenance. Facebook reports that it needs one engineer per million active users and that it uses such ratios to plan the capacities of other resources as well (Miller, 2009). Our first research question is therefore “what are the relative and absolute performances of some observed heuristics in the context of capacity planning?” Relatedly, we ask “whether we could identify improvements to the observed rules of thumb.” Finally, the performance of any heuristic likely improves if the quantity and/or quality of available information increases. Our third research question therefore is “how do the quantity and quality of available information affect the relative and absolute performances of observed capacity planning heuristics?” We examine these practically important questions using a rigorous framework. Our goals are to provide insight into the efficacy of current practices, identify factors that affect their performance, and develop implementable approaches for improving capacity planning.
We use simulations (as in Anand et al., 2017; Balakrishnan et al., 2011) to help compare heuristics’ performances while holding all other factors constant and to gain insight into the drivers of performance. We consider a firm that uses a common set of resources to make several products with uncertain demand. As in Banker and Hughes (1994), we assume Leontief technology to map product demand distributions to resource demand distributions via a consumption matrix. Each element in this matrix is the quantity of resource i required to make one unit of product j. This mapping is akin to a BOM that translates product demand to the demand for resources. The goal is to determine the advance purchase quantity of each resource that minimizes the expected costs of meeting realized demand.
We model limited information as the firm having incomplete and imperfect knowledge of the BOM. That is, it knows the values for only a subset of rows and the known values contain measurement error. In an inventory planning context, the BOM is “fuzzy” (Guillaume et al., 2013), forcing the use of heuristics.
We examine three kinds of heuristics: ratio‐based point estimates, methods that include information about opportunity costs, and distributions fit to available data. We draw the first two methods from the practitioner literature and theoretically motivate the third approach. We examine two variations of the practice‐based methods in ways that potentially enhance performance efficiency (thus, we examine five heuristics in total). We investigate generalizability by systematically varying the quantity and quality of information available for executing the heuristics. We examine robustness by varying the parameters of the production technology and resource costs. Our major findings are as follows.
Absent measurement error, ratio‐based point estimates yield costs that are ∼109% of the costs attainable with full information. We note that these ratio‐based heuristics resemble the core feature in cost accounting systems, wherein firms model the consumption of “non‐driver” or support resources by assigning each such resource to a “driver” resource to form cost pools. The entire cost of resources in a cost pool is then allocated to products in proportion to the consumption of the driver resource. Similarly, a ratio‐based heuristic estimates the demand for a non‐driver resource as being proportional to that of a driver resource (e.g., one kitchen helper for every six waiters).
Augmenting ratio‐based heuristics by including information about opportunity costs, as in inventory planning models, increases performance measurably. Data show that this approach yields results that are comparable to the gains available from the sophisticated statistical method of directly fitting a distribution to observed historical data about resource demand.
A “dual‐driver” costing system is one in which a firm uses two drivers to model the consumption of each non‐driver resource. We find that modifying observed heuristics to include dual drivers leads to gains in cost efficiencies and that the gains are pronounced when resource costs are diffuse. This finding is consistent with the argument in Balakrishnan et al. (2004), who develop a conceptual argument, and Balakrishnan et al. (2011), who demonstrate the idea empirically, for using indexed drivers in cost accounting systems. However, data also show that information‐based approaches (i.e., including opportunity costs) dominate mechanical improvements (e.g., dual drivers).
We next examine the effects of the quality and quantity of information available to the firm on performance. With zero measurement error, increasing the precision of the information that translates the demand for driver resources to the demand for non‐driver resources (specification error in the terminology of Datar & Gupta, 1994) only has a small, albeit positive, effect. 4 Moreover, consistent with prior research (e.g., Balakrishnan et al., 2011), the benefit of increasing the total amount of information (i.e., knowledge about the BOM or aggregation error) tapers off rapidly. Measurement error has a large and convex impact on performance and is the dominant force.
Measurement error has a significant interaction effect with problem size and the precision of information relating driver and non‐driver resources. With sufficient measurement error (10%–15% with our set of parameters), system performance could decline as we increase the precision of available information (regarding the ratios) and/or increase the quantity of available information (the number of driver resources). Thus, our data support the theoretical conjecture that errors in cost systems offset and that improving one dimension alone might worsen performance. Taken together, these findings suggest that firms would be well‐advised to focus their efforts on refining the estimates of the demand distributions (i.e., reducing measurement error) for a handful of driver resources.
We examined alternate ways to select driver resources, given their centrality in the problem we consider. We find that a greedy algorithm of picking the most expensive resources, an approach consistent with practice, yields the best performance. This finding reinforces related results found in other contexts (e.g., Bassok et al., 1999; Biller et al., 2005).
Our findings are robust to variations in the parameters of the simulation model such as the density of the BOM matrix, methods for grouping non‐driver resources with driver resources, and the relative distribution of costs over resources.
Our findings contribute to the operations management and cost accounting literatures. We add to the operations literature on resource planning by considering the effects of limited information. We provide guidance to organizations that struggle with the consequences of an incomplete BOM (Francis et al., 2007; González et al., 2013; Peng & Nunes, 2009; Stentoft et al., 2015). We also add to the accounting literature on the design of product costing systems (Labro, 2019). Our innovation is to consider limited information in a different context—capacity planning for support resources. We find that many of our findings echo those in the product costing literature enhancing their generalizability.
MODEL
The firm
We model a one‐period firm
5
as a process that transforms I resources to produce J outputs. Let
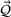
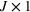
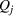
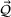
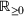
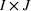
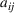
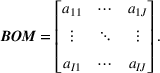
Let
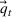
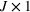
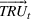
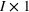
Input markets are perfectly competitive. Let
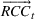
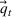
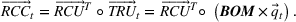
This formulation captures settings such as a restaurant deciding on staffing levels, a bakery selling many varieties of baked goods using a recipe to estimate the ingredients needed, a manufacturer using a routing sheet to estimate machine hours needed to make its many products, and a bank using activity sheets to decide on the number of tellers. We note that the firm's operations and accounting systems will document the total consumption of each resource even if the firm does not know the usage of any given resource by a specific product. That is, these systems provide values for
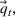
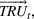
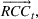
Opportunity costs
For many resources such as buildings, staffing, machinery, and raw meat in a restaurant, cost efficiencies motivate firms to purchase capacity ahead of knowing demand. Let
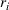
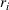
Many sources shape the opportunity costs associated with overstocking (understocking) resources. Salvage values and proceeds from distress sales reduce the costs of overstocking. In a multiperiod formulation, the cost of overstocking would include holding costs. The cost of understocking includes reputational losses in addition to any contribution margin lost by not being able to meet demand. Any ability to change prices affects opportunity costs because such adjustments alter product demand and thereby affect resource demand. Finally, while firms could adjust ex post the capacity for some resources (e.g., hire temporary labor or sell unneeded materials), it is impossible to adjust the capacity of others (e.g., rooms in a hospital, seats in a movie theater, size of an oven in a bakery). The level of flexibility (i.e., the extent of hard vs. soft capacity constraints) in adjusting capacity levels ex post affects the opportunity costs of understocking resources.
