
Abstract
Abstract
This article presents an approach to microarray data analysis using discretised expression values in combination with a methodology of closed itemset mining for class labeled data (RelSets). A statistical 2 × 2 factorial design analysis was run in parallel. The approach was validated on two independent sets of two-color microarray experiments using potato plants. Our results demonstrate that the two different analytical procedures, applied on the same data, are adequate for solving two different biological questions being asked. Statistical analysis is appropriate if an overview of the consequences of treatments and their interaction terms on the studied system is needed. If, on the other hand, a list of genes whose expression (upregulation or downregulation) differentiates between classes of data is required, the use of the RelSets algorithm is preferred. The used algorithms are freely available upon request to the authors.
Introduction
Depending on the goal of the study, statistics or data mining techniques are applied. When the goal is grouping of genes with similar biological function, both statistics and data mining address two types of tasks: supervised and unsupervised learning. For unsupervised learning, with the goal of finding patterns in gene expression, clustering methods are usually used. Classical clustering methods, such as hierarchical clustering, k-means clustering, self-organizing maps (Tamayo et al., 1999) have all been used for microarray data analysis. Methods for assessment of clustering results, for example bootstraping, have also emerged (Kerr and Churchill, 2001). When the goal of the experiment is to find genes with expression levels that differ significantly between classes of samples, or to find genes that accurately predict the class of the sample, supervised learning methods, such as decision trees and discriminant analysis, can be used (Butte, 2002).
When wishing to identify genes that are differently expressed between two classes under study, microarray data can be analyzed with the proper statistical models. Linear models are often used, but mixed-effects models are also becoming increasingly popular as an analytical tool (Wernisch et al., 2003). The difference between them is that mixed models incorporate random sources of variation (e.g., different people hybridizing different arrays within the same experiment). Regardless of the statistical model or learning method used, there is a risk of overfitting the model to the experimental data. That is why model complexity should be kept as low as possible; and the real challenge is to determine the optimal degree of model complexity that a given data set can support (Allison et al., 2006).
In the data mining/machine learning community, microarray data analysis can be approached through subgroup discovery with the goal of finding a set of rules for the target class.
The RelSets algorithm (Garriga et al., 2008) applied in this study employs relevancy filtering (Lavrač et al., 1999) in data preprocessing, followed by rule construction through closed itemset mining (Carpineto and Romano, 2004) to discover all relevant rules within a minimum true positive count constraint. For a better understanding of the paper, certain terms are introduced in Table 1.
The input to RelSets is a dataset with class labeled examples and one parameter: the minimum true positive count (min
These rules have high true positives count because they were built with a min
The RelSets algorithm is complete in the sense that it finds all the most specific rules satisfying the minimum true positive count constraint. The algorithm is also nonredundant because in finds only the relevant rules. This makes the algorithm very appropriate for microarray data analysis because a small number of examples are available and the complete search of the space is very adequate. Also, as the results are to be interpreted by experts, redundancy is undesired as it would lead to more complex results hindering rule interpretability.
In this article we present a novel approach to microarray data analysis using discretised expression values in combination with the methodology of closed itemset mining for class labeled data (RelSets). The relevance of this analytical approach is evaluated through its comparison with statistical 2 × 2 factorial design analysis. Validation of the approach is done using the permuted microarray dataset.
A scientific question in this study is the effect of a specific kind of treatment on the target organism. In our study the target organisms are potato plants, infected with potato virus PVY, which is one of the agronomically most important potato pathogens. Sometimes the question in mind is finding genes that were differentially expressed after the treatment, thus giving the possibility of better insight into target organism response. We tried to find solutions to the task of finding specific genes of interest: (1) genes that are significantly differentially expressed after a given time of infection, and (2) genes that determine a class of plants resistant or sensitive to the viral infection.
