
Abstract
This article investigates the task of folding a fabric using a human–robot collaboration (HRC) solution. HRC is a widely adopted concept in the industrial realm, as physical interaction between operators and robots has enabled the former to focus on high-value tasks and the latter to complete repetitive, physically strenuous, and risky tasks. This article proposes a robust framework based on Kalman filter pose estimation, for the human–robot comanipulation in folding of fabrics. The framework utilizes the Kinect 2 tracking algorithm to find the location of the operator and then performs Kalman filtering to eliminate noise and improve the tracking of the operator’s position. The robot reacts to the operator’s movement, by moving to the same hand direction and distance on each iteration, to assist in the folding of a rectangular fabric. The proposed system was tested in a real use case scenario, where the collaborative task is the fold of a rectangular fabric, and the presented results showed that the system is capable of tracking the human motion to assist him.
Introduction
The textile industry has historically relied on manual labor, particularly in developing countries where it is more economical. Advancements in technology and robotics have sparked renewed interest in automating the textile industry, particularly in manipulating nonrigid objects. This automation has broad applications in various sectors, including domestic, agricultural, automotive, and robotic space industries. Fabric handling tasks, upholstery installation, and satellite blanket manipulation could see significant productivity gains and risk reduction through automation.
Automation of hand layup in creating composite structures from multiple layers of materials presents another compelling application of nonrigid object manipulation. 1 In domestic settings, automated fabric manipulation can aid individuals with special needs or disabilities, facilitating daily tasks like bed making and dressing. Automating textile production poses challenges due to the unpredictable nature of nonrigid objects. Their low bending resistance and complex dynamics make them prone to deformations, unlike rigid objects. 2 The increasing fabric variety complicates matters, requiring sophisticated control methods and highly specialized approaches to overcome obstacles in automation.
The robotic systems for manipulating fabrics are based on single robots9–12,30 or multiple robots.3–8,27 Most of these applications use a vision-based system that can identify the fabric’s position and state (folded/unfolded/wrinkled/unwrinkled) by extracting useful geometric features3,4,6–8,11,29 or machine learning models that are trained on human motion5,9,24,29 or by generating a folding trajectory based on human motion planning.10,12,28,30 These approaches require complex algorithmic models and are not applicable to large fabrics due to the limited workspace of the robots.
Most recent applications make use of the adaptability and customization of collaborative robots and the intelligence of humans to create a human–robot collaboration framework for fabric manipulation.13–15,23 In Koustoumpardis et al.’s 13 study, a hybrid vision–force control system that tracks human motion was used to enable the robot to assist the human guide. In Kruse et al.’s 14 study, a hybrid vision–force control system was used to identify the fabric’s state (wrinkles/deformations) and calculate the appropriate direction to follow the operator’s movement. Alternatively, in Koustoumpardis and Aspragathos’s 15 study, instead of a visions system, a neural network force controller is incorporated to regulate the fabric’s tensional forces and comply to the human’s motion. In Sidiropoulos et al.’s 23 study, a combination of a hybrid dynamic movement primitives (DMP)-based and force control input with an external Kalman filter (KF) was used, for the robot to be able to assist the human by minimizing his/her effort of transferring an object.
Predicting future values in unstable systems with unpredictable behavior is crucial. Besides the KF, methods like the linear unknown input observer (LUIO) and nonlinear unknown input observer (NUIO) are utilized. LUIO, employing linear algebra, is effective in linear systems with unknown inputs, while NUIO handles nonlinear systems with noisy or unknown inputs.33–35 To ensure stability, observer gains are estimated using techniques, such as solving linear matrix inequalities (LMIs) or equations (LMEs). 36 NUIOs find applications in fault detection, robust control, and state estimation. An advanced method, the extended state observer (ESO), estimates both state and unknown input simultaneously in nonlinear systems.37,38 However, it requires more tuning parameters, is sensitive to noise, and faces stability analysis challenges. These systems, incorporating observers for predicting system behavior, find applications in human–robot collaborative scenarios, especially in tasks involving heavy fabrics where the human teleoperates the robot.25,26
This article proposes an enhanced approach for collaborative human–robot comanipulation and folding rectangular cloth pieces. It aims to bridge the automation gap by harnessing human–robot collaboration benefits and flexibility, facilitated by Kalman filtering. The design integrates human decision-making, perception, and cognition with the robot’s precision and repeatability, forming an efficient system for complex fabric handling. Human guidance combined with robot accuracy maximized performance. The system’s testing involves two serial fabric folds, with detailed sections covering problem statement, framework, decision-making model, system architecture, simulation, experimental results, and conclusions with future work. The Proposed Framework section introduces the problem statement and proposed framework, followed by the simulation of the proposed system in the Simulation section. Experimental results are presented in the Results for the Experimental Case Study of Folding section and conclusions and future work are discussed in the Conclusion section.