To keep our focus on capacity planning, we model opportunity costs in a general way rather than consider a specific contextual setting. We follow Banker and Hughes (1994) and make three assumptions. First, firms can purchase additional capacity for any resource i at a premium price after observing realized demand. Formally, let
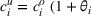
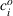
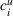
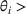
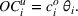
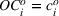
Full information
For our benchmark setting, we assume knowledge of the entirety of the BOM (
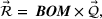
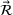
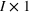
Let
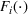
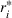
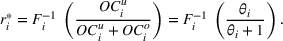
Thus, with full information, the firm can compute the optimal capacity level for every resource, that is, the first‐best capacity.
The model developed in Equations (1)–(5) is versatile and could represent many real‐world settings. For example, if the
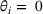
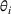
Limited information
We introduce a role for information as the firm having imperfect and incomplete information about the matrix
Imperfect information arises because of measurement errors in estimating the pattern of resource consumption (the elements in
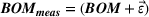
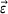
Incomplete information arises because, in practice, firms know the consumption of only some resources—we term these driver resources—by product. 7 Resources that represent variable costs are good examples of driver resources. A manufacturer would have excellent information about the material and labor needs for each of its products. A recipe provides the input–output ratios for baked goods and helps decisions about the amount of flour to stock. The firm may also have insight into the demand for some resources shared across products. Engineers can supply the times required for machining operations, chefs can estimate cooking times, and banks can project the average mix of services in a day when determining the demand for tellers. In contrast, consumption of other resources cannot be observed on a per‐unit basis (e.g., see Anand et al., 2017; Chen‐Ritzo, 2006). These non‐driver resources are items such as the amounts of coolants required in a machine shop, tool oil used, the number of helper staff in a kitchen, the number of technicians in the maintenance department, and computing resources. We focus on how limited information influences the way firms plan the capacities for these non‐driver resources.
We operationalize driver and non‐driver resources as a firm having knowledge about the values of the elements in some, but not all, rows of the matrix

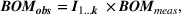
The relative proportions of driver and non‐driver resources (the fraction
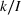
Extrapolating historical information
Because of incomplete information, firms must extrapolate the information about driver resources to determine the capacities for non‐driver resources. Such extrapolation is possible if the firm has produced related products before, its existing technology is similar enough, 8 and/or the employees have industry knowledge or relevant human capital. In the case of innovative technology, this knowledge might just be an educated guess. This approach of extrapolating known information to fill in gaps has a striking similarity with cost accounting systems found in all organizations. These systems employ a “cost driver” (with known consumption patterns) to allocate the costs of “indirect” resources (with unknown consumption patterns) to cost objects such as products.
Of course, the precision of the information relating driver and non‐driver resources will vary across production technologies and contexts. A firm replicating an existing facility to augment capacity would have excellent information on the relation between resource configurations and usage. Building a newer model using data from an existing application (as in making a next generation of a camera or car) or implementing the next generation of technology (as in making electronic chips) will erode precision. Input from industry experts could help increase accuracy. 9 An experienced restauranter can generate an excellent estimate of the number of waitstaff needed when provided with the number of tables and the target service level.
As with opportunity costs, we take a simple approach to model the information that relates driver and non‐driver resources. For a past period, the firm will know realized demand for its products. Accounting records provide the aggregate amounts of each resource consumed. Thus, the firm can compute ratios that relate the consumption of all pairs of driver and non‐driver resources. If it has data for many periods, the firm will have a distribution of the ratio for each pair. These ratios will differ across periods because of variations in realized demand for the products and thus the consumption of resources. The firm could use a summary statistic such as the mean of the distribution of ratios or use other statistical methods to estimate the “true” ratio of relative consumptions.
Formally, we suppose that a firm maintains a database of past product demand vectors,
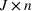
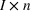
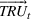
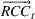
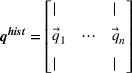
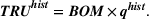
We chose this model of information precision because it helps us emphasize the links between accounting information and resource planning. The informational foundations of this approach are consistent with practice and with financial accounting. Specifically, because they expend money to acquire specific resources, firms observe the consumption of each non‐driver resource in the aggregate after production has occurred. A firm would know that it consumed 1.3 megawatts of electricity even if it does not know the electricity consumption by product. Stated differently, even though the firm can only observe some rows of
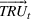
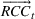
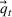
In sum, we characterize the limitations in available information along three dimensions. The ratio of driver resource cost to total resource cost defines the scope of the problem (i.e., the amount of available information) in planning the capacities of non‐driver resources. Measurement error relates to the confidence we have in our estimates of how products use driver resources. Finally, precision is the confidence we have in our estimates of the relation between the usage of driver and non‐driver resources.
Heuristics considered
We consider five heuristics for choosing the capacity levels of non‐driver resources. We choose two from practice. We develop two that seek to improve on practice‐based approaches and construct one based on theory.
Heuristics 1 and 2: Point estimates with one or more drivers
In our model, the firm's accounting system provides the values in the vector
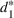
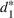
The use of indexed drivers in cost accounting (e.g., Babad & Balachandran, 1993; Balakrishnan et al., 2011; Homburg, 2001) motivates the improvement proposed in the Point2 heuristic. An indexed or synthetic driver is the weighted average of the allocation percentages from two or more primitive cost drivers. For example, we could allocate tooling costs using a synthetic driver that averages machine hours and labor hours. In the context of capacity planning, this refinement is akin to using both the magnitude and the intensity of use (e.g., size of a dorm in square feet and the number of students to estimate the needs for janitorial staff). That is, we use the ratios from multiple driver resources to “triangulate” the purchase quantity of the non‐driver resource. Let r
1 be the ratio between the consumption of a non‐driver resource and to that of driver resource #1, for which the firm optimally acquires
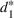
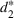
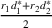
Heuristics 3 and 4: Incorporate information about opportunity costs, with one or more drivers
The point heuristics ignore information about the opportunity costs associated with non‐driver resources, which firms typically possess. Thus, we explore the gain from including this information in a heuristic. Observed stocking policies support the inclusion of opportunity costs into capacity planning. Firms buy resources with small spot market premiums (e.g., oils and coolants, wood glue for a cabinet maker) on an as‐needed basis. In contrast, they plan for “unused capacity” in resources such as design engineering time that are harder to augment on an as‐needed basis. At an extreme, a two‐bin strategy is a prudent way to have large stocks of low cost but critical items that are not easily replenished (e.g., specialized screws used in electronic equipment such as mobile phones).
In the Dist1 heuristic, we derive a distribution for the non‐driver resource as a transformation of the demand distribution for the relevant driver resource. Suppose the demand for a driver resource follows some distribution
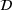
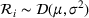
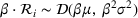
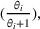
As with the point ratios above, the firm could improve or triangulate using multiple driver resources (i.e., compute two implied demand distributions). For the Dist2 heuristic, we compute the quantity for a non‐driver resource using two different driver resources by solving the newsvendor problem for each, independently. We average the two solutions to determine the quantity to acquire.
