
Abstract
Academic approaches considering demand uncertainty in lot sizing are seldom used in practice. Industry typically implements deterministic models and accounts for uncertainties by using a rolling‐horizon planning framework with frequent forecast updates. This paper bridges this gap by proposing a stochastic lot‐sizing methodology adapted to rolling‐horizon processes. Using the martingale model of forecast evolution (MMFE), we are able to anticipate the forecast updates from rolling‐horizon planning in stochastic lot sizing. Our formulation is extended with production recourse to reflect the replanning flexibility of rolling‐horizon planning. Extensive simulations on both synthetic and real‐world data show the value of forecast evolution models. Forecast evolution models reduce actual costs by 14% on average compared to traditional deterministic planning. The advantage of the extended model with production recourse depends on several factors including capacity, correlation, and uncertainty. Sensitivity analyses show that recourse can reduce costs by an additional 3% on average and up to 10% in specific settings. Using real‐world and synthetic data, we provide the first analysis of the value of additive and multiplicative MMFE‐based planning models when the true forecast evolution process is unknown. We show that, contrary to the existing consensus, the additive model performs more robustly than the multiplicative model on a wide array of problem settings.
Keywords
INTRODUCTION
Demand uncertainty has been studied extensively in stochastic lot sizing using probability distributions to model the uncertain demand. However, the use of these models in industry has been limited. A major shortcoming is that they cannot be integrated properly into the periodic planning processes that manufacturing companies use to update demand forecasts. Thus, the substantial information technology (IT) support, human resources, and time dedicated to forecasting are ignored. In fact, previous research on stochastic lot sizing has neglected the value of forecasts in generating demand distributions altogether. Stochastic lot‐sizing approaches suitable for industry adoption should exploit the data contained in historic forecasts. Demand distributions must be updated dynamically based not only on the latest demand realizations but also on forecasts to fit rolling‐horizon processes.
The use of forecast evolution models can bridge between stochastic lot‐sizing models and rolling‐horizon planning in industry. Different from demand distributions used in traditional stochastic lot sizing, they model demand uncertainty as encountered in rolling‐horizon planning. The martingale model of forecast evolution (MMFE) developed by Graves et al. (1986) and Heath and Jackson (1994) models future forecast changes as a stochastic process. Two methods for modeling the forecast evolution process according to the MMFE have been proposed. The additive model measures the difference between successive forecasts and assumes that these differences follow a multivariate normal distribution. The multiplicative model measures the ratio between successive forecasts and assumes that this ratio follows a log‐normal distribution. While it has been argued that the multiplicative model is more relevant when demand fluctuates over time (Hausman, 1969; Heath & Jackson, 1994), extensive comparisons of the two MMFE models are still missing. In particular, the cost of modeling error, that is using the additive or multiplicative model when the true process is unknown, has not been evaluated so far. Hence, MMFE models can be estimated directly from the history of past demand and successive forecasts revisions routinely collected in industry.
Demand forecasting is typically an organizational alignment step that is part of the sales and operations planning processes. Hence, the forecasts observed in each planning period can be a mix of expert judgmental forecasts and forecasts obtained from forecasting algorithms. Chen and Lee (2009) review how the MMFE generalizes several classical prediction models such as autoregressive moving average models. Here, the MMFE parameters can be determined exactly. Still, the strength of MMFE lies in its ability to integrate a combination of model‐based quantitative forecasts and expert‐based judgmental forecasts (Heath & Jackson, 1994). In this context, MMFE model parameters have to be estimated from historical data. Yet, despite the central role of data, the application of MMFE to real‐world cases is rare and many questions remain open regarding the applicability and value of forecast evolution models.
Lot‐sizing approaches suitable for rolling‐horizon planning must not only account for the forecast updating process but also for the ability of planners to adapt production plans. Ignoring this replanning opportunity leads to overly conservative decisions and ultimately higher costs. In the stochastic lot‐sizing literature, the replanning opportunity has been captured by introducing recourse production decisions that react to demand observations. With MMFE‐based models, recourse decisions respond not only to the realized demand but also to forecast updates for the entire horizon, providing richer information and representing industrial planning processes. Lot‐sizing approaches that capture this planning flexibility while maintaining computational tractability are lacking. Moreover, even though rolling‐horizon schemes shape planning processes in manufacturing companies, only limited attention has been given to the performance of stochastic lot‐sizing models in rolling‐horizon planning. Hence, the value of these methods compared to traditional deterministic planning is not always clear.
This work is motivated by our collaboration with a large producer of chemicals used in agriculture that manages expensive multipurpose equipment in the face of an uncertain demand. Demand has a yearly seasonal pattern, which is especially challenging due to uncertainties in both the volume and timing of the peak selling season. In a similar setting, Schlapp et al. (2022) study a stylized model without forecast evolution and production constraints. However, since capacity is limited, production often starts ahead of the peak season, which can lead to substantial on‐hand inventory. Moreover, expensive cleaning operations have to be conducted each time the equipment is set up for a different product family. The company's planning problem thus exhibits the key trade‐off between demand satisfaction, inventory costs, and setup costs that is captured by a lot‐sizing problem. Because early forecasts often have poor accuracy, planning is implemented in a rolling‐horizon fashion to benefit from frequent forecast updates.
We contribute to the state of the art in the following ways. We elevate modeling demand uncertainty from distributions to MMFE in lot‐sizing models to account for the central role of forecast evolution processes in real‐world rolling‐horizon planning. We show that both the additive and the multiplicative MMFE‐based lot‐sizing models can be solved efficiently using existing linearization techniques. The stochastic planning models can be solved to optimality without resorting to approximations for capacity allocation. Our modeling approach covers important real‐world considerations including fixed setup costs, multiple products sharing limited capacity, and a complex correlation structure of the forecast updates. While we focus on the classical production planning problem of lot sizing, our solution approach is applicable to a wide range of problem settings. By showing that MMFE can be applied to rich production planning problems, we aim to foster the adoption of forecast evolution models in research and industry. We demonstrate the value of forecast evolution for lot‐sizing models in rolling‐horizon planning on synthetic and real‐word data. We show that stochastic models based on forecast evolution consistently outperform deterministic models in rolling horizon. On average, they reduce overall costs by around 14%. In contrast, stochastic models that only account for demand uncertainty but ignore forecasts and their evolution fail to reduce costs compared to simple deterministic models. These results clearly show that the evolution of forecasts must be considered in effective decision‐support systems for rolling‐horizon planning. We assess the strengths and weaknesses of the additive and multiplicative models. We analyze the performance when the true forecast evolution process is unknown but has to be estimated from data. We show that the additive MMFE is more robust in a wide array of problem settings, even when demand fluctuates over time. The multiplicative model, on the other hand, lacks robustness to unknown forecast evolution processes and can even lead to significant cost increases compared to the deterministic benchmark. The superior performance of the additive MMFE, also observed on real‐world data, refutes the previous consensus on the suitability of the two forecast evolution models. We develop an extended model that allows production recourse and measure the value of recourse in repeated rolling‐horizon simulations. We show that production recourse leads to around 3% cost savings on average. We also identify key parameters that influence the value of recourse such as the correlation of forecast updates of different products and time periods. When the forecast evolution process is positively correlated over products and negatively correlated over time periods, the value of recourse can be up to 10%. In our extended model, a high value of recourse can be obtained with small scenario trees, allowing for computationally efficient implementations.