Proposed Framework
The proposed approach utilizes a single Kinect 2 sensor, instead of using Asus Xtion sensor, 13 to detect fabric position, corners, and operator hand position, offering a lower error rate, requiring no training or prior knowledge, relying solely on recognizing human intentions and movements. Comanipulation begins with identifying the human state using a decision-making model that considers hand position and orientation to determine folding direction and starting/stopping positions for both human and robot. While previous work applied a general moving average filter for sensor data smoothing, this approach utilizes the KF, known for improving tracking accuracy with Kinect data. It is also able to smooth the spatial coordinates of a movement and with a fine tuning of Kalman Gain it can eliminate any rapid movements that can damage the robot or the operator.20–22
This approach integrates a force sensor with vision feedback for collaborative motion, ensuring fabric tension monitoring and robot position correction when vision system fails. The proposed method employs a more intelligent grasping technique inspired by Koustoumpardis et al. 16 An illustration of the proposed system is provided in Figure 1.

Proposed system and state transition diagram.
The developed system aims to enable robot assistance to the operator based solely on identifying intentions and motion, without relying on prior knowledge of fabric properties. The state transition diagram in Figure 1, adapted from Koustoumpardis et al. 13 with an additional decision model state, outlines hierarchical states during collaboration. Like in Koustoumpardis et al.’s 13 study, the Setup state involves the operator placing the fabric, transitioning to Human Motion state upon fabric position identification. The Decision Model determines folding direction based on hand orientation, initiating Robot Motion state for fabric manipulation. Collaboration concludes when both reach stopping positions. The current method differences from Koustoumpardis et al.’s 13 study are summarized in Table 1.
Differences Between This Article and the Previous Work 13
Human tracking
The RGB-D sensor is used to monitor the operator’s right-hand position, orientation, and state (open/closed) and identify the fabric’s grasping points as well as the position calculating a 25-keypoint skeleton inside the collaborative space.
Infrared sensors, are sensitive to sunlight, humidity, temperature, reflective surfaces, and rapid movements, thus generate a lot of noise due to self-occlusion,20,22 struggling the skeleton tracking accuracy when objects are moving fast in complex environment. Therefore, a nonlinear KF was considered20,21 to predict in real time the state vector of a moving object as a discrete time stochastic process, estimating the 6-dimensional position and velocity joint point. The KF dynamics was applied on the operator’s hand, wrist, and hand tip joint:
High Kalman Gain values prioritize recent measurements, making the filter more responsive to them. In our application, the KF is engineered not to react to rapid changes in Kinect’s measurements, as such movements are not anticipated during collaborative tasks. This is achieved by leveraging the Kalman Gain, which ensures that short-time deviations do not influence the estimated state. In addition, the KF is applied to the force values generated from the force sensor.
The KF predictions of the operator’s right wrist and hand are used to estimate the angles between the hand and sensor coordinate systems. The hand line vector is computed using the equation 3. The corresponding angles are derived from equations 4–6.
The sensor’s tracking algorithm provides additional information related to the tracked hand gesture state, recognizing if the hands are in open or closed position, by processing the opened fingers’ area and the area ratio that the hand covers. In case of partial occlusions (the operator holds the fabric and part of his hand is hidden below the fabric), the previously discussed algorithm fails to identify the operator’s hand state.
Initially, a color-based skin detection algorithm is applied by cropping a region of interest around the operator’s hand (Fig. 2a), transforming the image from the RGB to the HSV color space (Fig. 2b). After detecting the hand area (Fig. 2c), the hand contour and its convex hull (Fig. 2d) is estimated. Based on this information, their convexity defects are derived as the difference between the hand’s contour and convex hull, the yellow triangles shown in Figure 2e. Consequently, the farthest point from the convex hull line that belongs to the same convex defect area (blue dot between fingers in Fig. 2f), its distance d from that convex hull line (blue perpendicular line in Fig. 2f), and the angle φ between the two triangle sides that the farthest point belongs (Fig. 2f) are estimated.

