
Abstract
Objective:
To date, there are no widely implemented machine learning (ML) models that predict progression from prediabetes to diabetes. Addressing this knowledge gap would aid in identifying at-risk patients within this heterogeneous population who may benefit from targeted treatment and management in order to preserve glucose metabolism and prevent adverse outcomes. The objective of this study was to utilize readily available laboratory data to train and test the performance of ML-based predictive risk models for progression from prediabetes to diabetes.
Methods:
The study population was composed of laboratory information services data procured from a large U.S. outpatient laboratory network. The retrospective dataset was composed of 15,029 adults over a 5-year period with initial hemoglobin A1C (A1C) values between 5.0% and 6.4%. ML models were developed using random forest survival methods. The ground truth outcome was progression to A1C values indicative of diabetes (i.e., ≥6.5%) within 5 years.
Results:
The prediabetes risk classifier model accurately predicted A1C ≥6.5% within 5 years and achieved an area under the receiver-operator characteristic curve of 0.87. The most important predictors of progression from prediabetes to diabetes were initial A1C, initial serum glucose, A1C slope, serum glucose slope, initial HDL, HDL slope, age, and sex.
Conclusions:
Leveraging readily obtainable laboratory data, our ML risk classifier accurately predicts elevation in A1C associated with progression from prediabetes to diabetes. Although prospective studies are warranted, the results support the clinical utility of the model to improve timely recognition, risk stratification, and optimal management for patients with prediabetes.
Introduction
Diabetes mellitus affects 37.3 million people in the United States and is a tremendous source of morbidity and mortality worldwide. Major complications include increased emergency department visits, hospitalizations, and death. 1–2 As a complex, chronic disorder that impacts myriad organ systems, diabetes accounts for a disproportionate health care system expenditure, with studies estimating the overall Medicare cost of care at a staggering $327 billion in 2017. 3
Among the strongest risk factors for diabetes complications is sustained and uncontrolled hyperglycemia. On a microscopic level, sustained hyperglycemia—the hallmark of diabetes—damages the microvasculature of multiple organ systems in a dose-dependent fashion. 4 To be sure, landmark Diabetes Control and Complications Trial, 5,6 Epidemiology of Diabetes Interventions and Complications, 7,8 and subsequent trials 9 –11 demonstrated that, compared with optimal control, populations with poor glycemic values are at significant risk for kidney disease, neuropathy, vision disability, and cardiovascular disease. Moreover, complications and costs rise exponentially with increased hemoglobin A1C (A1C) values, 12,13 and the consequences may be curtailed if significant hyperglycemia is interrupted. 14 –16 Based on these data, the American Diabetes Association sets the diagnostic threshold for diabetes at a A1C value ≥6.5%. 17
Upstream from diabetes, prediabetes is characterized by impaired fasting blood glucose levels (100–125 mmol/L) and/or A1C levels (5.7%–6.4%), which are below the diagnostic threshold for diabetes. 18 Within this cohort, the 5-year risk of progression to diabetes mellitus is estimated at 25%–50%; however, this event may be curtailed or significantly delayed by diet and lifestyle modifications. 19 Owing to its detrimental impact, valuable insight is gained by the ability to accurately identify which patients are most at risk for progression from prediabetes to diabetes. Yet, to date, there are no broadly adopted machine learning (ML) tools that predict this clinically significant event. Addressing this knowledge gap would aid in identifying high-risk patients within this heterogeneous population who may benefit from targeted treatment and management at an earlier stage in order to preserve glucose metabolism and prevent adverse outcomes.
Against this background, the aim of our study was to leverage longitudinal clinical laboratory data across a geographically diverse cohort and ML methods to develop a readily obtainable risk prediction model for progression from prediabetes to diabetes.
Materials and Methods
Study design and population
The study was reviewed and approved by the institutional review board at Western Institutional Review Board–Copernicus Group. Informed consent was waived because of the lack of feasibility of obtaining consent from all participants and because the data reviewed were deidentified, records-based, and retrospective in nature. The initial study cohort included deidentified data from 330,238 participants from the Northeast, Southwest, Mid-South, and West/Pacific regions of the United States. The overall median age was 62 years old, and 49% of the participants were men.