Heuristic 5: Fit a distribution
The point and the derived distribution heuristics require that the firm specify at least one driver resource for each non‐driver resource. That is, these heuristics require the firm to form cost pools by associating every non‐driver resource with a driver resource. The distribution heuristic also limits the distribution to be a transformation of the associated driver demand distribution. Theory offers a way to relax both requirements with sufficient data on the firm's history. Using the vector of realized demand for each non‐driver resource, the firm could use a distribution fitting method, such as kernel density estimation (KDE), to directly estimate the distribution of each non‐driver resource. Of course, the firm must specify the functional form of the distribution to be fitted, and the number of available observations influences the quality of the fit. It can then formulate and solve a newsvendor problem, employing the resource‐specific costs of advance and premium purchases.
SIMULATION PROTOCOL
We conduct a simulation to ascertain the efficiency of the heuristics described earlier. A simulation is appropriate here because, given the interlinked nature of resource consumption, the equations of this system cannot be solved in closed form (Anand et al., 2017). Additionally, the simulation permits flexibility in parameter choices, allowing us to model a wide range of parameter combinations.
Setup
We define a firm by (1) a set of products it makes and a known demand distribution for each; (2) a set of resources, as well as the pre‐production unit cost of each resource and a premium for spot purchases; and (3) a consumption or
We create a random sample of 1000 firms. Each firm sells 20 products, with normally distributed and independent demands. For each product, we draw the mean demand from discrete U(10, 40) multiplied by a randomly chosen integer from discrete U(3, 10). We draw the coefficient of variation from U(0.1, 0.3) and multiply it by the mean to obtain the standard deviation. This method for choosing the parameters permits realized demand to be positive with better than 99% probability.
Each firm has 50 resources in total, and each product uses a subset of these resources. The We randomly choose a resource density parameter, the percentage of cells with a non‐zero entry, from We require that each product consumes at least one resource and that each resource is consumed by at least one product (i.e., no rows or columns are all zero in the Based on producing mean demand, we impute resource costs so that the spending on the top 10 resources accounts for a percentage of the total spending (i.e., resource cost dispersion) that is drawn from Given the values for resource density and the dispersion in resource costs, and the production constraints, we follow the method in Balakrishnan et al. (2011) to determine the individual cell entries in the We draw the spot purchase premium for each resource from
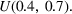
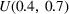
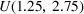
Table 1 supplies descriptive statistics that contextualize the above environments. The average product uses 28.1 of the 50 possible resources, with a range from 11 to 45 resources (untabulated). Likewise, the average resource is used by 11.2 of the 20 possible products, with a range from 1 to 20 (untabulated). We find limited evidence of co‐movement in resource usage at the product level. We compute pair‐wise correlation (across products or rows of the
Descriptive statistics: Bill of materials.
Note: This table provides descriptive data about the BOM (
Number of resources used by average product (Average number of products using a resource) is the average number of non‐zero entries in each column (row) of the
In sum, we allow for a wide variation in base parameters. 10 Moreover, the range of parameters we employ is identical to that employed in prior research (Anand et al., 2017, 2019; Balakrishnan et al., 2011), which has employed a similar methodology.
Full‐information solution (first best)
Using the vector of product demand distributions 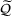
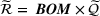
For each firm, we compute the total advance capacity cost, expected spot capacity cost, expected spot premium paid, and expected cost of supply–demand mismatch (expected cost of spot purchases plus expected cost of leftover inventory). These are the “first best” or full‐information costs that serve as the benchmarks for later comparisons.
Limiting available information
For each of the 1000 simulated firms, we manipulate three items: the number of driver resources, which determines the scope of the information problem; the magnitude of measurement error in estimating the usage of driver resources; and the length of history that influences the precision of the information that relates driver to non‐driver resources.
We vary the number of driver resources at three levels: three, five, and 10. The greater the number of driver resources, the less severe the firm's information problem because the number of non‐driver resources decreases to 47, 45, and 40 (all firms have exactly 50 resources). We often refer to the number of driver resources as the number of cost pools. Surveys show that most firms have fewer than 20 drivers (Babad & Balachandran, 1993).
We vary the extent of measurement error in estimating the usage of driver resources at four levels. We randomly add measurement error (as a percent of the true value) drawn from a uniform distribution with supports over (0%, ±5%, ±10%, and ±15%). Thus, the reported consumption of a driver resource by the firm's products is a noisy function of the actual consumption.
We operationalize information precision as the length of the firm's history, which we vary at four levels: (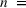
Together, we consider 48 (=3 * 4 * 4) information environments for each of our sample firms.
Solving for installed resource capacity
For each driver resource, the distribution of demand is known. We compute 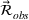
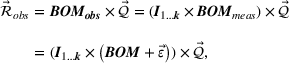
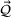
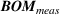
Turning to non‐driver resources, the Point1 and Dist1 heuristics associate each non‐driver resource with a driver resource. That is, we form a cost pool that comprised a driver resource and associated non‐driver resources. We use a National Football League (NFL) type draft system to assign non‐driver resources to cost pools. Each cost pool takes a turn and chooses the non‐driver resource with the highest correlation from the remaining unassigned non‐driver resources. This process repeats until we assign all non‐driver resources to a cost pool. For the Point2 and Dist2 heuristics, we need to add a second driver. For each non‐driver resource, we choose from the remaining driver resources the one with the highest correlation in usage. We compute the capacity for the non‐driver resource for both driver resources and average the values. We examine alternate methods (e.g., use stepwise regression, random assignment) in robustness tests reported later. The KDE method does not require the formation of cost pools as we fit a distribution directly to the history of usage for each non‐driver resource.
Evaluation of solutions
Our benchmark for evaluating the efficacy of a heuristic is the expected cost under full information, when the firm has complete and perfect information about
We examine generalizability by manipulating the information environment along select dimensions: the proportion of driver to non‐driver resources (quantity of available information), the extent of measurement error in the consumption of driver resources (quality), and the length of history available (precision). We evaluate robustness by varying the methods for choosing driver resources and for grouping non‐driver resources with driver resources, the density of the
For each firm and combination of information limitations, we compute the advance purchase capacity cost, the expected value of spot premium paid, and the expected cost of supply–demand mismatch (expected cost of spot purchases plus expected cost of leftover inventory). The efficiency of any given heuristic is the “cost ratio” obtained relative to the same value computed under full information. It is sufficient to examine costs in lieu of revenues or profits because all products are profitable. This approach also avoids scaling issues that can arise when profits are small and used in the denominators of ratios.
