
Abstract
Background:
Artificial intelligence, specifically deep learning-based large language models (LLMs), are quickly emerging as a tool for supporting clinical decision-making. We asked whether current LLMs can accurately and safely perform clinical decision-making for obesity medication prescribing.
Methods:
Twenty hypothetical patients visiting weight management clinics were created with detailed medical and personal histories. Four obesity medicine experts were asked to choose their first-choice weight loss medication, as were four LLMs: GPT-4o, Llama3, Gemini1.5, and Claude3.5. All the LLMs underwent identical prompt tuning and were configured with a uniform temperature setting of 1.0. All medication choices by the obesity medicine experts were presumed correct and a binary system was used to compare whether the LLMs did or did not select one of the medications proposed by the experts. Hallucination incidence and high-risk medication choices are evaluated.
Results:
Gemini1.5 and GPT-4o had the highest matching rate with experts (55%), followed by Claude3.5 Sonnet (50%) and Llama3 (30%). Only Gemini1.5 avoided high-risk or contraindicated medications in all cases. Among the LLMs, Llama3 had a statistically significant high hallucination incidence rate (p < 0.01). Some of the LLMs’ choices and rationales were creative and reasonable, offering insights that experts had not considered.
Conclusion:
LLMs can offer valuable insights into clinical decisions for obesity treatment. However, safety and accuracy concerns persist due to hallucinations. It is premature to use LLMs as clinical support tools. They need refinement through fine-tuning, detailed prompt tuning, real-world data incorporation, and rigorous validation to ensure reliability and safety.
Introduction
Artificial intelligence (AI), specifically deep learning-based large language models (LLMs), are quickly emerging as a tool to support clinical decision-making. In health care, AI is already used for multiple applications: to aid diagnostics, enhance efficiency of health systems, personalize treatment recommendations, offer risk predictions, identify patients for early interventions, and assist with clinical documentation.1–5 Although still in the early phases, LLMs have already demonstrated their ability to improve the efficiency and effectiveness of clinical practice. 1
In clinical decision-making, especially when prescribing antiobesity medication (AOM), the process requires consideration of both clinical and nonclinical factors. Consequently, the final choice of medication can vary among providers. Overlooking any of these factors may significantly affect the treatment decision. LLMs can support this process by minimizing errors . AI approaches to AOM prescribing to improve efficiency and accessibility should be considered, given the large mismatch between demand for health care providers who can deliver comprehensive weight management care and the population-level need. It is estimated that by 2030, 50% of the global population will be living with either overweight or obesity, 6 underscoring the importance of exploring all avenues for safe medication prescribing to improve access to AOMs for patients, including decision support from LLMs.
However, the safety of LLM tools as a clinical decision-making aid has not been fully evaluated across specific clinical scenarios, including for AOM prescribing. AI as a clinical decision-making tool for medication prescribing has previously been used in a number of applications, 7 including: as support for adverse drug reactions detection and prediction,8–10 to help pharmacists and physicians more easily sort through patient data and avoid prescribing errors using clinical decision support systems 11 and computerized physician order entry, 12 and to support individualized dose optimization for chemotherapy. 13 All of these AI-aided prescribing strategies aim to reduce errors related to medication interactions and improve medical system efficiency.
In this study, we explore whether four LLMs can accurately and safely perform clinical decision-making for AOM prescribing. We compared LLM AOM decisions with choices made by obesity medicine expert clinicians including physicians, nurse practitioners, and physician assistants. We evaluated unsafe choices by LLMs, as well as creative or surprising medication decisions, and explored the rationales the LLMs provided for their choices.
Methods
Twenty hypothetical patients visiting weight management clinics were created with detailed medical and personal histories (patient cases in Supplementary Data S1). Medical information for the patients included age, gender, occupation, medical insurance coverage, chief complaint, history of weight challenges and prior attempts to decrease weight, past medical history, family and social history, a brief dietary history, current medications, a physical exam (including height, weight, body mass index, blood pressure, heart rate, respiratory rate, temperature), and laboratory tests (basic metabolic panel, complete blood count, liver enzymes, thyroid stimulating hormone and free T4, fasting blood glucose, lipid panel, and A1c). Based on the information provided in the cases, four obesity medicine experts (MD, NP, or PA) were asked to choose their first-choice weight loss medication, as were four LLMs: GPT-4o by OpenAI, Llama3 (70B model) by Meta, Gemini1.5 by Google, and Claude3.5 Sonnet by Anthropic.
For the prompt tuning, an AI testing platform was used for LLMs while maintaining a uniform temperature setting of 1.0 across all models. Specifically, GPT-4o was run on GPT Playground, Gemini1.5 on Google AI Studio, Claude3.5 Sonnet on Anthropic API, and Llama3.0 on Ollama. Except for Llama3.0, which was operated offline on a personal computer, all other models were tested online.
