
Abstract
Range and charge anxiety remain essential barriers to a faster electric vehicle (EV) market diffusion. To this end, quickly and reliably finding suitable charging stations may foster an EV uptake by mitigating drivers' anxieties. Here, existing commercial services help drivers to find available stations based on real‐time availability data but struggle with data inaccuracy, for example, due to conventional vehicles blocking the access to public charging stations. In this context, recent works have studied stochastic search methods to account for availability uncertainty in order to minimize a driver's detour until reaching an available charging station. So far, both practical and theoretical approaches ignore driver coordination enabled by charging requests centralization or sharing of data, for example, sharing observations of charging stations' availability or visit intentions between drivers. Against this background, we study coordinated stochastic search algorithms, which help to reduce station visit conflicts and improve the drivers' charging experience. We model a multiagent stochastic charging station search problem as a finite‐horizon Markov decision process and introduce an online solution framework applicable to static and dynamic policies. In contrast to static policies, dynamic policies account for information updates during policy planning and execution. We present a hierarchical implementation of a single‐agent heuristic for decentralized decision making and a rollout algorithm for centralized decision making. Extensive numerical studies show that compared to an uncoordinated setting, a decentralized setting with visit intentions sharing decreases the system cost by 26%, which is nearly as good as the 28% cost decrease achieved in a centralized setting. Even in long planning horizons, our algorithm reduces the system cost by 25% while increasing each driver's search reliability.
INTRODUCTION
Electric vehicles (EVs) can play a crucial role in decarbonizing the transportation sector, given a rapid energy transition and continuous battery technology improvement (Schuller & Stuart, 2018). To sustain the global EV market's growth of the past 2 years (Deloitte, 2020), it is necessary to mitigate the remaining barriers to private EV adoption. In addition to the well‐known range anxiety, a new phenomenon referred to as charge anxiety, caused by unreliable and insufficient public charging infrastructure, remains an essential barrier, particularly in cities (Myersdorf, 2020). Besides increased price transparency, a seamless charging experience may reduce these anxieties if drivers can easily find and use an available charging station (McKinsey, 2020).
In this context, increasing public infrastructure coverage and improving interoperability between charging service providers is necessary to facilitate easy and reliable access to public charging stations but requires a long planning horizon (Volkswagen, 2019). Accordingly, complementary short‐term solutions are necessary to alleviate deficiencies in the currently undersized charging infrastructure. In theory, cooperative charging strategies based on vehicle‐to‐vehicle communication can allow for fairer charging capacity allocation (You et al., 2016) but are not implemented yet due to immature technology and uncertain economic value (Lauinger et al., 2017). In practice, existing map‐based services help EV drivers to locate available charging stations based on real‐time charging station availability data, but fail to provide a reliable charging station search experience: Stations reported as available can be unusable due to inaccurate reporting or ICEing, that is, conventional vehicles blocking the access to a charging station (Guillet et al., 2022). In such cases, drivers must take detours to reach another station, which may lead to increasing anxiety.
Moreover, simultaneous uncoordinated searches of multiple drivers may conflict if drivers head to the same charging station. Navigation service platforms that offer services to find available charging stations through local navigation devices or an online Application Programming Interface (API), may centralize driver requests or leverage active and passive driver community input, for example, GPS trace data, to coordinate search recommendations. In the literature, stochastic charging station search methods offer a reliable alternative to existing search services, accounting for charging stations' availability uncertainty. Such methods consider charging stations as stochastic resources and aim to find a sequence of charging station visits—a search path—that minimizes the expected search cost to reach an available station. These approaches are amenable for real‐time applications, may significantly save drivers' time, and may increase the search's reliability. However, such approaches so far focus always on a single‐agent setting. Accordingly, coordinating drivers in a multiagent setting has not been studied so far, but may avoid possible visit conflicts and further improve the driver's charging experience by increasing the search's reliability and decreasing its time.
With this paper, we close this research gap by extending stochastic single‐agent search algorithms to a stochastic multiagent setting, accounting for information sharing and possible requests centralization. We consider scenarios in which drivers may share their planned visits, their observations of a charging station's occupancy, or both. Our goal is to identify the coordination strategy that yields the best improvement on the drivers' search times and the search's reliability.
Related literature
In the following, we first review literature that relates to stochastic charging station search problems in a single‐agent setting, including EV routing with uncertain charging station availabilities and more generic stochastic resource search problems. We then focus on multiagent resource search problems with stochastic availability or locations.
Only a few papers that deal with EV routing problems address charging station availability uncertainty but do not focus on open‐search problems. Kullman, Goodson, et al. (2021) solve the EV routing problem with a public–private recharging strategy, while Sweda et al. (2017) and Jafari and Boyles (2017) focus on shortest paths with multiple charging stops for EVs. Sweda et al. (2017) propose adaptive charging and routing strategies when utilizing the public charging infrastructure, whereas Jafari and Boyles (2017) additionally model both stochastic travel time and charging consumption. Alternatively, a few papers deal with stochastic resource search problems in general settings (Guo & Wolfson, 2018; Schmoll & Schubert, 2018) or more specific settings, for example, on‐street parking spots (Arndt et al., 2016) or stochastic taxi customer demand (Tang et al., 2013). Guillet et al. (2022) are the first to cover multiple variants of the stochastic charging station search problem for EVs, considering charging or waiting times at stations. However, all aforementioned papers, including Guillet et al. (2022), are limited to single‐agent settings and ignore possible agents coordination.
Focusing on multiagent settings, most works on resource search problems under uncertainty focus on cooperative searches, that is, settings in which agents share a unique common goal. In Bourgault et al. (2003), all agents aim at locating a resource with no a priori information on its location in a decentralized decision‐making setting. Chung and Burdick (2008) solve a similar setting with centralized decision making, while Wong et al. (2005) and Dai and Sartoretti (2020) extend the single resource target search problem to a multitarget search problem. Qin et al. (2020) address the multiagent travel officer problem in a centralized decision‐making setting, in which agents must cooperatively collect resources with stochastic availability in given locations. In all of these papers, the cooperative search terminates after the (all) resource(s) have been found. This is not the case in our multiagent charging station search setting: Here, each agent terminates her search when she found at least one nonshareable available resource. Existing work on multiagent settings for EVs mostly focuses on autonomous EV fleet management, such as ride‐sharing planning (Al‐Kanj et al., 2020) or online requests matching for ride‐hailing (Kullman, Cousineau, et al., 2021) and do not cover stochastic resource search problems.
In summary, most papers that deal with heterogeneous resource search problems with stochastic availability focus on a single‐agent setting. Multiagent search problems mostly focus on cooperative (multi) resource search problems with unknown resource locations. In contrast, the search problem studied in this work is rather collaborative than cooperative because there exists a trade‐off between an individual agent's search experience and the system performance. Furthermore, while agents usually synchronously search for one or multiple resources, our setting requires the agents' search to start at different times and in different locations, which are sequentially revealed.