Materials and Methods
Experimental design and preprocessing
Two experimental data sets were used in the experimental setup. In the first, four transgenic potato lines (two of them resistant and two of them sensitive to a viral infection) were tested. Plants from each transgenic line were divided in four subsamples: one half was infected with potato virus
Every experiment was performed with at least three biological replicates, thus yielding 24 microarrays for the first experiment and 13 microarrays for the second. Each microarray was hybridized with a subsample inoculated with virus and a mock infected subsample from the same resistance type. Figure 1 illustrates the two experiments.
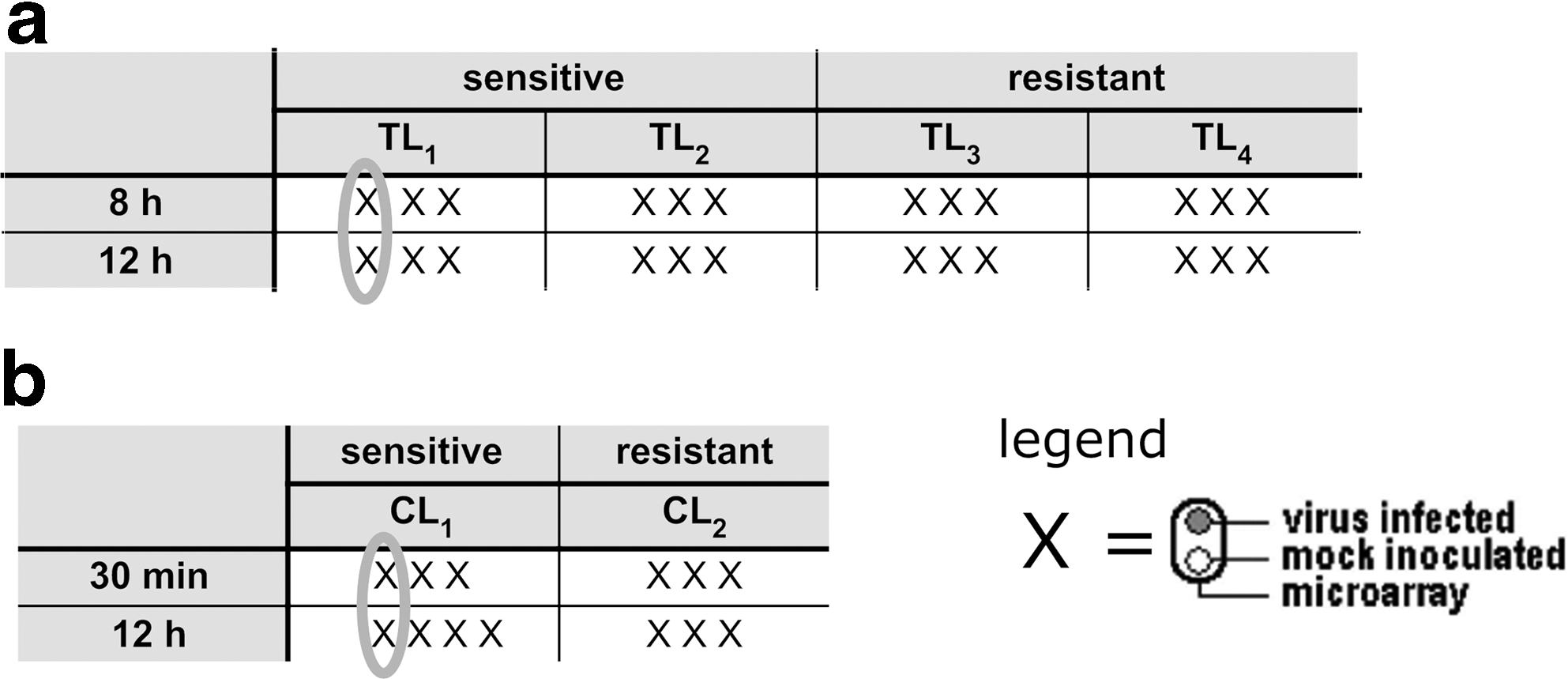
Schematic representation of the (
Potato 10k cDNA microarrays (http://www.jcvi.org/potato/sol_ma_microarrays.shtml) were used, in which, excluding controls, 15,600 clones are spotted in duplicate. The initial data dimensions were therefore 31,200 × 24 for the first experiment and 31,200 × 13 for the second (also see Fig. 1). Quality control was performed using the image analysis software ArrayPro Analyzer®. Spots that were unevenly shaped and had a low signal-to-noise ratio and low intensity signal on both channels (red and green), were not included in further analysis. Background correction
Data discretization and application of RelSets Algorithm for microarray data analysis
We first define the term example (see Table 1). The first dataset is composed of 12 examples and the second of 6 examples.
