
Abstract
Background:
The Clificol® COVID-19 Support Project is an innovative international data collection project aimed at tackling some of the core questions in homeopathy, including the aspect of treatment individualization. This article further analyzes the symptoms used and remedies prescribed.
Methods:
We conducted an international clinical case registry study (ClifiCol) of patients with confirmed or suspected COVID-19. In China, the symptoms were collected with the aid of a questionnaire, whereas, in all the other countries, participating homeopaths could freely record the symptoms that informed the remedy prescription. The symptom rubrics and remedies used in non-Chinese countries were further analyzed.
Results:
The database consisting of 1227 cases, as collected between January 10, 2020, and October 31, 2021, was used as a basis for the analyses. It included 868 cases (1354 prescriptions) from 29 non-Chinese countries. We observed an unexpectedly high level of variability. This was expressed, among others, by the very large number of repertory rubrics used in general. In total, 1190 of the 1403 rubrics (85%) were used less than five times. A higher proportion of uncommon rubrics was not associated with faster recovery from COVID-19. In total, 137 homeopathic remedies were used; the three most frequently used ones (Bryonia alba, Phosphorus, and Arsenicum album) were used in 42% of all prescription episodes. The 88 least commonly used remedies (out of a total of 137) accounted for only 9% of all prescription episodes.
Conclusions:
A small subset of the most commonly used symptom rubrics and remedies covered the great majority of prescriptions. Focusing on the most common symptoms and remedies for the statistical validation of homeopathy is justified and will greatly enhance the ability of clinical case registry projects to contribute to improving homeopathic practice.
Introduction
The Clificol® COVID-19 Support Project is an innovative international data collection project aimed at tackling some of the core questions in homeopathy, including the aspect of treatment individualization. Several articles on this project were published.1–5
The remedy selection process in homeopathy was based primarily on the expression of specific and general acute COVID-19-related symptoms in each individual patient. Symptom rubrics used for repertorization were analyzed. This article expands on the previously reported results in this journal 1 , 6 , 7 by further assessing the extent and nature of variability observed in the selected symptom rubrics and remedies.
Materials and Methods
Analyses of Clificol dataset
We assessed actually observed variability in an international observational clinical case registry study (ClifiCol) of patients with confirmed or suspected COVID-19. In one country (China), the symptoms were collected with the aid of a 150-item questionnaire. In all the other countries, participating homeopaths could freely enter the symptoms that informed the remedy prescription. All non-Chinese patient records entered in the database with confirmed or suspected COVID-19 were included; the Clificol project team had no influence on the selection of patients and remedies prescribed. The analysis team downloaded the data periodically from the platform. Any data-related queries were fed back to the concerned practitioners as appropriate. The analysis team checked that all cases had linked consultation(s) data.
In order to facilitate/optimize comparisons, we used the same dataset as in our earlier article, 1 which excluded the Chinese patients.
The remedy selection process in homeopathy was based primarily on the expression of both specific and more general, acute COVID-19-related symptoms in each individual patient. Symptoms deemed most relevant for informing the homeopathic prescription were converted by the homeopath into “symptom rubrics” and entered into repertorization software, with the objective to identify the most suitable individualized homeopathic remedy that best matched the patient’s symptom picture. While homeopaths could enter any symptom in the form of “free text,” “symptom rubrics” were the most useful “standardized” bits of information used for analytical purposes.
Prescription episodes were defined as one or more consultations where the remedy remained unchanged. If the same remedy was repeated one or more times in the same or a different potency, this would be analyzed as part of the same prescription episode. A change in the homeopathic remedy based on clinical need, for example, based on a change in symptomatology or a lack of clinical response, would trigger a new prescription episode. If a new repertorization accompanied the prescription of the new remedy, it would be linked to this remedy in the new prescription episode. This procedure ensured that recorded repertorizations, and the changes observed subsequently would always be linked to the remedy prescribed. In the very rare cases that more than one remedy was given simultaneously, the homeopath had to indicate the main remedy for the prescription. Any supplementary remedies were entered as free text and were not analyzed as part of the prescription episode. The rubrics were quantified by counting the total of rubrics collected in association with prescription episodes, as well as the total number of unique rubrics. Subsequently, we applied a number of rubric aggregating/grouping techniques with the aim to reduce the total number of rubrics. For increased clarity, we explain (and practically illustrate) these techniques in conjunction with the results.