In the following section, a brief review of related literature is presented. In Section 3, we introduce the additive and multiplicative MMFE and describe how they can be used to dynamically update the demand distributions over the horizon. In particular, we recall how to obtain the distributions of demand and cumulative demand from the forecast evolution process and analyze the effect of forecast update correlation on the variance of the cumulative demand for additive and multiplicative MMFE. Section 4 provides the MMFE‐based lot‐sizing formulation. We then introduce a multistage formulation that allows production recourse with a scenario‐based representation of demand uncertainty. In Section 5, we assess the value of forecast evolution models and the value of recourse in extensive rolling‐horizon simulations using synthetic and real‐world data. Our findings are summarized in Section 6, where we also provide suggestions for future research.
LITERATURE REVIEW
In this section, we review the literature on stochastic lot sizing and forecast evolution. We locate our work at the intersection of the two research streams and highlight gaps in the existing literature.
Stochastic lot sizing and rolling‐horizon planning
The analysis of the value of adapting lot‐sizing decisions in rolling‐horizon planning can be traced back to Bookbinder and Tan (1988), who introduce different strategies to update decisions. Using the static strategy, decisions are determined all at once and fixed over the planning horizon. The dynamic strategy, on the other hand, allows decisions to be adapted as new information is observed in rolling horizon. The authors emphasize that dynamic planning approaches are especially relevant when demand distributions are dynamically updated in rolling horizon. Dynamic strategies can be implemented through scenario‐based formulations in which production decisions are set as recourse variables. Escudero et al. (1993) present several lot‐sizing formulations that allow increasing levels of recourse in a multistage scenario tree. Brandimarte (2006) investigates the value of scenario‐based stochastic lot sizing in rolling‐horizon planning by means of repeated simulations. They show that scenario models allow good performance through recourse decisions but require long computation times. Recently, Thevenin et al. (2020) use a combination of heuristics and advanced sampling techniques to implement dynamic strategies in a multiechelon lot‐sizing context.
Scenario‐based models are notoriously hard to solve. To improve computational performance, Helber et al. (2013) develop piecewise‐linear approximations (PLAs) of the expected inventory and backlog functions and show that they outperform scenario‐based formulations without recourse. These formulations have proved flexible and have been used in several production planning settings. Rossi et al. (2015) use PLA to determine the parameters of near‐optimal production policies. De Smet et al. (2020) include sequence‐dependent changeovers in a lot‐sizing and scheduling problem. Tempelmeier and Hilger (2015) and van Pelt and Fransoo (2018) introduce fill‐rate service‐level constraints. Sereshti et al. (2021) extend this work showing that PLAs can be used to formulate many types of service‐level constraints in stochastic lot sizing. However, PLA methods may lead to overly conservative production plans as they do not allow for recourse decisions. To incorporate the replanning opportunity in lot‐sizing problems, Tavaghof‐Gigloo and Minner (2021) integrate a heuristic in an extended PLA formulation and investigate its benefits in rolling‐horizon simulations.
A significant limitation of the above‐cited works is that they assume the demand distributions to be known. Yet, demand distributions are seldom available in practice. This problem was discussed by Klabjan et al. (2013) who propose nonparametric approaches to estimate demand distributions from past observations. Still, this work ignores forecasts and their updates stemming from the rolling‐horizon processes. We contribute to this research stream in two ways. First, we show that forecast evolution models can provide demand distributions that are dynamically updated in rolling‐horizon planning and readily integrated in lot‐sizing models using existing methods. Second, we extend existing PLA formulations to allow production recourse over discrete scenarios. Thus, we combine the strengths of PLA and scenario methods to allow flexible decisions while ensuring fast computation.
Forecast evolution models
Since the early analyses of forecast revision processes conducted by Hausman (1969) and Hausman and Peterson (1972), the MMFE has been applied to a wide variety of problems including defining supply contracts (Donohue, 2000), capacity planning (Boyacı & Özer, 2010), and inventory management (Bicer & Seifert, 2017; Iida & Zipkin, 2006; Özer & Wei, 2004; Wang & Tomlin, 2009; Wang et al., 2012). The aforementioned research focuses on determining optimal policies analytically but does not consider complex production planning settings such as managing multiple products with limited capacity and fixed setup costs for production. Further, it does not consider the rolling‐horizon implementation of production plans. In particular, unconditional production decisions that do not depend on demand scenarios should be determined over the short‐term horizon. This provides a reference plan that can be communicated to upstream and downstream partners in the supply chain in each review period. Pinçe et al. (2020) apply the findings of Wang et al. (2012) on multiplicative MMFE for multiordering newsvendor to a real‐world data set of a large product portfolio. They discuss the challenges of applying MMFE‐based planning models from real‐world data but do not investigate the out‐of‐sample value of their method when the true forecast evolution model is unknown.
A second research stream studies the rolling‐horizon implementation of forecast evolution models. Norouzi and Uzsoy (2014) determine the key properties of the uncertain demand under additive and multiplicative MMFE and derive the optimal base‐stock policy for a single‐product, uncapacitated planning problem with a chance constraint. Albey et al. (2015) extend this work with a heuristic that solves the multiproduct problem based on a predetermined capacity allocation. They evaluate the rolling‐horizon performance of the MMFE model in a real‐world case study in the semiconductor industry. Ziarnetzky et al. (2018) adapted the method to a multiplicative MMFE and evaluate it in rolling‐horizon planning with synthetic data. Albey et al. (2016) combine the model with a genetic algorithm to allocate capacity to products. They show the benefits of the improved allocation in a simulation study under additive MMFE. Ziarnetzky et al. (2020) perform extensive rolling‐horizon simulations to evaluate and compare the performance of the additive and multiplicative MMFE. The forecast evolution is set to follow either the additive or multiplicative MMFE and the forecast and production plan updates are performed in a rolling‐horizon fashion. However, the ability of MMFE models to generalize when the true forecast evolution process is unknown has not been studied so far.
We extend the research stream on MMFE by further relaxing the limiting assumptions of the model. We consider a general lot‐sizing setting with multiple products, limited capacity, inventory holding costs, and fixed costs for setup operations. The model does not rely on a predetermined allocation of capacity and can be solved to optimality. Further, we provide insights into the strengths and weaknesses of the additive and multiplicative MMFE, analyze their ability to generalize from historical data, and evaluate performance through rolling‐horizon simulations on both synthetic and real‐world data.
FROM FORECAST EVOLUTION TO DEMAND DISTRIBUTIONS
In this section, we introduce the additive and multiplicative MMFE as formalized by Heath and Jackson (1994). For each model, we recall how the probability distributions underlying the uncertain demand can be deduced from the stochastic forecast evolution process over the planning horizon. This fully describes the dynamic updating of the demand distribution as new forecasts are observed in rolling horizon. Then, we show how to obtain the distributions of the cumulative demand over the horizon by adapting the results from Norouzi and Uzsoy (2014). This step is essential to derive linearized lot‐sizing formulations that are tractable, as will be shown in Section 4. Finally, we analyze the effect of forecast update correlation on the cumulative demand variance for the additive and multiplicative MMFE.