Biochemical testing for serum glucose, HDL, and A1C were performed on equivalent high-throughput instrument platforms across all testing sites and were standardized according to best practices, including those identified by the National Glycohemoglobin Standardization Program. 20 Disease codes were adopted using the 10th revision of the International Classification of Diseases (ICD-10). 21 The reference intervals were as follows: serum glucose (70–99 mg/dL), A1C (<5.7%), and HDL (>39 mg/dL).
The training and test cohorts were derived from the laboratory information system (LIS) at outpatient facilities within Sonic Healthcare USA. Patients with A1C values between 5.0% and 6.5% and dates of service between January 1, 2017, and December 31, 2021, were included in the study. Outcomes were determined by reviewing records contained in the LIS.
Variables
Candidates were selected based on the availability of sufficient demographic data (e.g., age and sex) and laboratory results. Minimum criteria for inclusion in the study were three A1C values over a span of at least 24 months. Where applicable, slopes for specific variables were calculated using the linear regression function within python sklearn linear model. Slopes were derived from baseline values and adjusted using an annual time interval. The outcome of interest or independent variable was defined as A1C ≥6.5% within 5 years with confirmation.
Statistical analysis
Models were built by creating training and testing datasets, using 80% of the data in training and 20% for independent testing, respectively. The training and testing datasets were stratified to ensure similar patient cohorts. After filtering, a random forest (RF) classifier was built using sklearn version 1.1.1. Ten thousand trees were generated within the models to develop the classifier. An additional 5-fold cross-validation was performed on the training set, and a representative model was used in the testing set to assess the performance. R version 4.2.1 was used to perform additional data wrangling and statistical analysis using the tidyverse packages and the equivalence package for statistical testing. In time-based analysis, events were censored if they occurred before reaching the endpoint. Variable importance was calculated as part of the RF analysis. Candidate variables that were supported by the dataset and demonstrated a meaningful impact to the classifier were reported as a percentage. The predictive accuracy was assessed using the area under the receiver-operator characteristic curve (AUC) on the test set. Calibration was performed using CalibratedClassifierCV from sklearn, and the 95% confidence interval was generated for all models.
Data and resource availability
The datasets generated during and/or analyzed in the current study are available from the corresponding author upon reasonable request.
Results
The initial registry included 330,238 adult patients aged 18–75 years with an outpatient clinical laboratory encounter within the Sonic Healthcare USA network between January 1, 2017, and December 31, 2021. In order to account for the well-established challenge of interlaboratory variation, A1C testing and other biochemical analyses were performed on an equivalent high-throughput instrument platform and standardized according to best practices. 21 Persons with initial A1C <5% or ≥6.5%, fewer than three A1C values over 5 years, ICD-10 code associated with diabetes, and <24 months of follow-up data were omitted from the study.
After applying exclusion criteria, the abnormal A1C dataset contained 15,029 patients (Fig. 1) with a median age of 62 years and an equal distribution between men (49%) and women (51%). The cohort included participants with the following baseline (median) results for A1C (5.8%), HDL (50 g/dL), and serum glucose (98 mg/dL) (Table 1).

Participant flow diagram. The flow diagram depicts the number of adult participants between 18 and 75 years of age in the original dataset prior to removal because of exclusion criteria. Omitted participants included those with <24 months of data, fewer than three A1C results, ICD-10 codes associated with diabetes, and initial A1C <5% or ≥6.5%. The final dataset included 15,029 participants. A1C, hemoglobin A1C; ICD-10, International Classification of Diseases, 10th revision.
Baseline Characteristics
Progression time is defined as the average number of months identified for hemoglobin A1C values ≥6.5% from initial value. Observation time is defined as the average number of months of laboratory data procured for the cohort.
IQR, interquartile range.
Models utilizing eight variables (age, sex, initial A1C, A1C slope, initial serum glucose, serum glucose slope, initial HDL, and HDL slope) with 5-fold cross-validation were trained and tested against ≥6.5% A1C within 5 years. Based on RF survival analysis, the eight-variable model was accurate and achieved an overall AUC of 0.87 (Fig. 2). Utilizing cross-validation output, we generated a normalized histogram of probability given the risk classifier result of either failure (i.e., ≥6.5% A1C within 5 years) or nonfailure. These data demonstrate bimodal distribution with clear separation between failure and nonfailure groups (Supplementary Fig. S1). Accordingly, the positive predictive value (probability of failure) and negative predictive value (probability of nonfailure) within 5 years was 0.91 and 0.89, respectively.
