
Abstract
Introduction:
Minimally invasive surgery (MIS) suturing demands advanced surgical skills. Therefore, it is important these skills are adequately trained and assessed. Assessment and feedback can consist of judgments and scores of expert observers or objective parameters using instrument tracking. The aim of this study was to determine to what extent objective parameters correspond to expert assessment.
Methods:
Participants performed an intracorporeal suturing task on the EoSim simulator repeatedly (maximum 20 repetitions) during training. The best discriminating parameters, which previously shown construct validation, were combined into a composite score, using regression analysis. All videos were blinded and assessed by 2 independent reviewers using the validated laparoscopic suturing competency assessment tool (LS-CAT). These scores were compared with the composite score.
Results:
A 100 videos of 16 trainees, during separate points on their learning curve, and 8 experts were used. The parameters “time” and “distance” were statistically significantly correlated with all LS-CAT domains. The composite score (calculated from “time” and “distance”) showed improvement between the first and the last knot (57% versus 94%, P < .001). Also the LS-CAT score improved (28 versus 17, P < .001). However, the correlation of the composite score with the LS-CAT score was weak (R: 0.351), with an accuracy of 55/100 when pooling the outcomes based on inadequate, adequate, or good performance.
Conclusion:
Instrument tracking parameters (using Surgtrac) could give an indication of the skill level, however, it missed important elements, essential for reliable assessment. Therefore, expert assessment remains superior to determine the skill level in MIS suturing skills.
Introduction
It has already been demonstrated that training of minimally invasive surgical (MIS) skills outside the clinical setting improves the MIS skills and shortens the learning curve in real-life procedures.1–4 In addition, owing to the COVID-19 crisis, fewer (elective) surgeries are being performed and most hands-on seminars have been cancelled, limiting trainees' possibilities for surgical skill development.5–8 The opportunity for course-based training or direct supervision during training is, therefore, currently reduced.
Together with less elective surgery being performed, this might cause a setback of the surgical trainee's learning curve that, in the end, may contribute to the risk of learning curve-associated morbidity. 9 The reduction of exposure to surgical skills is especially true for residents and junior surgeons. Therefore, there is a need for more training possibilities in smaller settings or even training at home, which requires low budget MIS trainers. However, for an adequate training experience and targeted improvement, it is important to have guidance and objective assessment during the training sessions. MIS suturing can be trained in a laboratory or in a home-based setting, to maintain surgical skills and quality of care.
Surgical training with virtual reality (VR) and augmented reality (AR) techniques has both been shown to improve technical skills.10–14 For MIS suturing, a box trainer or AR trainer remains favorable. 15 Particularly in the more complex MIS skills, such as suturing, training in VR simulators is difficult due to the lack of realistic haptic feedback.16–19 Therefore, box trainers are mainly used for this purpose, however having the need for expert observers. Expert observers are time consuming, expensive, and very difficult, if not impossible, to use in a home-based setting.
To have the users verify whether they are objectively improving their skills and aid in the training process, it is possible to use instrument tracking. This motion analysis of the instruments might be a valuable component to provide that feedback. It can be used in addition to traditional box trainers, for example, SurgTrac ©, which is also used in the EoSim AR MIS simulator.20–23
Although the user is provided with objective metric outcomes after each performed task, these are still just separate metrics consisting of “distance traveled by the instruments” and “time to complete the task.” These metrics do not provide a total score with a benchmark to aim for during training. It is also unclear whether and in what way the metric outcomes correlate with the feedback of expert observers. It would be highly beneficial if the metrics of a simulator could provide a comparable score with an expert observer.
Therefore, this study focuses on the use of a composite score, based on instrument tracking parameters, to predict the outcome of an expert assessment of MIS suturing during a learning curve in a box-trainer setting.
Methods
Participants
Participants for this study were recruited voluntary at Radboudumc, Nijmegen, the Netherlands, from February to June 2017. 22 The novices did not have clinical surgical experience, but they had knowledge of the minimally invasive surgery (MIS) concept. Participants were only eligible if they had participated in a surgical internship as part of the medical study. In addition, expert MIS surgeons were recruited (>50 MIS procedures performed) to serve as a benchmark comparison. All data were processed anonymously and a written informed consent, regarding approval to the study and the recording of the simulator metrics and video, was registered. Owing to the nonmedical intervention setup, no medical ethical approval was required.
