
Abstract
Bringing tactile sensation to robotic hands will allow for more effective grasping, along with a wide range of benefits of human-like touch. Here, we present a three-dimensional-printed, three-fingered tactile robot hand comprising an OpenHand ModelO customized to house a TacTip soft biomimetic tactile sensor in the distal phalanx of each finger. We expect that combining the grasping capabilities of this underactuated hand with sophisticated tactile sensing will result in an effective platform for robot hand research—the Tactile Model O (T-MO). The design uses three JeVois machine vision systems, with each comprising a miniature camera in the tactile fingertip with a processing module in the base of the hand. To evaluate the capabilities of the T-MO, we benchmark its grasping performance by using the Gripper Assessment Benchmark on the Yale-CMU-Berkeley object set. Tactile sensing capabilities are evaluated by performing tactile object classification on 26 objects and predicting whether a grasp will successfully lift each object. Results are consistent with the state of the art, taking advantage of advances in deep learning applied to tactile image outputs. Overall, this work demonstrates that the T-MO is an effective platform for robot hand research and we expect it to open up a range of applications in autonomous object handling.
Introduction
Tactile afferents in our hands provide information about the state of a grasp and, crucially, whether the grasp is failing. 1 Therefore, bringing tactile sensation to robotic hands will allow for more effective grasping, along with a wide range of benefits of human-like touch. This will enable the performance of tasks that we take for granted and that robots are currently incapable of achieving.
Tactile-enabled robots will be able to operate autonomously and safely in cluttered and unknown environments in such varied situations as health and social care or industrial manufacture. 2 Tactile sensing has been demonstrated to be useful in multiple areas of robotics, including single-point sensors such as whiskers, large area sensors, and high-resolution fingertips. 3 However, significant scientific and social barriers remain that prevent tactile robot hands from becoming commonplace. These include the development of robust and safe soft sensors, and the public acceptance of robots for use in domestic settings. 4
Although robotic hands with integrated soft tactile sensors are becoming more common,2,5 the vast majority of research on robotic hands still focuses on vision-guided grasp planning. In part, this is because there is a limited selection of commercial tactile-enabled hands, which are expensive and behind the development curve of the most advanced tactile sensors. Thankfully, the advent of fast, precise, multimaterial three-dimensional (3D)-printing technologies now means that it is relatively straightforward and inexpensive to adapt tactile sensors and robotic hands into new integrated platforms with both soft and hard parts.
Scaling to multiple sensors on a robotic hand presents many challenges, such as how to control the hand with integrated sensor feedback. With those challenges in mind, the presented platform offers a balance of dexterous capability against relative simplicity in its underactuation and fabrication.
The aim of this study is to modify a three-fingered robotic hand, the OpenHand Model O, 6 to house the TacTip, a soft optical tactile sensor with 3D-printed biomimetic morphology, 7 such that the combined system is capable of predicting whether a grasp will be stable and identify objects by using tactile sensing alone. Prior work on integrating this tactile sensor with 3D-printed hands has involved two 2-DoF (degree of freedom), two-fingered robotic hands: the OpenHand model-M2 gripper with a tactile thumb and the GR2 gripper with two tactile fingertips.8,9 The current work represents a major advance in the functionality of 3D-printed tactile dexterous hands to integrate three tactile fingertips within a four-DoF hand with state-of-the-art grasping capabilities.
Here, we demonstrate tactile capabilities by performing object classification and predicting the stability of grasps by using Convolutional Neural Networks (CNNs) applied to tactile data alone. We expect that the grasping capabilities of the Model O combined with the success of the TacTip as a tactile sensor will result in an effective platform—the Tactile Model O (T-MO)—for a wide range of future tactile robot hand applications and research. The main contributions of this study are to (Supplementary Video S1):
Customize the design of a 3D-printed tactile sensor (the TacTip) for integration with a 3D-printed robot hand designed for grasp research (the Model O). Assess the performance of this tactile hand on real-time one-shot grasp success prediction and object classification, using deep learning on tactile images. Assess also the sensitivity of this performance to a reduced number of tactile sensors, to demonstrate the utility of tactile sensing within a robot hand.
An area of further novelty is that the new tactile sensor design contains an on-board processing unit that enables local computation. For example, data processing for each finger can be done on the hand, in principle encompassing deep learning models for perception (via TensorFlow Lite). Overall, the T-MO's combined capability at grasping and tactile perception results in a low-cost tactile grasping system, which sets a new level of capability in the field of robot hands.
Background
The majority of work with tactile robot hands has involved solid-state tactile sensors, and it has been reviewed extensively elsewhere.2,5 Widely used platforms include the anthropomorphic iCub hand with integrated capacitive sensors, 10 the Shadow hand with BioTac sensors placed at the fingertips 11 and with fabric and capacitive tactile sensors, 12 the four-fingered Allegro hand with PPS capacitive sensors 13 and with BioTac sensors, 14 and the TWENDY-ONE hand 15 with embedded force-torque sensors and a tactile skin 16 ; this last hand was the first to use deep learning for object recognition. In addition, the i-HY hand used in this study has been integrated with MEMS barometric TakkTile sensors, to give a basic array of four pressure-sensitive taxels on each fingertip. 6
Several studies have integrated optical tactile sensors onto two-fingered robotic grippers. The first was Ward-Cherrier et al., 8 who used the M2 gripper, a two-fingered two-DoF hand from the OpenHand project similar to the hand considered here, 17 and rolled cylinders across the surface using only tactile feedback. Next, two GelSight optical tactile sensors were integrated onto a two-finger parallel gripper and used for slip detection. 18
Subsequently, Ward-Cherrier et al. 9 integrated the TacTip onto a GR2 two-fingered gripper, 19 also rolling cylinders along a trajectory in the hand's workspace over the TacTip's surface. Then followed a slimmer version of the GelSight, the GelSlim, which reflects light down the finger to a camera module at its base and has a flat profile appropriate for parallel jaw grippers. 20 There recently followed a more compact, two-fingered robot gripper with multiple Gelsight optical tactile sensors covering the inner surface of the hand. 21
In relation to the current study with TacTip optical tactile sensors integrated into a three-fingered hand, both the M2 and GR2 grippers are effective at establishing pinch grasps but their design is focused on the in-hand manipulation of objects through simple control, which makes them unsuitable for many of the tasks performed here.
Testing of tactile-enabled hands has largely taken the form of collecting a dataset of grasps on various objects and using various machine-learning methods to try to distinguish between them. Spiers et al. 22 use 11 objects from the Yale-CMU-Berkeley (YCB) object set by using data from an array of barometric pressure sensors attached to a two-fingered hand and classify them by using random forests. They obtained a validation accuracy of 94% when the objects' orientations were unconstrained.
Flintoff et al. 23 also use random forests on a two-fingered hand containing barometric sensors and the Google Soli radar sensor to classify 26 objects, obtaining 99% validation accuracy. In this work, the hand was placed on a surface with objects placed in the sample plane, with minor variation in object positions and orientations. Schmitz et al. 16 identify a set of 20 objects with an accuracy of 88% by using a deep neural network on the four-fingered TWENDY-ONE hand. It was significantly shown that dropout can be used with tactile data to notably improve performance.
Regoli et al. 24 achieve an accuracy of 97.6% by using a kernel regularized least-squares method on data collected over 21 objects from the YCB set. Here, objects are placed into an iCub hand and tactile data from two fingers are gathered during exploratory grasping and wrapping actions. A grasp stabilization phase resulted in an increase of up to 29% accuracy on object recognition. Funabashi et al. 25 use uSkin tactile sensors on an Allegro hand alongside proprioceptive joint angles as the input to a CNN. Objects are placed into the hand, and 95% accuracy is obtained when classifying 20 objects: 10 from the YCB set and 10 cylindrical objects.
Liu et al. 26 investigate whether the intrinsic relationship between tactile data collected from different fingers can be exploited to improve object recognition performance. Two object recognition tasks are used: classifying five bottles by using a BarrettHand with capacitive tactile sensors; and classifying up to 10 household objects by using a Schunk parallel gripper and piezoresistive tactile sensors. The best accuracy over these tasks was found by using a joint kernel sparse coding method that exploits the similarity between data gathered on individual fingers via a shared sparsity support pattern.