The median number of rubrics entered on an unrestricted basis was calculated and compared between countries.
Results
The study base is described in Figure 1.

Flowchart of case and rubric selection process.
After excluding the 359 patients from China, the dataset consisted of 868 cases recorded between 10 January 2020 and 31 October 2021. In 868 cases, 1354 prescription episodes were recorded. In the 679 prescriptions where rubrics were entered, a total of 1403 unique rubrics were used (median = 4 rubrics per prescription). We already reported on the high level of variability between countries in this dataset. 1 In this article, we analyze variability in the selected rubrics and remedies prescribed in further detail.
The number of distinct rubrics is plotted against the number of prescription episodes in Figure 2 (blue line).

Number of unique and grouped rubrics in relation to the number of prescription episodes.
As depicted by the steep rise of the blue line in Figure 2, the number of distinct rubrics used (1403 in total) shows an almost linear increase with the number of prescriptions, which did not level off, not even after more than 650 prescription episodes. This meant that many rubrics were only rarely used; for instance, 1190 of the 1403 rubrics (85%) were used less than five times.
Considering that quite a few symptoms were represented by multiple, similar, rubrics, we decided to group as many rubrics as possible. The procedure for this is described below.
Rubrics were grouped preserving information as much as possible. When a modality was present (e.g., worse cold), the rubric was split into two rubrics, with the second rubric containing the modality. Rubrics, or rubric groups, that were used less than five times in total were considered uncommon and not considered further.
A few examples of the rubric groupings are given in Table 1.
Examples of Groupings of Individual Rubrics
The orange line in Figure 2 represents the grouping resulting from steps (A) and (B). It illustrates that the procedure significantly reduced the total number of rubrics to 445. However, as illustrated by the rising orange line, it did not resolve the problem of an ever-increasing number of rubrics with an increasing number of prescriptions. The main reason for this was that many uncommonly used rubrics could only be grouped into a small “cluster” of only two or three rubrics. Similar to the ever-increasing number of rubrics as illustrated by the blue line in Figure 2, this led to an ever-increasing number of very small “rubric groups.” As described in step C above, we therefore excluded rubrics, or rubric groups, with less than five uses. This further reduced the number of rubrics, or rubric groups (henceforth for ease of reading referred to as “rubrics”) by 300 (from 445 to 145). This is visualized by the difference between the ends of the orange and green lines in Figure 2. While excluding 300 rubrics used less than five times seems to be a high number, it only reduced the total (absolute) number of rubrics entered in the database by about 6% (from 4268 to 4017). Therefore, the practical implication was limited because the great majority of rubrics were used only once. Step C was therefore necessary to prevent a moderate continued rise in the total number of rubrics. Overall, steps A to C reduced the number of rubrics in total by about 90% (from 1403 to 145).
After this, we further explored the frequency distribution of the 145 rubrics. For this, we first determined the total number of prescriptions episodes in which each of the rubrics was used. We then sorted and numbered the rubrics in descending order based on frequency of use, where rubric number 1 was used the most (in 200 prescription episodes) and rubric number 145 the least (in five prescription episodes). This is depicted in Figure 3.