Aims and scope
With this work, we close the research gap outlined above by providing coordinated stochastic search algorithms, that consider both resources and agents heterogeneity, tailored to various information‐sharing and decision‐making scenarios of high practical relevance. Specifically, our contribution is threefold. First, we formalize the underlying centralized multiagent decision‐making problem. To this end, we define the planning problem as a single–decision maker Markov decision problem (MDP) and show that with an additional policy constraint, this MDP can be alternatively represented as a set of single‐agent MDPs, which enables decentralized and static planning. Second, we present several online algorithms that allow to solve a variety of real‐world scenarios. Here, we consider both settings in which a navigation device addresses a charging request on the fly, by providing either a full search path (static planning) or only the next best charging station to visit (dynamic planning) to the driver. Moreover, we consider centralized and decentralized planning settings with different levels of information sharing in which drivers share either their planned visits, or their charging station occupancy observations, or both. Third, we conduct extensive numerical studies based on real‐world instances to analyze which coordination strategy yields the highest improvement potential from a system and a driver perspective.
Focusing on a short planning horizon, our results show that, from a system perspective, a centralized coordination strategy can decrease the system cost by 28% on average, and that a static decentralized coordination strategy already achieves a 26% cost decrease if visit intentions are shared, compared to an uncoordinated scenario. In a decentralized setting with intention sharing, observation sharing does not increase the system's performance further, but enforcing agents' collaboration is required when drivers depart within a short time span. While a decentralized setting with only observation sharing performs worse than intention‐sharing settings, it provides a computationally efficient implementation in practice. When implemented in a dynamic setting, it yields a 10% average cost decrease when drivers depart within a short time span, but achieves a 26% average cost decrease with larger departure time span. From a driver perspective, coordination may save up to 23% (intention‐sharing setting) of a driver's search time, while increasing her search reliability. Our results further show that a coordinated search outperforms uncoordinated searches, with respect to both best and worst solutions that an individual driver may obtain. Finally, focusing on long‐term planning horizons, additional analyses show that a centralized coordination strategy achieves a slightly lower cost reduction compared to a short‐term planning horizon but nevertheless decreases the system cost by 25% on average compared to an uncoordinated scenario.
Organization
The remainder of this paper is as follows. Section 2 introduces our problem setting. In Section 3, we formalize our multiagent decision‐making problem as an MDP, before we characterize MDP policies that allow for decentralized policy execution and planning. Section 4 introduces our solution framework for online charging requests. In Section 5, we describe our case study and the corresponding experimental design. We discuss numerical results in Section 6. Section 7 concludes this paper and provides an outlook on future research. Throughout the paper, we refer to its Supporting Information as appendices to keep the writing concise.
PROBLEM SETTING
We focus on a nonadversarial multiagent search problem, with stochastic charging station availability, where multiple drivers seek to find an unoccupied charging station in their vicinity at the earliest possible time. We consider an online setting in which drivers enter the system sequentially and reveal their current position upon entering. Accordingly, drivers start their search asynchronously; each driver departs from a given location, that is, its current position, and may visit multiple occupied charging stations before reaching an available charging station. A driver visits the stations recommended by her navigation device, which synchronizes with a central navigation service platform. In this setting, an EV driver's objective is to minimize her expected time to reach an available station and any related charging costs. The navigation service provider's objective is to satisfy as many drivers as possible by minimizing the sum of all drivers' individual search cost as well as the likelihood that a driver does not reach any available station within a given time budget.
We assume each individual search to be spatially and temporally bounded to account for a driver's limited time budget. Every unsuccessful search induces an individual penalty. Moreover, we assume that a driver cannot wait at an occupied station or visit a station twice and that she stops at the first available station she visits. Stations are heterogeneous and using a station yields a cost. Drivers are heterogeneous with respect to the charging and penalty costs, their time budget, and the radius delimiting their (circular) search area.
Practically, the navigation device transmits a search solution to the driver: The driver may either receive a full sequence of stations to visit until an available station is reached, that is, a search path, or she may receive the next station to visit dynamically. We refer to the former as static planning and to the latter as dynamic planning. Moreover, the solution planning can be (i) centralized within the navigation service platform or (ii) decentralized, that is, at agent level. In the latter case, solution planning can happen directly within the local navigation device and devices only use the platform to share information with each other. In both cases, agents may share their station occupancy observations intermittently or in rea time with the central platform. In the decentralized case, they may additionally share the planned charging station visits. To capture these varying characteristics, which are of practical relevance, we introduce the following problem settings as summarized in Table 1.
Problem settings overview.
Static path planning
In such settings, a search path is planned upon request of the agent and cannot be dynamically updated once the agent started her search. Accordingly, an agent's actions only depend on the agent's own observations and the initial information available prior to her search. We assume that planned search paths and (if shared) collected observations can be transmitted to the central platform to be available to subsequent agents. We introduce four decentralized decision‐making settings according to the type of shared information. In the decentralized setting (D), no information is shared between agents, while each agent is aware of prior available observations of other agents when computing her search path in the decentralized setting with observation sharing (DO). Both settings D & DO are purely informative, such that agents are unaware of other agents' planned search paths. The decentralized intention‐sharing settings (DI & DIO) extend the D & DO settings: Each agent additionally knows previous agents' search paths, that is, their intended station visits and visit times. Agents may use this information selfishly, for example, by visiting other agents' target stations first, or they may use this information collaboratively.
Dynamic path planning
In such settings, an agent does not receive the whole search path at once. Instead, it receives the next station to visit at each occupied visited station until it reaches an available station. Here, we consider a centralized decision‐making setting (CIOd) in which a central planner, that is, the navigation platform, is fully aware of all agents' observations and actions, and assigns station visits on the fly to minimize the total expected search cost of all agents, while maximizing the likelihood that all agents find an available station. Here, each action assigned to an agent depends on the other agents' actions and all decisions are system‐optimized as the platform does not prefer any agent. Further, we consider a dynamic variant (DOd) of the decentralized observation‐sharing setting DO. In this setting, the initial solution is dynamically replanned upon each occupied station visit to account for the latest shared observations. Note that we discard settings COd, DId, CId, and DIOd from our analyses for the following reasons: COd does not exist, as a planner who centrally assigns stations to drivers is aware of all drivers' visit intentions. In a DId or CId setting, intention sharing implies observation sharing, as an intention update occurs when a driver visits an occupied station, which reveals the driver's station occupancy observation. In a DIOd setting, each driver has nearly as much information as a centralized planner, at the exception of other drivers' search radii or time budget preferences. As both settings are very similar, we limit our analyses to a CIOd setting, which requires less information sharing in practice.
Discussion
A few comments on our problem setting are in order. First, we model our coordinated charging station search as a closed system. While this assumption seems to be a limitation from a theoretical perspective, it is appropriate from a practitioner's perspective as it reflects real‐world planning scenarios, where charging requests usually accumulate during certain periods of the days (see Figure 1). Even for scenarios with charging requests homogeneously distributed during a day, we observe a sufficiently long period without charging requests during the night, which imposes a natural system boundary.