Problem setting
Consider the rolling‐horizon planning of K products with a horizon of T periods. In each review period, updated forecasts are observed and used to calculate a production plan. Let
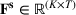
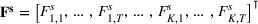
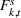
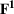
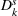
Additive MMFE
The additive MMFE describes the evolution of the forecast vector by the relation
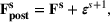
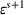
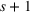
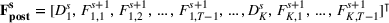
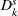
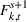
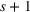
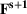
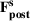
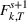
The forecast update vector follows a multivariate normal distribution
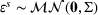
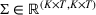
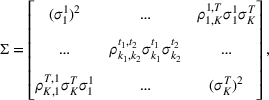
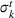
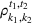
Demand distribution
The demand follows the same updating process as the forecast and is given by
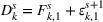
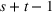
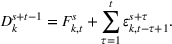
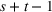
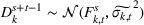
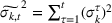
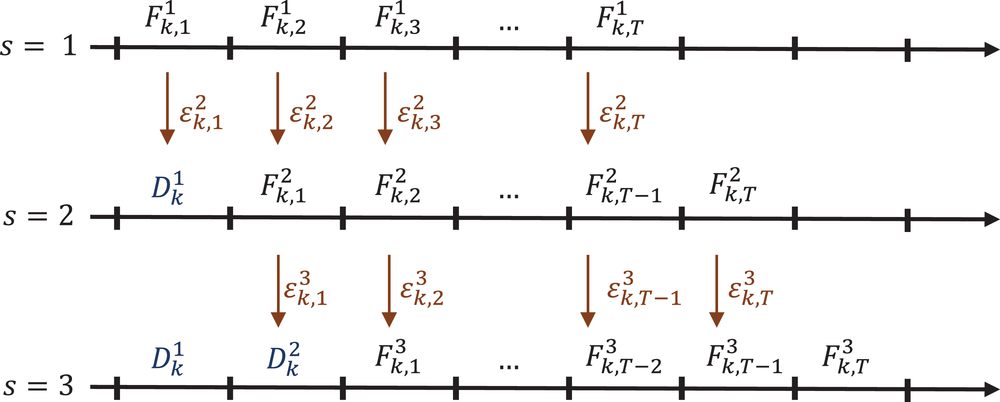
Demand and forecast observed at three successive review periods
Demand covariance
Although the forecast update vectors are observed independently in each review period, the update of different products and time periods described in Equation (1) can be correlated. It follows that the demand distributions of a product in different periods of the planning horizon may be correlated. In review period s, the covariance between the demands of product k in periods t
1 and t
2 of the planning horizon is given by
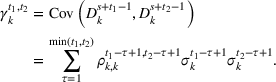
Cumulative demand distribution
The cumulative demand of product k in period t of the planning horizon at review period s,
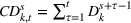
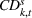
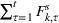
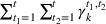
The variance of the cumulative demand depends only on the covariance of the demand distributions of the same product. The variance of the cumulative demand increases linearly with the forecast update correlation between two time periods. The cumulative demand distribution describes the demand uncertainty over the planning horizon. Determining the cumulative demand distributions allows the stochastic lot‐sizing problem to be solved with the formulation introduced in Section 4.
Multiplicative MMFE
In the multiplicative MMFE, the forecast evolution process follows the relation
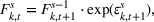
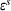
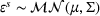
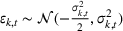
The variance of the forecast updating process depends both on the forecast update covariance matrix Σ and on the forecast vector
Demand distribution
The demand of product k in each review period s follows the same relation as the forecast update so that
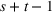
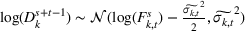
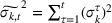
Demand covariance
The demands of product k in periods t
1 and t
2 of the planning horizon in review period s are correlated with covariance
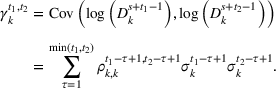
Cumulative demand distribution
Contrary to the additive case, there is no closed‐form expression for the cumulative demand since it is the sum of correlated log‐normal distributions. However, it has been observed that the sum of log‐normal distributions can be well approximated by a log‐normal distribution. To estimate the cumulative demand distributions with multiplicative MMFE, we follow the approach of Norouzi and Uzsoy (2014) and apply the Fenton–Wilkinson approximation (FWA). The method is attractive because of its computational simplicity and overall high approximation quality over a wide range of parameters. The approximation is based on matching the first two moments of the approximating log‐normal distribution with the moments of the sum of the correlated log‐normal distributions (Abu‐Dayya & Beaulieu, 1994).
Following the moment‐matching approximation, the cumulative demand
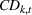
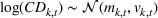
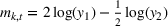
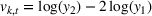
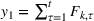
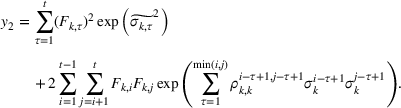
Influence of forecast update correlation on the cumulative demand variance
The variance of the cumulative demand has been shown to depend linearly on the forecast update correlation for the additive model. In the multiplicative model, although the relation between the forecast update correlation and the cumulative demand variance appears exponential, it is approximately linear over the relevant domain. Under multiplicative MMFE, the variance of the cumulative demand of product k in period t,
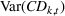
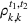
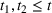
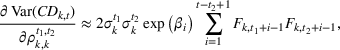
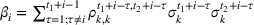
Proposition 1 implies that ignoring the correlation between demand periods can lead to under‐ (resp. over‐) estimation of the cumulative demand variance if the correlation is positive (resp. negative). The proof is provided in Supporting Information EC.1. The effect of the correlation coefficient is proportional not only to the variance but also to the forecast values. Thus, ignoring correlation has a greater impact for large forecasts. Moreover, Proposition 1 suggests that the multiplicative model is more sensitive to estimation errors of correlation parameters than the additive model when forecasts are large.
We analyze the evolution of the variance of the cumulative demand distribution with the forecast update correlation and compare the additive and multiplicative MMFE. We consider a single product planned over a horizon of
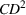
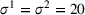
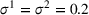
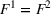
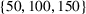
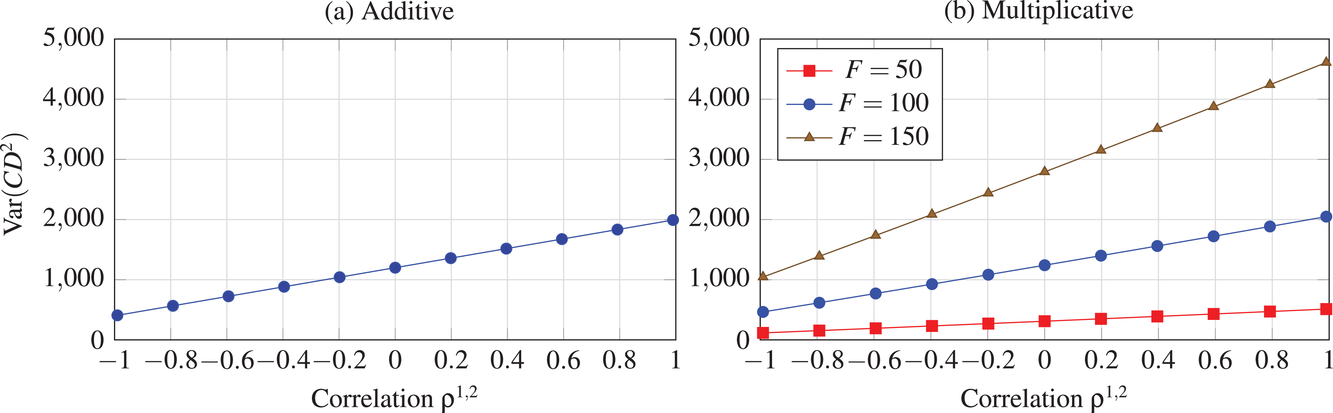
Evolution of variance with correlation coefficient for the (a) additive and (b) multiplicative MMFE
Summary
In this section, the multivariate forecast evolution process has been introduced for additive and multiplicative MMFE. The parameters of the resulting demand and cumulative demand distributions have been obtained. The cumulative demand distributions can be determined exactly for the additive model and approximately for the multiplicative model. Finally, we have analyzed the dependency of the cumulative demand variance on the forecast update correlation coefficient. In the next section, we derive efficient formulations for the stochastic lot‐sizing problem based on the cumulative demand distributions estimated from the MMFE.