Another common task for evaluating tactile robot hands is grasp stability prediction. Data-driven approaches are often used in the form of collecting a dataset of successful and unsuccessful grasps, then using this information to train machine-learning algorithms. Wan et al. 27 predicted grasp stability on an iHY robotic hand with MEMS barometers but used only one object at a fixed position, making grasps highly repeatable, and obtained an accuracy of 90% by using an support vector machine (SVM). Similarly, Dang and Allen 28 use a BarrettHand with capacitive sensors to train an SVM. Simulated data from 704 objects resulted in 81% accuracy. A physical experiment was also performed on six household objects, where grasps were sampled until the simulation-trained SVM predicted a successful grasp, at which point an attempt to raise the object was performed. Using this method, a grasp success rate of 84.6% was achieved, although the baseline success rate in the training data was not given.
Krug et al. 29 applied an analytic approach by using tactile data to determine whether a set of wrenches (concatenated force/moment vectors) necessary to grasp an object can be applied by the hand. This approach required no training data and was computationally efficient. When applied to a test dataset of 584 grasps distributed over four household objects, the classification accuracy was 74%.
Most prior work on object recognition and grasp success prediction has used objects passed directly to either a fixed robotic grasper, or a fixed grasper constrained to the same plane as the object. Often, there is variation added to the object position and orientation to make the task more challenging, although this is typically at the discretion of the user. There are a limited number of studies that perform object classification in a more realistic pick-and-place environment, such as the one considered here. We are of the view that such environments are more representative of practical applications.
Methods
Tactile sensor
This study involves the integration of a soft optical biomimetic tactile sensor in the TacTip family7,30 onto an OpenHand Model O, an underactuated three-fingered hand. 6 The TacTip surface consists of a rubber-like 3D-printed surface made from Tango Black+ and supported at its base by a hollow cylinder made from VeroWhite plastic. The sensor tip is filled with silicone (RTV27905) and sealed with a clear acrylic lens. This design allows the sensor to deform around objects and regain its shape postcontact.
The principal design aspect of the TacTip family is an array of protruding pins arranged inside the sensor surface, which mimic the dermal papillae and Merkel cell complexes present in the glabrous (nonhairy) skin of primate fingertips. The pins are printed on the inside of the hemisphere by using Tango Black+ and a small tip of Vero White is printed on top of the Tango Black+ “rods” to make pin detection easier to visualize from a camera. The entire TacTip exterior is printed as a single unit, using both materials, which has allowed complicated pin structures to be tested that would be very difficult to manufacture with other fabrication methods. 31
White light-emitting diodes (LEDs) are used to give uniform illumination inside the sensor and reduce the effects of any external light that bleeds through the Tango Black+ skin or Vero White base. A camera is mounted on the base of the sensor to view the pins as the sensor deforms and either the pin positions or the raw camera images can be used as the tactile information, for example as tactile inputs into supervised learning methods for regression or classification over labeled data.
Robotic hand
Underactuated robot hands greatly simplify the control systems required to grasp objects by using their morphology to conform to objects.32,33 The hand chosen for this work was the Model O, developed by the OpenHand project at Yale. 34 The Model O is based on the i-HY hand first presented by Odhner et al., 6 which won the autonomous robotic manipulation hand track of the defense advanced research projects agency manipulation challenge. 35 The Model O is a three-fingered underactuated hand with four DoF, which, along with other OpenHand designs, has demonstrated great success in grasping by leveraging the morphology of its design.6,36 The Model O is mostly 3D-printed (using ABS plastic) and a completely open source. This makes it ideal for this study, as the manufacture and modification of the design for integration of the tactile sensor is straightforward.
The three fingers are almost identical in that they contain two joints and a single DoF, making each underactuated in the same way. A braided polyethylene wire “tendon” runs the length of the finger and is connected to a Dynamixel MX-28T motor in the base of the hand. This allows the fingers to deform around objects for grasping, without the object shape being known by the controller. Springs in both joints cause the finger to passively release when the active force from the motor is removed.
The only difference between the fingers is that one, the “thumb,” is fixed to the palm of the hand, whereas the other two fingers can rotate through 90° from facing the thumb to facing each other (Fig. 1). The rotation of these two fingers is mechanically coupled and, therefore, constitutes only a single DoF.
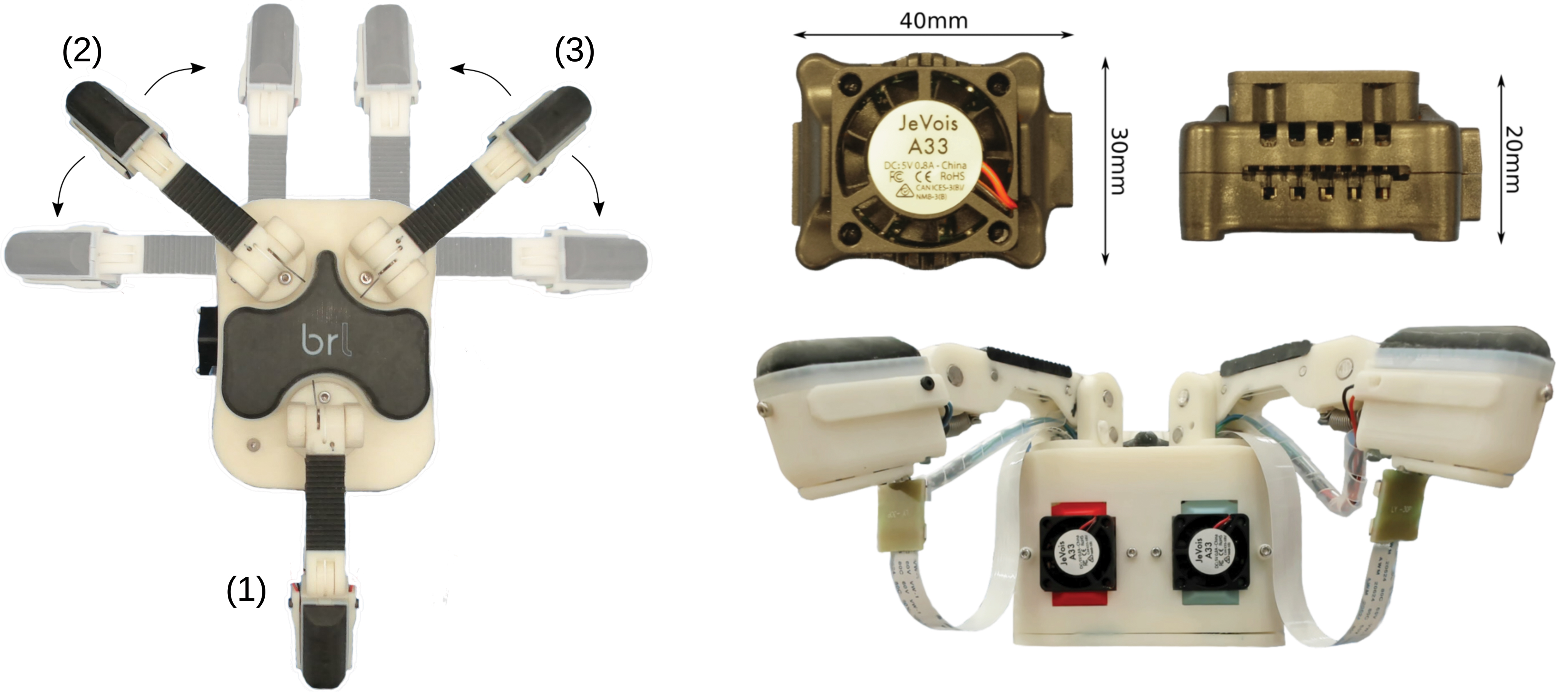
Left: The T-MO with fingers labeled (1–3). Note the range of movement of fingers (2,3), which are mechanically coupled, giving a single degree of freedom. Right: JeVois machine vision modules above a side view of the T-MO. Four Dynamixel servos and three JeVois are housed in the base unit with a marginal increase in size compared with the Model O. The lower image shows how the JeVois processors are integrated into the base of the hand. A ribbon cable runs from each JeVois unit to its camera module in the distal phalanx of each finger. A second cable supplies electricity to the LEDs. LEDs, light-emitting diodes; T-MO, Tactile Model O. Color images are available online.