Hand state classification algorithm.
Thresholding the distance d and angle φ, the algorithm differentiates between the convexity defects of the hand and the fingers, as shown in Figure 2f. The convexity defects on the right side of the little finger and on the left of the thumb have bigger angle values or smaller distances. The proposed method counts how many fingers are open and classifies the hand as open if more than two fingers are counted, giving accurate results when the hand is facing the camera in a clear view and in close distances.
Improving the method robustness and overcoming these limitations, the ratio of the convex and the contour area is estimated. A closed hand (less than two convexity defects) has small ratios as the convex hull will tend to coincide to the hand contour. In addition, the ratio value is dynamically scaled using the distance of the hand from Kinect. The state of the hand is identified using the number of fingers and the computed ratio, as shown in Equation 7.
The operator’s hand position, orientation, and state are used in the decision-making model to identify the operator’s intentions and to estimate the appropriate robot’s starting position.
Decision-making model
The decision-making model is designed to identify the operator-desired folding direction, as shown in Figure 3. Our method is restricted to rectangular fabrics but can be easily modified to compensate for more shapes.

Decision-making model example.
Label each fabric corner, starting with the closest to the RGB-D sensor (placed in the bottom right corner of Fig. 3) that has the lowest x value as Bottom Right (BR) and continues clockwise, from the sensor’s view with Bottom Left (BL), Top Left (TL), and Top Right (TR).
Identify the corner that the operator grabbed (BL in Fig. 3) and compute the appropriate robot starting corner. The operator’s and robot’s starting corner are always adjacent and never diagonally, as the fabric cannot be physically folded this way. Therefore, only two options for the robot to grab are available (green circles in Fig. 3).
The hand’s orientation, in relation to the fabric, is used to identify the folding direction. Given the operator’s grabbed corner the model constructs two vectors representing the fabric lines that include the grabbed corner (purple vectors in Fig. 3).
The hand line vector is computed as described in Human tracking section.
The angles between the fabric line vectors and the hand line vector are estimated using equations (3–5) and the line with the lowest angle, because the hand line must be parallel to that fabric line.
The second corner defines the robot’s starting direction. In Figure 3, the hand angle is closer to the BR line, thus the model identifies the path depicted by the blue arrow pointing from the bottom line to the top line as the folding direction, as well as the BR corner as the robot’s starting position and the TR corner as the robot’s ending position.
Once the robot determines its starting position, it proceeds to execute the grasping, lifting the fabric off the table. Our decision-making model currently caters only to rectangular fabrics. However, a more versatile model could be developed to accommodate various shapes and determine starting points and folding directions accordingly. Moreover, the contrast between the fabric and the surface color influences the accuracy of the robot in grasping the fabric.
Fabric grasping technique
The fabric grasping technique (Fig. 4), based on Koustoumpardis et al., 16 mimics human fabric handling. Featuring three fingers, with two capable of rotation and longer than the third, the gripper offers adaptability to various sizes, shapes, and material types, along with flexibility and maneuverability during approach, grasping, and manipulation, owing to the multiple degrees of freedom provided by its fingers. The gripper’s fingers offer low bending resistance, enabling them to slide on various surfaces like a human finger lifting fabric. It is designed to approach fabric corners at a 45° angle between the smaller, nonrotating finger and the fabric center, ensuring the nonrotating finger reaches the corner effectively, as depicted in Figure 4’s top view.

Fabric grasping technique.
After approaching the fabric, the gripper uses the following four steps to grasp and lift the fabric as shown in Figure 4:
The two rotating fingers align parallel to the 45° purple line and gradually descend toward the fabric until contact is sensed through pressure on the force sensor. This process allows the fingers to exert force on the fabric, immobilizing it on the table. The third nonrotating finger initiates its motion toward the fabric’s end to lift it off the table, as seen in step 2 in Figure 4. The two rotating fingers adjust to center the nonrotating finger. The two rotating fingers pinch the fabric corner to secure it tightly, ensuring it remains securely held by the gripper throughout the human–robot collaboration.