Simulator
The EoSim AR MIS simulator (Eosurgical ltd., Edinburgh, Scotland, United Kingdom), used for this study, consists of a box with a connected laptop as monitor, running the SurgTrac software. 21 A laptop standard was used to have an adjustable ergonomic working position (Fig. 1). With the SurgTrac software, the instruments were tracked by using colored markings on the instrument tips. The software used this information to create parameters.22–24 The standard intracorporeal suturing task of the simulator was used in this study. Two 5 mm needle holders were used in all training sessions. The left instrument tip was colored with a blue tag and the right tip with a red tag (Fig. 1). Each participant received a similar sized (3-0) braided 10 cm long suture for the suturing procedure.

EoSim-MIS simulator with colored markings on the instrument tips needle-drivers. MIS, minimally invasive surgery.
The simulator's outcome parameters were time (seconds), distance (meters), off-screen time (percentages), speed (meters/second), acceleration (meters/second 2 ), smoothness (meters/second 3 ), and working area (average distance between instruments in centimeters).
Only the parameters “time” and “distance” have proven construct validity in recent studies on the SurgTrac software22,23 and are, therefore, included in this study. Because there was conflicting evidence about the parameters “speed” and “smoothness,” these were included in the results as well to create more clarity about their validity.22,23,25,26
Laparoscopic suturing competency assessment tool form
The Laparoscopic Suturing Competency Assessment Tool (LS-CAT) was developed and validated previously to assess the performance of laparoscopic suturing (objectively) by expert observers (Fig. 2). 27 Each step of performing a MIS suture was defined as a component task and evaluated separately: needle pick-up, needle insertion and passage, first double throw and knot tying. These four-component tasks were scored for the instrument handling, tissue handling, and component-specific errors. These scores range from 1 to 4, with 1 being the best and 4 being the worst result. All errors were counted as extra points for each mistake made in the relevant section. Therefore, a low LS-CAT score corresponds with a good performance and a high score with a poor performance.
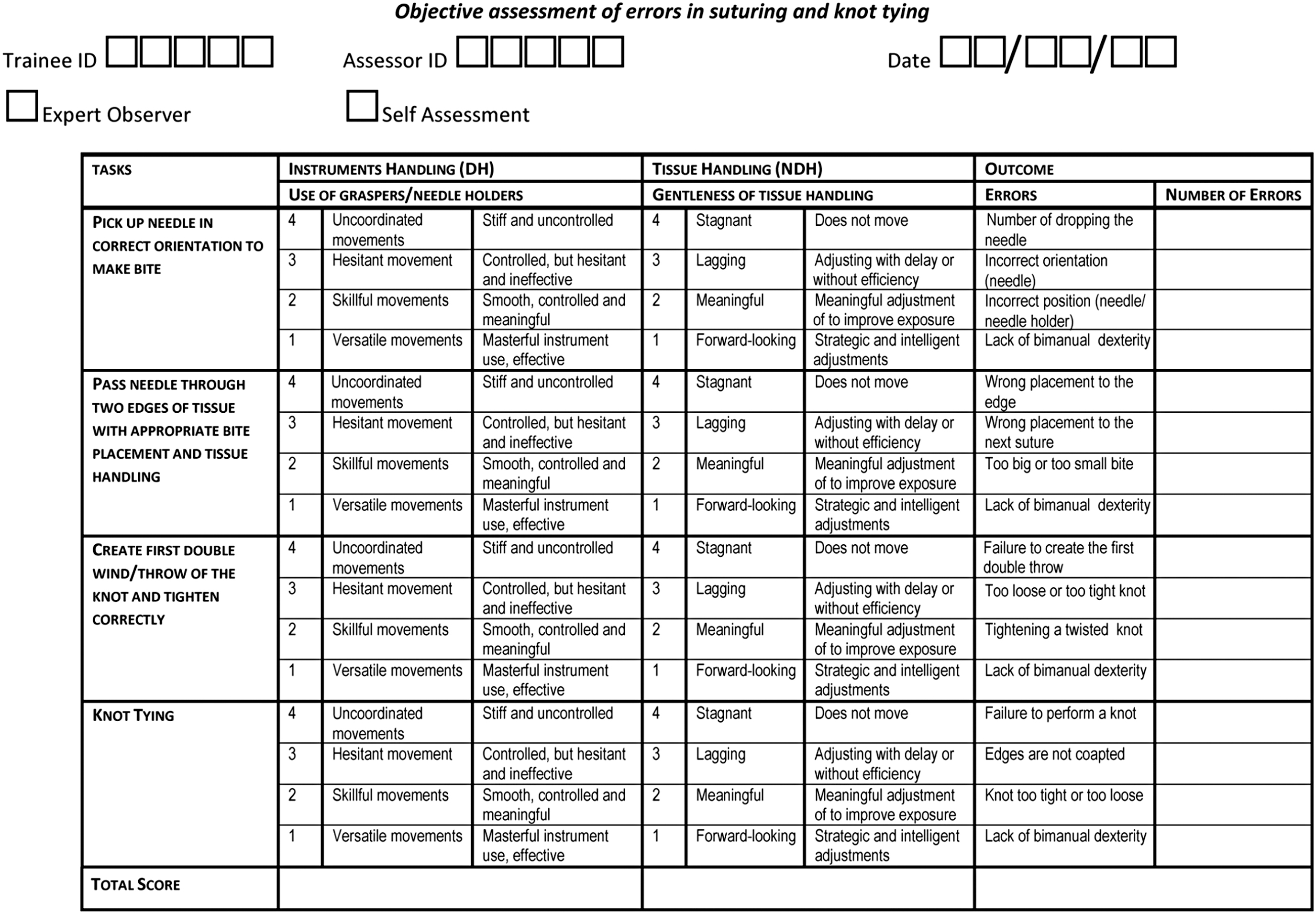
Laparoscopic Suturing Competency Assessment Tool (LS-CAT). 27
To evaluate the LS-CAT scores, three groups were made: inadequate performance, >28; adequate performance, 17–28; and good performance, <17. These groups are made by the experts, based on their opinion of what adequate performance should consist of.
Composite score