Modification of finger design for sensor integration
We had several goals for the design when modifying the Model O to integrate the TacTip tactile sensor:
To maintain the strong grasping performance of the Model O by keeping the tendon-driven actuation design.
To minimize the size of the sensor such that the Model O distal phalanx was minimally enlarged and strong sensing performance was retained.
To integrate the camera processing unit into the motor housing of the Model O with a minimal increase in size.
To keep the system low cost and easily fabricated via 3D printing.
With these design goals in mind, we now discuss the changes we have introduced to the Model O hand.
Each finger of the Model O has two joints and two phalanges, with pads constructed from Vytaflex 30 to give a high-friction surface that is suitable for grasping. We have replaced the distal phalanx of each finger with a tactile sensor such that three sensors are used in total (Fig. 1). As the tendon is fixed at the base of the distal phalanx and runs down the center of the finger, modifying only the distal phalanx allows us to maintain the fundamental actuation principles of the Model O, in keeping with design goal 1. Also, this keeps the complexity of the modification low but still involves collecting data from more TacTips than earlier. To date, this is the smallest TacTip variant that has been integrated onto a robotic hand.
Previously, the TacTip had a hemispherical shape with 127 pins.9,31,37 However, for integration onto the Model O the sensor was modified to be closer to the shape of the distal finger phalanx of the Model O (Fig. 2). We chose to change the shape to rectangular rather than keeping a smaller hemispherical design. This was to minimize changes to the morphology of the distal phalanx finger pad, with which a hemispherical sensor would necessarily have a smaller sensing area if integrated within a rectangular linkage. A rectangular sensor covers as much of the potential contact area as possible.

Exploded view of the distal phalanx in the T-MO finger. Color images are available online.
This reduction in size and change of shape (40 mm diameter hemisphere to 40 × 20 mm rectangle) presents two challenges. The first challenge is that the pin layout needs modifying to be consistent with the shape of the distal phalanx. The number of pins in the sensor is reduced to 30, arranged in three rows of 10, to ensure good coverage of the interior surface while also having sufficient separation of the pin tips to be easily distinguishable. Four LEDs are mounted above the sensor lens in two strips along the major axis of the finger (previously, six were used in a ring). The pins have a diameter of 1.2 mm with centers that are 3 mm apart.
The second challenge involves integrating the camera system: The small size of the distal phalanx means that for the camera to be attached directly above the sensor, the form factor of the camera board must be small and the lens must have both a wide field-of-view and a small focal length. These requirements led to us using a 90° FoV nondistortion lens connected to a JeVois machine vision camera system. 38 The camera module is connected to the finger (Fig. 2) and a ribbon cable connects it to the JeVois board, which is housed in the “base” of the hand where the motors are housed (Fig. 1).
Fundamentally, the new sensor has similar design principles as the original hemispherical TacTip, with a camera observing changes in a soft surface as it contacts objects. Although we anticipate some changes in sensing capabilities between the original and modified designs that could be examined in future work, the key focus here is to examine the performance of this new design situated in the hand.
The JeVois can capture frames and process them by using OpenCV at a variety of frame rates and resolutions ranging from 1280 × 1024 (15 FPS) to 176 × 144 (120 FPS). TensorFlow Lite models can even be loaded directly onto the JeVois, enabling processing by pretrained deep networks within the hand itself. We use a single JeVois module for each of the three TacTips. We were able to integrate the three Jevois without changing the frontal area of the base by removing the taper between the “palm” of the Model O and the bottom of the base. The JeVois is low cost (∼£50) and combining this with the small size means that it satisfies design goals 2–4. For this study, the base of the hand has a connector unit, for mounting on a six DoF robotic arm (UR5; Universal Robots, Denmark), which is described later in the Autonomous Grasping Platform section.
The camera is held in place by screwing a cap over the top of the board. The ribbon cable emerges from the rear of this cap and feeds directly into the base of the hand, where the JeVois processors are housed. The TacTip slots into the phalanx and is held by three screws. This makes replacing the sensor skin very simple when breakages inevitably happen. Overall, the integration of the tactile sensors makes the fingertips heavier, the effect of which is compensated by using stronger springs to hold the fingers in a fully relaxed position when the hand is held with the palm facing down.
Although the new fingers are roughly the same width and length as those of the original Model O, they are deeper because the use of a camera with a 90° field-of-view means that the lens must be at least 20 mm away from the TacTip to view the entire 40 mm surface. This makes the fingertips significantly thicker than those of the model O, increasing from 12 to 35 mm. This has the effect of removing the ability to slide the fingertips under objects to initiate grasps. For this reason, we expect that the larger size of the fingers presented here will have an impact on the ability of the hand to pick up very small flat objects, but otherwise the functionality of the hand should be similar to the original Model O.
Tactile data
There are two modes of operation available for processing tactile data on the T-MO. The first is to track the movement of pins via the Python OpenCV function “SimpleBlobDetector” by using a script on the JeVois and pass a list of positions to the control PC by using a serial connection. This mode uses the pin positions as the tactile output,7,39 as in previous work integrating the TacTip into two-fingered grippers.8,9 When using this mode, the JeVois was capable of performing pin detection at the same rate as image capture (60 FPS at 320 × 240px), which provides a major benefit to the system as performing pin detection on three simultaneous video streams is a resource heavy task for a PC. Other off-the-shelf image processing boards such as the Raspberry Pi 3 or Zero were unsuitable as they were too large (Pi 3) or unable to detect pins at a high frame rate (Pi Zero).
The second technique is to capture the raw camera image and feed this into a neural network with minimal preprocessing. For this mode, the control PC can detect each JeVois as a video source and capture frames directly. Recent research has shown that this second technique gives improved results in a contour following tasks, particularly when concerned with robustness in an online setting. 40 Thus, in this article, the main approach will be to use raw images and neural networks; the hand has, however, been designed to accommodate both approaches.
Tactile image data are collected as a video (20 FPS) while the hand performs a grasping motion. Although the platform allows for autonomous data collection, it still requires a significant investment of human time and effort for large datasets. Efficient use of the collected data is, thus, a priority.
One of the methods used to achieve efficiency is to sample multiple sequences of frames from each grasping video. To estimate the appropriate frame, we calculate the absolute pixel difference for each frame in a tactile video when compared with the first frame in the same video. 40 This gives a basic measure of sensor deformity.
From this method, it is possible to find the frame that corresponds with ∼25% deformation of the sensor, which we use to estimate when contact has been made with an object. We then select a sequence of 8 frames by taking every 10th frame after the initial contact frame. Repeating this with a single positive offset in the original frame number provides additional sets from each tactile video. In total, we take 10 sets of 8 frame sequences for each grasp to increase the size of the dataset.