All LLMs followed the same prompt tuning process. Each model could choose only one medication, and selecting nonmedical treatment options was not permitted. However, they were allowed to opt for non-FDA approved medications with proven benefits for weight loss, including combination therapies such as bupropion with naltrexone or phentermine with topiramate. They were instructed to consider both clinical and nonclinical information to recommend the most feasible and effective medication for each case (Supplementary Data S2).
All medication choices by the obesity medicine experts were presumed correct and a binary system was used to compare whether the LLMs did or did not select a medication proposed by any of the four expert clinicians. Hallucination incidence and high-risk medication choices by the LLMs were evaluated by a 5th obesity medicine expert clinician (MD) (Table 4).
Categorical variables were expressed as numbers and percentages (frequencies). To compare the “agreement rate with the experts,” “AI hallucination incidence rate,” and “rate of high-risk medication selection” between the LLM groups, Fisher’s exact test was applied. All analyses were performed using SPSS version 29.0 (IBM, Chicago, Illinois, USA). A two-sided P value of <0.05 was considered statistically significant.
This project was reviewed by the Mass General Brigham Institutional Review Board, classified as nonhuman subjects research, and therefore exempt from IRB approval. The decision was made on June 18, 2024.
Results
All four LLMs made medication choices for the patient cases with varying degrees of alignment with expert opinions. They also exhibited hallucinations (medication choices that included misinformation and incorrect rationales even if they matched with expert opinions), and unsafe AOM choices (Tables 1–5). Gemini1.5 and GPT-4o had the highest matching rate of medication choices with expert clinicians (55%), followed by Claude3.5 Sonnet (50%) and Llama3 (30%) (Tables 1, 4–5, Fig. 1). The least well performing was Llama3, which made four high-risk medication choices (20%) and had 17 (85%) hallucinations. Best performing was Gemini1.5 Pro, which made no high-risk drug choices, with only two (10%) hallucinations. In the middle were GPT-4o, which made two high-risk drug choices (10%), and had four (20%) hallucinations, and Claude3.5 Sonnet, which made one (5%) high-risk medication choice, and had four (20%) hallucinations (Tables 1, 4–5, Fig. 1
Antiobesity Medication Choices by Large Language Models
H, hallucination; U, unsafe AOM choice; C, creative choice.
Example Hallucinations and Unsafe Medication Choices by Large Language Models
Valid Artificial Intelligence Prescribing Rationales That Did Not Match Clinician Choices (Creative Choices)