These four steps offer an effective method for grasping and lifting the fabric, ensuring a secure hold as the fingers apply pressure and squeeze the fabric, without deformations for folding the fabric symmetrically with minimal wrinkles. After grasping the fabric, the robot is ready to collaborate with the operator to manipulate the fabric as described in the next section.
System architecture
For proper fabric folding, synchronization between human and robot motion is essential. Like the prior collaboration attempt, 13 the hybrid RGB-D–force feedback control system is employed to track the human’s hand position, orientation, and state, along with the applied force on the fabric, as illustrated in Figure 5.

RGB-D–Force feedback control.
The RGB-D sensor tracks the human hand’s position, while a KF enhances tracking accuracy by mitigating the position and spikes noise from the Kinect’s algorithm. The filter operates in two steps: In the prediction step, a mathematical model updates the human hand state Qt, predicting the future state Qt+1 using matrices A and B to model the system’s physical behavior and α for constant acceleration.
After state prediction, KF takes into consideration the measurement noise and the error covariance of the state:
In the correction step, the KF compares the measured and the prediction values using the Kalman Gain factor:
The gain can be adjusted using the Ez and Ex matrices. When there’s minimal expected noise in measurements (Ez approaching zero), the Kalman Gain remains relatively constant, closely tracking measurements with high responsiveness. Conversely, a low Kalman Gain (P approaching zero) leads to slower response of the predicted state to measurement changes.
After calculating the Kalman Gain, the predicted state can be corrected by:
The new error covariance matrix is given by:
The dynamics used to describe the movement of the human hand in one axis is:
The matrix values for position noise are derived from experimental measurements in the Kinect collected data31,32 and are given by:
The covariance matrix Ex, is derived from the standard deviation and σp, σp, and σv and are:
The constant matrix C is defined as:
The parameters t, noisemagnitude, and noisex/y/z are the KF adjustable parameters used to fine-tune the predictions accuracy. The value of t is set to 4/30, because the Kinect’s 1/30 frame rate is adjusted to 4/30 due to the computational load, and the noisemagnitude is fixed at 4 as specified in equation 16.
Kalman estimation calculates the distance traveled by the operator’s hand on each axis by comparing current and previous positions. This difference is then added to the end-effector’s Cartesian position for consistent movement. Force sensor measurements are filtered using Kalman filtering, and the estimated value is utilized by the proportional controller (proportional gain kp = 1.35) to compute position error.
The KF noise magnitude for the force sensor was set at 5N. Force feedback aids collaboration only in the x± and y± directions (Fig. 5). In these directions, the vision sensor alone fails to detect hand motion since the operator can only apply force and stretch the fabric but cannot physically pull the robotic arm toward them, keeping their hand motionless. The force feedback error serves two main purposes: allowing the human to pull the robotic arm toward them as needed and preventing the robot’s end-effector from inadvertently pulling the human during incorrect hand motions.
The force sensor state update is:
The position output is derived by:
The robot’s joint values are determined through inverse kinematics to facilitate linear movement. This integrated system is developed and assessed in both simulation and real-world scenarios. In practice, the system aids a human in folding a rectangular fabric, with results detailed in the following section.
Simulation
The framework simulation and robot communication utilize RoboDK software 17 and the open-source Kukavarproxy server 18 via ethernet. Initially, the collaborative cell’s 3D model is created using CATIA software, 19 then imported into RoboDK (Fig. 6). The robot model, motion, and inverse kinematics are established using DH table conventions, with RoboDK library managing frame conversions during collaboration. A 3D hand model, updated by Kinect’s hand values, represents the human’s hand position, with color indicating hand state. The fabric’s position is represented by a 3D rectangle using its actual width and height.

3D designed workspace.
Before real-world testing, the robot’s motion was assessed in the RoboDK simulation to determine a safe folding strategy and prevent potential harm to the operator or the robot. The collaborative system was tested with a rectangular fabric, with the human leading the folding attempt and the robot model following suit, as depicted in Figure 6a–c. The simulation confirmed the system’s ability to follow the human’s lead and accomplish the task.
