
Abstract
We study the model‐based undiscounted reinforcement learning for partially observable Markov decision processes (POMDPs). The oracle we consider is the optimal policy of the POMDP with a known environment in terms of the average reward over an infinite horizon. We propose a learning algorithm for this problem, building on spectral method‐of‐moments estimations for hidden Markov models, the belief error control in POMDPs and upper confidence bound methods for online learning. We establish a regret bound of
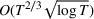
Get full access to this article
View all access options for this article.