To evaluate whether it was possible to create a reliable, meaningful, and objective assessment score of MIS suturing based on instrument tracking alone, a composite score was calculated. The outcome parameters that showed construct validity (time and distance) in previous validation studies and showed a moderate correlation were used for a regression model.22,23 Because of the large range in outcome of the parameters, the biggest outliers have been removed and have been reduced to the 95% confidence interval. These values were based on the outcomes of previous studies.22,23 Time >1000 seconds resulted in a score of 0. Time <100 seconds resulted in a score of 50.
Distance >30 m resulted in a score of 0. Distance <2 m resulted in a score of 50. Therefore, there was more variation in the “normal ranged scored” parameters, based on data from previous studies.22,23 The composite score was calculated after normalization of the parameters showing construct. Furthermore, these were combined to one score that ranges from 0 to 100, with 100 being the best score. To give an indication of the performance, the composite score and the LS-CAT were rated with an “inadequate” (<50%), “adequate” (50%–75%), and a “good” (>75%) score.
Protocol
After recruitment, the participants completed a questionnaire regarding demographics and surgical experience. To get acquainted with the simulator, three basic tasks were performed before commencing the suturing learning curve. The suturing task was performed up to 20 times or less if the same level was achieved 3 consecutive times regarding simulator parameters. 22
Of these learning curve repetitions, the 1st, 5th, 10th, 15th and last knot were aimed to be used for this study. Owing to technical failure, this was not always possible. Therefore, five groups were created, the start, 3–7, 8–14, 15–18, and end group. In addition, 8 experts performed the same task, after acquaintance with the basic tasks, for an expert benchmark. All videos were anonymized. Afterward, 2 blinded MIS experts independently assessed the recorded videos using the LS-CAT form (Fig. 2), in a randomized order. Based on the power calculation, 90 videos had to be assessed to create a valid composite score.
Statistics
Statistical analysis was performed with the Statistical Package for Social Sciences (SPSS, IBM corp.) version 25. The two separate LS-CAT scores of the 2 independent experts were calculated into one mean outcome per participant. To measure the inter-rater reliability, the extent to which 2 or more observers agree, the intraclass correlation was determined. 28 A Pearson correlation was used to evaluate the correlation between the LS-CAT and the SurgTrac parameters. The strength of the correlations was considered very strong for an r > 0.80, strong for an r of 0.60–0.79, moderate for an r of 0.40–0.59, weak for an r of 0.20–0.39, and none for an of r < 0.20.