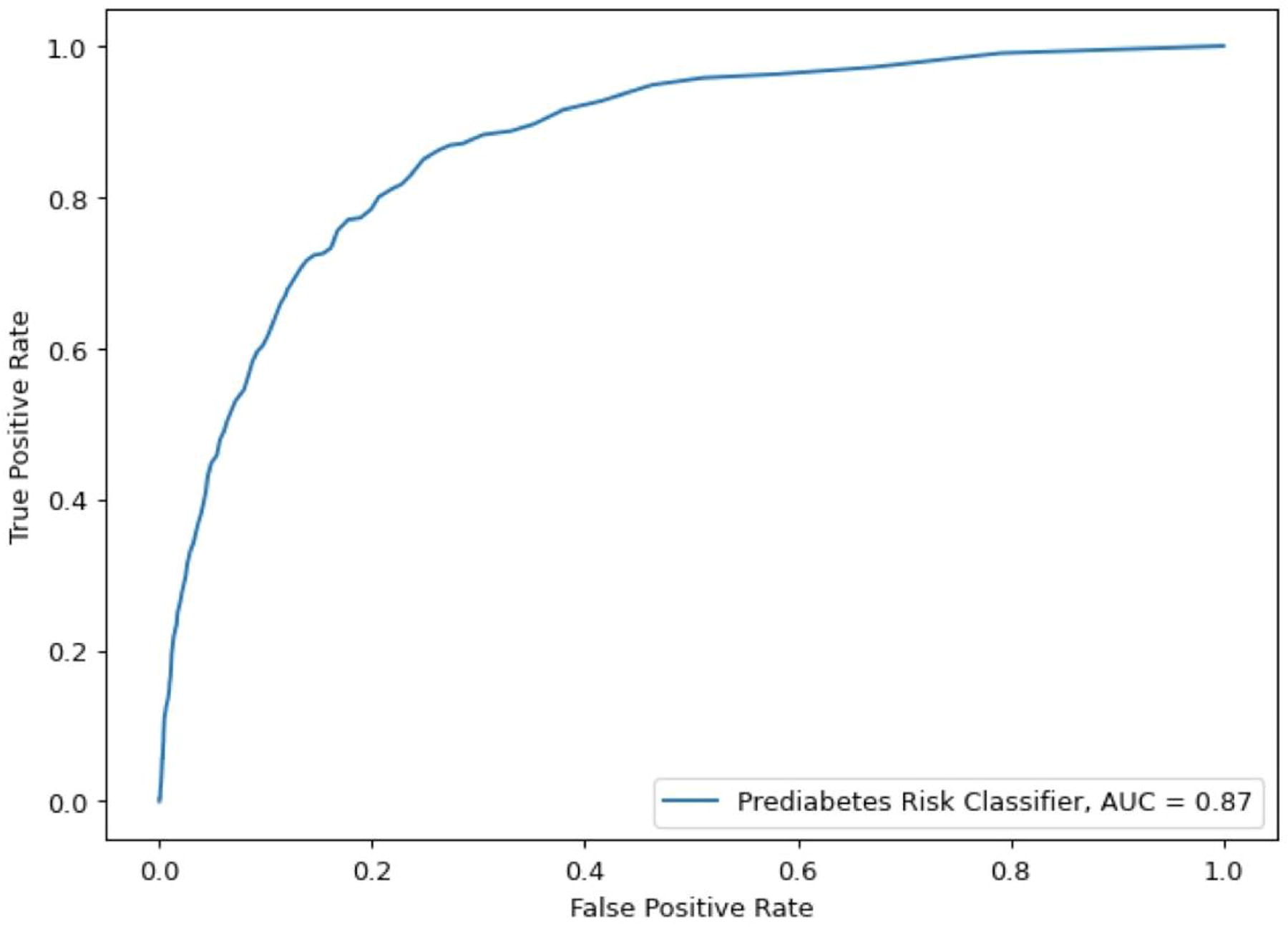
Receiver-operator characteristic curves of classifier models showing prediction performance for ≥6.5% A1C in 5 years.
Further analysis was performed on the prediabetes risk classifier. In sensitivity analysis, the cohort was selected exclusively for minimal (A1C 5.0%–5.5%) and moderate (A1C 5.5%–6.0%) prediabetes, and the performance was similar (AUC = 0.84). For time-to-event analysis, the 95% confidence interval was within 0.01.