First, filtering was done (see Table 2). The genes that had weight = 0 were marked as missing (NA). Next, if, for at least one of the possible factorial levels, that is, experimental conditions [e.g., sensitive (sen) Time 1 or resistant (res) Time 2] there were NA values for the replicates, then the gene was filtered out. After filtering, data dimensions were reduced to 10,397 × 24 for the first experiment and to 11,464 × 13 for the second experiment. Feature relevancy (e.g., if the same pattern of P or A values was obtained in sensitive and resistant examples, see also Table 1) was checked. There were no irrelevant rules in the first experiment and three genes were irrelevant and removed in the second one.
To pass through the filter, at least one of the given sensitivity–time combinations needed to have a full set of data, that is, no missing data. For example, for gene STMHJ51 one of the three replicates for sen Time 1 combination was missing. In the other three sensitivity–time experimental combinations there was no combination where all of the replicates were nonmissing; therefore, this particular gene was filtered out. On the other hand, for gene STMET79 had one experimental combination (res Time1) where all three replicates were nonmissing values, and therefore this gene was accepted for further data analysis, even though when observing the other three experimental conditions, this gene would have been filtered out.
The task of closed itemset mining task for class labeled data was to find differences in gene expression levels characteristic for virus sensitive potato plants, discriminating them from virus resistant potato plants and vice versa. The thresholds for data discretization were defined by using expert background knowledge on relevant expression values. Two threshold values were chosen for each of the two experiments. Expression levels above the selected threshold value were marked with P (present/upregulated), those below the negative threshold value were marked with A (absent/downregulated), whereas expression levels in the interval [ − threshold, + threshold] were marked with M (marginal) and excluded from further analysis. Three groups of conditions within an example were generated:
gene expression levels Time 1 hours after infection gene expression levels Time 2 hours after infection the difference between gene expression levels at Time 2 and Time 1 after infection
We ran our RelSets algorithm twice: once the sensitive examples were considered positive and once the resistant ones were considered positive. In both cases the constraint of minimal true positive count was set to the number of replicates for the experiment; that is, for Experiment 1 the constraint was set to 6 and for Experiment 2 it was set to 3 or 4, depending on the number of replicates. The second part of the algorithm, which involves rule relevancy filtering, filtered the rules to just one relevant rule with true positive rate 100% and false positive rate of 0%.
The algorithm was validated by permuting the rows and columns on the original data set; that is, gene names and experimental time points were randomized. RelSets algorithm was then applied as described above.
Statistical analysis of microarray data
A 2 × 2 factorial design analysis was applied, with the factors being (1) type of plant's resistance and (2) time (see Fig. 1). Statistical analysis was used to identify lists of differentially expressed genes for the interaction term between the two factors where the biological question asked was to identify the genes whose expression changed significantly with time and between resistance types.