The SurgTrac parameters that showed at least a moderate correlation with the LS-CAT outcomes were included for a multiple linear regression model to predict the LS-CAT outcomes. The model was calculated using the backward method that calculated multiple models by including all parameters and accordingly excluded parameters that had the least contribution to the prediction model. The most optimal model was presented with the highest accountability of the variance in data (R2). Additional to the concurrent validity (correlation between the composite score and LS-CAT score), the construct validity was evaluated by comparing the videos of the start with those of the end, using a Wilcoxon signed rank test. The performance of the novices at the start of the training was also compared with that of the experts, using an independent t-test.
Results
A total of 24 participants were included, of which 16 were novices during their learning curve training and 8 were experts. The novice group had a mean age of 23 years and consisted of 11 female participants. The expert group had a mean age of 44 years and were mainly male (n = 6/8). In total, 92 suture tasks performed by the novice group and 8 suture tasks performed by the experienced surgeons were used in this study. All videos were assessed using the LS-CAT form by the 2 independent observers, with a high degree of interobserver reliability (0.81).
Metric parameters versus LS-CAT
The correlations between the relevant SurgTrac outcome parameters and the LS-CAT scores are given in Table 1. The parameters “time” and “distance” have a statistically significant correlation with all LS-CAT domains, however, only moderately. The strongest correlation was between time and instrument handling (r = 0.600), although the correlation between time and the total LS-CAT score was almost as good (r = 0.592). When evaluating the individual steps of the procedure as stated in the LS-CAT form, the only relevant correlation was seen in “picking up the needle,” with a moderate correlation with both time (r = 0.581) and distance (r = 0.522). Speed and acceleration did not show any relevant correlations with the LS-CAT outcomes.
Correlation Between the Separate SurgTrac Parameters and the Laparoscopic Suturing Competency Assessment Tool Scores
Data in this table represent the Pearson correlation coefficient.
Indicates a significant P-value of <.001.
LS-CAT, laparoscopic suturing competency assessment tool.
Composite score
A multiple linear regression analysis was performed with the parameters “time” and “distance,” as indicated in Table 2, to examine the capacity of the SurgTrac parameters to predict the LS-CAT outcomes. These were the only two demonstrating significant correlation with the LS-CAT. The parameters “speed” and “acceleration” did not show a moderate correlation with the LS-CAT and were, therefore, excluded from this linear regression analysis. The scores of the time and distance were added together to formulate the composite score:
Composite Score Regression Model
Data represented in this table are the regression model with the optimal fit for the composite score.
R2, explained variance; SE, standard error.
The formula of the composite score:
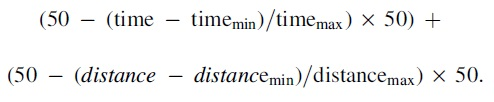
Multiple linear regression analysis resulted in the parameters time and distance to predict the total LS-CAT score with an R2 of 0.351 accounting for 35.1% of the data variance.
The correlation between the composite score and the LS-CAT is shown in Figure 3, in which a higher composite score should correspond with a better performance and a lower LS-CAT score indicates the better performance. However, Table 3 shows that the composite score could only give a correct indication of the user's skill level 55 out of the 100 times. In one case, the composite score estimated “good,” but the LS-CAT score was rated “inadequate.” The ratio inadequate/adequate/good between the assessment methods is similar, indicating a similar assessment method regarding difficulty.