INTEGRATING FORECAST EVOLUTION IN STOCHASTIC LOT SIZING
We integrate the additive and multiplicative MMFE in lot‐sizing problems through the cumulative demand distributions derived in the previous section. We introduce the PLA formulation that can be solved efficiently and extend the model with scenario‐based production recourse. The extended model combines the strengths of PLA and scenario methods, providing fast computations and flexible decisions.
Problem setting
In each review period, the planner determines the production quantity
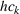
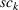
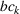
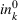
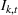
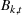
Linearization of inventory and backlog functions
To obtain tractable formulations, the PLA method has been developed. It evaluates the first‐order loss function at a selected number of breakpoints and determines the slope of the expected inventory and backlog between these breakpoints (Helber et al., 2013). Rossi et al. (2014) provide analytical bounds on the approximation error of PLA when the uncertain variable follows a normal distribution, which applies under additive MMFE. They show that the approximation error is small with only a few linearization points.
The first‐order loss function of a real variable x and random variable ω with p.d.f. ϕ and c.d.f. Φ is defined as
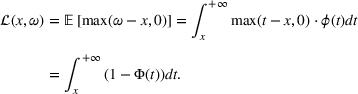
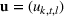
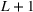
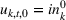
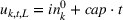
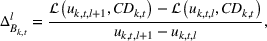
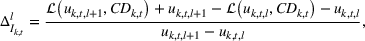
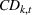
Section 3 showed that the cumulative demand follows a normal and log‐normal distribution for additive and multiplication MMFE, respectively. Calculating the slopes of the L segments of the expected inventory and backlog requires evaluating the first‐order loss function
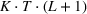
The PLA of two demand distributions following a normal and log‐normal with equal mean and variance is shown in Figure 3. For the chosen parameter values, the functions for both distributions are very similar. The figure shows that the expected inventory and backlog functions can be already well approximated with only
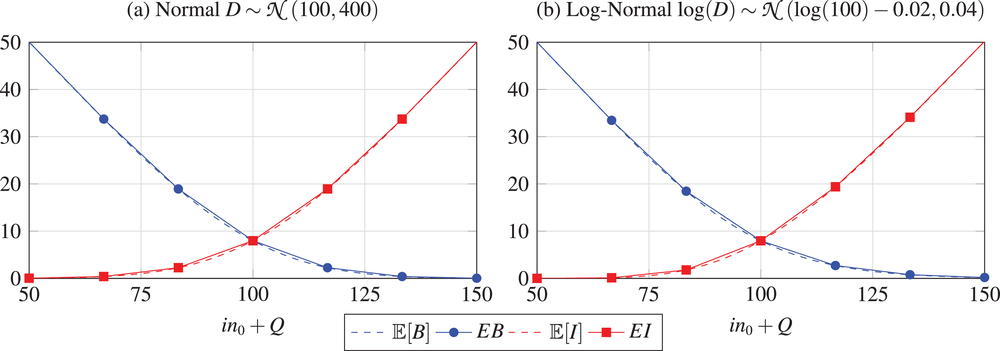
PLA of expected inventory and backlog for demand following (a) a normal distribution and (b) a log‐normal distribution
In practice, the feasible domain of the production variable
Stochastic lot sizing without recourse
The PLA formulation of the stochastic lot‐sizing problem approximates the expected inventory and backlog with variables
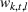
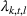
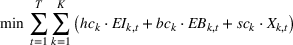
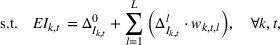
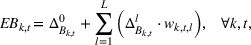
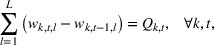
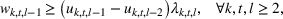
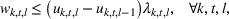
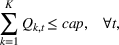
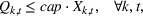
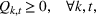
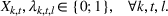
The objective function in (13a) minimizes the expected costs of inventory, backlog, and setup for all products over the horizon. Constraints (13b) and (13c) approximate the expected inventory and backlog using the slopes of the first‐order loss function previously determined. Constraint (13d) determines the production volume from the cumulative production over the linearization segments. Constraints (13e) and (13f) ensure that the linearization segments are used in increasing order through the auxiliary variable
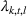
Extended lot‐sizing formulation with production recourse
The stochastic lot‐sizing formulation in (13) provides significant computational improvements compared to traditional scenario‐based stochastic formulations. However, it ignores that the planner has the opportunity to react to forecast updates in each review period. More precisely, Problem (13) defines all production decisions as first‐stage variables, which can lead to overly conservative decisions. Scenario trees can model multistage stochastic processes with recourse decisions. However, they require notoriously long computation times that grow exponentially with the size of the problem instance and scenario tree. We combine PLA and scenario‐based formulations in a single model to allow fast computations and flexible decisions. To reflect the flexibility of this strategy in the planning model while maintaining a reasonable computational effort, we introduce recourse decisions on production variables but not on setup variables. Partial recourse structures can be traced back to Escudero et al. (1993), and are also closely linked to the static–dynamic strategy of Bookbinder and Tan (1988) that implements flexible production decisions with fixed setup decisions. Our numerical studies show that this partial recourse structure improves planning flexibility with only a moderate increase in solution times. In this section, we describe the integration of PLA and scenario‐based recourse decisions, build multistage scenario trees from the MMFE models, and formulate the extended model.
Combining PLA and scenario‐based recourse
In a multistage stochastic optimization approach, our extended model connects first‐stage decisions for early periods obtained through PLA with recourse decisions for later periods obtained from demand scenarios. For early periods, PLA provides an accurate approximation of the expected inventory and backlog. In parallel, a multistage scenario tree is created to describe the demand and forecast uncertainty over the planning horizon. Applying the first‐stage production decisions from PLA, different inventory positions are reached in the scenario tree. In later periods, the multistage scenario tree allows recourse decisions to react to the different positions created by the first‐stage decisions. Because of the added flexibility, the model can take less conservative first‐stage decisions in the short‐term horizon. Formally, we define
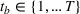
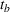
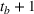
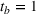
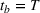
The scenario‐based extension of the PLA model can be seen as an approximation of the optimal production policy that would be obtained if the corresponding dynamic programming model were solved. The scenario part of the model acts as a look‐ahead approximation of the optimal policy (Powell, 2016). There are two main advantages for applying PLA for early periods and scenario trees with recourse for later periods. First, it is well known that the approximation quality of scenario‐based formulations increases with the number of scenarios. Multistage scenario trees grow exponentially over the planning horizon because of their branching structure. As such, only few scenarios describe the uncertainty in the short‐term horizon and the approximation error is high specifically for the immediate periods that are most important for planners. By using the PLA formulation over the short‐term horizon, we ensure low approximation error in the periods with few scenarios while still benefiting from the flexibility of multistage models over the long‐term horizon. Second, the introduction of recourse production decisions leads to a lack of a reference plan since production decisions are conditioned on the discrete scenarios. By using only first‐stage decisions over the short‐term horizon, our method ensures the availability of a reference plan, which is often indispensable in industry. The trade‐off between flexibility and availability of a reference plan is adjusted through choosing parameter
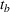
Let
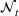
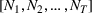
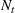
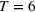
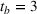
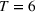
Demand observations, production decisions, and inventory trajectories over
Generating scenario trees from forecast evolution
The demand scenario tree is generated from the MMFE from period 1 to T by updating the initial forecast
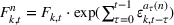
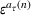
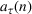
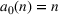
Many techniques have been developed to generate scenario trees from probability distributions. In this paper, we use Latin Hypercube because of the high variance reduction observed empirically (Linderoth et al., 2006) and the simplicity of its implementation. To sample the high‐dimensional, correlated forecast update vectors in each node, we apply the Latin hypercube with multivariate uniformity (LHMU) method developed by Deutsch and Deutsch (2012) designed to reduce sampling variability for high‐dimensional multivariate random variables. Other techniques such as optimal quantization or moment matching may also be applied although they often increase computation times (Heitsch & Römisch, 2009; Löhndorf, 2016).