All calculations were done using limma software package for R (Smyth, 2005). The data was normalized twice, thus yielding two normalized datasets that were analyzed separately.
where the expression,
The interaction term (time × sensitivity type) was investigated. Genes were ranked according to their
Biological interpretation
Genes found to be differentially expressed by statistical analysis and by rules constructed by the data mining algorithm were checked for their biological significance. MapMan annotation (Rotter et al., 2007), where all clone names are organized into 35 BINs that represent major metabolic categories, served as a functional annotation tool. For simpler analysis of results BINs were combined into few larger functional categories: housekeeping, signalling, transcription factors, defence, unknown function and combinations of these. They provide a useful insight into the plant's reaction to pathogen attack.
Results
Closed itemset mining for labeled data
The setup for the microarray experiments used in this study is presented in Figure 1. Microarray datasets were first preprocessed by appropriate filtering due to missing values. The filtering procedure of selected genes is presented in Table 2. Further on expression values were discretisized. Two threshold values were chosen in discretization for each of the two experiments to check the influence of this factor on analysis results.
We ran the RelSets algorithm twice for each dataset: once the sensitive class of examples was considered positive and once the resistant class was considered positive. The output of the RelSets algorithm are rules in the form:
This output is read as: “IF gene

A rule induced in Experiment 1 for class resistant, using the ± 0.3 threshold, consisting of 13 conditions.
The results are presented in Table 3 where the number of conditions in rules (i.e., genes with changed expression values) that determine the resistance class is shown as a function of the selected threshold value. Expression values of obtained rule conditions determining the resistance classes are shown in Figure 3.
Heatmap representing genes whose expression values at a given time point determined the potato class (