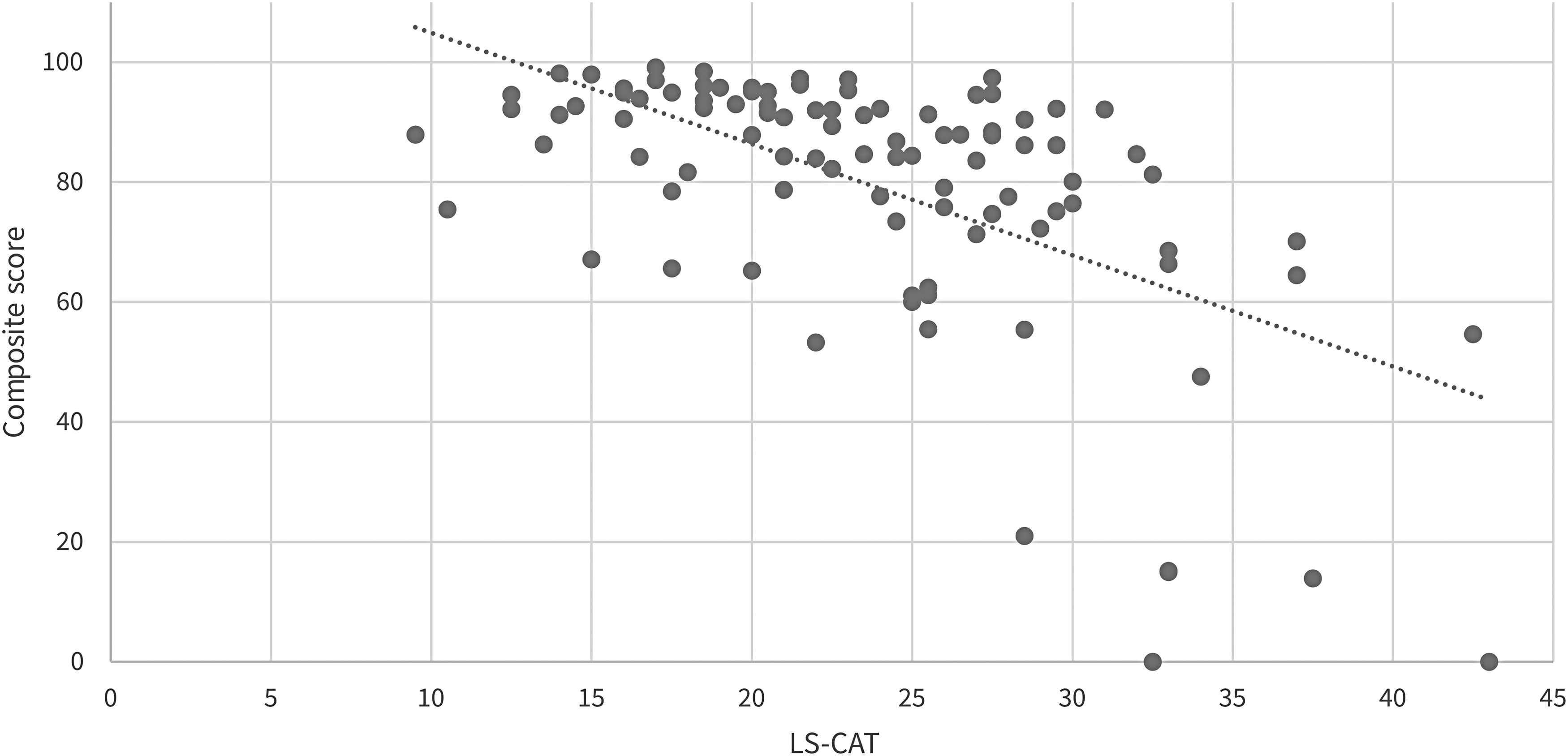
Scatterplot of the correlation between the composite score and the Laparoscopic Suturing Competency Assessment Tool (LS-CAT).
Correspondence of the Composite Score and Laparoscopic Suturing Competency Assessment Tool Score, Based on Group Scoring
All values are stated in numbers.
LS-CAT, laparoscopic suturing competency assessment tool.
Score differences between expertise level
The scores of the groups during the training and those of the experts are shown in Figures 4 and 5. Both assessment methods show an increase in score during the learning curve. To compare the novices at the start of the training with those at the end of the training, Table 4 gives an overview of the scores. Both the composite score (57–94) and LS-CAT score (28–17) improved significantly between the start and the end of the learning curve. These improvements were also significant in the separate parameters and components of the LS-CAT.