Extended lot‐sizing formulation
The extended stochastic lot‐sizing formulation with PLA and scenario‐based recourse is given by:
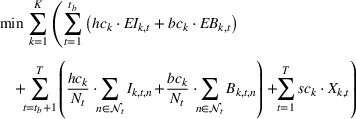
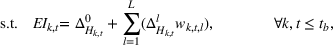
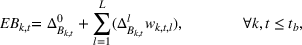
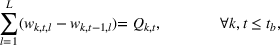
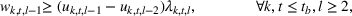
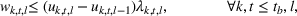
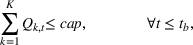

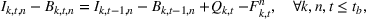
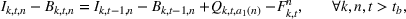
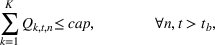


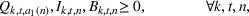
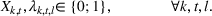
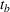
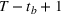
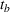
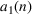
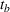
Summary
This section has introduced a general stochastic lot‐sizing approach apt for use in rolling‐horizon planning. The forecast evolution models described in Section 3 are integrated in the lot‐sizing problem through the cumulative demand and forecast evolution distributions. We have shown that both additive and multiplicative MMFE models can be readily included in lot‐sizing problems through PLA. The model was extended to allow for production recourse for later periods through a discrete scenario tree. We have shown how the scenario tree can be constructed by sampling the multivariate distribution describing the forecast evolution process.
NUMERICAL STUDY
The numerical study investigates the use of forecast evolution models in stochastic lot sizing from model estimation to application. Our assessment is based on extensive rolling‐horizon simulations. We answer the following questions: How can MMFE model parameters be estimated from real data? What is the value of forecast evolution models in practice? What are the strengths and weaknesses of the additive and multiplicative MMFE? What is the value of recourse provided by our multistage formulation? What factors influence the value of recourse?
The numerical study is composed of three main parts. First, we solve the real‐world case study of a global company in the process industry. A large data set of forecast and demand history is used to estimate the MMFE models and assess their performance. Simulations are run in an out‐of‐sample setting in which the forecast evolution process is unknown and can only be estimated from historical data. Second, we use synthetic data to analyze in detail the effect of not knowing the distribution underlying the forecast evolution. We specify the forecast evolution distributions for the additive and multiplicative models and simulate them in a rolling‐horizon fashion. Since the forecast evolution process is fully known in these experiments, we are able to evaluate the value of using the additive model when the actual forecast evolution follows a multiplicative model and conversely. Further, we quantify the value of recourse for the MMFE model with a known forecast evolution process. Sensitivity analyses are set up to identify parameters that drive the performance of forecast evolution models including demand fluctuation, capacity, and the variance of MMFE models. In a third part, we summarize our findings and provide general recommendations on the use of MMFE models.
The numerical study is implemented in Julia (Bezanson et al., 2017). The optimization problems are modeled in JuMP (Dunning et al., 2017) and solved with Gurobi 9.0. The relative objective gap of the solver is set to 1% for all models. The calculations are run on an Intel(R) Core(TM) i7‐4810MQ processor at 2.80 GHz using 16GB of RAM. The code used to produce the results and figures based on synthetic data is made publicly available on the online repository (
Real‐world case study
We apply our approach to the real‐world case study of a large company manufacturing chemical products used in agriculture. Demand follows the growth cycle of crops and exhibits strong seasonality and high uncertainty. In each planning period, demand forecasts are obtained through a sales and operations planning (S&OP) process that combines expert evaluations and automated calculations. The demand forecasts are determined for all products of a large product portfolio. We focus on the tactical planning level with a long production horizon. At this level, planning decisions are made on an aggregated product‐family level. The families have been designed such that cleaning operations are required each time a new family is set up. Thus, our analysis covers
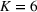
The historical demand and its clear yearly seasonality are shown in Figure 5. The planning horizon is set to
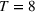
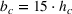
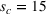
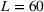
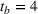
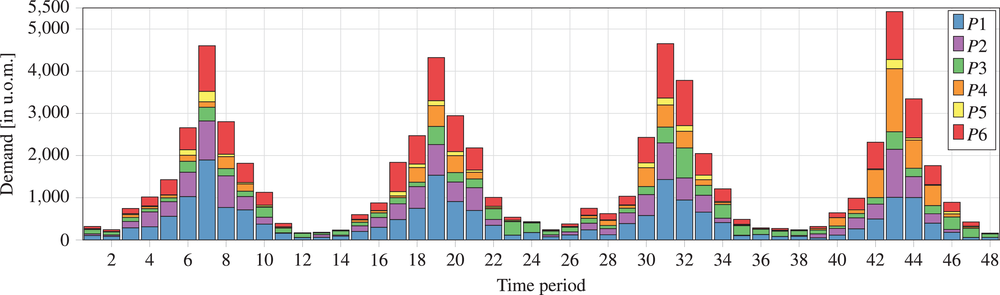
Four‐year demand history for the six families of chemical products investigated in the industry case
Estimating MMFE models from historical data
Simulations are run in an out‐of‐sample fashion to provide unbiased estimates of model performance and to assess the ability of MMFE models to generalize from past observations. In each review period, only past observations of the forecast evolution process are used to estimate the MMFE parameters. The simulation starts in period 25 so that half the data set is available to estimate the MMFE parameters in the first simulation period, and half the data set is used for the rolling‐horizon evaluation. In each review period, model parameters are re‐estimated from the history of forecast updates in an online fashion.
While the empirical mean and covariance matrix of the additive MMFE can be estimated easily, the occurrence of zero values for the forecast and demand complicates the estimation for the multiplicative model. Because the multiplicative model assumes that demand and forecasts are always positive, all forecast and demand vectors in which at least one value is zero are removed from the data set. In total, this amounts to around 50% of the data set. We then determine the parameters of the log‐normal distribution as the empirical mean and covariance of the log of the forecast updates. Thus, we find the maximum likelihood estimators of the forecast update distribution parameters for both additive and multiplicative MMFE. To conform to the assumption of an unbiased forecast underlying the MMFE models, we additionally correct the sample bias. The estimated covariance matrices exhibit complex correlation structures. Interestingly, the additive MMFE exhibits strong positive correlation for the first three products over the horizon, while the multiplicative MMFE has high positive time correlations for the two last products. The difference between the correlation parameters of the two MMFE models can be explained by the censoring of forecast updates with a value of zero in the multiplicative model. Such updates occur more frequently in the low season.