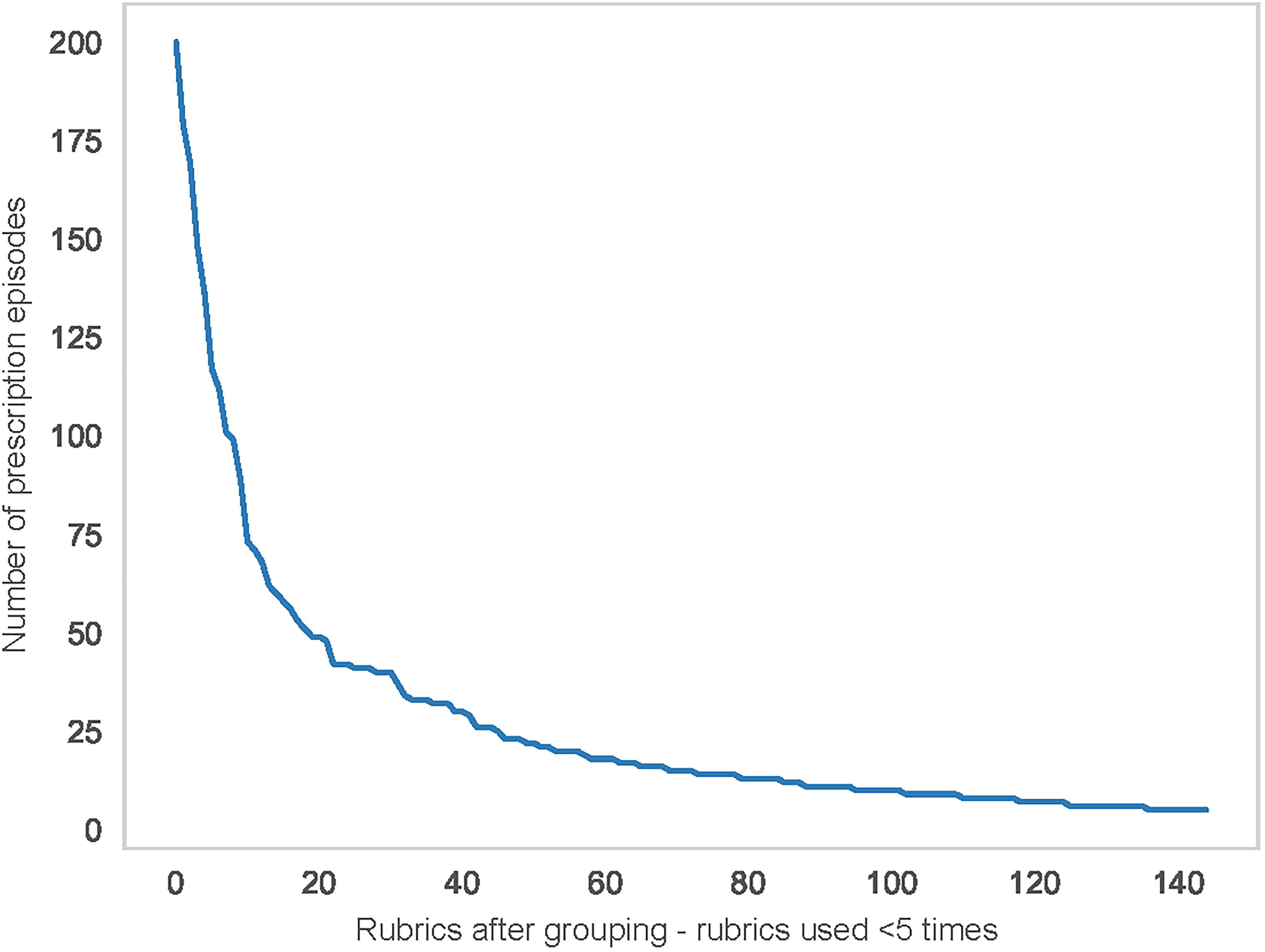
Number of prescription episodes in which each of the 145 rubrics was used, sorted in descending order of frequency.
Figure 3 illustrates that the distribution of rubrics has a characteristic exponential shape, with a few common rubrics being used in many prescriptions, and many rubrics being used only infrequently. While the grouping process resolved the unbridled increase in the number of rubrics used, it did not fundamentally change the shape of the distribution compared with the same distribution for the ungrouped rubrics (data not shown). This is typical of the Pareto principle (https://www.juran.com/blog/a-guide-to-the-pareto-principle-80-20-rule-pareto-analysis/), which, in popular language, is often referred to as the “80/20 rule.” In our dataset, we observed that a small subset of, for example, 29 (20%) of the most commonly used rubrics informed 762 (91%) of the prescriptions.
Figure 4 provides further details on the nature and the prevalence of the 20 most commonly used grouped rubrics.