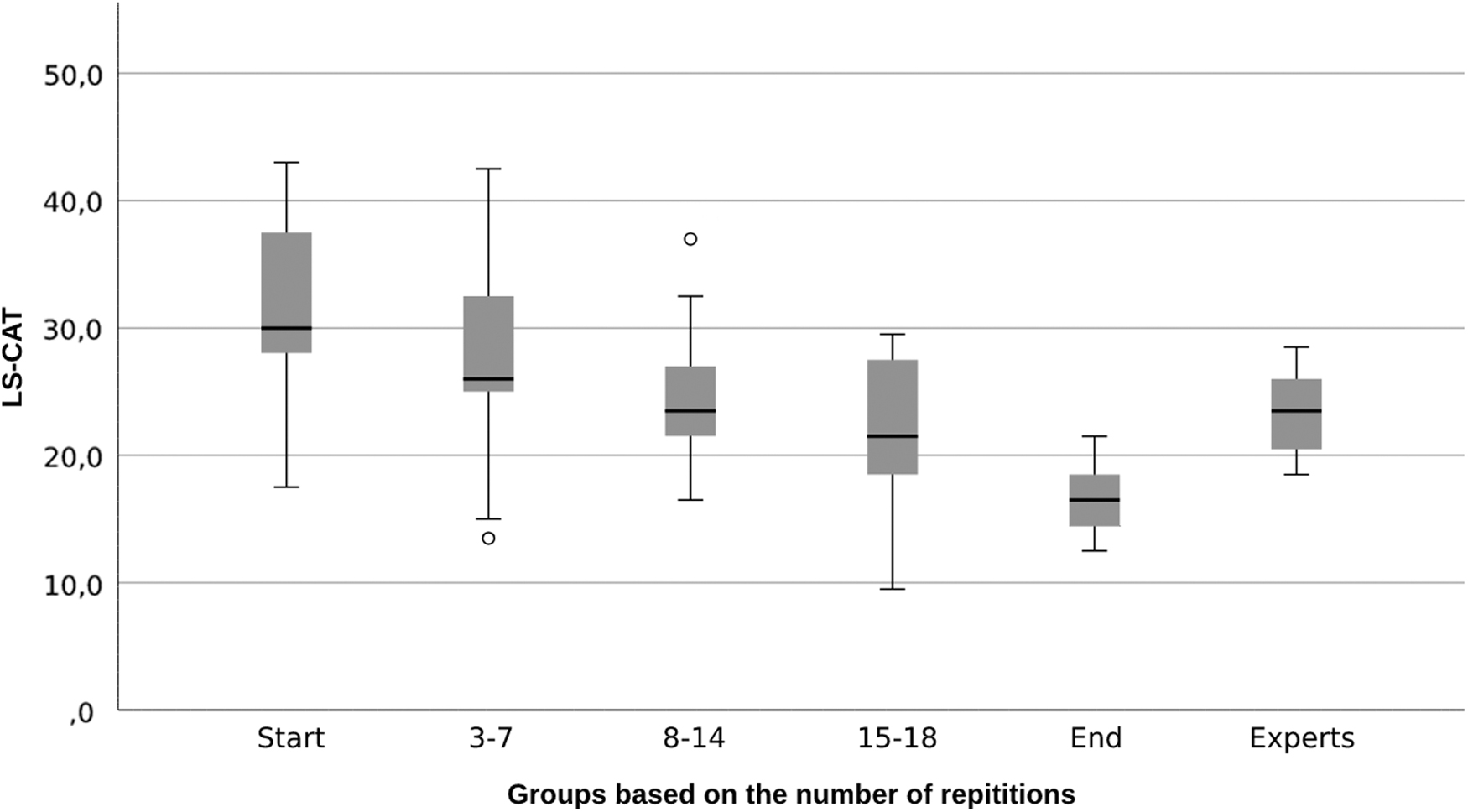
Boxplots during training regarding the Laparoscopic Suturing Competency Assessment Tool (LS-CAT).