Number of ending trips on Tuesday 12.01.22 in the east area of Berlin, Germany. Note: The figure shows
Second, we assume charging station occupancy persistency in our basic problem setting. The validity of this assumption depends on the length of the considered planning horizon. Considering a short planning horizon, for example, between 15 min and 1 h, our persistency assumption remains valid and is in line with real‐world observations: Here, typical charging durations exceed the planning horizon. Considering a long planning horizon, our persistency assumption is clearly unrealistic. We describe in Section 4.3 how to relax observation persistency and consider temporarily occupied stations with occupancy probabilities that recover over time. Alternatively, one can roll out several short planning horizons, and assume that information on observed (i.e., excluded) stations outdates after some time, such that excluded stations can explicitly be considered as candidate stations again.
In our basic problem setting and analyses, we focus on short planning horizons and consequently assume occupancy persistency, which eases the problem's exposition, for two reasons: First, a short planning horizon, possibly used in a rolling‐horizon approach, is sufficient to mitigate local bottlenecks, which are spatially and timely limited, and are currently the main problem in practice. Second, from a single‐agent perspective, modeling time‐dependent recovering availability probabilities has no impact on the computed search path as an agent either succeeds or gives up the search after a limited time budget (cf. Guillet et al., 2022). However, we extend our analyses to long planning horizons in Section 6.2.3 to complete our analyses and show the efficacy of our methodology in such a setting.
Third, we assume that all the shared information is available to the other drivers or the central decision maker, but limited to a certain vicinity. This assumption allows to reduce computational effort and is reasonable in practice as far‐distanced drivers do not interfere with each other.
MDP REPRESENTATION
We refer to the problem setting discussed in Section 2 as the multiagent stochastic charging pole search (MSCPS) problem and model it as a sequential multiagent decision‐making problem with a finite time horizon. In the following, we first consider a centralized representation of the system states and represent an offline multiagent search with an omniscient single decision maker. We then reduce the solution space such that the solution policy can be decentrally executed in Section 3.2, and show that in this case the MDP can be represented by a set of individual MDPs in Section 3.3.1.
We formalize the MSCPS problem on a complete directed graph 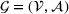
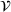
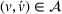
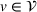
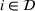
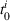
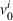
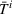
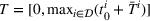
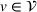
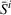
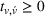
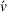
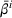
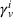
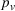
MDP notation
An agent triggers a new decision epoch either by requesting to charge her vehicle or by observing a new station. We refer to the requesting or observing agent as the deciding agent denoted with λ although a central planner may take the actual decision. If the observed station is occupied and there is at least one reachable station within her remaining time budget, λ selects her next station visit; otherwise λ has terminated her search. Note that each station visited by λ can no longer be used by any succeeding agent, since the station is either (i) already occupied or (ii) available and thus occupied by λ. Accordingly, the set of visited stations, that is, stations that have been observed, corresponds to the set of occupied stations.
State space:
We represent a system state 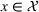
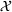
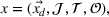
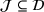
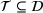
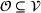
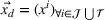
Here, we define an agent's state 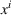
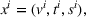
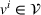
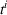
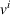
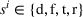
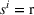
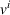
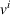
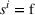
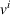
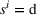
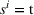
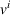
Action space and immediate cost:
We denote with u, the action taken in state x for agent λ, that is, the next station to visit, and by 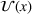
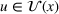
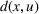
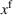
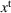
Available station (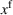
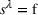
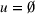
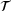
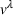
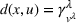
Occupied station (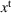
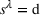
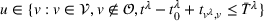
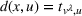
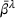
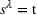
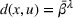
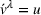
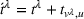
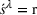
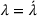
We define a policy 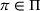
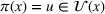
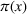
State transition:
Upon a single‐agent's action, the system transitions from state x to the next state 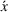
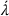
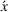
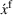
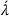
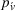
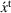
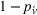
We introduce the value function 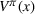
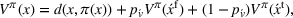
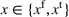
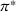
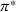
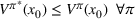
To increase the robustness of our solution, we introduce a global penalty cost 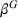
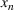
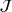
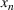
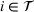
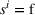
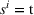
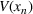
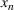
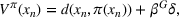
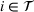
Policy representation
In Section 3.1, we introduced an agent‐agnostic policy, that is, a policy that applies to any agent. Alternatively, we can represent π as a set of single‐agent policies 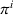
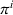
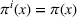
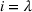
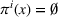
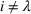
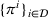
User‐independent single‐agent policies:
While coordinated search in general requires central coordination, it is possible to ensure a priori coordination between agents without central coordination, that is, preserving user‐independent search policies. In this special case, coordination accounts for other agents' visit intentions when deriving an agent's search policy but excludes observation sharing during the search. In such a setting, an agent i, executing a search policy π, being located at station v with v being occupied, will always visit the same next station. We can formally describe this condition as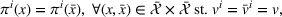
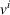
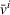
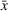
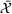
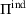
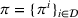
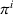
User‐dependent single‐agent policies:
In general, the execution of a single‐agent policy 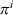
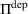
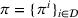
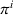
MDP representation with a user‐independent policy constraint
The MDP defined in Section 3.1 considers a user‐dependent global policy that can be represented as a set of single‐agent user‐dependent policies (see Section 3.2). We show that by constraining single‐agent policies to be user independent, this global MDP representation simplifies to a set of single‐agent MDPs, which allows to easily plan each agent's solution decentrally. We introduce the representation of a single‐agent MDP in Section 3.3.1 accordingly. Here, the objective function equals the sum of single‐agent MDP objective functions with an extra penalty cost. In this case, a single‐agent policy 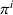
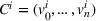
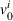

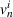
Single‐agent MDP notation
Analogously to Guillet et al. (2022), we model each driver's individual search process as a single‐agent finite‐horizon MDP. Let 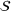
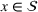
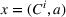
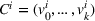
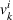
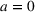
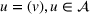
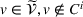
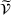
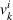
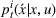
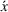
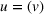
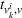
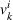
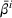
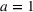
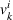
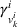
Policy 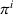
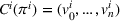
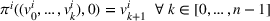
Agent i aims to find a policy 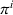
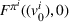
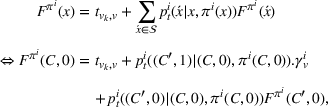
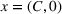
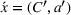
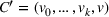
Transition functions:
To define our transition functions, we recall that station occupancy observations are persistent for the whole planning horizon and a priori availability probabilities are identical for all agents by assumption, which leads us to the following observation: If the first station v visited by j is available, j stops and charges there, otherwise v is occupied and remains occupied during the search horizon. Accordingly, v will never be available to another agent i who intends to visit station v after j. More generally, the probability that v is available to agent i equals the probability that all agents j intending to visit v before i (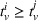
Formally, we denote the probability that station v is available for agent i at time t with 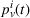
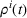
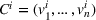
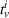
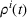
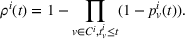
Then, 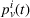
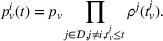
We now define the user‐dependent transition function as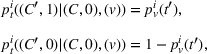
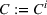
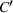
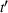
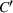
In a single‐agent setting, transition functions are independent of other agents planned actions and simplify to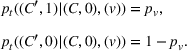
System evaluation cost
With 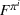
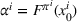
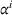
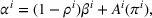
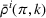
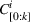
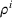
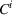
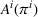
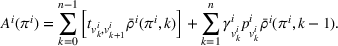
We define the cost Let policy π be a set of single‐agent user‐independent policies, such that 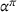
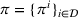
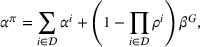
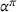
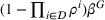
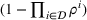
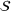
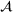
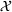
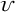
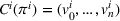
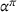
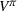
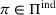
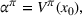
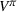
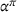
Proposition 1 simplifies the representation of the centralized MDP to a set of single‐agent MDPs, which enables us to devise decentralized online algorithms in Section 4.