Prevalence (absolute count) of the 20 most commonly used rubric groups.
We also looked at the number of remedies prescribed as a proportion of the total number of prescriptions. This analysis revealed that the 3 (2%) most commonly prescribed remedies (Bryonia alba, Phosphorus, and Arsenicum album) covered 42% of the total number of prescriptions, whereas the 25 (18%) most commonly prescribed remedies covered 80% of the prescriptions. This indicates that a small number of remedies covered the great majority of prescriptions. On the other end of the spectrum, the 100 least commonly prescribed remedies (73% of the total number of remedies used) covered only 13% of all prescriptions. Therefore, many remedies were used only once or twice. This is not at all in line with the notion of a more limited set of “genus epidemicus” remedies.
When presenting the results of these analyses to colleagues, we received feedback that the use of uncommon rubrics and remedies could be associated with a high level of individualization in line with paragraph 153 of Hahnemann’s Organon, which emphasizes the use of “strange, rare, and peculiar” rubrics. We therefore looked further into the speed of recovery, as assessed with the aid of the ORIDL score 8 in relation to the proportion of uncommon rubrics supporting the remedy decision. For this purpose, we made use of the dataset with 445 rubrics after steps A and B as described above and categorized these into “uncommon” (used less than five times) and “not uncommon” (used five times or more). For each prescription episode, we then divided the number of uncommon rubrics to the total number of rubrics used and expressed this as a percentage. Subsequently, the prescriptions with more than 25% uncommon rubrics were categorized as having a “high” level of uncommon rubrics and the remainder as “not high.”
As described in our previous article, 1 the speed of recovery was dichotomized into “rapid” and “non-rapid” based on the ORIDL score as follows; a rapid disease resolution was defined as an ORIDL score ≥3 (major improvement) on day 3 after initiating homeopathic treatment with no relapse or new prescription on or before day 7; all other scores led to categorization as “non-rapid” recovery. We then explored a possible association between the level of uncommon rubrics and the speed of COVID-19 recovery (rapid or non-rapid) in Table 2.
Speed of Recovery in Relation to the Proportion of Uncommon Rubrics Used to Inform the Remedy Selection
Percentages were rounded to the nearest integer.
Table 2 indicates that recovery was rapid in 78% of prescriptions with a high proportion of uncommon rubrics and 76% in prescriptions with a low proportion of uncommon rubrics (p-value chi-squared test 0.8). These findings do not support the hypothesis that the use of rare or uncommon rubrics is associated with better outcome, as assessed via the speed of recovery.
The total number of different remedies that were used, was 137. We also explored if the frequency in which particular remedies were used by the participating homeopaths was associated with treatment outcome. In particular, we wanted to explore the hypothesis if less frequently used “uncommon” remedies were associated with faster recovery compared with more commonly used remedies. For this purpose, we categorized the remedies into those that were used in total 1–7 times, 8–30 times, and 31–250 times and compared the proportion of rapid recovery between these three categories (Fig. 5).

The proportion of rapid recovery, stratified into three categories based on the frequency of remedy use. The number of remedies in each category as well as the number of prescription episodes concerned are listed at the bottom of each column. Vertical bars are 95% confidence intervals.
Uncommon remedies are more likely to be selected in patients with highly individualizing “strange, rare, and/or peculiar” symptoms. It is hypothesized in homeopathy, as proposed by its founder Samuel Hahnemann, that highly individualized prescriptions are more effective than less well-individualized prescriptions. If true, this would lead to a faster recovery in patients who received highly individualized uncommonly used remedies, compared with patients who received more commonly prescribed remedies based on more common homeopathic symptoms, including clinical COVID-19 symptoms. Figure 5 illustrates that no such trend was observed in our data; the proportion of patients with a fast recovery was about the same for the least commonly used remedies as for the most commonly used remedies.
In conclusion, the use of uncommon rubrics and remedies was not associated with improved clinical outcomes. Moreover, it added a lot of variability, and this complicated and limited our ability to analyze the data.