After estimating the distribution parameters, a practitioner might be interested in evaluating the goodness‐of‐fit of the forecast update samples to the distributional assumptions of the additive and multiplicative models. Intuitively, one would think that the goodness‐of‐fit provides a first measure of the expected performance of the MMFE models. A Shapiro–Wilk test is performed over the whole data set on each marginal distribution of the additive and multiplicative models. The statistical tests reject the hypothesis that the forecast updates are normally distributed with strong confidence for all products and all time periods for the additive model. The results are more nuanced for the multiplicative model as the distribution hypothesis cannot always be rejected with strong confidence. This first analysis suggests that the multiplicative model, having a better fit to the data, is likely to provide good results whereas the additive model should perform poorly. The detailed results of the goodness‐of‐fit tests are provided in Supporting Information EC.2.
Out‐of‐sample simulation results
In our numerical simulations, we notice that the presence of outliers can significantly impact model performance. In this context, outliers are understood as large forecast updates (positive or negative), which disrupt the estimation of the MMFE parameters. To remove outliers, forecast updates belonging to the upper and lower α quantiles are ignored when estimating MMFE parameters in each planning period. This method is known as trimming and has been used in diverse settings such as robust regression (Bertsimas et al., 2017). Outlier data are removed independently for each product and time period in the planning horizon so that the marginal distributions of trimmed MMFE models are assumed independent. We choose the value
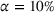
Currently, our company partner implements a deterministic planning in a rolling‐horizon fashion. We introduce a deterministic model that uses the available point‐estimate forecasts directly and ignores demand uncertainty to benchmark this practice. Due to the seasonality of demand, only few observations of the demand process are available. As such, we do not implement a stochastic benchmark based only on the demand data. The simulation results over the 24 periods are presented in Table 1. The additive MMFE model with PLA reduces costs by 11% compared to the deterministic model, thanks to relevant safety stock that increase inventory costs but provide a significant reduction in backlog and setup costs. The extended additive model with production recourse further reduces costs by 3% through less conservative inventory decisions. The multiplicative model performs poorly over the simulation as it builds large inventory reserves. These results are particularly noteworthy for two reasons. First, they contradict the goodness‐of‐fit analysis that suggested that the additive MMFE would not be an appropriate model. Second, they contradict the consensus that multiplicative MMFE is preferable when demand fluctuates over time.
Results of out‐of‐sample case study: Realized costs (in c.u)
To explain the poor performance of the multiplicative model, we conduct a sensitivity analysis of the trimming factor α. The trimming factor is varied between 0% and 25%. Because zero forecast values are removed when estimating the parameters of the multiplicative model, only few samples are available as the trimming factor increases. It is not possible to investigate trimming factors greater than 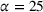
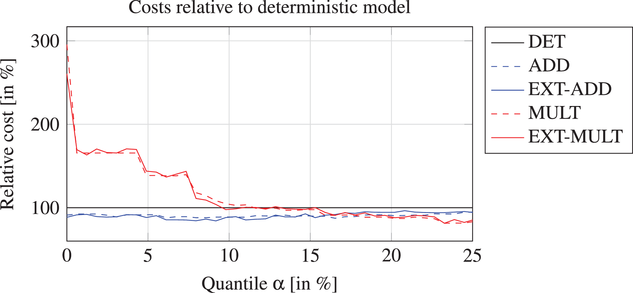
Sensitivity analysis of model performance to outlier trimming
Several factors explain the worse performance of the multiplicative model. First, the censoring of forecast update with a value of zero leads to an overestimation of demand variance in the multiplicative model. Second, the multiplicative model has a higher sensitivity to estimation error as discussed in the interpretation of Proposition 1. Since uncertainty is relative to the forecast itself, an estimation error on variance parameters can have a large effect on the peak of the seasonal demand. This can be further amplified by the presence of outliers in the data, as is shown in the trimming analysis. Another explanation is that the multiplicative model fails to generalize to settings in which the true forecast evolution process does not follow a multiplicative MMFE. Goodness‐of‐fit tests measure how well the historical data follow the distributional assumption of the MMFE models and suggest that the multiplicative MMFE better fits past data. They assess the normality of the log‐updates but do not provide any guarantee on the performance of the MMFE‐based model in rolling‐horizon planning.
Minimizing estimation errors and minimizing planning costs are two different tasks (Elmachtoub et al., 2020; Elmachtoub & Grigas, 2022). In fact, prediction models with low estimation error may yield higher costs than other seemingly less precise models (Ferber et al., 2020). Hence, an explanation of the poor performance of the multiplicative model may be that the estimation error minimized when fitting the model is less closely linked to the planning costs than the estimation error used when fitting the additive model. Adapting the model fitting procedure to take into account planning costs is an interesting but challenging research direction. Differing from the simpler class of problems studied by Elmachtoub and Grigas (2022), our problem is dynamic and implemented in a rolling‐horizon fashion. Further, the uncertain parameters have nonlinear effects on the objective function.
To better understand the shortcomings of the multiplicative model and to identify situations in which it is better to use an additive model, we perform an extensive numerical study with synthetic data in the following section. In particular, we evaluate the cost of model misspeficiation for demand patterns with different dynamics.
Synthetic data
In this section, the forecast evolution process described by the MMFE is simulated on artificial instances. By performing sensitivity analyses of key parameters, we evaluate the performance of MMFE‐based models in a variety of problem settings. In particular, we vary the capacity, uncertainty, and demand patterns. We also aim to provide insights on the use of MMFE‐based models in real‐life situations in which underlying probability distributions are unknown. To this end we employ the additive model when the true forecast evolution process is multiplicative and conversely. Then, we assess our multistage extension and identify drivers that influence the value of recourse enabled by it.
Simulation instances
We consider 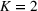
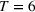
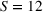
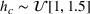
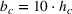
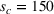
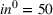
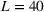
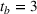
The capacity in each period is chosen as 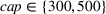
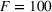
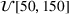
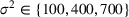
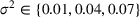
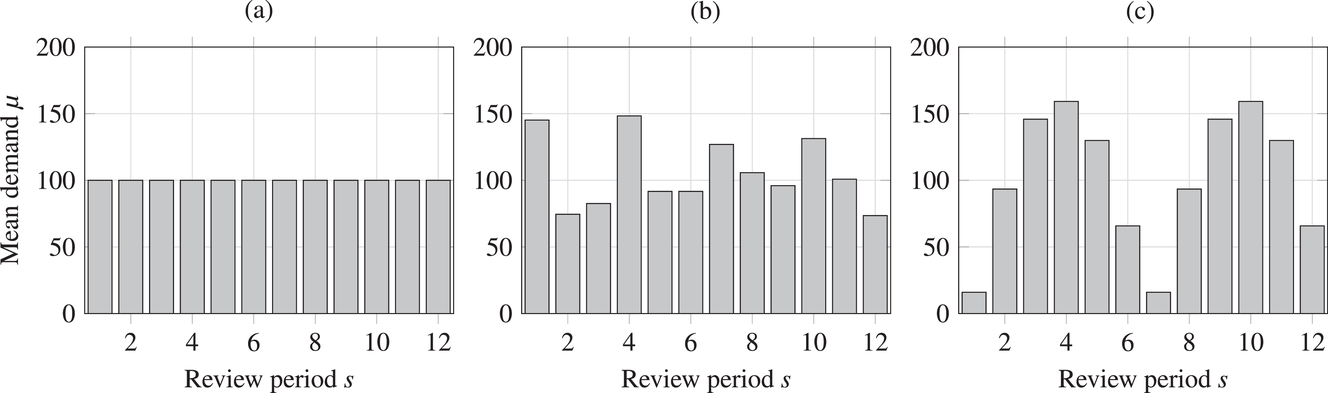
Mean demand for (a) stationary, (b) random, and (c) seasonal patterns over simulation of eight periods
MMFE models and benchmarks
In practice, the true forecast evolution is unknown. To estimate the value of MMFE‐based lot sizing when using a mismatched forecast evolution model, we run two distinct sets of simulations in which the forecast evolution process follows the assumptions of the additive and multiplicative MMFE. The mismatched model is estimated from a simulation of the true forecast evolution process over 1 million periods. The sampled forecast updates are measured according to the mismatched MMFE model and used to estimate its parameters.