ONLINE SOLUTION PLANNING
In the following, we present our online heuristics to process sequentially revealed charging requests, that is, drivers entering the system are unknown ahead of time. Accordingly, the set of agents 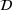
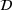
We note that the station occupancy–sensitive variant of our algorithms is clearly also applicable to short time horizons and will yield similar results. However, from a practical perspective, the station occupancy–sensitive implementation is computationally more costly, and should only be used if necessary.
Static policy planning
For static policy planning, we focus on decentralized decision‐making settings (see Section 2). We plan each agent's search path with a modified version of the stochastic search algorithm developed in Guillet et al. (2022), by taking into account the latest available information, that is, the latest shared visit intentions or the latest availability observations. In the following, we first briefly outline our algorithm (Section 4.1.1) in its basic variant without any information sharing, before we detail the required changes to account for observation sharing (Section 4.1.2), visit intention sharing (Section 4.1.3), or both (Section 4.1.5).
No information sharing (D)
This setting corresponds to a (fully decentralized) single‐agent setting, in which each agent is unaware of any prior requested search paths and availability observations. In practice, this setting equals planning routes on individual noncommunicating navigation devices or with a stateless navigation service platform, which does not retain information about past requests. Here, each agent aims to minimize her individual cost 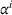
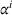
In general, a multilabel setting algorithm propagates partial policies to find a cost‐optimal policy, maintaining a list of all explored and nondominated partial policies in cost‐increasing order. A partial policy describes a given search path starting from the initial vertex v
0 and ending at v. We associate each partial policy with a label 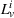
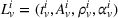
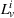
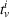
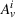
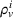
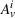
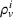
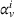
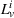
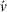
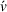
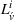
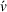
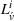
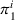
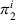
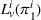
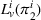
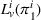
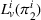
Finally, the labeling procedure returns the—nondominated—minimum‐cost label, that describes the search policy 
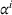
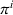
Occupancy observation sharing (DO)
In this setting, each agent i knows about occupied stations observed by other agents prior to her search. To account for this knowledge, we remove observed occupied stations from an agent's action space because occupied stations cannot be freed up during the remaining planning horizon. Accordingly, an action u for i consists of the single‐station selection decision 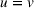
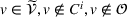
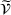
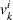
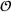
Visit intentions sharing (DI)
In this setting, an agent i knows all station visit intentions of agents who started their search prior to i, that is, all 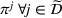
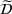
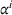
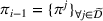
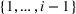
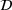
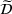
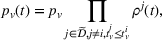
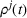
Each agent i uses the information about other agent's visit intentions to individually optimize her own search path, which may occur at the detriment of the agents that started their search earlier. In some cases, agent i may bypass another agent j by visiting the intended stations of j before j's expected visit times.
Collaborative intention sharing
To avoid the selfish use of intention sharing, we design a hierarchical solution method such that agents minimize their search times without compromising other agents' success. Here, agent i does not optimize her search path with respect to her individual cost; instead she optimizes her search path with respect to the cost of the subsystem that includes herself and already planned policies 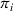
Formally, let 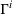
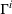
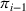
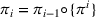
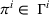
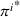
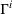
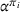
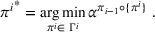
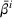
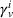
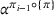
Intentions & occupancy observations sharing (DIO)
In this setting, an agent i combines both knowledge about past agents' observations and visit intentions when planning her search path at time 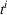
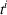
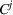
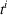
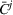
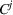
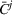
Dynamic policy planning
In the following, we describe the methodology for dynamic policy planning.
Focusing on a centralized decision maker (CIOd), we utilize two different algorithms to dynamically solve the large‐scale MDP introduced in Section 3.1. The first algorithm is a rollout algorithm (ro) with a one‐step decision rule as described in Goodson et al. (2017), which is known to provide high‐quality solutions in similar settings. This rollout algorithm explores the MDP solution tree partially, using a base policy to approximate the value function. In each state, the algorithm selects the action that yields the lowest approximated cost. The second algorithm bases on a dynamic implementation of our hlc algorithm (see Section 4.1.3). Instead of selecting the next best station visit based on a partial MDP solution tree exploration, this algorithm (re)computes an agent's individual search path using the latest observations and visit intentions available at each decision step. We then use the first station visit of the recomputed search path as the next station visit. We refer to this second algorithm as lro and note that it combines dynamic and offline planning similar to the work of Ulmer et al. (2019).
Rollout algorithm (ro)
Figure 2 details the pseudo‐code of our algorithm, which dynamically solves the MDP defined in Section 3.1. We initialize the set of active and terminated agents, the set of observed stations, and the vector that describes the state of each agent (l.1). A new request or a new station visit triggers a new decision epoch (l.3). In case this is not the first decision epoch, we update the status of the last deciding agent from 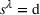
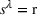
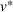
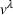
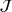
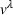
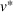
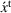
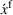
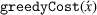
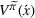
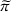
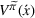
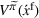
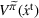
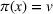
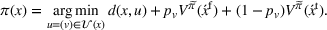
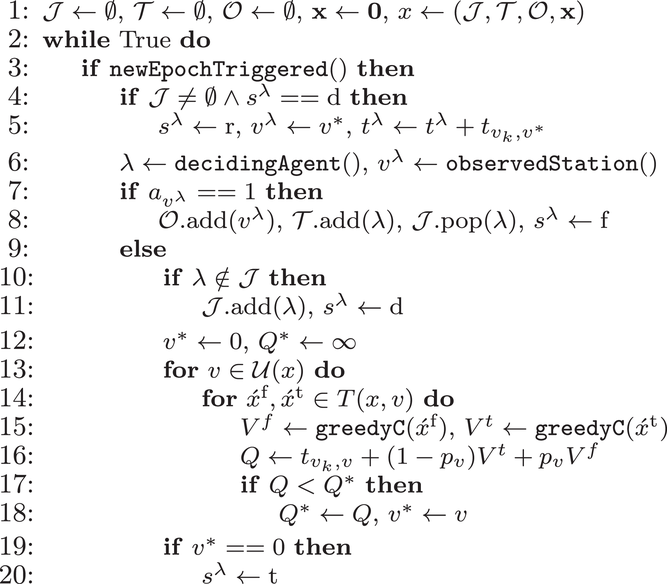
Online rollout algorithm.