Before being passed to the network, some preprocessing is applied to the data, as follows (Fig. 3):
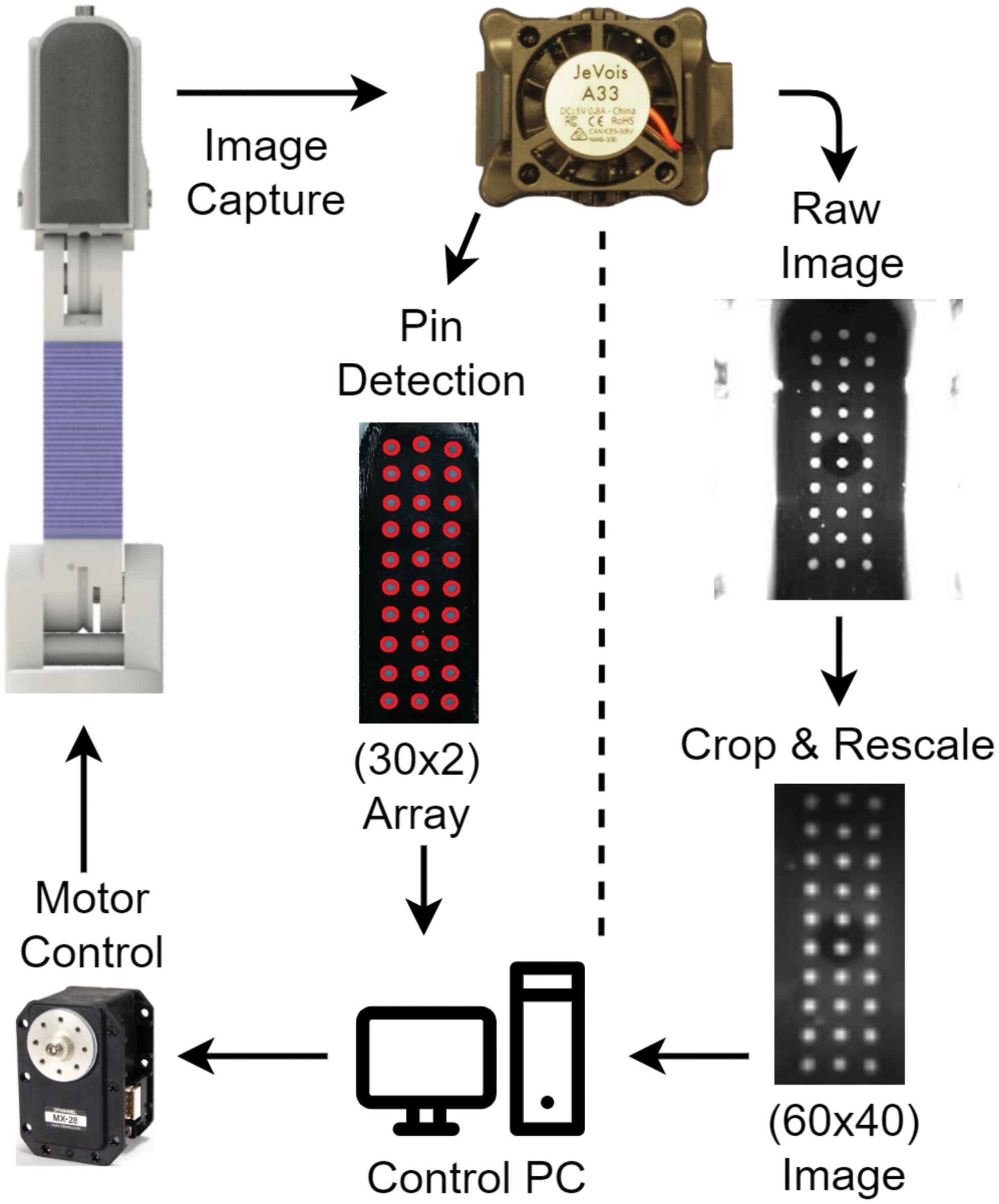
Flowchart showing the processes within the T-MO when images are captured by the JeVois. Either pins can be directly detected onboard the hand and sent to the control PC via a serial port or—as used here—raw images are cropped and rescaled before being passed to a classifier. Processes are the same for each of the three sensors. Note that the pixel dimension (bottom right in brackets) is an example and can be changed as required. Color images are available online.
Image cropping from the captured resolution of 320 × 240 down to 160 × 220 resolution to remove outer pixels that contain little or no tactile data.
Image downsampling to 40 × 60 resolution to retain enough of the information for the specific task while significantly reducing network size.
Image concatenation horizontally over the three tactile sensors to give a 120 × 60 pixel image.
These techniques were chosen through a combination of leveraging existing work40,41 and author experimentation. There are lots of options that could have an effect on performance. For example, horizontal image concatenation could be replaced with vertical concatenation, stacking or using a shared weight convolutional stage for each individual sensor image 42 ; sharing weights between networks could improve performance by exploiting the relationship between fingers 26 ; and similarly, the number of frames used per sequence or the resolution of the tactile images could be changed. We explored several of these, and the proposed method gives a simple procedure that works effectively; however, we do not rule out that other choices of setup could give slightly improved results.
Some example images are shown later in this paper, and these are taken from the objects used to test item classification. These images are the final frame of the extracted tactile sequences, so the sensor should be near its maximal deformation for that grasp.
Neural network architecture
Recent application of CNNs to a single TacTip has found highly robust performance for edge perception and contour following tasks, 40 the promise of deep learning for robot hands integrated with TacTip tactile sensors. As we are considering a sequence of tactile images, a 3D CNN is appropriate to capture both spatial and temporal information. Then, the network may learn not only the geometric properties of objects being grasped but also physical properties such as compliance during the grasping process. The network architecture chosen for this task is a standard combination of convolutional layers passing forward to a fully connected output stage (Fig. 4).

Convolutional network architecture used for item classification. Color images are available online.
Several methods of image augmentation are employed during training to reduce overfitting. This includes random cropping between 6% and 2% of width and height of an image, respectively, random zooming up to an increase of 2%, and additive Gaussian noise with variance σ2noise = 10−4. Random brightness and contrast adjustments are applied by using clip (pixel intensity scaled by α and offset by β), where the limits for α and β are randomly selected from the ranges [0.3, 1] and [−50, 50], respectively. All these are individually applied per frame and per sensor to best match the possible environments experienced during testing.
As a regularization technique, we use a dropout of 0.5 on the final fully connected layers. Batch normalization, early stopping, and learning rate decay are all used to improve performance. Patience values of 5 and 15 epochs are used for decaying the learning rate on a plateau and early stopping, respectively. A factor of 0.25 is the value used for decaying the learning rate. The loss function used is soft-max cross entropy, and the optimizer used is Adam 43 ; initialization parameters such as learning rate are given in the subsequent sections.
Autonomous grasping platform
To facilitate testing and data collection, we have built an automated grasping platform for the hand (Fig. 5). The T-MO is mounted as the end effector on a UR5 robot arm (Universal Robots), controlled by the PC used to capture and store the tactile data. In addition, a Kinect 2 RGBD camera (Microsoft) is mounted above the workspace to provide an in-depth image of objects, which we process to give putative pose estimates of use for grasping. A tray is located in front of the base of the arm into which a user can place an object and give the control PC an object label (currently the only human input into this system).