Number of rules determining class (resistant, sensitive) for the selected offset values.
To assess the method, a statistical evaluation in the form of randomization of the data was performed. The results achieved by the RelSets algorithm were validated on the same data by permuting gene names and experimental time points used in the experiment. The number of rules obtained with permuted data is presented in Table 3. Only the results determining class
Statistical analysis
The intersection of two differentially expressed gene lists derived from applying two different normalization methods on the same data was taken as a means of selecting significantly differentially expressed genes, regardless of the preprocessing method used (Rotter et al., 2008). Two hundred genes in the first experiment and 315 genes in the second were identified as differentially expressed (
The first 20 differentially expressed genes, ranked by their
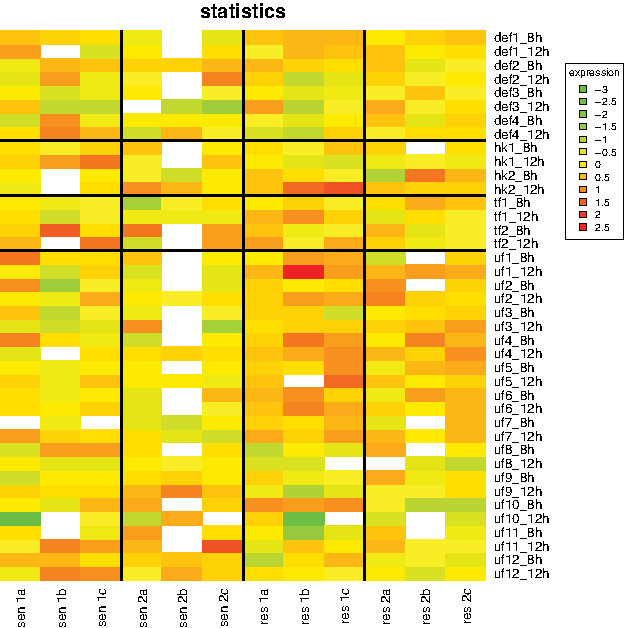
Heatmap for the top 20 differentially expressed genes for the first experiment, ranked by their respective
Biological evaluation of obtained results
Genes that appeared in the rules and/or in the list of differentially expresed genes were assigned into functional categories using the MapMan annotation tool (Fig. 5):
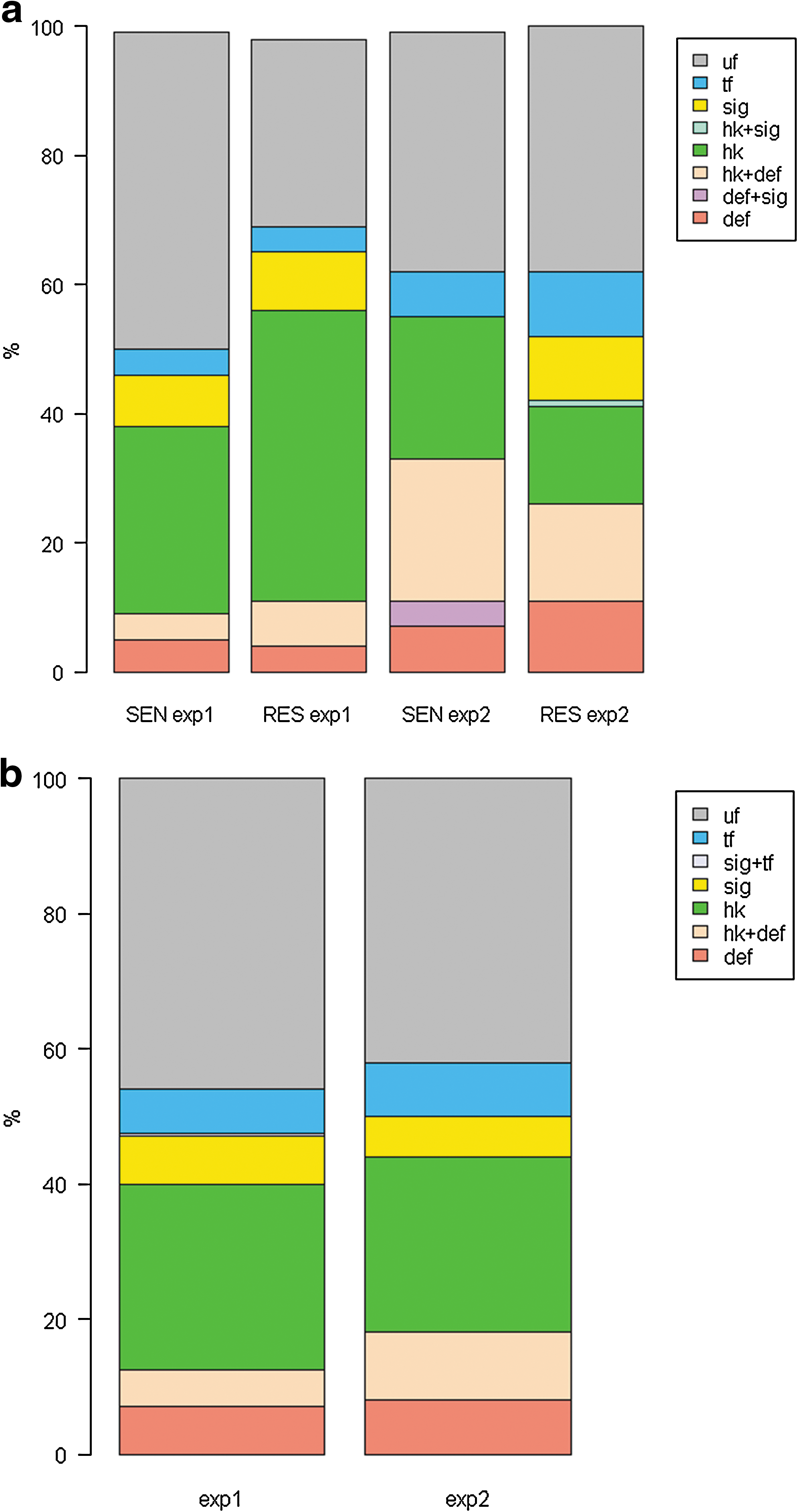
Barplot comparing functional categories (
The genes belonging to a given functional category or their combinations, if present, were compared between classes and data analysis approaches in both experiments. We can see that the groups of genes, important for class discovery (sensitive and resistant), as well as genes whose expression changed significantly in time and between resistant types, were found as expected when analyzing plant–pathogen interactions. These are genes involved in signaling, regulation of transcription and genes with already denoted function in plant defense. Interestingly, many genes traditionally annotated as housekeeping were also present in the list of responsive genes. There was also a high percentage of genes with unknown function in all conditions analyzed. This is to be expected, because a large proportion of genes still need to have their function determined.