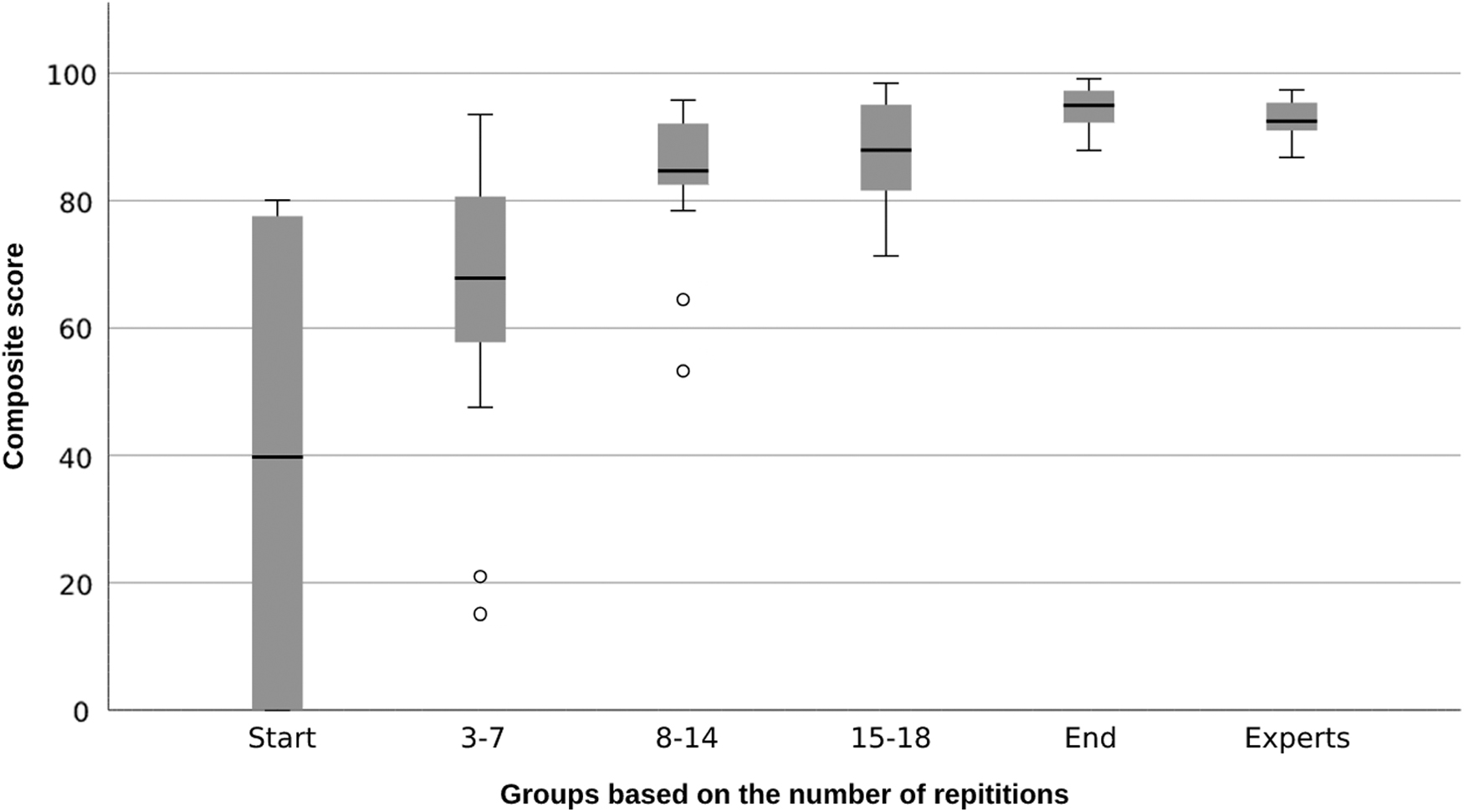
Boxplots during training regarding the composite score.
Significant Differences Were Calculated Using a Wilcoxon-Signed Ranked Test, Because the First and Last Knot of the Learning Curves Used Are from the Same Participants
All values are stated in median (interquartile range). A P value <.05 (displayed in italic) were considered significant.
Counterintuitively, the experts did not significantly score better than the start of the training group regarding the LS-CAT (23 versus 27 P = .095) (Fig. 4). However, looking at the composite score, the experts scored significantly better than the beginner group (93 versus 51, P < .001) (Fig. 5).
Discussion
Previous studies have shown that the EoSim simulator is able to determine differences in expertise with the parameters “time” and “distance.”22,23 The construct validity of these parameters has been proven again in this study. The parameters failed to show a strong correlation with expert assessment using the LS-CAT. The composite score, using these parameters, showed construct validity, but was not able to give a reliable indication of the skills level, when compared with the expert assessment. Therefore, neither the composite score nor the separate SurgTrac parameters could show concurrent validity in this study.