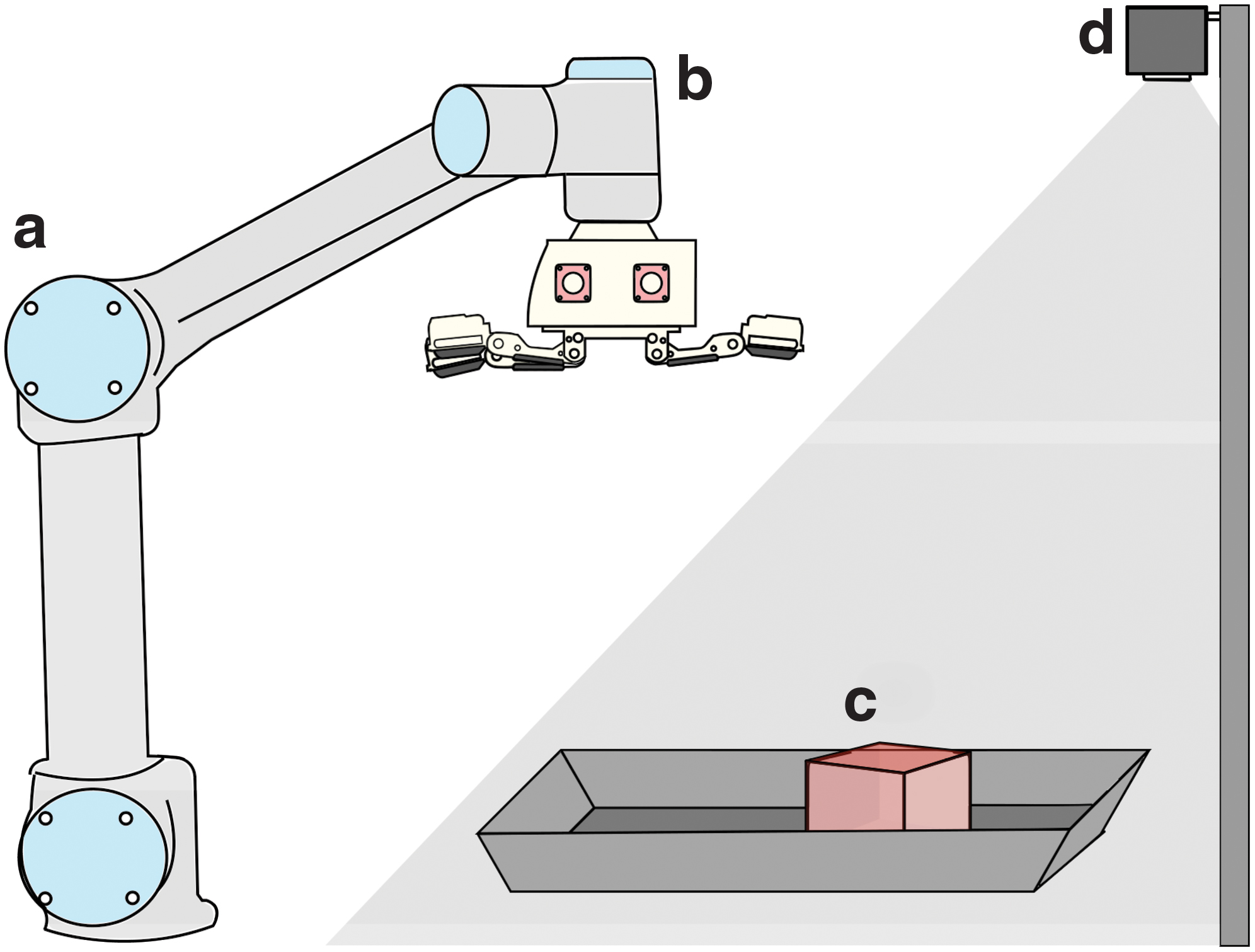
Diagram of the autonomous setup used for both collecting large amounts of data and verifying grasping capabilities of the T-MO.
This platform uses the Kinect depth images to estimate the pose of objects, which guide a simple planner for the arm-hand system to attempt to grasp and lift test objects. The depth image captured by the Kinect is first cropped to contain only the region covering the tray. The approximate depth of this tray is then obtained by averaging the depth across an entire image, which gives a reasonable approximation because the object occupies a relatively small area.
We then consider points closer than this depth minus an offset of 10 mm (to account for image noise) to give the two-dimensional extent of the object. This region is used to find the center of mass (x,y) and pose angle from the image moments, corresponding to the major and minor axes of the best-fit ellipse. A z coordinate is also estimated from the minimum object depth to guide the initial vertical hand placement before grasping at 20 mm above the object. We then transform from the coordinates in the camera frame to the robot frame to provide the position for the T-MO to grasp the object.
Further control of the hand is available in the rotation of the finger joints. Fingers 2 and 3 can be jointly rotated from 0° (cylindrical grasp), through 45° (spherical grasp), to 90° (opposed grasp). In the Grasping Benchmarks section, the grasp that is likely to be successful is then manually selected from these distinct cases depending on the geometry of the object to be grasped (e.g., Fig. 6).

Example images of the T-MO hand grasping a variety of objects from the YCB Benchmarking Object Set. Each grasp is performed by placing the object on a flat surface in a fixed position and using a UR5 robotic arm to lower the hand over the object and raise it to a specified height. This figure also shows how the rotation of the fingers can be employed to help grasp objects depending on their shape. YCB, Yale-CMU-Berkeley. Color images are available online.
In “Tactile Sensing Test I: Item Classification” and “Tactile Sensing Test II: Grasp Success Prediction” sections, we define an automatic procedure to choose the rotation of the finger joints. To do this we use the ratio of major to minor axis detected by the outline of the object by using the depth image from the Kinect. If an object has a 1:1 axis ratio, it is assumed that a spherical grasp (45°) will be best. Similarly, if an object has an aspect ratio of 1:3 or higher, it is assumed that a cylindrical grasp (0°) will be best. Overall, we found that this mapping of aspect ratio to [0°,45°] joint angle worked best for the subset of objects used here.
The tactile sensors have an immediate use within this autonomous platform, as they indicate both grasp success and also which fingers contact a held object. After the hand has grasped and attempted to lift an object, the tactile images from the three fingers at the peak of the raising movement are compared with initial nondeformed reference images before grasping. Previous work has demonstrated that the Structural Similarity Index Metric (SSIM)
44
can provide an accurate difference metric for tactile images.
45
We use SSIM to measure the difference between each tactile image and its nondeformed reference:
where u and v represent a window of N × N pixels (here n = 7) within the two images to be compared, μ and σ represent the mean and covariance of the windows given, and c1 and c2 are regularizing constants defined to stabilize the division. The regularizing constants are calculated with c1 = (k1L) 2 and c2 = (k2L) 2 where k1 = 0.01, k2 = 0.03, and L is the dynamic range of the pixel values (here 255). A single numeric similarity value for each sensor is calculated by averaging this metric over a sliding window taken across the entire image. If these values are below a predefined threshold (here 0.96) for two or more sensors, then the grasp is considered a success.
For more robust detection, this process is repeated over 20 frames and the mode SSIM is taken as a final measure. The SSIM metric is chosen, because we expect it to be robust to lighting changes likely to occur during movement of the hand (which can affect the tactile image). Testing showed that this was a reliable method and produced minimal false positive or negative results. The full method for data collection is given in Algorithm 1.

Experiment Description
Grasping benchmarks
First, we assess how modifying the existing grasping system of the Model O hand to include tactile sensors affects grasping performance, considering four grasping benchmarks from other studies. These are mainly based on the YCB object set, which comprises 77 objects in five categories, including food items and tools. 46
Grasping Benchmark 1: complete YCB set
To start, we test every object in the YCB object set to determine whether it can be grasped by the T-MO. Each object was placed at a fixed position directly beneath the hand, which was then lowered to a predefined height, a grasp was performed, and the object was lifted. Both the set height that the hand was lowered to and the grasp type (Opposed, Cylindrical, or Spherical) were prespecified on a per-object basis.
Grasping Benchmark 2: i-HY comparison
The Model O hand is originally based on the i-HY hand, which demonstrated its grasping capabilities with a benchmark involving 10 unique objects grasped 20 times. 6 Each grasp was automated by detecting the approximate center of an object by using the depth map from a Kinect RBGD sensor and aligning it to the major axis of the detected object. The same experiment is performed here (details in the Autonomous Grasping Platform section), but as the objects in the i-HY study were not standardized, we have used the most similar objects we could find.
Grasping Benchmark 3: Gripper Assessment Benchmark
Another official benchmark is the Gripper Assessment Benchmark (GAB), provided by Calli et al., 46 which is performed with a subset of objects from the YCB set. This benchmark does not use the depth sensor but instead a fixed position, as described in the benchmarking guidelines.
Grasping Benchmark 4: extended GAB
An extension to the standard GAB was proposed by Jamone et al. 47 to include three more categories of objects: Cubic, Cylindrical, and Complex. The addition of further objects provides more information about the types of object graspable by the T-MO. The experiment is undertaken in the same manner as Benchmark 3, described earlier.
Tactile sensing Test I: item classification
Bearing in mind that our modification of the Model O design was to use tactile sensing for improving the hand's functionality, we first validate the tactile sensing quality by classifying objects using the tactile images alone.
For this test, we chose a subset of 26 items from the YCB object set that satisfy two properties (Fig. 7c): They must be consistently graspable with the hand and be clearly detectable with the depth sensor (which struggles with small or clear objects). For added difficulty, some of the objects have been chosen to share either global or local geometric similarities.