Results for the Experimental Case Study of Folding
The collaborative framework (Fig. 1) utilizes a KUKA LWR IV+ robot, equipped with an ATI Gamma force–torque sensor to measure fabric force and a Reflex One gripper from RightHand Robotics for fabric handling. The Kinect 2 for Windows serves as the RGB-D sensor, tracking fabric placement and operator hand pose/state via Microsoft’s algorithm and a KF. The system architecture is depicted in Figure 7 1 . Operator hand monitoring, decision making, and collaboration algorithms are coded in Python on the main laptop running Windows. Gripper functions are implemented in ROS using Python on Ubuntu, with an API interface facilitating communication with the Windows laptop. Robot communication employs RoboDK software. Force and vision control share a computer, communicating with the force controller via serial RS-232 to USB.
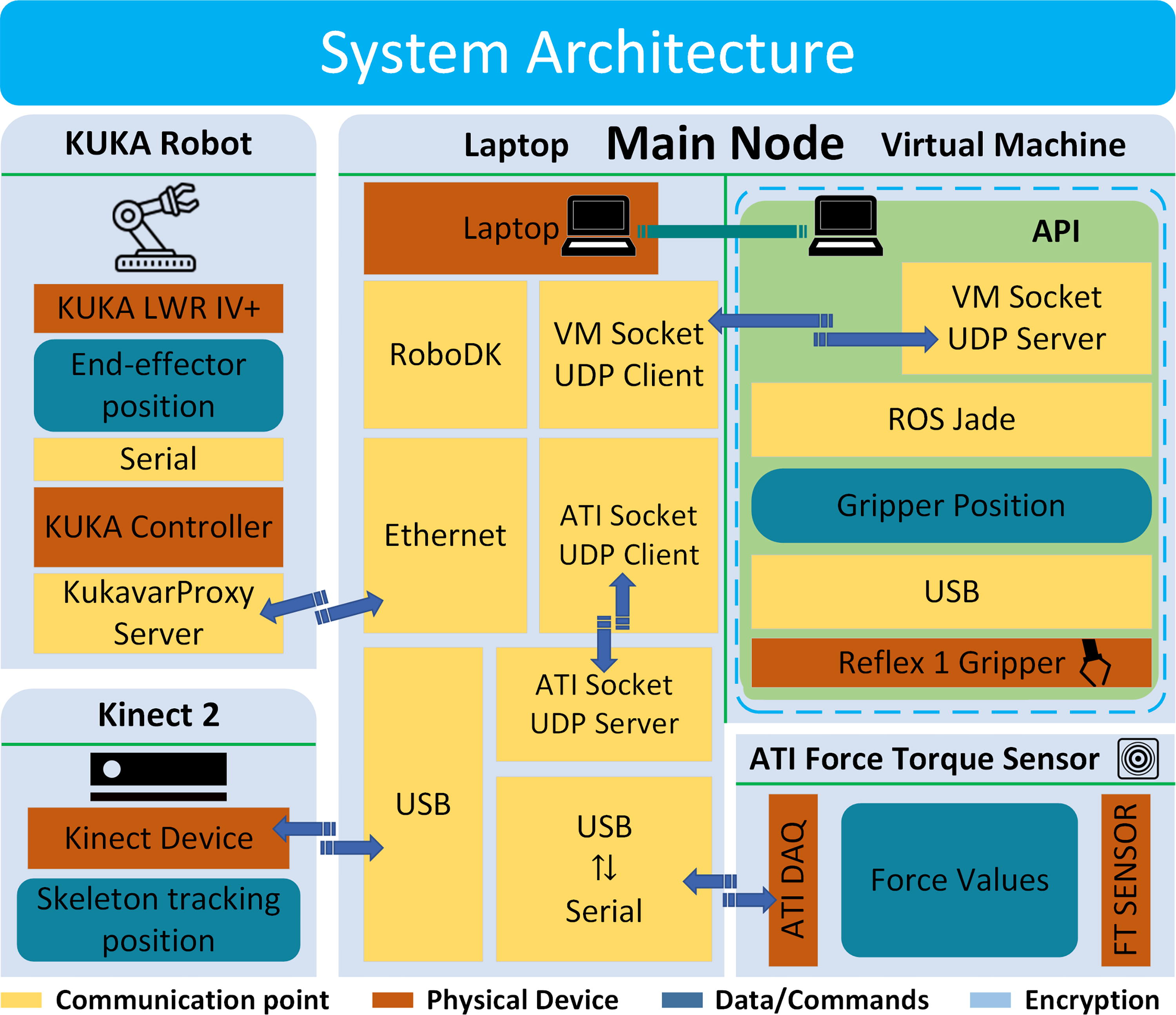
System architecture.