Dynamic hlc algorithm (lro)
We now use the dynamic variant of the hlc algorithm to solve the CIOd setting and detail the pseudo‐code in Figure 3. Upon each agent's request, the algorithm plans a user‐independent policy and dynamically refines it at each agent's decision epoch using the latest updated information, that is, station occupancy observations and visit intention updates.

Label‐based heuristic (lro).
Similar to the online rollout algorithm, we initialize our variables and compute a visit recommendation each time an agent starts her search or visits an occupied station. We add the agent to the set of terminated agents if it finds an available station (l.7 & 8). In addition, we initialize the set Π that contains for each active agent 
The procedure 
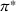
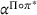
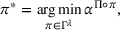
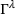
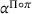
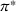
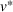
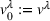
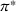
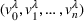
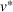
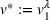
In the decentralized decision‐making settings with observation sharing (DOd), we compute an agent's search path using the algorithm developed for the static planning setting DO. However, we recompute the initially planned search path each time the agent visits an occupied station, using the latest observations shared by all agents
Long‐term planning horizon
In the following, we discuss how to relax the station occupancy persistency assumption. To this end, we distinguish occupancy observation information that corresponds to (i) stations observed as temporarily occupied (e.g., due to ICEing), (ii) available stations selected for charging by navigated drivers during their search, and (iii) stations being permanently blocked (e.g., due to connector deficiency).
In the first case, we assume that stations observed as occupied start to recover their availability immediately after the occupancy observation, following a time‐dependent exponential function (cf. Guillet et al., 2022) defined as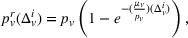
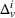
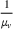
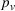
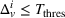
In the second case, we assume stations to be occupied during a fixed period of time corresponding to a car charging, and to recover their initial probability afterwards. In this case, the station is available upon the agent's departure and the probability availability decreases from 1 to her initial value 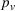
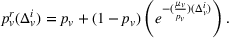
In the third case, stations remain occupied, and occupancy observations do not outdate.
We can immediately apply such recovering probabilities in pure observation‐sharing settings (DO, DOd) or in the centralized setting (CIOd). In practice, implementing these changes requires timestamped observations for all of the three formerly mentioned cases.
For intention‐sharing settings (DI & DIO), we need to account for recovering probabilities when expressing user‐dependent probabilities (cf. Equation 8). Here, we recursively express the probability 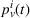

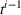


EXPERIMENTAL DESIGN
To analyze the effectiveness of the different coordination strategies, we conduct extensive numerical simulation experiments on real‐world test instances for the city of Berlin. In the following, we first detail our instance generation, before we describe additional benchmark algorithms, and elaborate on the metrics used to evaluate our algorithms' performance.
Instance generation
Besides the charging station availability distribution, the ratio of candidate stations per number of drivers and the departure time horizon are the main factors that impact our results. Accordingly, we vary the number of drivers, the global and individual search area dimensions, and the planning horizon to create a diverse set of scenarios as follows.
To account for varying spatial overlaps in between multiple drivers' search areas as well as for a varying number of drivers, we randomly draw departure locations within a radius of 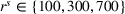
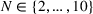
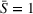
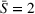
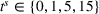
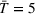
To analyze the impact of the varying charging station availability, we consider a low and a high charging station availability scenario. We generate those scenarios based on probability distributions centered on an expected mean 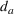
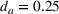
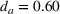
We analyzed the sensitivity of our algorithms with respect to the penalty term 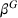
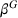
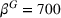
We further consider agents' heterogeneity to account for both heterogeneous and homogeneous use cases. We focus the main results discussion on the homogeneous agents use case, because a service provider does not want to bias the search toward single agents by considering heterogeneous parameters in practice. Accordingly, we set the station's utilization cost 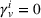
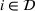
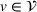
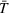
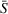
While our main results discussion focuses on the impact of coordination in a short planning horizon with an at‐most 15 min departure time window, we further analyze the impact of relaxing our station occupancy persistency assumption by considering a larger departure time window of 180 min.
Benchmark algorithms
To evaluate the performance of our online heuristics (hl, hlc, ro, lro), which we introduced in Section 4, we introduce two naive benchmarks to compare the quality performances of more advanced coordinated search methods. In D‐gr, drivers visit the closest station independent of any other drivers, whereas in DO‐gr, drivers visit the closest station, which has not yet been visited by any of the previously planned drivers.
Furthermore, we evaluate the quality performances of ro and lro in the centralized setting (CIOd). Since the MDP is too large to be solved optimally, we benchmark both policies against a myopic greedy algorithm CIOd‐gr and the optimal solution obtained in a deterministic and offline setting, that is, a perfect‐information setting (PI‐op), as suggested in Powell (2009). To analyze the quality loss in the centralized setting due to not anticipating charging requests, we further implement our ro algorithm in a stochastic setting (OFF‐ro) with requests known ahead of time.
In CIOd‐gr, we greedily decide on the next station visit 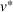
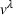
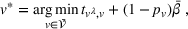
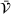
In PI‐op, we assume the charging demand, that is, all drivers' departure time and location, to be known for the overall planning horizon. We then compute for each realization 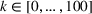
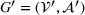
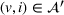
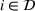
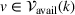
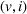
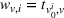
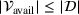
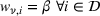
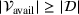
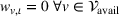
Performance evaluation
For each test instance, we successively compute the search path (static planning) or next station visit (dynamic planning) for all drivers, according to their departure order and the selected setting. We then evaluate the performance from both a driver and a system perspective, based on 100 simulation runs for both low‐25 and high‐60 scenarios. From a driver perspective, we compute the realized search time 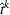
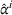
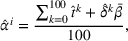
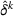
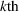
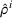
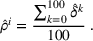
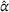
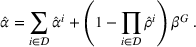
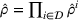
RESULTS
We first discuss our results from a system perspective (Section 6.1) before we focus on a driver perspective (Section 6.2).
System perspective
In the following, we first analyze the impact of collaboration in intention‐sharing settings, before we focus on the impact of dynamic planning in observation‐sharing settings. We then benchmark our algorithms for the centralized setting, and finally draw general conclusions on the performance of all possible algorithmic settings.