To grasp the objects, we rotate the fingers of the T-MO to [0°,45°] by using only the spherical and cylindrical grasps (the Autonomous Grasping Platform section). The opposed grasp at 90° rotation is omitted, because it works best with very small objects, which are not present in the objects chosen for this tactile task. For each of the 26 objects, data were collected for 20 grasps, giving 520 unique grasp videos. The object position was varied for each grasp by randomly moving the object after a grasp and dropping it from a small height of 5 cm. This exposed different object orientations and therefore different tactile responses during data collection. It was necessary to ensure some objects faced upward, otherwise they were not graspable with our simple top-down grasp planner; for example, long cylindrical objects were placed with their elongated side on the tray surface.
The processed tactile data are then fed into a network trained to classify these objects. The architecture is as described in the Methods section, but with learning rate initialized at 10−4 and weights randomly initialized from a Gaussian with mean 0 and standard deviation 0.01. The collected data are separated into training and validation sets with a 70% to 30% split on a per-video basis (not a per sequence basis) to avoid training and testing on sequences of frames from the same grasp video.
An online experiment is used to further validate the performance on distinct test data, with four grasps performed on each of the 26 objects. Multiple tactile image sequences are taken from the grasp video and fed into the trained network as a batch (the Tactile Data section). The final prediction is the argmax of the mean prediction over the batch; in effect, the most confident prediction over all sequences extracted from a single grasp.
Tactile sensing Test II: grasp success prediction
Next, we use touch to predict whether an established grasp will be successful when lifting an object. The data are labeled (success/failure) by using the SSIM-based measure (the Autonomous Grasping Platform section) of whether the fingers are still in contact after a lift attempt.
To collect a balanced dataset with both failed and successful grasps on the same object, the tactile data were collected while introducing random perturbations in the hand pose and grasp. The hand pose was perturbed by a uniform-random distributed [−20,20] mm variation in the (x,y)-coordinates, a [0,20] mm z perturbation, and a [−30°,30°] axial perturbation. The finger joint rotation was also varied randomly between [0°,45°] and the maximum torque between 20% and 35% of the maximum instantaneous and static motor torque (compared with 30% as previously used), which also affected the speed of finger movement during a grasp. Overall, these perturbations reduced the grasp success to 80% of the 520 collected grasps (Fig. 6); the same objects are depicted in the Tactile Sensing Test I: Item Classification section.
The processed tactile data were again fed into a neural network, with the same architecture as in the Tactile Sensing Test I: Item Classification section. Minor hyperparameter changes (dropout increased to 0.75; learning rate decreased to 10−6) are made to reduce overfitting, which became more prevalent in this task. The output layer gives a two-label classification, with each grasp predicted as a success or failure according to the mean output of the final softmax layer of the network (successful grasp category being >0.5).
A final aspect of this experiment measures whether there is a correlation between force applied when grasping an object and grasp success prediction. We performed an additional experiment in which the maximum motor torque is varied over 12 grasps from barely touching to firmly holding the object (from 11% to 35% of the maximum instantaneous and static motor torque, where each grasp has an increment of 2% in this torque). This test was performed over four objects having uniform grasping surfaces (Baseball, Orange, Bleach, GumPot) to control for factors such as positions of edges and textures on more complex objects. The GumPot is a novel object that is used to test whether the learned features generalize outside of the objects used for training.
Tactile sensing Test III: sensitivity analysis
Our final analysis investigates how the T-MO behaves with a reduced number of tactile sensors. All systems are liable to breakage or temporary inaction, so determining whether a system remains effective when operating at reduced capacity is an important consideration. This test also gives an improved understanding of how the tactile information has been employed for item classification and grasp success prediction.
In this test, we re-used the data from the previous experiments of item classification (the Test I, Tactile Sensing Test I: Item Classification section) and grasp success prediction (the Test II, Tactile Sensing Test II: Grasp Success Prediction section), with all possible combinations of “working” tactile sensors. The validation accuracy is then assessed after retraining the neural networks using these limited tactile observations.
Results
Grasping benchmarks
The T-MO successfully grasped the majority of the objects in the YCB set (Grasping Benchmark 1) only struggling on the larger heavier objects and the smaller flat ones (successful/unsuccessful objects shown in Fig. 7).
The T-MO also had strong results in 7 out of 10 objects based on those used to test the i-HY (Grasping Benchmark 2), with at least 18 out of 20 trialed grasps being successful. The remaining three objects—a hammer, file, and pen—were unsuccessful, because the thickness of the redesigned distal phalanges did not allow us to use the previous technique of driving the hand into the table to perform a power grasp. Similarly, the compliance of the tactile sensors results in pinch grasps being more subject to failure when given high torsional forces.
Although the i-HY apparently scored better than the T-MO in this test (the i-HY only struggled with the pen), there are, thus, subtleties with comparing these results directly. As the objects tested on the i-HY were not standardized, we could only use similar but not identical objects in our comparison. Nevertheless, this test does indicate the physical properties of objects that the T-MO is likely to struggle with, indicating limitations in the design.
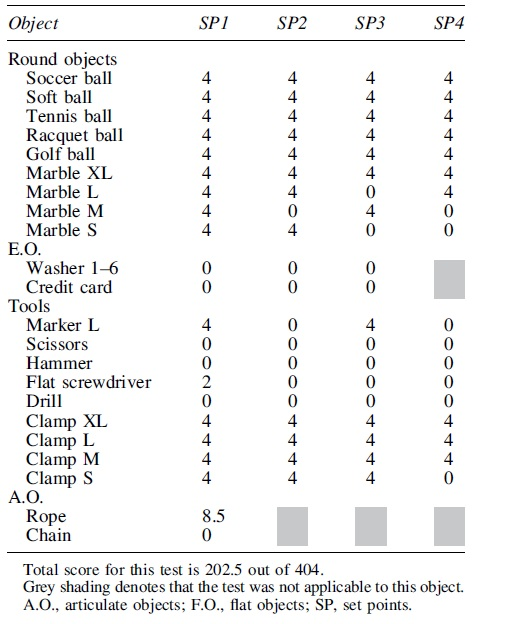
To further validate the grasping capabilities of the T-MO hand, two standardized benchmarks, the GAB and extended GAB (EGAB), were deployed. These two tests carry much more weight when compared with other systems, as they involve a rigorous, standardized procedure. Overall, the total score for the GAB was 202.5 out of 404 (complete scores for each object shown in Table 1), and the total score for EGAB was 176 out of 208 (complete scores in Table 2).
Total score for this test is 176 out of 208.
Therefore, performance of the T-MO hand is competitive with other hand designs, surpassing the iCub (173/404) and Model T (122/404) scores. The T-MO also surpassed the iCub score (164/208) in the Extended Benchmark. That said, flat objects prove a significant challenge for this hand, resulting in a drop in the overall score. Although it would be possible to modify this hand with a nail design to help grasp flat objects, this would require significant modification of the tactile-sensing part of the design to remain effective. To guide this modification, it would be useful to also have a comparison with the original Model-O hand, but to the best of our knowledge this is not available.
Other GRAB Lab robotic hands do achieve better scores on the standard benchmark. These include the Model B, Model T42, and Model S, which score 270, 379, and 402.5 out of 404, respectively (none of which have tactile sensing). These higher scores are mostly due to the fingernail designs that are useful for picking up flat objects and possess the ability to pick up heavy objects by using a power grasp. Most tactile sensors focus on the fingertips of robotic hands, avoiding fingernail designs and palm sensors. This generally reduces the ability to grasp flat and heavy objects and results in lower benchmark scores. To the best of our knowledge, the T-MO is the highest scoring hand with tactile capabilities.
Tactile sensing Test I: item classification
The first test of the tactile sensing capabilities involved identification of 26 objects (Fig. 7c) from a grasp by using only tactile data fed into a CNN (example tactile image for each object shown in Fig. 8). The overall accuracy found over this set was 93%. Misclassifications tend to be on objects that share some geometric similarities (confusion matrix shown in Fig. 9). For example, both the pudding box and sugar box are rectangular with similar depths (32 and 37 mm), giving an edge in the sensor images at approximately the same location.