The system is tested by performing two sequential folds using a rectangular fabric, as shown in Figure 8. Initially, the operator places the unfolded fabric on the table, responsible for ensuring its state (unfolded/unwrinkled). Using the Kinect sensor and OpenCV library, the framework extracts the fabric’s corner positions (depicted as four red stars in Fig. 8.1a–8.2a), crucial for the decision-making model. Collaboration commences when the operator grabs a fabric corner, identified by proximity to a corner and a closed hand gesture. The decision-making model then determines the robot’s starting and ending positions, directing it to approach and grasp the fabric corner using the proposed technique. Subsequently, the system assists the operator in folding the fabric, employing vision–force control, as observed in Figure 8.1b–1f and 2b–2f).

First fold and second fold.
The operator’s hand position path, using the Kinect and Kalman estimations, as well as the robot’s end—effector path, in both folds, is presented in Figure 9.

Human and robot path during collaboration for both folds.
As expected, the human leader maintains stability in the perpendicular folding axis, exhibits high dexterity in the parallel axis, and moves upward in the Z-axis to reduce fabric wrinkles. Position error over time is depicted in Figure 10 for the first and second fold, respectively.

Position error between robot’s end effector and operator’s hand Kalman prediction for both folds.
The first fold exhibits a position error of 3.28 cm in the folding direction, while the second fold shows an error of 3.27 cm. These errors arise because the fabric is not perfectly aligned perpendicular to the Kinect plane, affecting initial human and robot positions. However, in fabric folding tasks, a 3 cm position error is generally inconsequential. While the system effectively follows the human’s path, limitations in hardware and software lead to a communication frequency of 1.125 Hz and a total execution time of 20 seconds. This imposes challenges for the operator, who must adapt to the robot’s movements rather than seamlessly guide it. Despite using modest hardware, such as a third-generation Intel Core i3 CPU with 2 cores and 8GB RAM, the system adequately assists the operator. Performance improvements are expected with higher-spec computing systems.
Conclusions
This article introduces a HRC for fabric folding. The developed framework presents a versatile, high-level architecture, demonstrated to effectively enable collaborative fabric manipulation. The KF significantly improves the accuracy of the operator’s hand position by smoothing Kinect’s values and eliminating tracking algorithm errors. The force–torque sensor efficiently corrects the robot’s trajectory when vision feedback is lacking. The robotic gripper successfully grasps fabric with minimal deformations. Despite expected errors due to equipment limitations, they are insignificant for fabric folding tasks. The system effectively guides the robot in supporting human tasks, with the advantage of mounting the RGB-D sensor on a mobile robot, expanding its application in larger workspaces. By leveraging human intelligence, the proposed method bypasses complex computational strategies, making it adaptable to various fabric shapes and applications.
The core limitation of our proposed system is the fabric’s color. The white tabletop makes white fabrics invisible to the RGB-D camera. Another critical limitation is the robotic arm angle joint limits, reducing the robotic end effector reach, supporting only small fabrics, which can be addressed, in future work, by using a robotic arm attached to a mobile robot. Other minor potentially treatable limitation includes the computational limits of our software/hardware, the vision/force sensor limitation in communication as well as the use of a single RGB-D camera for computing the fabric’s state while tracking the operator’s motion. The robotic end effector can easily block the view of the operator during the manipulation resulting in the tracking algorithm losing focus.
Future work should prioritize incorporating the pitch/yaw/roll of the operator’s hand to enhance the robot’s dexterity and accurately mirror the operator’s hand pose. Additionally, adapting the framework for use with a mobile robot would enable flexible fabric manipulation in domestic settings and larger workspaces with bigger fabrics. Integration of multiple RGB-D sensors to monitor the operator’s position and maintain clear workspace visibility during collaboration can enhance data accuracy.
Footnotes
Authors’ Contributions
Conceptualization: P.K. and E.D.; Methodology: P.K. and E.D.; Investigation: K.A.; Supervision: P.K. and E.D.; Experiments: K.A.; Validation: P.K. and E.D.; Writing—original draft: K.A.; Writing—review & editing: P.K. and K.A. All authors have read and agreed to the published version of the article.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This research received no specific grant from any funding agency, commercial, or not-for-profit sectors.