Discussion
We found that a limited number of rubrics and remedies covered the great majority of prescriptions, whereas a large number of rubrics and remedies were only rarely used. The high level of variability in the reported symptom rubrics and remedies used, complicated, and hampered the conduct of aggregated analyses. Overall, the variability observed was much greater than we expected for the treatment of an epidemic disease. Homeopathic theory predicts a more limited set of COVID-19-associated “genus epidemicus” symptom clusters. While we observed such clusters in questionnaire-based COVID-19 data, 2 we were not able to identify such clusters in the current dataset of cases based on freely entered symptoms. 1
To our knowledge, our study is the first one in which the Pareto principle with regard to the number of rubrics and remedies used was quantified in homeopathy on the basis of “real-world” clinical data.
While grouping of similar rubrics significantly reduced the total number of rubrics, a high number of rubrics remained “un-groupable” or could only be grouped in very small symptom clusters, many of which were still rarely used.
Strengths
Our analyses provide a unique “window” on the actual behavior of homeopathic practitioners during a modern-era pandemic. Moreover, the global nature of the project enabled naturalistic comparisons between countries with unstructured data collection. A further strength is that we were able to apply modern cloud-based information technology to homeopathic data collection at a global level.
Weaknesses/limitations
The Clificol COVID-19 case registry involved retrospective data entry, increasing the likelihood of biases, including unknown selection biases, in comparison with prospective data collection. Moreover, due to the difficulties experienced with analyzing the data, we did not make full use of the potential of cloud-based data collection by promptly feeding back results to the practitioners. Apart from the fact that promptly feeding back results helps to build a community and motivates practitioners to contribute their cases, we missed the opportunity to discuss, and if necessary correct, anomalous results and biases. The latter very likely contributed to the high levels of variability in our data.
Another possible explanation for the observed high variability could be that because COVID-19 was a “new” disease, no previous experience had been obtained, leading to a higher than usual level of treatment heterogeneity. Because homeopathic treatment is patient-centered, rather than disease-centered, we do not feel that this can fully explain our findings.
We recognize that observations made concerning the treatment of a specific acute disease cannot be generalized to the homeopathic treatment of other, for example, chronic diseases. However, it is worth noting that variability in the treatment of chronic diseases is likely to be even higher because the symptom and remedy selection process centers more around the patient’s general, constitutional characteristics. Our findings are therefore likely to be an underestimation of the problem of unwanted variability (the latter is also referred to as “noise”).
Implications
The founder of homeopathy, Samuel Hahnemann, emphasized the value of strange, rare, and peculiar symptoms for identifying the correct (i.e., successful) remedy (also referred as the “similimum”). The frequent use of uncommon rubrics and remedies would therefore theoretically be associated with a higher probability of treatment success. Despite thoroughly exploring this hypothesis, we were unable to demonstrate such an association with a better treatment response. Differently put, the increased variability introduced by the highly individualized use of uncommon rubrics and remedies was not associated with the benefit of improved treatment outcomes. As a limitation, it should be emphasized that the presence or absence of an association in an observational study such as ours, does not prove the presence or absence of a causal association. All we can say is that we did not observe in our dataset what some homeopathic textbooks would predict.
We therefore think that the rubric grouping and exclusion of uncommon rubrics as described, were justified. We did this retrospectively, which is arguably a limitation.
In the future, it would be worth looking further into work already done by homeopaths to link similar rubrics. Arguably, different homeopaths may be using a slightly different language (repertory rubrics) to approach the same “symptomatic concept.” For instance, in the homeopathic repertorization software package RadarOpus, the “Synthesis/Adonis” feature could be used for the identification of synonyms and for cross-referencing. Other repertories such as Foster and Guernsey also offer a cross-referencing function. Another possibility would be to enable subrubrics in a hierarchy of rubrics to be allocated to the (more common) rubric that is highest in the hierarchy. The latter, together with linking similar rubrics, could possibly be used to create more common “symptom concepts” that could be used for aggregated analyses while maintaining the possibility to link it back to the more “granular” level that underpins the symptom concept for other types of analyses.