Our primary dependent variable is the expected cost of supply–demand mismatch, which is computed as the sum of the expected cost of spot purchases and the expected cost of leftover inventory (e.g., see Zhao et al., 2012). This cost is positive, even with full information because of the uncertainty in product demand. Then the cost ratio is the cost of supply–demand mismatch under a specified information limitation (e.g., number of drivers = 3, length of history = 10, measurement error = 0%) divided by the value obtained with full information for that firm. The use of a ratio as a measure of efficacy has the advantage that parameter choices affect both the full‐information (first best) and the heuristic‐based (second‐best) solution. Thus, we expect our inferences to be robust to parameter choices such as the relative ratios of the opportunity costs of under‐ and over‐stocking, the demand distribution, and features of the production function. 11
Inferences from other dependent variables, such as the ratio of expected total cost of supplying demand, are similar. Detailed results are available on request.
Number of observations
As noted earlier, for each firm, we vary the information available along three dimensions: the number of driver resources at three levels; the error in measuring the usage of driver resources at four levels, and the length of history at four levels to obtain 48 configurations for each firm. For each of these 48 configurations, we apply five heuristics, giving us 240 observations for each firm. We repeat the process for 1000 firms (with random choices for the density of the
RESULTS
We present results in the form of graphs and tables that aggregate and sort the observations along the dimensions of interest. We do not present formal statistical analyses as sample size, and hence statistical significance can be increased arbitrarily in a simulation (Anand et al., 2019). We provide additional data in the Online Appendix, labeling the relevant tables and figures with the prefix A.
Ratio‐based planning is robust and efficient
In Figure 1, we plot the efficiency of heuristics that plan the capacity of non‐driver resources. The x‐axis is the number of driver resources considered and the y‐axis is the cost ratio, with each plot marker averaged over 4000 observations. We set measurement error to zero as it has significant interactive effects, discussed later.
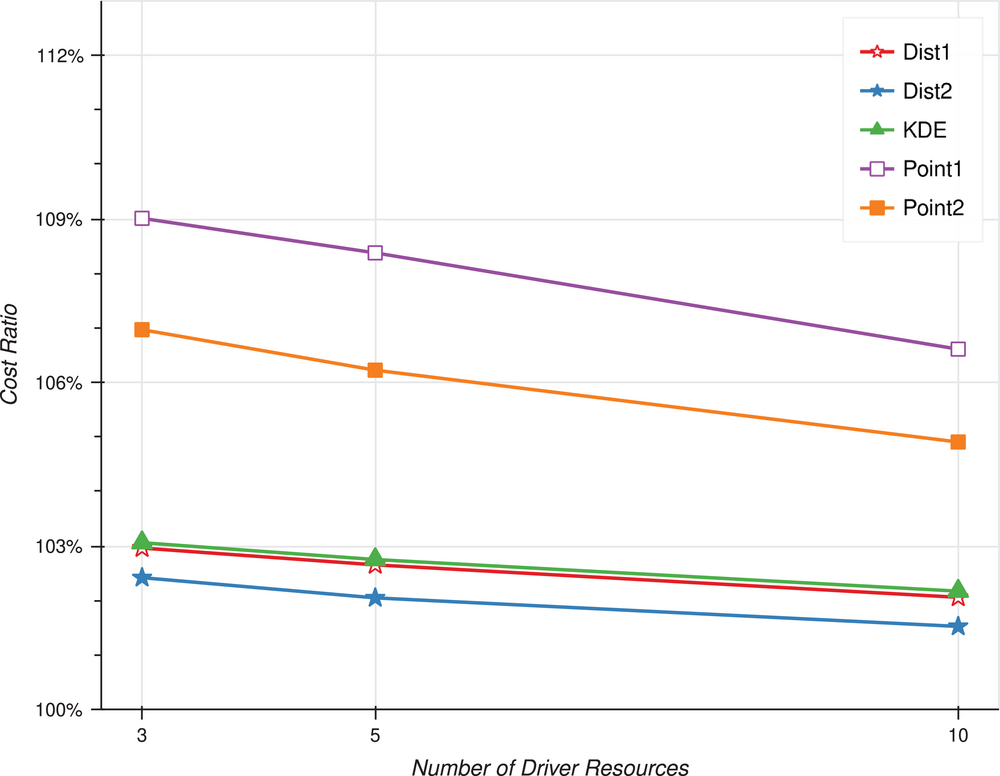
Efficiency of heuristics as knowledge of bill of material increases, 0% measurement error. For each of 1000 simulated firms, we infer the demand distribution for each of its 50 resources from the known demand distributions for each of its 20 products. We solve a newsvendor problem independently for each resource and obtain the optimal advance purchase quantity for each resource. From this, we compute the first‐best expected cost of supply–demand mismatch as the sum of the expected cost of spot purchases plus the expected cost of leftover inventory. We manipulate the length of history for each firm at five, 10, 25, or 50 periods. For each period in the firm's history, the firm knows the aggregate consumption of each resource required to meet product demand. From the resource consumption history, the firm computes the pair‐wise ratio of resource consumption between all resources. In this figure, we assume zero measurement error in resource consumption. For each level of the length of history, we manipulate the number of driver resources for which the firm has full information about the consumption of the resource by product. We use each driver to form a cost pool and assign non‐driver resources based on correlation patterns. We employ five heuristics to determine the advance purchase capacity of the non‐driver resources. Under the Point1 heuristic, the capacity level of a non‐driver resource equals the optimal capacity for the corresponding driver times the historical ratio between the driver and non‐driver resource. Under the Dist1 heuristic, we scale the demand distribution for the corresponding driver by the ratio and solve a newsvendor problem using the under‐ and over‐stocking cost of the non‐driver resource. Under the kernel density estimation (KDE) method, we estimate a distribution separately for each non‐driver resource from its history. For each firm, length of history, number of driver resources, and heuristic, we compute the total expected cost of supply–demand mismatch across all resources and divide it by the corresponding first‐best cost to obtain a cost ratio. The figure shows the cost ratio for each condition, averaged across levels of the length of history. Each data point corresponds to 4000 observations.
On average, the Point1 heuristic increases total cost by ∼9% relative to a solution with full information in an informationally sparse setting with three driver resources and 47 non‐driver resources. Violin plots (see Figure A1) reveal many outliers. The top decile of cost ratios averages 122% (max value = 158%, untabulated), and these observations have a greater likelihood of occurring in settings with high resource cost dispersion. 12 Increasing the number of drivers improves the average cost ratio and reduces the variance in a concave fashion (see also Table A1). This finding, which is consistent with and augments (for variances) prior research that reaches a similar conclusion in different contexts, corroborates practice recommendations to restrict the number of driver resources. 13
Data in Table 2 provide insight. First, as expected, the percentage of costs accounted for by driver resources increases as we classify more inputs into this category. The ratio is 36.8% with three driver resources and 55.2% with 10 driver resources. Naturally, the costs from incorrect planning for non‐driver resources monotonically decline. Moreover, the percent increase in costs is concave, meaning that the reduction in the scope of the problem is also concave, limiting the gain from adding more drivers. Next, considering five driver resources, the average correlation in total resource usage within a cost pool is 0.5501, noticeably higher than the overall average of 0.3996 reported in Table 1. The implication is that the practice of forming cost pools by looking at correlations in resource usage leads to a significant information gain when planning for non‐driver resources. The final row of Table 2 reports on the accuracy of the ratio relating driver to non‐driver resources. We find that the average absolute error is about 3.6%. Together, the data show that increasing the number of pools helps both by reducing the magnitude of the problem and by increasing the within‐pool correlation, which in turn increases the accuracy of the ratio used in the heuristic.