Examples of tactile images extracted from a grasp for each object used in the item classification task. Each image is taken when the sensor is under its maximal deformation. The bright spot visible at the top left of each middle sensor image is caused by glare from the LEDs on the sensor's acrylic lens. As this is consistent across all objects, the glare does not provide any useful features from which a Convolutional Neural Network can learn; therefore, we do not expect this to have an effect on tactile sensing.
Confusion matrix demonstrating the validation results of the object classification based on purely tactile information task. The overall validation accuracy for this task is ∼93%. Colored shading indicates non-zero entries. The darker shading on main diagonal corresponds to the more accurate predictions. Color images are available online.
For round objects, the misclassifications seem reasonable; for example, depending on the grasp direction, the peach and pear objects are of similar size and curvature. The worst performance for item classification was on the golf ball. We attribute this to it being the smallest object, which may lead to frames being passed to the CNN before any sensors contacting the object. Consequently, there are fewer tactile images in which deformation occurs, resulting in less data from which the networks can learn useful features.
When testing on online test data, the overall accuracy was 77%, with similar misclassifications as the offline validation described earlier. Considering there are 26 objects, many of which have geometric similarities, this is good performance but clearly poorer than the 93% validation accuracy. This drop in performance indicates that the training has not generalized fully to off-sample data, most likely because there is a large number of possible positions and orientations for unconstrained objects. We expect that a larger training set would enable better determination of features that generalize across different positions and orientations. The present dataset is sufficient, however, to show reasonable online performance and indicate directions for future improvement.
Tactile sensing Test II: grasp success prediction
The second test of the tactile sensing involved predicting whether a grasped object, once lifted, would be successfully held. On successful grasps, the classifier was almost always correct with 98% true positives and only 2% of false positive predictions when the grasp was predicted to fail but was actually a success. On unsuccessful grasps, 82% true negatives were correctly predicted, with 18% false negatives of predicting that a grasp would succeed when it actually failed (Table 3).
Confusion Matrix Demonstrating the Validation Accuracy of the Trained Neural Network Predicting Whether a Grasp Will Be Successful or Unsuccessful
However, the baseline accuracy for this task is that 80% of all grasps were successful (20% unsuccessful). Therefore, overall, the predictor correctly predicted true positives or true negatives on 95% of the validation data (since the 18% false negative rate was on 20% of the data). It is evident that the bias prevalent in the data, which contains fewer unsuccessful grasps, is also present in the trained network, with the majority of misclassifications being false negatives.
Based on our observations of failure cases, we hypothesize that the motor torque variation was having the most effect on grasp success prediction, which makes sense intuitively because less firmly held objects will provide poorer tactile data. To test this hypothesis, we performed an additional experiment in which the maximum motor torque is varied over grasps from barely touching to firmly holding the object.
The results of this test indicate a strong trend between applied force and successful grasp prediction (Fig. 10a). Once the grasp has been established and the prediction made, the arm attempts to raise the object and a ground truth of whether the grasp was successful or not is taken (Fig. 10a; blue/red points for correct/incorrect predictions). The overall accuracy achieved in this test matched that of the validation data, with 92% of grasps being classified correctly (75% for predicting unsuccessful grasps; 100% for successful grasps).

Overall, the network has learnt that a higher grasping force is more likely to be successful. There is a sharp drop where the network switches from predicting successful to unsuccessful grasps (near a normalized torque of 0.19). Torques close to this boundary are where incorrect predictions are most common (red markers, Fig. 10a). High and low grasping force tends to result in correct predictions, which we interpret as from either the tactile information being sufficiently good for accurate prediction (high torque) or because the classifier indicated an insufficient torque for a successful grasp.
Tactile sensing Test III: sensitivity analysis
To determine how well the T-MO performs in scenarios where some sensors are not operational, our final test repeated the previous two experiments with various sensor combinations. As expected, the best performance for both tests was when using all three tactile sensors (Fig. 10b). Also, as expected, the performance dropped for all three combinations of two sensors (sensors 1,2; 1,3; and 2,3) and dropped once again when using only of one of the three tactile sensors (sensors 1, 2, or 3). However, the drop in performance reduction from three to two sensors was relatively small, with a mean drop of 7% from 93% for Test I and of 2% from 95% for Test II, revealing redundancy in the sensor readings. The performance drop was larger from three to a single sensor (mean 18% for Test I and 5% for Test II), but perhaps not as much as anticipated.
In Test II (the Tactile Sensing Test II: Grasp Success Prediction section), the highest single sensor accuracy for grasp success prediction is for sensor 1. This is expected because this finger is needed to apply a force that opposes the other two fingers during all successful grasps, and therefore should carry the most relevant information to indicate a failing grasp. However, in Test I (the Tactile Sensing Test I: Item Classification section), the opposite trend is visible: Sensor 1 scores the lowest accuracy for a single sensor. To explain this, we observe that sensor 1 is aligned to the major axis of the object during grasping (the Autonomous Grasping Platform section), whereas the other two fingers are rotated depending on the object. Therefore, there may be less variation for sensor 1 on the object surface than the other two sensors, and hence less information about object identity.
Although there is a significant reduction in performance when using only a single sensor, particularly on the item classification task, an interesting area for further study is how to combine the predictions from all three single-sensor networks. Single-sensor networks have significant hardware benefits, because they enable individual predictions by using the embedded graphics processing unit (GPU) functionality for each tactile sensor.
Therefore, for a final sensitivity test, we make a prediction voted by networks trained for each individual sensor (rather than having all three images fed into the same network). A prediction is made by taking the mean of all values predicted by the three networks. When applying this technique to the validation data, the performance improves to 91% in the item classification task (from mean 75%), close to the 93% performance of a network trained directly on all three sensors. Similarly, the performance on the grasp success prediction task is 92% (from mean 90%) compared with 95% when combining all three tactile images, indicating the benefit of using individual tactile sensor predictions.
Discussion
We have presented a three-fingered tactile hand that comprises a GRAB Lab Model O modified to include three TacTip soft biomimetic optical tactile sensors in its fingertips. Using small camera modules mounted in the distal phalanx of each finger coupled with the JeVois vision system housed in the “palm” of the hand and lightweight TacTip sensors provided an integrated and sophisticated tactile sense that complements the grasping functionality of the hand.
To evaluate the capabilities of the T-MO, we benchmarked its grasping performance by using the GAB on the YCB object set. 46 We then tested the tactile sensing capabilities with two experiments: first, tactile object classification and second, predicting whether a grasp will successfully lift an object.
Grasping capability
In the GAB, we scored similarly (202.5/404) to the Model T and iCub hands (122/404 and 173/404) but were surpassed by other hands produced by the GRABLab. 48 This included a test where the iHY hand (on which the model O is based) could grasp all 20 objects and the T-MO could reliably grasp 17 items. The reason for this performance drop is the change to the finger morphology needed to integrate our tactile sensors within the distal phalanx that can be improved in future design iterations of the hand. Due to the thickness of the redesigned distal phalanges, the technique of driving the hand into the table to perform a power grasp was no longer possible.
Future design improvements to the tactile fingertips will focus around a more compact design that would help grasp small objects with a “fingernail” and larger objects by sliding under them to establish a power grasp. At present, to avoid distortion of the tactile image we use a lens with a 90° field-of-view, which constrains the camera to be mounted fairly high above the sensing surface.
One redesign strategy would be to adopt mirrors that enable the camera to be mounted nearer the joint, as in the GelSlim. 20 That said, camera technology is going through a stage of rapid miniaturization, and it may be that a combination of a smaller camera with a wide-angle lens would be more effective. In addition, using different gel mediums and skin materials to test the effect of sensor friction and compliance on grasping capability would be an interesting future study. For example, a higher friction surface would allow for objects to be grasped with lower force and a more compliant sensor may improve tactile perception because of its greater deformation, which are subjects for future study.