Collaboration in intention‐sharing settings
To analyze the benefit of collaboration, we compare the performances of hl and hlc (see Section 4.1.3) in the DI setting, with respect to individual drivers' costs 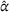
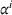
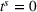
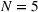
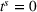
Comparison of hl and hlc in the DI setting for
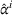
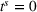
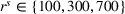
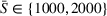
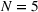
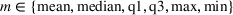
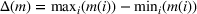
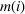
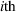
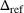
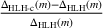
As can be seen in Figure 4, solutions obtained with hlc outperform the solutions obtained with hl on average with respect to both the system cost Visit intentions sharing can—and should—be used collaboratively. Without collaboration, visit intention may favor selfish solutions that negatively affect early departing drivers' search paths.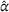
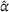
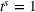
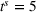
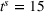
Dynamic planning for decentralized observation sharing
We analyze the impact of dynamically replanning solutions in the observation‐sharing setting. Table 2 compares the system cost 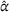
System cost comparison between static and dynamic decentralized policy planning.
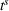
The table shows 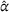
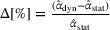
As can be seen, the effectiveness of dynamic and static planning depends on the length of the drivers' departure time horizon: If Without intention sharing, dynamic observation sharing in addition to static observation sharing improves the system performances for short departure time horizons by decreasing cost 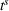
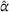
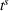
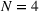
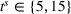
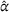
Centralized planning
In the following, we compare the performance of CIOd‐ro's and CIOd‐lro's policies to the greedy (CIOd‐gr) and offline (PI‐op) benchmark described in Section 5. Here, CIOd‐gr provides an upper bound to CIOd‐ro and CIOd‐lro, which allows to analyze the performance gain by looking ahead (C‐ro & C‐lro) rather than myopically deciding (CIOd‐gr). Contrary, PI‐op provides a lower bound for each availability realization, as all uncertain information—station availability and future charging demand—is known, allowing to study an artificial perfect information setting. Appendix E in the Supporting Information further analyzes the quality loss due to not anticipating unseen charging requests ahead. Figure 5 shows the detailed distribution of the realized cost 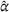
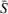
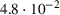
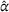
Distribution of the realized system cost
As can be seen, both CIOd‐ro and CIOd‐lro outperform the myopic policies (CIOd‐gr) by decreasing cost 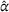
The cost reduction depends however on the search radius On average, the lro algorithm decreases the cost 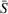
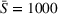
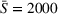
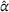
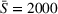
General performance evaluation
We compare the performances of all decentralized strategies, D‐l, DI‐hlc, DO‐hl, DIO‐hlc, and DOd‐hl, the best centralized strategy CIOd‐lro, and the two naive benchmarks D‐gr and DO‐gr. Figure 6 provides a comparison of all settings with respect to the system cost 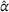
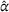
Average realized system cost
As can bee seen, an advanced search strategy without coordination (D‐l) already decreases the system cost obtained with a naive search strategy and no information sharing (D‐gr) by 13% on average. With coordination, the DO‐hl setting decreases the cost compared to the cost obtained with D‐gr by 25% in a static setting and by 29% in a dynamic setting (DOd‐hl), while DI‐hlc and DIO‐hlc lead to a 36% reduction, and CIOd‐lro yields a 38% cost reduction. These average cost reductions decrease when comparing coordinated strategies against a greedy search strategy with observation sharing (DO‐gr), but remain significant. Compared to DO‐gr, DO‐hl yields a 15% cost reduction, DOd‐hl a 20% cost reduction, both DI‐hlc and DIO‐hlc a 28% cost reduction, and finally CIOd‐lro yields a 30% cost reduction.
In the remainder, we ignore the two naive benchmarks due to inferior performance compared to the other algorithms. Accordingly, we now refer to a strategy, that is, the algorithm used in a given setting, only by the corresponding setting to keep the notation concise, that is, we refer to DI‐hlc as DI or to D‐l as D.
In‐depth comparisons between these remaining uncoordinated and coordinated settings show that DOd decreases the cost obtained in D by 18% while both DI and DIO decrease it by 26%, and CIOd leads to a 28% decrease. The static observation‐sharing setting DO performs on average worse than both static intention‐sharing settings due to the algorithm's sensitivity to the departure time horizon Compared to an uncoordinated setting (D), decentralized static intention sharing (DI, DIO) reduces 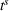
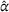
Figure 7 compares D, DI, DO, DIO, DOd, and CIOd with respect to cost 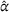
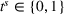
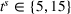
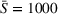
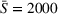
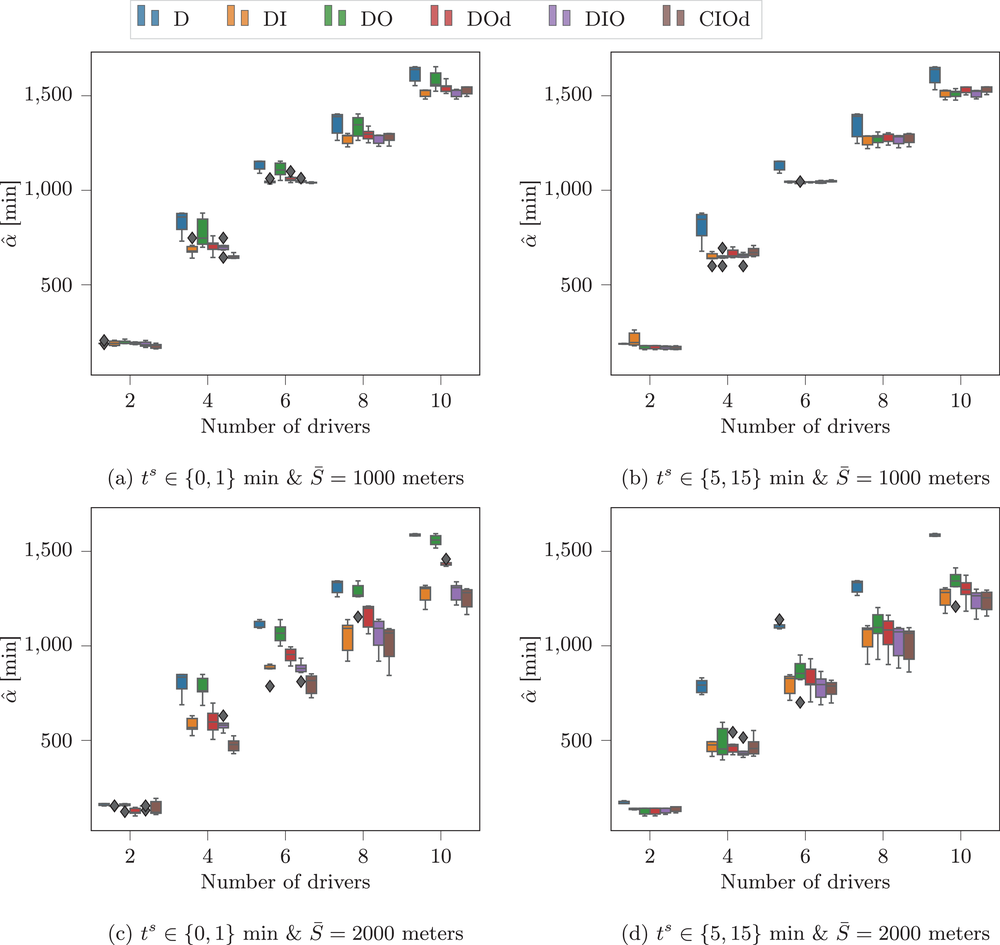
Comparison of decentralized and centralized decision making in low‐availability scenarios.