Effect of number of driver resources on quality of available information, 0% measurement error.
Note: This table shows the effect of increasing available information on sources of error in capacity planning when there is 0% measurement error in driver resources. As the number of driver resources increases, firms’ knowledge of their BOM increases. Percent of total cost contained in driver resources is the percent of total cost accounted for by driver resources when the firm purchases the optimal quantity for every resource (first best). Average pair‐wise correlation in resource usage of driver and non‐driver resources within a cost pool (determined from BOM) is computed as follows. Within a cost pool, the pair‐wise correlation between the pool driver and every non‐driver is computed using rows of the BOM. This is averaged across all non‐driver resources. Average correlation in total consumption of driver and non‐driver resources within a cost pool (empirically determined) is computed similarly, but instead of using rows of the BOM, 10,000 draws from the resource demand distributions are used. Mean absolute percent error in installed capacity for non‐driver resources is ABS [(second best capacity – first best capacity)/first best capacity], averaged across all non‐driver resources. Second best capacity is computed using a heuristic, while first best is computed using full information. Larger values of this variable indicate lower quality of the ratios that map driver resources to non‐driver resources. This measure is reported only for the Point1 heuristic, length of history of 10 periods, and 0% measurement error. Entries in this table average the firm‐level value for the relevant measure over 1000 firms.
Returning to Figure 1, we find that adding in data about resource‐specific opportunity costs (Dist1) reduces the average cost ratio from 109% to 103% with three driver resources. This refinement is implementable as firms likely have good information about the unit costs and spot premiums for resources. As noted earlier, observed stocking policies for support resources appear to employ estimates of opportunity costs. Compared to Point1, the Dist1 heuristic has lower variance and fewer outliers (the average is 110% for the top decile of cost ratios and a maximum of 139%; see Figure A1). The average improvement, relative to the solution from the Point1 heuristic, ranges from 1.2% for the bottom decile to 13.6% for the top decile (see Table A2 and Figure A2). Moreover, the improvement obtains in over 99% of examined cases. The larger differences are more likely in settings with diffuse resource costs and higher variance in spot premiums. The mean value for DISP, the cost in the 10 most expensive resources is 51% (58%) in the top (bottom) decile of observations, sorted by the improvement in the cost ratio. Likewise, the correlation between the variance in the firm‐level spot premium and the gain from including opportunity costs is 0.24 (p < 0.001).
Data show limited incremental gains from increasing statistical sophistication. Fitting a distribution to the observed history of usage of non‐driver resources (KDE) does not outperform the simpler approach in the Dist1 heuristic.
We find similar patterns when we consider the length of history rather than the number of drivers (Figure A3). Firms do not appear to need deep information or experience with a proposed technology to make good planning decisions. Overall, we conclude that simple, easily implemented heuristics are cost‐efficient ways to address information limitations.
Using multiple drivers to triangulate increases cost efficiency
Figure 1 also shows significant gains from the refinement of using two drivers to estimate the usage of capacity resources. Adding the estimate from another driver (with lower correlation) and averaging the two results decreases the cost ratio from 109% (Point1) to 107% (Point2) when using three cost drivers; the gains are similar with five and 10 cost drivers, indicating that the triangulation manipulation produces a main effect. We also document a reduction in the variance of the cost ratio, suggesting that the improvement has bite in a variety of settings (see Figure A1). However, the gain is not guaranteed as we fail to document an improvement in about 5% of the cases.
We find a similar pattern for Dist1, a heuristic that incorporates opportunity costs. However, the decline in the cost ratio is smaller: 103% (Dist1) to 102.4% (Dist2) in the case with three cost drivers. We draw three inferences. First, the data are consistent with Balakrishnan et al. (2011) who advocate the use of indexed drivers to better measure the economic usage of resources. Even considering information costs, Homburg (2001) shows that it is often beneficial to replace a driver with a combination of other drivers. Second, triangulation (or indexing) leads to smaller gains with the more sophisticated method than the simpler method. Finally, while triangulation helps, it is better to implement heuristics that include additional information such as opportunity costs of non‐driver resources, even if they involve more computations. Both refinements have the greatest impact with diffuse resource costs, increasing the dollar magnitude of the problem of planning for non‐driver resources.
Data in Table 3 report the incremental gain in regions sorted by problem parameters. Once again, diffusion in resource costs, which directly affects the magnitude of the problem, has the largest effect. Even so, the variation in the gains due to improvements is modest. We conclude that our Findings 1 and 2 apply in general (see also Table A2 and Figure A4 in the Online Appendix).
Performance of heuristics and improvements, sorted by parameter values, 0% measurement error.
Note: This table shows the variation in the performances of the heuristics across the parameter space. We form four quadrants sorted by the density of the BOM matrix and the dispersion in the resource costs, sorting based on median values. We report values when there is 0% measurement error in driver resources and average values across the number of driver resources and the length of history. The variable P1_D1 shows the improvement from the Point1 to the Dist1 heuristic. The variable P1_P2 represents the improvement from using two drivers relative to one for the Point method, and the variable D1_D2 provides the equivalent improvement under the Dist method. DNS and DISP report the average value for the density of the BOM matrix and the percentage of cost accounted for by the 10 most expensive resources, for each quadrant. Each entry in the table is an average of the firm‐level value for the relevant measure over 1000 firms.
We investigate the gains from additional triangulation by extending the analysis to three, four, and five drivers. In untabulated results, we find that the gains, while positive, fall off sharply. Our findings suggest that averaging results from two drivers is an effective way to reduce the deleterious effects of specification error (Datar & Gupta, 1994), particularly when we consider information‐related costs.
Reducing measurement error in usage of driver resources is valuable
As shown in Figure 2 (see also Figure A5), measurement error has a significant and convex effect on the average cost ratio, and its variance, for all five heuristics. One implication is that it is useful to focus refinement on reducing measurement error. It is better to get good data on a few driver resources than gathering mediocre data on many driver resources. 14 For instance, considering the Point1 heuristic, the cost ratio is 135% with five pools and 10% measurement error, compared to 160% with 10 pools and 15% measurement error (see Table A4). This result echoes similar findings obtain in other contexts. Considering the stocking of operating rooms in hospitals, Rappold et al. (2011) find that reducing the uncertainty (i.e., measurement error) in the physician‐determined BOM through standardization exhibited the greatest potential for savings.