Earlier studies22,23 suggest that the parameters “time” and “distance” could be used to evaluate surgical skills to show large differences in skill level (novice versus expert) as shown in this study. For more precise assessment, as needed during home-based training or assessing whether or not a trainee is ready for the clinical setting, expert assessment remains superior.
Other tracking parameters have been evaluated on their validity and assessment properties. Mansoor et al. already raised concerns about the usability of “speed” and “smoothness” as reliable simulator parameters and it is still not clear whether these are able to show construct validity.23–26 It is also important to keep in mind that “speed (m/s),” “acceleration (m/s 2 ),” and “smoothness (m/s 3 )” are calculated from the parameters “time (s)” and “distance (m).” In our study, no construct, nor concurrent validity, was shown for these parameters and we suggest that these will not be used for assessment purposes.
The composite score was unable to reliably estimate the LS-CAT score. Thirteen participants would have wrongly received a negative result from the simulator, using the composite score unjustifiably causes insecurity and reduced motivation. In contrast, 10 participants would be wrongly classified as good enough, making them eligible for the next step and maybe endangering patient safety. Despite the fact that the two assessment methods both measure the same thing and improve during training, there is still too much discrepancy between the composite score and expert assessment.
Apparently, there is something that the composite score does not or cannot measure, which does contribute heavily to the expert's assessment. Possibly the distance and time parameters can be trained quite isolated and show progression just by doing with little or without expert feedback. This could mean that speed and efficiency in movements can improve without primarily increasing the MIS skill level and the quality of the suture as judged by expert assessors. This could also be the number of errors made. However, the real issue to overcome remains unclear.
Maybe VR training can help to overcome the problems we faced, because it might be able to assess a knot more adequately. It lacks realistic haptic feedback and many studies indicate that “created” haptic feedback does not work well. Therefore, it has no added clinical value compared with regular VR training.29–31 Tasks that rely on force application, such as intracorporeal suturing, are performed better when true haptic feedback is provided in a video box-trainer.14,17,32,33 In addition, residents seem to prefer box-trainers over VR trainers. 34
Better methods of determining a user's level without an expert, such as artificial intelligence (AI)-driven systems, should be investigated. Incision© uses AI to recognize different surgical instruments as well as the way the instruments are used, and creates feedback for surgical procedures. 35 This could be the future of objective assessment in MIS suturing training, if applicable to (low budget) training systems and box-trainers.
Limitations of this study were the use a small expert group. Nevertheless, the expert's scores seemed consistent and showed little variance, especially regarding the composite score. There were more outliers in the novice group than in the experienced group, which was taken into account during the calculation of the composite score. This larger variance was expected and seen in earlier studies.22,23 To uncover more details about the experts, additional studies will be needed. Owing to a software error, the groups were different than originally planned. Some videos started too late, making a reliable assessment with the LS-CAT impossible.
However, there was no reason that this has negatively influenced the overall results. It seems better to look at several moments during the training, instead of purely the predefined moments. In addition to the technical failure, it was not possible to use the first try of all participants, therefore, the first knot as stated in Table 4 was not always the first knot of the participant, but the first knot that could be assessed reliably. That is why the number of the “start” and “first” knots does differ. The number of the end and last knots also differs, because some participants did reach their plateau before they reached their 20th repetition.
Conclusion
Neither a calculated composite score nor the separate parameters “time” and “distance” were able to reliably predict the quality of a complex surgical procedure, like minimal invasive suturing. The metric parameters of instrument tracking seem to miss important components that experts do value in their assessment. Consequently, reliable feedback and judgment of the surgical skills with simulator metrics alone are not possible, and expert assessment remains superior.
Footnotes
Authors' Contributions
D.V. contributed to writing—original draft (lead), formal analysis (lead), and conceptualization. V.H. was involved in review and editing. E.L. was in charge of review and editing, and formal analysis (supporting). B.H.V. carried out review and editing, and resources. S.M.B.I.B. took care of review and editing, resources, conceptualization, and supervision. All authors read and approved the final article.
Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.