It should also be pointed out that the use of rubric aggregation techniques in homeopathy is not something new: The homeopath Boenninghausen first published a “Systematic Alphabetic Repertory” between 1832 and 1835, which contained 617 pages. 9 He then concluded that this concept was not optimal, after which it took him 11 years to “generalize” and reduce the number of symptoms as reflected in his “Therapeutic Pocket book,” 10 which was smaller in size and contained only 375 pages. Therefore, in the course of 11 years of deliberation, he was able to more than half the total number of symptoms, which he referred to as “genius symptoms.” 11 In modern times, various homeopaths, including George Dimitriadis and Heiner Frei, further expanded on, and confirmed the value of, Boenninghausen’s seminal work.12,13
Variability is a fundamental principle inherent in all natural systems, and whether it is desirable or undesirable will depend on the context. We observed undesirably high levels of variability in the sense that it hampered the ability to learn lessons from homeopaths’ collective experience with the treatment of COVID-19 patients. It should be stated that the problem of unwanted variability (also referred to as “noise”) is not unique to homeopathy; it has been identified as an underestimated problem in many other domains involving human judgment. 14 Addressing this problem in homeopathy requires a deeper understanding of all possible sources of both wanted and unwanted variability in homeopathic practice. While retaining some room for the validation of strange, rare, and peculiar rubrics based on high-quality case material, a significantly reduced number of more commonly used symptoms and/or rubrics can be validated in clinical case registry projects as well as more targeted prospective observational studies.
Comparing the COVID-19 Support Project findings as reported in this article with those of the Chinese patients obtained with the aid of a symptom questionnaire 2 indicated that the latter significantly reduced unwanted variability. We therefore recommend a wider use of symptom questionnaires in patient registry projects.
A fundamental question emerging from our analyses is whether it is necessary to reduce the complexity of homeopathic practice by reducing the number of rubrics in repertories and the materia medica. In the second half of the 20th century, the motto in the homeopathic community seems to have been “more is better.” The number of rubrics in repertories was expanding rapidly; many new remedies were added to the materia medica, often without much, or unclear, empirical substantiation. The beginning of the 21st century was possibly a turning point, heralded by the groundbreaking work on prognostic factor research of Dr. Lex Rutten, 15 who argues that we need smaller, more reliable repertories. 16 He and his colleague Dr. Jose Eizayaga have launched such a repertory (https://www.bayesian-homeopathic-repertory.com/) as well as a specific application for COVID-19 patients (https://www.hpra.co.uk/).
Overall, our findings also point in the direction of “less being better;” in other words, that “Ockham’s razor” (see opening quote, “plurality should not be assumed without necessity”) should be applied more in homeopathy. In the same spirit, the French writer Antoine de Saint-Exupery stated that “perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away.” While it would be too early to conclude just on the basis of our study that the value of “rare” rubrics may be over-rated in homeopathy, it seems justified to raise this question. While clinical case registries could be used to identify unusual cases, case registries are unable to statistically validate “Strange, Rare and Peculiar” symptoms or rarely used remedies, because it is not possible to obtain sufficient quantitative data. Moreover, the common practice of adding such symptoms to the materia medica solely based on the opinion of homeopathic experts is clearly insufficient in 21st-century evidence-based practice. Validation of such symptoms should ideally be based on successful, high-quality clinical case reports, for which guidelines are now available.15–19
Conclusion
We observed high levels of variability, much of which hampered our ability to statistically analyze the experiences of participating homeopaths with the treatment of COVID-19 patients. Reducing unwanted variability (noise) in homeopathy is needed and justified. We demonstrated that a small subset of the most commonly used symptom rubrics and remedies covered the great majority of prescriptions. Focusing on the most common symptoms and remedies for the statistical validation of homeopathy is justified and will greatly enhance the ability of clinical case registry projects to contribute to improving homeopathic practice.
Footnotes
Acknowledgment
The authors would like to acknowledge Lex Rutten for his critical, constructive, and practical feedback, which has helped them to further improve this article.
Authors’ Contributions
R.v.H. and A.T. were involved in the planning and interpretation of the analyses and writing of the article. A.T. and Y.F. were involved in the planning, conduct, analysis, and writing of the article. All authors agree to the contents of the article.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received for this article.