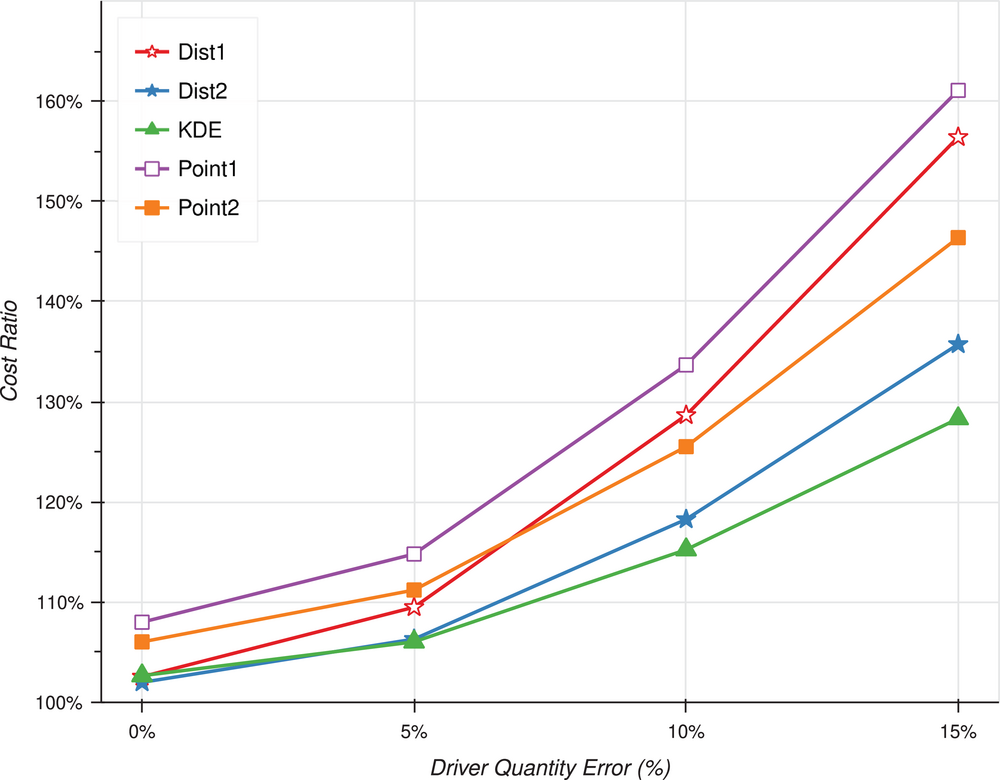
Effect of measurement error. For each firm, length of history, number of driver resources, heuristic, and level of measurement noise in driver resources, we compute the total expected cost of supply–demand mismatch across all resources and divide it by the corresponding first‐best cost, computed without measurement noise, to obtain a cost ratio. The figure shows the cost ratio for each condition, averaged across all levels of the number of driver resources and length of history. Each data point has 12,000 observations. See Figure 1 for definitions of terms and description of the method.
With high measurement error, the ordering of the heuristics is not monotonic as the negative effect of measurement error is larger for more computationally intensive methods. With zero measurement error, at 103%, the cost ratio for Dist1 is four percentage points lower than the ratio for the Point2 heuristic. However, the relation reverses (i.e., Dist1 has a higher cost ratio at 158% vs. 145% for the Point2 heuristic) when we consider a setting with 15% measurement error (see Table A3). This reversal implies that triangulation becomes attractive in settings where it might be expensive to reduce measurement error directly. The intuition is that measurement error affects both the mean and the variance of the derived resource demand distribution. While the effect of the mean affects the efficacy of both the Point and the Dist heuristics, changes in the variance only affect results under the Dist1 heuristic.
Measurement error also has a larger impact on the cost ratio than the effect from the precision of available information. In Table A6, we report the extent of absolute deviation in the installed capacity of non‐driver resources, relative to the value in the full‐information solution, sorted by the levels of precision and measurement error (for the case of five driver resources). Considering the global averages, for the Point1 heuristic, increasing the length of history from five to 50 periods reduces the error from 5.92% to 5.22%. However, the deviation from the benchmark capacity increases faster, from 4.56% to 8.14%, as measurement error increases from 0% to 15%. The intuition is that a heuristic does not consider the error in the data it uses. Measurement error affects the installed capacity for driver resources and the error flows through to non‐driver resources as well. 15 In contrast, the length of history (precision) has no effect on the capacity planned for driver resources as we assume the firm knows the demand distributions of these resources.
Partial improvements can hurt in settings with high measurement error
Measurement error has a significant interaction effect. For the Point1 heuristic with 15% measurement error, the cost ratio declines (from 162.1% to 161.1% to 160.1%) as we go from three to five to 10 driver resources (see Table A4). This decline is proportionately smaller than for the case with 0% measurement error, suggesting the interaction. Moreover, this interactive effect is stronger for the Dist1 heuristic. In this case, we know from Figure 1 (0% measurement error) that increasing the number of drivers decreases the cost ratio. However, this improvement is absent (and reverses to a small degree) with significant measurement error; the cost ratio changes from 156.7% to 156.1% to 156.4% as we go from three to five to 10 drivers (see Table A3). With high measurement error, we document a monotonic increase in the average cost ratio for the Point2 (145% to 146% to 147%) and Dist2 (from 133% to 135% to 138%) heuristics as we increase the number of pools from three to five to 10 (see Table A3). These findings reaffirm the earlier inference that measurement error has a larger impact on more sophisticated heuristics. As measurement error is more likely in newer firms or firms using newer technologies, such firms may be better off using simple heuristics.
We next explore settings wherein the negative effects of measurement error are pronounced. Even for the Point1 heuristic, where the average improves, the change in the cost ratio from three to five cost pools is negative for ∼49% of observations, indicating that this effect is common. For insight, we sorted the change in the cost ratio by moving from three to five drivers into deciles (Table A5). We find that the lowest and the highest deciles obtain in settings with high density for the
In Figure 3, we also consider diverse levels for the precision of available information. Data show the intuitive effects with 0% measurement error. Improving the number of drivers or the precision of available data (reducing aggregation or specification error) helps system performance. Moreover, with 0% measurement error, we do not discern a strong interaction effect between these two factors, for either of the two heuristics we consider. The story changes with significant measurement error. First, improving precision does not always help. For the Point1 heuristic with three or five drivers, cost ratio increases as precision increases. The error due to measurement, in both driver and non‐driver resources, overwhelms the marginal gain due to precision, which only affects non‐driver resources. 16 Likewise, considering the Dist1 heuristic, increasing the number of drivers could degrade system performance.