Tactile sensing
When attempting an item classification task (Test I: Tactile Sensing Test I: Item Classification section), we obtain 93% validation accuracy on 26 objects randomly placed in the tray to vary the grasp. This performance is comparable to other studies, such as Spiers et al. 22 (94%), Schmitz et al. 16 (88%), and Funabashi et al. 25 (95%) but it is surpassed by Flintoff et al. (99%). That said, a direct comparison between studies is not possible because the hands and tactile sensors differ, along with the objects and experiments. In particular, our T-MO picked objects off a table, whereas other studies such as Regoli et al. 24 obtain up to 98% on a smaller set of 21 objects that were passed to static mounted hands, which does not control against the human help providing a better grasp for object classification.
Our other main test was to predict whether a grasp would successfully lift an object (the Test II: Tactile Sensing Test II: Grasp Success Prediction section). We obtain 95% accuracy of grasp success prediction on the same 26 objects as Test I but with their grasp poses perturbed randomly so that some grasps fail on lifting. Calandra et al. 42 performed a similar experiment and obtained 75.6% validation accuracy when using tactile information from two GelSight sensors. This was performed on a larger dataset with more (and different) objects, and the data were split such that an object was only in the training or test set, so again a direct comparison is not possible. We also exceed the results of Wan et al. 27 (90%) and Krug et al. 29 (74%) but, again, there are significant experimental differences.
In addition to reporting validation results, we use an online dataset to assess performance for both item classification (Test I) and grasp success prediction (Test II). There was an appreciable (16%) drop in performance from the offline validation (93%) to an online test (77%). This performance drop is partly due to changes that may occur over time and are not captured in training, such as trial-to-trial variation in tension of the springs and cables, or movement of the cameras within the tactile sensors. Despite the small number of online trials per object, the total number of tests (104) demonstrates that the T-MO is capable of robust grasp success prediction and object classification in real time. Moreover, these results are more comprehensive than previous work where online tests were not performed.23,25
We cannot rule out some over-fitting to the training set, although measures were taken to reduce this (the Neural Network Architecture section). A larger dataset would allow exploration of more complicated networks, such as introducing recurrent neural networks for improved use of temporal information rather than the 3D (2 space, 1 time) convolutions used. Although more data may improve the accuracy of the online tactile predictions, the priority in this initial study was to establish the T-MO's credibility as a tactile grasping system.
A further tactile analysis was conducted by testing the T-MO with differing numbers of working tactile sensors to demonstrate the benefit of a three-fingered system. When two sensors were active, results were not greatly affected compared with all three sensors. The greatest drop in performance was when the “thumb” was omitted. When using an opposed grasp, the thumb has the highest normal force, which may thus provide more reliable tactile information. Conversely, dropping to just a single sensor resulted in a large performance drop.
Overall, we sought to maximize performance while minimizing cost and complexity. Hence, this result demonstrates that three fingers enable high performance even under reduced operating conditions. In contrast, two-finger grippers may be rendered inoperable under the loss of a single tactile sensor, whereas four-plus finger systems add cost and complexity.
The JeVois camera system used here is small and of low cost with machine vision processing modules that are small enough to be embedded within the hand. In principle, onboard processing could be performed via neural networks loaded on the modules by using TensorFlow Lite compatibility. This was not utilized in this study, but would give a route to process and react to captured images without the need for a high-performance control PC. Alternatively, a dimensionally reduced output, such as that from the convolutional layers, could be sent to reduce the processing requirements external to the hand. This would give a semi-autonomous robot hand the ability to interpret its tactile sense.
For an initial exploration of the potential of this onboard processing, we examined whether item classification could be accurately performed on the hand (the Tactile Sensing Test III: Sensitivity Analysis section). The camera processing modules are not directly connected to each other, so the tactile images from each sensor must be processed independently. If the mean prediction from all three sensors is used (rather than processing data from all three), the performance drops by just 2% to 91% for item classification (Test I) and by 3% to 92% for grasp success prediction (Test II). This shows that deployment of the computation on the JeVois would give a small reduction in performance. Use of the onboard processing would allow the T-MO to be deployed as a complete autonomous system.
Hardware design
In this study, we use the same 3D-printed skin as other tactile sensors within the TacTip family, with an array of pins spaced ∼3 mm apart that were developed originally for a 40 mm-diameter, domed tactile sensor. 7 This design choice was for consistency in the absence of a good reason to customize those aspects, unlike, for example, the overall shape of the sensing surface, which required customization to fit onto the Model O fingertip. However, it does result in relatively few pins (a 10 × 3 array) compared with others in the TacTip family. 7 Since these pins are used as sensing elements, this may limit the tactile sensor performance.
When compared with previous hands with integrated TacTip sensors, there are two clear operational benefits provided by the T-MO. First, the T-MO is entirely self-contained with onboard processing, allowing computational load on the control PC to be reduced. This is not the case with the M28 and Shadow Modular Grasper 49 hands integrated with TacTips. The tactile integration of the two-fingered GR2 gripper 9 utilized Raspberry Pi computers but these were not integrated into the design, meaning that the entire system cannot at present be attached as a single unit to a robotic arm. The second advantage is having three sensors: The T-MO retained high tactile sensing performance when operating with two sensors, but performance dropped significantly for just one sensor; in contrast, any loss of sensing for the GR2 or M2 hands would potentially have much more performance loss.
There are many design options that may improve tactile sensor performance: The pins could be made smaller, the skin thinner, the pin spacing could be nonuniform, the shape or distribution of the pins could be changed, raised “fingerprints” used 31 or a differently shaped sensing area, such as circles. 9 could be tested. It is hard to intuit the effect of these choices and despite the platform being autonomous, it does require human supervision/intervention and so a rigorous examination of multiple designs, though feasible, would be laborious. We anticipate the best design will be task dependent, and so likely different for each tactile benchmark considered here.
For a final comment, we note that the T-MO is able to perform well in comparison with other tactile hands even though it has a much lower cost (costing us less than £1100 to make). We have demonstrated comparable results in tactile perception to previous work that utilizes more expensive robot systems such as the BarrettHand, 28 Schunk, 26 and iCub 24 hands. Most of the T-MO's cost is actually its motors, followed by the 3D printing and camera costs, so it may be possible to reduce these costs still further. A benefit of building the hand ourselves is that we can quickly fix issues such as accidental damage or parts failure, whereas being 3D printed means the hand can be adapted to various applications and we can fix design problems that only become apparent later in its use.
Conclusion
Overall, we have demonstrated that soft biomimetic tactile sensors embedded within a robot hand—the T-MO—are able to accurately distinguish and categorize objects by using only tactile information from the finger surface deformation. This ability to classify objects without vision is essential in many scenarios, such as clearing items from a cluttered bin and where a visual snapshot may not be a reliable indicator of the object properties. The T-MO demonstrated high performance at object recognition and grasp success prediction, with both of these relatively robust to sensor failure. Further, we anticipate that grasping performance could be enhanced by further design changes such as the addition of a fingernail and testing different sensor constructions.
The T-MO is a low-cost, 3D-printed tactile robot hand with multipurpose tactile sensing capability and the ability to undertake computation onboard the hand to reduce the high bandwidth requirements associated with images. In addition, to the authors' knowledge, no other system has demonstrated the ability to perform both grasp stability prediction and object classification in real time and in a single attempt. We believe this demonstrates that the T-MO is an effective platform for robot hand research, and we expect it to open up a range of applications in autonomous object handling.
Footnotes
Acknowledgments
The authors thank Kirsty Aquilina, Gareth Griffiths, Raia Hadsell, John Lloyd, Nicholas Pestell, Andrew Stinchcombe, and Ben Ward-Cherrier for their help.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
N.F.L. was supported in part by a Leverhulme Trust Research Leadership Award on “A biomimetic forebrain for robot touch” (RL-2016-039). J.W.J. and L.C. were supported by the EPSRC Centre for Doctoral Training in Future Autonomous and Robotic Systems (FARSCOPE). A.C. was supported by Google DeepMind.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.