Antiobesity Medication Choices by Expert Clinicians: Binary Yes/No (1/0), if the Large Language Model Matched with at Least One Expert Opinion
Number of Large Language Model Hallucinations, High-Risk Drug Choices, and Antiobseity Medicine Choices Matched with Expert Clinicians (out of 20 Cases)
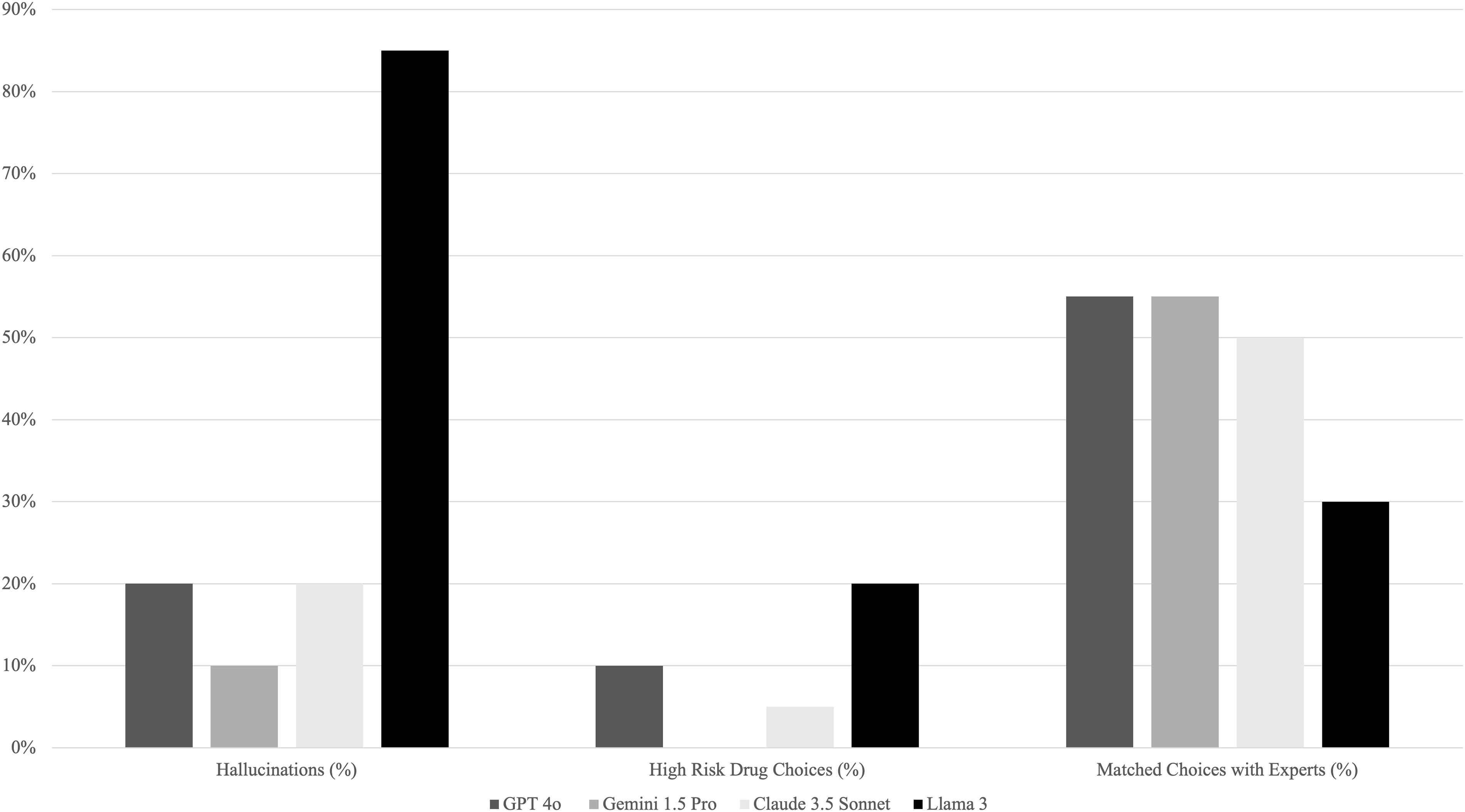
Percentage of LLM hallucinations, high-risk drug choices, and AOM choices matched with expert clinicians (out of 20 cases). LLM, large language model; AOM, antiobesity medicine.
There was also overlap in hallucinations and unsafe medication choices; some choices by the LLMs were contraindicated (unsafe) but were still selected with false rationales (hallucinations). For example, Claude3.5 Sonnet chose Qysmia (phentermine, topiramate) for a patient with kidney stones stating, “Kidney stone consideration: topiramate, a component of Qsymia, has been shown to have some protective effects against kidney stones, which is relevant given Linda’s history.” This is incorrect, as topiramate increases the risk of kidney stones. 14 Only Gemini1.5 avoided high-risk or contraindicated medications in all cases. Further examples of hallucinations and unsafe medication choices with the rationales provided by each LLM and expert clinician comments can be found in Table 2.
Discussion
There was significant variability in performance across LLMs when evaluated for the number of hallucinations, unsafe medication choices, and choices matched with expert clinicians (Table 5, Fig. 1). Although all the LLMs had hallucinations, Llama3 had significantly more than others. This may be because only Llama3 used an independent program and was run on a personal computer (which limited choices and learning). There is a “Meta AI” chatbot based on Llama3 and operated by Meta. However, it is already pretrained with multiple algorithms, and all medical questions are strictly prohibited. Therefore, we are unable to perform any tests using this online-based chatbot. Gemini1.5 was the only LLM that did not choose any contraindicated or high-risk medications across all 20 cases. Except for Llama3, which chose either Wegovy (semaglutide) or Qsymia (phentermine, topiramate) for all 20 cases, all the LLMs had decent variability (>3 different medications) in medication choices. The variability in hallucinations and medication choices between the LLMs is likely due to the pretraining times, or the duration of time it takes to train a machine learning model on a large general dataset, as pretraining times differ for all LLMs. This is also likely why no LLM chose a newer medication, such as Zepbound (tirzepatide), as the study was run in July 2024, and the LLMs did not have the knowledge of Zepbound in their training datasets.