Numerical results show that the system cost 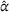
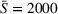
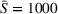
For short departure time horizons (see Figure 7a,c), we observe that pure intention sharing (DI) slightly outperforms combined observation‐ and intention sharing (DIO) for static policies, mostly when 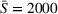
For large departure time horizons (see Figure 7b,d), DIO improves over DI and even outperforms CIOd for smaller search areas. Notably, DO performs very similar to the other coordinated settings in this case. As the departure time horizon increases, the likelihood that searches temporally overlap decreases, which in turn decreases the benefits of intention sharing in addition to observation sharing. We further observe that DO slightly outperforms DOd in this case for small search areas (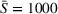
Figure 8 in Appendix E in the Supporting Information contains similar analyses for high‐availability scenarios. While these results show similar trends in general, we note that the benefit of dynamic observation sharing in a decentralized setting (DOd) is less consistent in this scenario for smaller departure time horizons. Sharing occupancy observations in addition to intentions is not beneficial for almost simultaneous searches, that is, 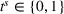
For larger departure time horizons, that is, 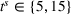
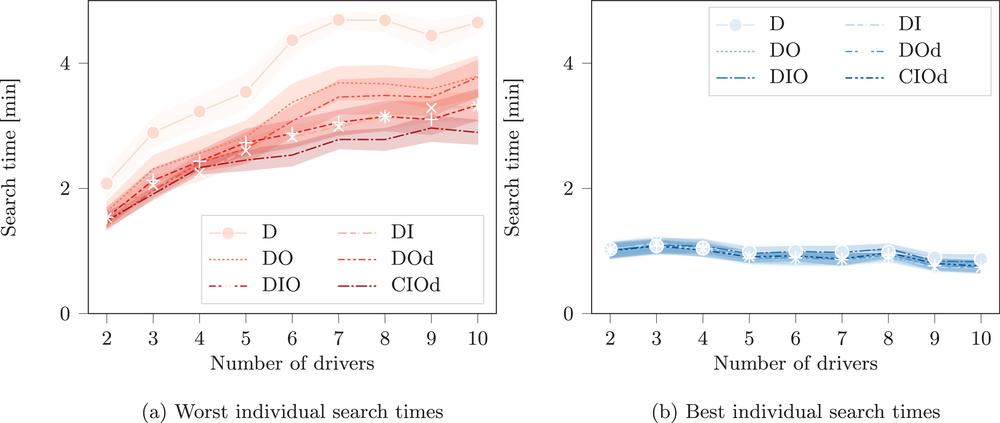
Distribution of the worst and best search times in the low‐availability scenario.
Single‐driver perspective
In the following, we evaluate how coordination impacts an individual driver's solution, before we analyze the impact of driver heterogeneity. Finally, we analyze the benefits of coordination in a longer planning horizon, while relaxing the persistent charging station occupancy assumption.
Drivers' benefits of coordination
We refer to the uncoordinated solutions (D) as selfish solutions, in which a driver obtains her solution independently, without additional information and in her own best interest. First, we analyze the worst and best realized solutions obtained among all drivers for each test instance. For all decentralized settings (DI, DO, DIO, DOd) as well as for the centralized dynamic setting (CIOd), we compare the results to the uncoordinated setting (D). We then analyze the impact of a driver's departure position on her individual solution, before we analyze each driver's success rate and search time deviation between the selfish and any coordinated solution.
Figure 8 shows the mean value of all lowest and highest realized individual search times and a corridor corresponding to a 95% confidence interval over all test instances of the low‐availability scenario for each analyzed setting. As can be seen, the lowest search times are comparable with and without coordination, such that a selfish solution does not improve the best case scenario with respect to individual search times. However, all coordinated settings decrease the maximal individual search times, in particular by 30% in DI and DIO, and by 35% in CIOd. Similarly analyzing performances with respect to individual success rates, there exists a minor trade‐off between the best and the lowest individual success rates. While the highest individual success rate appears to be slightly higher in a selfish environment, the lowest success rate increases significantly in all coordinated settings, by up to 30%. We note that CIOd yields the most robust solutions, by providing lowest worst individual search times and highest worst individual success rates. Coordinated searches outperform selfish searches, because they significantly improve the worst‐possible solution that a driver may obtain while preserving her best‐possible solution.
Figure 9 shows the individual costs 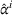
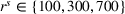
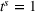
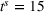
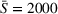
Single‐agent cost ordered by departure times in a low‐availability scenario (low‐25) with larger search radius (
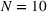
As can be seen, coordination reduces a driver's search cost (nearly) independent of her departure position. In some specific cases (e.g., for the first driver with At the exception of early departing drivers, the individual solution obtained by a driver with coordination outperforms the one obtained without coordination, independent of the driver's departure position.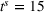
Table 3 shows the relative individual search time deviation (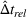
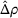
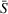
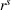
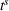
Individual search time and reliability improvements with coordination.
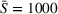
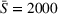
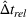
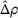
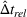
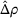
The table compares the average search time deviation 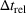
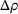
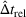
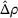
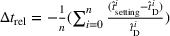
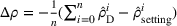
There exists a trade‐off between search time savings and the reliability improvement. For small search areas (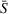
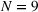
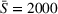
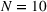
Impact of driver heterogeneity
To analyze the impact of driver heterogeneity, we split drivers into two distinct groups: The first group contains all drivers with an odd departure position, while the second group contains all drivers with an even departure position. Figure 10 shows the impact of drivers with heterogeneous search radii in the CIOd setting by analyzing three cases: In the first case (10a), drivers of the first group have a smaller search radius (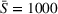
Impact of heterogeneous search radii on drivers' search times.
In the second case (10b), drivers of both groups have a smaller search radius (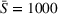
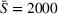
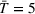
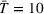
Impact of heterogeneous time budgets on drivers' search times.
As can be seen, the distribution of individual search times in homogeneous settings is (nearly) independent of the respective group. This is not the case in heterogeneous settings. Here, drivers that perform a more constrained search, that is, have a smaller search radius (see Figure 10a) or a smaller time budget (see Figure 11a), obtain lower search times compared to drivers that perform a less constrained search, especially in the first case. To reduce potential visit overlap, drivers with a larger search radius increase their chances of finding unoccupied stations by visiting far‐distanced stations that are less affected by potential overlaps, which then contributes to increase their search times. Finally, we note that performing searches with homogeneous parameters appears to be preferable from a practitioner's perspective, in order to provide fair and consistent service to all customers. Time budget or search radius heterogeneity favors drivers with lower time budget and lower search radius.