We have additionally applied functional classification for evaluation of rule discovery in permuted versus original datasets. The result for rules, determining resistance in the second experiment is shown in Figure 6.
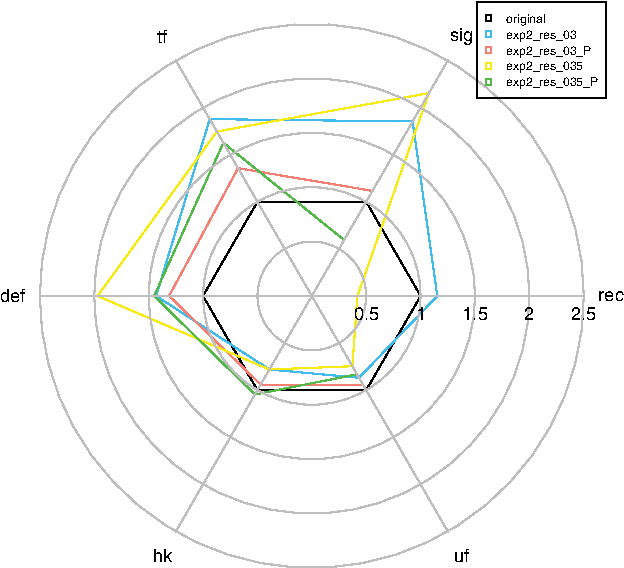
Radial plot representing validation of the RelSets algorithm by permutation. Rules determining resistance in the second experiment are shown. Offset values are marked in the figure legend (0.3 and 0.35) and permuted datasets are marked with P in the figure legend. The complete dataset (i.e., all the clones on potato microarray) was also divided to six categories (
Discussion
The usability of the new data mining approach was demonstrated on two experimental datasets. The tool was shown to be useful in combination with statistical analysis to add another perspective into the biological interpretation of microarray data. Using data mining enables conjunctions of conditions to be found (i.e., underexpression or overexpression of a gene after at a given time point) that are characteristic for a given class (in our case, resistant and sensitive potato plants). Several conditions that determine the class were constructed by the data mining algorithm (see Table 3). If the purpose was to select a few target genes that differ in their expression after a given time, to separate the target classes (in our case sensitive and resistant potato plants) or even define target genes for diagnostics, then a higher threshold is advised (in our case, 0.3 for the first experiment and 0.35 for the second one). This would result in a smaller number of conditions, which is more convenient, from the practical point of view of diagnostics. Data mining applications for diagnostics have been described before (Kovalerchuk et al., 2000). If the purpose of the analysis were, say, of a descriptive nature, that is, determining genes and their expression that sufficiently differentiates between two classes, then a lower threshold (0.2) should have been chosen to be able to put the conditions in a broader biological context. The threshold is preferably chosen in such a way that a reasonable number of conditions are generated, thus avoiding the issue of interpretation complexity. On the other hand, a high threshold would also pose the danger of lower reliability and robustness of the results. The choice of a threshold value is also important when accounting for the variability of the data. A higher threshold leaves less room for variable data. The only variability that is not allowed is the alternation of the signs of the M values (positive/negative M values).
Because we wanted to use the data mining (RelSets) results in a descriptive manner, a lower threshold yielding more conditions in rules (i.e., genes whose expression over time determines class sensitive or resistant) was chosen (see Table 3) to complement the results obtained using the statistical approach.