Some of the LLMs’ choices and rationales included creative insights that are still valid even if they did not match the experts' choices (Table 3
LLMs also accurately factored insurance considerations into AOM decision making. For example, Gemini1.5 Pro selected metformin for a self-paying patient with the rationale, “John is self-paying, making cost a significant factor in medication choice. He’s already on metformin, and increasing his dosage for weight loss would be considerably more affordable than starting a newer, branded medication.” While weight loss with metformin will likely be minimal, this is still a creative rationale for a medication choice by Gemini1.5 Pro and illustrates the sophistication of the LLM decision making in select cases. As another example of sophisticated risk-benefit considerations and insurance coverage, Gemini1.5 Pro chose Wegovy for a Medicare patient stating, “Cardiovascular Benefits: Given Arthur’s history of stroke and myocardial infarction, the established cardiovascular risk reduction benefits associated with Wegovy (semaglutide) make it a compelling choice. Medicare Coverage: Medicare coverage for weight-loss medications is limited, so careful verification of Arthur’s specific plan and potential out-of-pocket costs for Wegovy is essential. While cost is a factor, the potential long-term health benefits and cost savings associated with preventing future cardiovascular events should be considered. Discussing these factors and exploring potential financial assistance programs (if needed) with Arthur would be essential.” In this case, a portion of the cost of Wegovy should be covered by Medicare given the patient’s history of both stroke and myocardial infarction, but this is an important consideration by Gemini1.5 Pro and illustrates another example of sophisticated decision-making by an LLM.
A number of limitations are inherent to LLM use as clinical decision tools. One issue inherent in LLM use for AOM prescribing is the rapidly changing nature of the AOM landscape and clinical recommendations, as well as changes in insurance coverage plans. Real-world data incorporation and pretraining takes time for LLMs, which means that in a rapidly changing clinical landscape, they may not be able to offer clinical recommendations that are current. As discussed above, pretraining lag time is likely why none of the LLMs chose a newer medication such as Zepbound, as this study was run in July of 2024. Another limitation is the tradeoff between higher temperature settings for LLMs, which can act as a proxy for creativity, but can also produce inconsistent outcomes. For example, if the same query is presented to the same LLM multiple times, it may yield different responses and varied rationales for selecting an AOM. 15
Another limitation of this study is that the LLMs were not trained specifically for obesity medicine diagnostics. Therefore, there were still a significant number of errors in formulating the treatment plans. However, the results may be different if the LLMs underwent training. It is possible to train a model to increase accuracy of generated data, diagnosis, and treatment options, similar to how we train human clinicians in use of AOMs.
Based on these results, many LLM tools are not yet ready to act as the primary decision maker for AOMs. Providers should counsel patients that LLMs and other AI tools should never be used alone to diagnose or treat medical conditions, and patients should always consult with a trained physician to discuss risks and benefits of different medications for overweight and obesity.
Conclusions
AI is emerging as a promising tool for information synthesis and clinical problem solving in medicine. However, none of the LLMs tested in this study had >55% matching rate with obesity expert clinicians for AOM choices. Safety and accuracy concerns persist due to hallucinations and unsafe medication choices. Therefore, it is premature to use any of the four LLMs we tested in this study (GPT-4o, Llama3, Gemini1.5, and Claude3.5 Sonnet) as clinical decision support tools for AOM prescribing. At the same time, our study highlights that LLMs can offer meaningful perspectives on clinical decisions for obesity treatment, including ideas that clinicians might not typically consider. Matching rates and safety concerns can be addressed through fine-tuning, retrieval-augmented generation, detailed prompt engineering, and/or the integration of real-world data into LLMs. Rigorous validation will be essential to ensure their dependability and safety before these models can be utilized in clinical settings to guide obesity treatments.
Footnotes
Authors’ Contributions
D.W.K. conceived of the presented idea and served as the corresponding author. B.F. developed the article. H.L. performed the data analysis. T.T., T.D., and C.C. contributed to data collection and verified the findings. C.M.A. supervised the work and encouraged B.F. throughout article development. All authors discussed the results and contributed to the final article.
Author Disclosure Statement
B.F.—Nothing to disclose. H.L.—Nothing to disclose. T.T.—Nothing to disclose. T.D.—Nothing to disclose. C.C.—Nothing to disclose. C.M.A. has participated on advisory boards for Altimmune, Inc; BioAge; Biolinq Inc; CinFina Pharma, Inc; Cowen and Co, LLC; Covi-dien LP; Form Health, Inc; Fractyl Health, Inc; Gelesis SRL; Lilly USA, LLC; L-Nutra, Inc; NeuroBo Pharmaceuticals, Inc; Nutrisystem; OptumRx, Inc; Pain Script Corp; Pa-latin Technologies, Inc; Pursuit By You; Redesign Health Inc; ReShape Lifesciences Inc; Riverview School; Roman Health Ventures Inc; Vida Health, Inc; Veru Inc; Wave Life Sciences; Xeno Biosciences; and Zyversa Therapeutics, Inc. D.W.K.—Nothing to disclose.
Funding Information
No funding was received for conducting this study.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.