Coordination in longer planning horizons
In the following, we analyze the impact of coordination in a longer planning horizon. To keep the discussion concise, we focus our analysis on the best performing strategy, that is, the CIOd‐lro. We compare three charging demand distribution scenarios, see Figure 12. In SC1, drivers are steadily entering the system, with five requests per 15 min time interval. In SC2, each fourth request is skipped, whereas in SC3, every fourth and fifth requests are skipped. The first scenario reflects a homogeneous demand distribution, while the other scenarios reflect heterogeneous demand distributions, similar to peak demand that arises in practice.
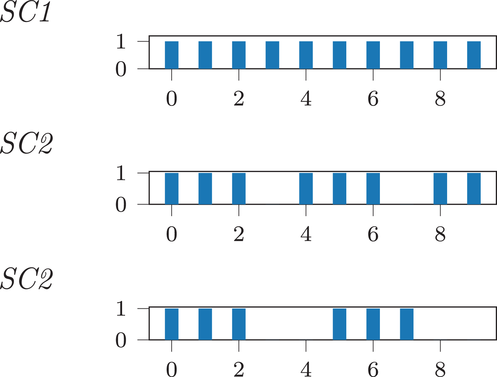
Requests distribution scenario. Note: The figure shows for each scenario the requests distribution pattern, with each (missing) bar corresponding to a (missing) request.
Table 4 compares the relative cost improvement obtained on average between coordinated (CIOd) and uncoordinated decentralized (D) planning in both short (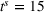
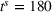
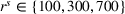
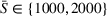
Relative cost improvement for CIOd over D.
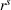
The table shows the relative improvement of the realized system cost 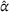
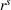
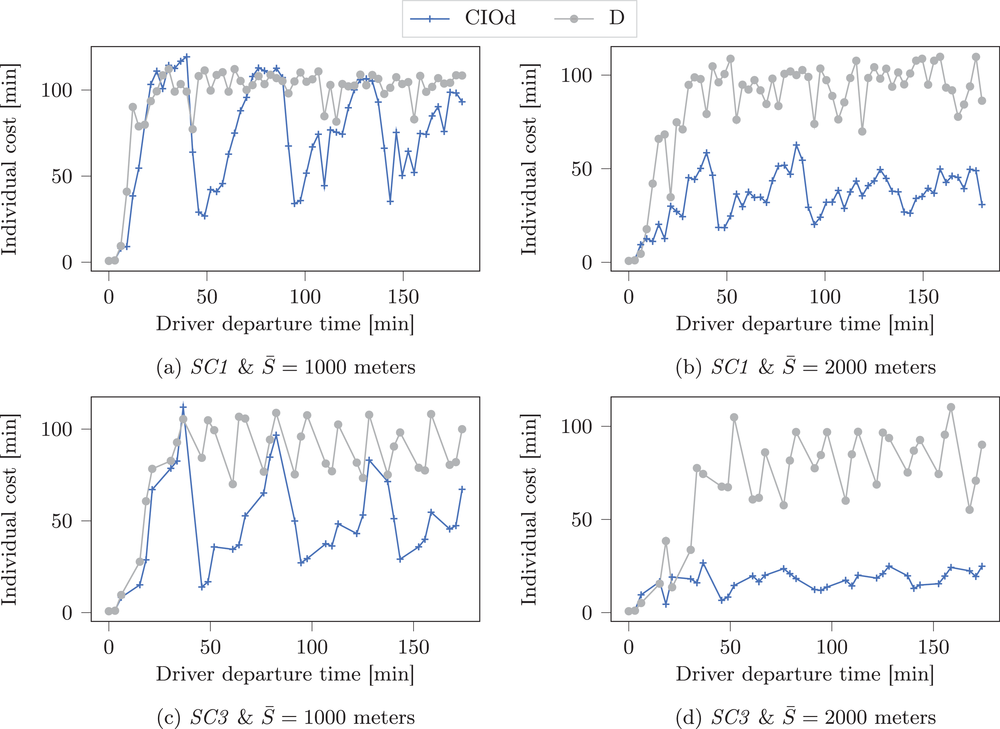
Comparison of D and CIOd in high‐availability scenarios for a 3‐h planning horizon.
As can be seen, coordination significantly improves the overall search performances in longer horizon settings. Comparing the results of the short and long planning horizon settings (cf. Table 4), our results show that cost savings in the long planning horizon setting decrease for a limited departure area (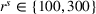
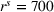
However, additional information related to stations getting freed can be shared, such that the results illustrate the trade‐off that exists between the performance loss due to the availability decrease and the performance gain due to the information increase. Our results further show that a decreased charging demand (i.e., SC3) increases the cost reduction obtained with coordination in long planning horizons, with an up to 46% 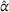
Finally, we observe that long planning horizon results reveal cyclic patterns for individual drivers cost (see Figure 13). These patterns show a decreasing amplitude for larger charging demand heterogeneity or search radii.
This effect results from early drivers having a higher chance of reaching closely related charging stations and thus obtaining lower individual cost than succeeding drivers. When these stations are freed after 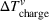
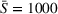
CONCLUSION
In this paper, we studied the multiagent charging station search problem in stochastic environments, which we define as a single decision maker MDP. We showed that by constraining agents' individual policies to be executed independent of each other, we can simplify the global MDP representation to a set of single‐agent MDPs. We then introduced several online algorithms that solve centralized and decentralized decision‐making settings, applicable to static and dynamic policies, and different levels of information sharing. Specifically, we analyzed the benefits of intention sharing, that is, drivers sharing their planned visits, observation sharing, that is, drivers sharing observed occupancies of charging stations, or both.
Using a case study for the city of Berlin, we analyzed the benefits of coordination between multiple agents' search: Our results show that coordination increases the system performance while individually benefiting each driver in general. Analyzing the performance from a system perspective, our results show that a static decentralized coordination strategy achieves a 26% cost decrease compared to an uncoordinated scenario, as long as drivers share visit intentions. A centralized coordination strategy requires higher computational load but achieves only 2% additional cost decrease. We further highlight the benefit of enforcing collaboration in intention‐sharing settings. Moreover, our results show that observation sharing performs on average worse than intention sharing. However, observation sharing requires less data and computational resources, and may be used to derive more accurate availability probabilities, which makes it interesting for practitioners. We show that from a driver perspective, coordination may save up to 23% of a driver's search time, while increasing her search's success rate by 9% on average. We find that coordinated searches outperform uncoordinated searches for individual best and worst case scenarios. Finally, we observe similar positive effects of coordination in a 3‐h planning horizon, with a centralized coordination strategy achieving 25% cost reduction on average compared to an uncoordinated scenario.
One comment on our study is in order. We assumed a nonadversarial setting such that agents always follow their navigation device visit recommendations, which may however be challenged by drivers' behavior in practice. If drivers deviate from the recommended visits, intention sharing might become misleading. Analyzing competitive searches within a game‐theoretical setting by relaxing the nonadversarial assumption opens a new avenue for further research in this context.
Footnotes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.