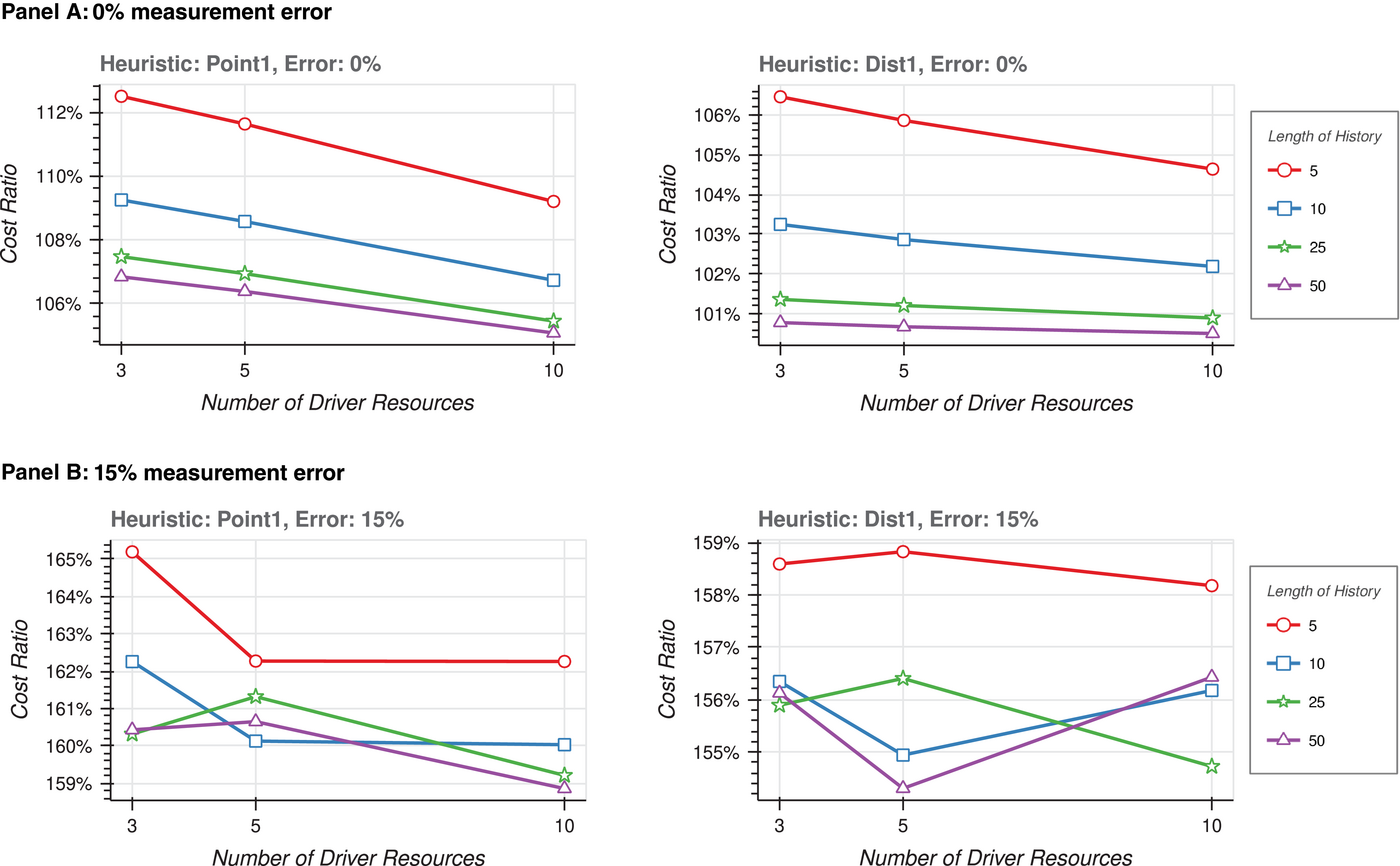
Interaction between measurement error, length of history, and number of driver resources. Cost ratio as a function of the length of history and number of driver resources for the Point1 and Dist1 heuristics. Panel A (B) shows results for low (high) measurement error. See Figure 1 for definitions of terms and description of the method. Each data point has 1000 observations.
Together, we conclude that measurement error reduces and could even reverse any gain due to the number of drivers or the precision in the ratios that relate the usage among driver to non‐driver resources. The intuition is that measurement error affects the installed capacity for both the driver and the non‐driver resources and that as we increase the number of driver resources, the magnitude of the problem (relating to non‐driver resources) decreases. The data suggest that the increased error in the installed capacity of driver resources overwhelms the marginal gain due to the reduction in the number of non‐driver resources or gains in determining their installed capacities. The implication is that in settings with high measurement error, firms need to be judicious in implementing partial improvements of their data collection processes, particularly when they employ sophisticated heuristics to fill in for limited information.
ROBUSTNESS CHECKS
See Section A5 in the Online Appendix for additional details on each of these sensitivity tests.
Choosing driver resources
The centrality of driver resources implies that how we choose the set of driver resources matters. We have used the largest total cost method, the “Willie Sutton” rule, 17 which is consistent with practice. We consider four alternatives to this greedy algorithm: random choice, resources most used by products, maximum average absolute correlation with other resources, and stepwise regressions.
We find that the greedy algorithm yields the best results because this approach reduces the total costs of non‐driver resources (see Figure A7). This finding holds with positive measurement error and for the other heuristics. These results echo extant results in the operation management literature; for example, Bassok et al. (1999) and Biller et al. (2005) show that greedy algorithms are effective means for making pricing and production decisions.
Method for assigning resources to cost pools
Results thus far employ the NFL method to assign resources to drivers: cost pools take turns. In each turn, the cost pool chooses from the remaining unassigned non‐drivers resources the one with the highest correlation. We examined two alternate methods to assign non‐driver resources to drivers (i.e., to form cost pools): random assignment and a correlation‐based assignment. The random method is self‐explanatory. Under the correlation‐based method, we assign each non‐driver resource to the driver with the highest correlation in usage (based on the firm's production history). Note that these procedures produce an imbalanced (in terms of the number of resources and their cumulative value) cost pools. Inferences from these two alternate methods mirror those reported here. We conclude that the method for forming cost pools is not critical in capacity planning. This finding echoes findings in the research that examined the same question in the context of cost system design (Balakrishnan et al., 2011).
Picking the second driver for triangulation
The main results are from choosing as the second driver for the Point2 and Dist2 heuristics the available driver with the highest correlation. As an alternative, we estimated a stepwise regression with all remaining drivers and used the Akaike Information Criterion to select the second driver with the greatest explanatory power. Our inferences regarding the value of triangulation continue to hold. We conclude that simple methods to select the second driver suffice from the perspectives of generalizability and ease of implementation.
Distribution of product demand
Our assumption that product demand distributions are normal facilitates closed‐form solutions for expected costs but is not central to our results. Normality of the resource demand distribution is reasonable because convoluting a reasonable number (20 products in our case) of any set of distributions tends to yield a normal distribution. See Section A.5.4 of the Online Appendix for additional details.