It is again important to emphasize that the data mining algorithm does not take into account the variability of data but the consistency of the result, even when variable data are represented; all replicates needed to be of the same value after discretization (P or A), because the false positive rate was set to be zero. From a biologist's perspective this is an advantage, because biological data is highly variable and sometimes information is lost due to high coefficient of variation between replicates. When discretizing data, its variability is not considered, rather the consistency of the results (i.e., comparison of the same discretized values for a particular example).
The number of biological replicates per experiment was three to four (see Fig. 1), which is the case with many microarray experiments. That is why true positive rate was set to 100%. In the cases where more replicates would have been made per experimental condition, the same true positive rate would have been chosen for, for example, highly accurate determination of genes with putative diagnostic meaning (determining a specific class). For descriptive purposes, in the case of many biological replicates, a lower true positive rate could also have been chosen.
We have also inspected the results to find genes that were part of data mining (RelSets) rules for determining both classes. In other words, we have checked if a gene was found to be important for class differentiation in both sensitive and resistant plants. Finding genes that were important for determining both classes is of great interest, because those might be the genes most connected with the biological question under study. For the first experiment, using a lower threshold of 0.2, one such gene, STMER65, involved in callcium signalling (
RelSets algorithm was validated by permuting clones and experimental time points. We expected that the permuted results would have resembled the original dataset (i.e., the percentage of clones of a certain category would be similar to 1, see also Fig. 6). In fact, for permuted dataset with different offset values (red and green plots on Fig. 6), the shape of the plot was similar to the complete experimental dataset (in black), except for the
When performing microarray experiments, several biological questions are asked. Sometimes the question can be to find differences between two classes of organisms tested. That can be normal versus infected tissue, wild-type versus mutant organisms, etc. Looking at the genes whose expression differes significantly between the two tested classes gives a global overview of the differences between the groups. When another factor is added to the experimental design, more complex biological questions can be answered. In our case, where two factors were tested (time and virus sensitivity), statistical analysis for the interaction term pointed to the genes that exhibited a significant change in time and between sensitivity types. We additionally tried to establish conditions that differentiate between virus sensitive and virus resistant plants. This answers a different biological question from the one addressed by statistical analysis. Here, the biological question is to find the genes and their expression in time (upregulated or downregulated) that determine the sensitivity or resistance in plants.
In conclusion, data mining and statistics, as applied in our experiments (i.e., RelSets algorithm and 2 × 2 experimental design, respectively), differ at one point when analyzing microarray data: the biological question asked. Statistics is to be preferred when it is important to know the genes that are differentially expressed under a given treatment, to focus on a more or less complex biological interpretation. However, when the goal is to determine the genes (and their expression) responsible for defining the class variable (in our case, resistant and sensitive potato cultivars), data mining with discretized values using the RelSets algorithm is appropriate. When dealing with the task of finding specific genes of interest, both types of analysis are very useful for (1) describing a biological system and its differences under different conditions, (2) helping to determine target genes for further analysis (real-time PCR or enzyme activity), (3) leading to formation of new biological hypotheses that would have to be confirmed in separate, independent experiments, and (4) possible future diagnostics of unknown samples. The appropriate experimental design and analysis will depend on the biological question being asked.
Footnotes
Acknowledgments
The authors would like to acknowledge Dr. Roger Pain for carefully revising the manuscript, which helped make it more concise and clear and to Henrik Krnec from Anoda d.o.o. for help with the preprocessing. We are grateful to Gemma C. Garriga from Helsinki University of Technology, the main author of the RelSets algorithm, for joint work in the development of this algorithm. This work was partially funded by the Slovenian Research Agency grants No. 1000-05-310172, Z4-9697, P4-0165 and P2-0103, Ministry of Higher Education, Science and Technology grant No. 4302-38/2006/4, 6FP EU Network of Excellence Pascal and the 6FP EU project Inductive Queries for Mining Patterns and Models IQ.
Author Disclosure Statement
The authors declare the no conflicting financial interests exist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.