As in the previous real‐world case study, the estimation procedure of the multiplicative model is not straightforward. When the forecast evolution process follows an additive MMFE, demand is normally distributed and demand observations may be zero (or negative, which is corrected to zero in all simulations of additive MMFE). It is also possible that a forecast with value of zero is updated to a positive forecast. These two cases, while frequently occurring in practical settings, are not compatible with the multiplicative MMFE. Thus, when estimating the parameters of the multiplicative MMFE, we remove all sampled forecasts that contain at least one zero value. For the setting with low uncertainty, this amounts to removing 0%, 1%, and 41% of samples for the stationary, random, and seasonal patterns, respectively; 13%, 26%, and 64% for the medium uncertainty setting; and 37%, 50%, and 74% for the high‐uncertainty setting. Clearly, more sample updates are removed from the data set as the demand pattern is more dynamic and as uncertainty increases. The high number of unusable samples is an important shortcoming of multiplicative MMFE since collecting data is an expensive process.
Two benchmarks are introduced: (1) a deterministic model that uses the forecast as a point estimate and ignores uncertainty but observes the updated forecasts in each planning period and (2) a demand‐driven stochastic model that ignores forecasts and their evolution and instead estimates demand distributions from historical data. For the stationary and random patterns, the demand‐driven model estimates a stationary demand distribution. For the seasonal pattern, the demand‐driven model estimates independent distributions for all periods in the season. The model estimates the parameters of normal and log‐normal distributions from simulations of the forecast evolution process over 1 million periods using additive and multiplicative MMFE, respectively. These two models benchmark the planning practices of industry and the traditional stochastic lot‐sizing literature, respectively. The performance of stochastic models is traditionally evaluated by measuring the value of the stochastic solution (VSS), which is based on a static evaluation of the deterministic and stochastic models, and the expected value of perfect information (EVPI), which measures the value of obtaining perfect forecasts (Birge & Louveaux, 2011). By comparing the performance of the stochastic models to the deterministic benchmark implemented in a rolling‐horizon fashion, we extend the VSS to a more realistic setting in which the deterministic benchmark also benefits from updated forecasts. Further, the value of improving the forecasting process is measured by comparing the costs of MMFE‐based models under the different uncertainty settings, providing a richer performance evaluation than the EVPI.
Results
Each rolling‐horizon simulation of the 36 instances is repeated 1000 times. Model performance is measured as the sum of realized inventory, backlog, and setup costs. The results under additive and multiplicative MMFE are presented in Table 2 and Table 3, respectively, as the average of the costs over the 1000 repetitions. The statistical significance of all relative cost differences from the deterministic model is assessed using Student's t‐test. Statistical significance is indicated with the symbol (*) for all relative values for which the associated p‐value is strictly smaller than 5%.
Simulation results when forecast evolution follows an additive MMFE process
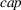
Simulation results when forecast evolution follows a multiplicative MMFE process
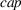
Our simulation results quantify the value of forecast evolution models compared to both traditional deterministic approaches typical in industry and stochastic models that focus solely on historical demand data and ignore forecast. The costs of the deterministic benchmark are especially high when capacity is tight, uncertainty is high, and demand fluctuates over time. It is also in these settings that the MMFE models with known forecast evolution provide large cost reductions. The stochastic, demand‐driven model increases costs compared to the naive deterministic model for almost all instances. This can be explained by two reasons. First, the model is overly conservative since it accounts for the whole demand uncertainty for all periods in the planning horizon. Second, it is inaccurate because it only aims for the average observed demand and ignores the forecasts. This is especially true for the random demand pattern since, even though demand is stationary, the initial forecast values provide a lot of information on the final demand observations. On the other hand, the additive and multiplicative MMFE models reduce costs by 14% on average compared to the deterministic model when the forecast evolution process is known.
The value of improving the forecasting process to reduce forecast uncertainty can be measured by comparing the costs of the correct MMFE model in different uncertainty settings. For instance, under additive MMFE in the seasonal setting with low capacity, the planner would be willing to pay up to 580 c.u. to reduce the forecast uncertainty from the high uncertainty to medium uncertainty, and up to 500 c.u. to reduce it further to the low uncertainty setting. Interestingly, the value of information appears higher in the simulation settings with low capacity. This result contrasts with previous studies that found that advance information was not useful when utilization is high (Albey et al., 2015; Ziarnetzky et al., 2018, 2020). This difference can be mainly explained by the fact that previous literature uses several approximations such as capacity allocation when determining the safety stocks of the different products. This severely restricts planning flexibility when utilization is high. Flexibility is even more important in our experiments since we consider products with different cost parameters whereas Ziarnetzky et al. (2018) and Albey et al. (2015) consider symmetric products. A detailed analysis of the effect of the simulation parameters and their interactions is given in Supporting Information EC.3.
The cost of model misspecification is high for the multiplicative model. Indeed, Table 2 shows that using a multiplicative forecast evolution model when the true process is additive can significantly increase costs even compared to traditional deterministic planning. On average, the costs of the multiplicative model are 12% larger and more than 50% when demand is seasonal and uncertainty is high as is the case in our industry application. In contrast, the cost of model mis‐specification is low for the additive model. Table 3 shows that when the true process is multiplicative, the additive model yields costs almost as low as the multiplicative model, suggesting that additive MMFE‐based models are robust to errors in modeling the forecast evolution process. These results explain the superiority of the performance additive model for our industry case, in which the true forecast evolution process is unknown.
Value of recourse
The value of recourse is defined as the difference between costs of the stochastic model without recourse and the extended stochastic model combining PLA and scenario‐based recourse, as presented in Table 2 and Table 3. The value of recourse varies over the simulation settings similarly for both MMFE models. It is higher for more complex planning settings: When demand is dynamic, uncertainty is high, and capacity is limited. Overall, recourse is more beneficial under multiplicative MMFE. On average, the value of recourse is around 1.5% and 2.5% across all simulation settings and can reach 2.3% and 6.2% for the additive and multiplicative models, respectively. The detailed statistical analysis of the value of recourse is given in Supporting Information EC.4. It shows that these results are statistically significant at a p‐value smaller than 5%. The distribution of the value of recourse is skewed so that in the majority of cases, observed costs are smaller than the average value. To further investigate the value of recourse in stochastic models and to identify settings in which it is most beneficial, we perform several sensitivity analyses.