Variations in spot premium
Results reported thus far set the distribution of the spot premium as 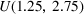
Data in panel B of Table A7 show another intriguing pattern: The performance of the Point1 heuristic (but not the Dist1 heuristic) degrades as the variance in spot premium, across resources, increases. The intuition is that the variance in spot premiums does not affect the full‐information solution, as we plan the capacity for each resource on its own. However, this variance adversely impacts the performance of the Point1 heuristic. We use the solution for the driver (which uses the opportunity costs for that resource) to project the capacities for the non‐driver resources. An increase in the variance implies that there is a greater probability of a mismatch in the opportunity costs, and hence the stocking ratio in the newsvendor problem, of the driver and non‐driver resource pairs. That is, there is a greater error in the installed capacity for the non‐driver resource. The mismatch is moot with the Dist1 heuristic as it directly employs the known opportunity costs for the non‐driver resources when planning capacity levels. The implication is that refinements in the form of heuristics that include opportunity costs (e.g., Dist1) are particularly valuable in settings with “high” variance in spot premiums. 18
CONCLUDING REMARKS
In this paper, we consider the efficacy of heuristics that permit firms to plan for capacity in anticipation of demand, when they have incomplete and imperfect information about resource demand. Results from numerical analyses suggest that easy to implement heuristics perform well in terms of their efficiency relative to a solution with full information. A simple system with a handful of driver resources that uses ratios to plan for all other resources delivers good performance. Moreover, easily implemented tweaks to these heuristics (e.g., using two drivers to “triangulate” rather than one as in traditional cost systems) lead to dramatic improvements. Finally, our data show that the firms may benefit the most from efforts at reducing the measurement error in the use of driver resources. These findings are robust to considerable variations in the underlying parameters.
Our insights can be extended in several ways. A step cost formulation is likely appropriate for some resources. In this case, we conjecture that the cost efficiency of the heuristics will improve because more demand observations map into the same resource capacity. In the limit, a resource whose capacity is independent of demand will be estimated with zero error in all settings. Of note, it seems important to consider resource flexibility, which alters the opportunity costs of advance purchases. For the same reason, considering firms with pricing power that alter realized demand is likely to be fruitful. As noted earlier, considering inventory policy is important for settings with seasonal demand. Finally, considering hard capacity constraints (so that excess demand is lost rather than met via spot purchases) is important as several industries have resources that impose hard constraints (e.g., there is limited potential for outsourcing an operating room).
Footnotes
ACKNOWLEDGMENTS
Lengthy discussions with Eva Labro and K. Sivaramakrishnan regarding concepts surrounding the measurement of product costs have contributed a great deal to the intellectual foundations that underlie this work. We thank the department editor, Anil Arya, the anonymous senior editor, and the reviewers for many helpful suggestions that greatly improved the paper. We also thank Shannon Anderson, Mark Bagnoli, Kai Mertens, Brian Mittendorf (discussant), Mark Penno, Korok Ray, Susan Watts, and seminar participants at the University of California, Davis, the 2022 University of Illinois at Urbana‐Champaign Emerging Management Accounting Scholars Symposium, University of Illinois at Urbana‐Champaign managerial brownbag, the 2020 MAS Conference, and 2022 JMAR brownbag for insightful comments.
1
2
In a field study at an automotive company, González et al. (2013) find that managers are unable to forecast changes in raw material needs as production schedules change. In the pharmaceutical industry, Singh et al. (2022) and Peng and Nunes (2009) show that an incomplete BOM hampers the efficacy of an enterprise resource planning (ERP) system. Stentoft et al. (2015) find that lack of knowledge about a BOM poses a barrier to outsourcing. The operations literature also recognizes that firms have limited information about their production processes (e.g., Chen‐Ritzo, ![]() ).
).
3
4
In the context of cost systems, Datar and Gupta (![]() ) define three kinds of errors. Aggregation error occurs when we group unlike resources together into the same cost pool, specification error occurs when the consumption patterns for the driver and support resources differ, and measurement error occurs when the measured quantity of a resource needed to produce an output differs from the actual quantity.
) define three kinds of errors. Aggregation error occurs when we group unlike resources together into the same cost pool, specification error occurs when the consumption patterns for the driver and support resources differ, and measurement error occurs when the measured quantity of a resource needed to produce an output differs from the actual quantity.
5
As inventory is a mechanism to “move” capacity across periods, considering a multiperiod framework is of interest when product demand is seasonal and/or correlated over time. In such settings, inventory policies interact with capacity levels to determine the opportunity costs of under and overstocking capacity. As we directly manipulate opportunity costs, a multiperiod setting would add complexity without necessarily supplying additional insight.
6
The ○ operator represents the Hadamard, or Schur, product of two vectors, that is, element‐wise multiplication.
7
We use the term driver resources to emphasize differences from the classical accounting definition of a direct resource. While many driver resources are direct to a product, there are cases of indirect resources that serve as drivers. For example, firms often use machine hours as drivers even though the resource is indirect to products.
8
In a report for the US Government Accountability Office about the challenges faced by the US Navy in constructing an aircraft carrier, Francis et al. (![]() ) state: “According to the shipbuilder, material requirements for previous carriers were developed by using the bill of materials from prior ships before the extent of design changes was well understood.”
) state: “According to the shipbuilder, material requirements for previous carriers were developed by using the bill of materials from prior ships before the extent of design changes was well understood.”
9
When marketing its Azure cloud computing platform, Microsoft offers different combinations for servers, storage capacity, central processing unit (CPU) types, and other computing resources tailored for different applications such as web hosting, graphics design, and artificial intelligence. Microsoft has refined these offerings over time as it learned customers’ patterns of resource consumption.
10
Sparse empirical data are available about the actual values of these parameters. We therefore consider a wide range and examine how performance differs across regions of the parameter space.
11
We validate this intuition by sorting observations by the magnitude of the expected loss in the full‐information solution and comparing results for observations in the top and bottom terciles. We do not find any significant differences in inferences.
12
Outliers also are more likely when there is higher variance in the spot premiums across resources within a firm. The correlation between the firm‐level variance in the spot premium and the cost ratio is 20% (p < 0.001). See Section 5.5 for more on this relation.
13
14
The contour plot in Figure A6 does not reveal any striking differences across regions of the parameter space.
15
The decline in the performance of KDE is solely because of the error in planning capacities for driver resources. The history of resource use depends on the true values in the BOM and is independent of the precision of available information or measurement error.
16
The data in Table A6 provide intuition. Consider panel A, which reports the accuracy of installed capacity for the Point1 heuristic with five driver resources. With 0% measurement error, the accuracy improves from 4.22% to 3.14% as we increase precision. However, the gain is much smaller (from 8.33% to 8.03%) when we consider 15% measurement error. We find a similar interaction in the context of the Dist1 heuristic.
17
Willie Sutton was an American bank robber in the early 20th century. When asked by a reporter why he robbed banks, Sutton answered, “Because that's where the money is.” This metaphor is commonly used to explain why the largest resources are chosen as cost drivers.
18
We find corroborating evidence at the firm level as well. The correlation between the variance in the firm‐level spot premium (across resources) and (1) the benefit due to triangulation (P1_P2) is 0.13 (p < 0.001); (2) gain from using Dist1 (P1_D1) is 0.25 (p < 0.001), and (3) the cost ratio for Dist1 is 0.01 (p > 0.10).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.