Impact of product and time correlation
In Section 3, we have shown that positive (resp. negative) forecast time correlation was equivalent to a higher (resp. lower) cumulative demand variance for both MMFE models. For the extended model with recourse, correlation has an even larger impact since the recourse model can react to correlated forecast updates. We analyze the impact of the correlation structure on the value of recourse on the simulation setting with seasonal demand and 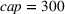
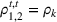
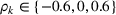
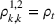
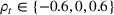
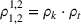
The costs of the extended model with recourse relative to the costs of the model without recourse are presented in Table 4. The statistical significance of the relative cost is assessed with Student's t‐test and is shown with the symbol (*) if the p‐value is below 0.05. The correlation structure has a strong impact on the value of recourse. Negative time correlation yields high value of recourse for both MMFE models, whereas positive time correlation leads to lower values than in the uncorrelated case. Recourse decisions can take advantage of negative time correlation by anticipating that forecast updates will compensate over time. Specifically, a forecast increase for the first period in the horizon might be compensated by a forecast decrease in the second period. Anticipating this effect leads to less conservative decisions. Hence, the largest improvements are observed when time correlation is negative and product correlation is positive. Here, a compensation over time occurs for both products and costs can be reduced by more than 10% compared to the stochastic model without recourse. This analysis shows the importance of including correlation in stochastic planning especially when using recourse models. Further, it confirms the trend that the multiplicative model benefits most from recourse.
Value of recourse for different correlation structures
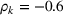
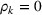
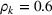
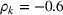
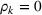
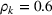
We also perform extensive sensitivity analyses of the available capacity and scenario structures. The sensitivity analysis of capacity shows that the value of recourse increases monotonously with the available capacity under additive MMFE. The value of recourse is larger under multiplicative MMFE and peaks when capacity is neither too limited nor too large. The sensitivity analysis of the scenario structure shows that scenario trees with an intermediate size, such as the one used throughout this section, are sufficient to benefit from recourse without substantial increase in computation times. Details on both sensitivity analyses are provided in Supporting Information EC.5.
The value of flexibility is also studied in a broader context in Supporting Information EC.6 by comparing the value of recourse to the value of a free‐return policy, which allows to liquidate excess inventory at no cost. The numerical results confirm that flexibility is more valuable under multiplicative MMFE than additive MMFE. Recourse and returns decisions are two flexibility levers that provide large cost reductions under multiplicative MMFE. Recourse decisions are more beneficial when capacity is tight whereas return decisions prove especially valuable when capacity is large.
Summary and recommendations
The numerical study shows that integrating forecast evolution models in stochastic lot sizing can significantly improve planning quality compared to traditional deterministic approaches and stochastic methods based solely on demand data. The additive MMFE model is robust and performs well across all simulation instances: (1) when the forecast evolution process is known, (2) when it is unknown and estimated from mismatched updates, and (3) when it is learned from real‐world historic data. Interestingly, the cost savings provided by stochastic models based on additive MMFE relative to the deterministic benchmark are similar on both the real‐world and the synthetic data. On the other hand, the multiplicative model suffers from several limitations, which have been identified through our extensive numerical studies. First, the multiplicative model is particularly sensitive to model misspecification: When the forecast evolution model is unknown, the multiplicative model leads to a cost increase and often performs worse than traditional deterministic rolling‐horizon planning. The performance deteriorates most when uncertainty is high, capacity is limited, and the demand is dynamic, for example, when there is a strong demand seasonality. This suggests that the relative forecast error measure, on which the multiplicative MMFE model is based, is more sensitive to a distributional error than the absolute measure underlying the additive model. On top of this limitation, the multiplicative model is more strongly impacted by estimation errors due to the variance being relative to the absolute value of the forecast as shown in Proposition 1. Thus, demand peaks and outliers can strongly impact the multiplicative model's performance, which is clearly shown in the real‐world case study. Further, due to its inability to include demand and forecasts values of zero, the multiplicative model overestimates forecast uncertainty when using historical data that include such periods.
Thus, in contrast to the consensus in the MMFE literature stating that the multiplicative model better characterizes forecast revision processes, we advise to prioritize the implementation of the additive MMFE because of its robustness in a wide array of problem settings. In any case, we emphasize that the choice of the relevant MMFE model should not be based on an a priori goodness‐of‐fit analysis but instead on evaluating model performance through out‐of‐sample rolling‐horizon simulations using historical data.
The extended model with production recourse can provide consistent cost reductions with both real‐world and synthetic data. Across all simulation settings, the value of recourse is higher for the multiplicative model. Still, recourse can consistently provide lower costs for the additive model. We have identified that the value of recourse is especially high when demand is dynamic, uncertainty is high and when forecast updates exhibit negative time correlation.
The extended model with recourse requires managerial decisions as it impacts planning in several ways including slightly longer computation times and a reduced reference plan due to the presence of recourse decisions. In our analysis, we have provided initial guidelines to tune the model and find a good compromise between its advantages and limitations.
CONCLUSION
This paper proposed a methodology for a dynamic, stochastic, capacitated lot‐sizing approach apt for use in rolling‐horizon planning. For this purpose, we integrated forecast evolution models in tractable lot‐sizing formulations. We have shown that cumulative demand distributions describing the forecast evolution can be integrated efficiently in stochastic lot‐sizing models using existing linearization techniques. Rolling‐horizon planning also allows for a revision of production plans. We therefore extended our approach with a scenario‐tree representation of uncertainty to allow for production recourse. We quantified the value of forecast evolution models in a large‐scale numerical study using both real‐world and synthetic data. Forecast evolution models have been shown to provide significant cost reductions compared to both traditional deterministic methods used in industry and stochastic methods that use only demand history, which are common in the stochastic lot‐sizing literature. On average, production recourse consistently reduces costs for both additive and multiplicative MMFE. Key parameters that impact the value of recourse such as product and time correlations have been identified through sensitivity analyses.
This work proposes the first numerical comparison of additive and multiplicative MMFE in rolling‐horizon planning when the true forecast evolution process is unknown. Previous literature stressed that the multiplicative MMFE better fits industry data than the additive MMFE, which is also observed in our analysis. However, we find that multiplicative MMFE‐based planning performs poorly when the true forecast evolution process is unknown. Thus, we highlight that the MMFE model that best fits the historical data does not necessarily provide the best planning performance. The additive model, in contrast, performs robustly across all simulation instances. Future research could investigate how to make multiplicative forecast evolution models more robust to an unknown forecast updating process. The two main steps of defining a forecast evolution model may be challenged: (1) measuring forecast updates from data and (2) fitting a probability distribution to the updates. For instance, more robust multiplicative MMFE models could use novel approaches to measure the relative forecast updates or investigate alternative estimation techniques to find model parameters from data. The normality assumption, central to both additive and multiplicative forecast evolution models, could also be challenged by investigating other distributions or applying distribution‐free methods. A last research direction pertains to the link between the revision of forecasts and the revision of planning decisions. It is known that frequent planning changes can cause nervousness in supply chains. Integrating forecast evolution in planning models may allow new methods to anticipate planning instability in rolling‐horizon planning and derive replanning strategies yielding more stable plans.
Footnotes
ACKNOWLEDGMENTS
The authors thank the department editor as well as the anonymous senior editor and reviewers for their comments that substantially improved the manuscript. The work is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)—277991500/GRK2201.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.