Overall, the most meaningful predictors of progression from prediabetes to diabetes were elevated values in the following parameters: initial A1C, initial serum glucose, A1C slope, serum glucose slope, initial HDL, HDL slope, age, and sex (Fig. 3).
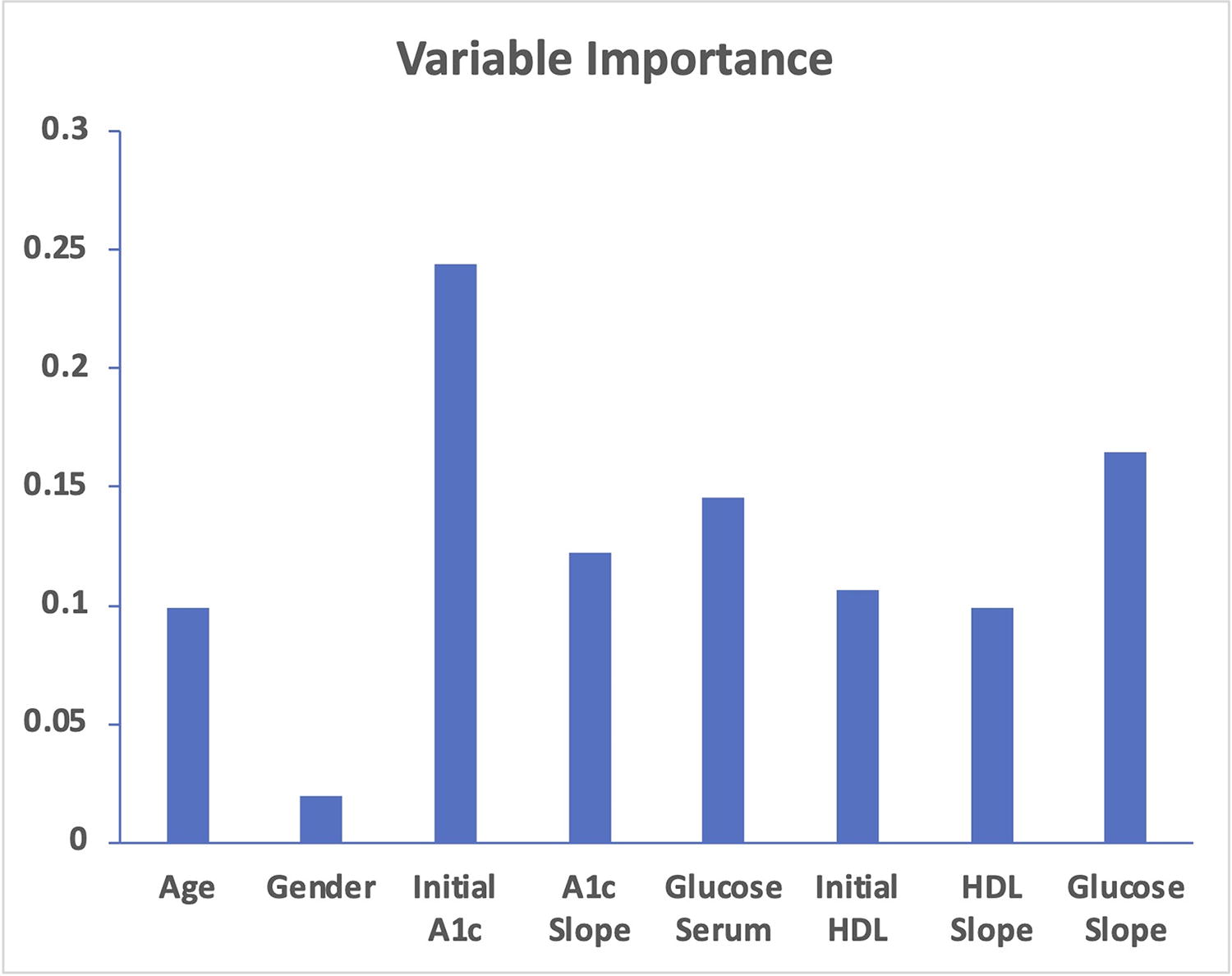
Variable contributions.
Discussion
Leveraging real-world data and ML RF survival analysis, this retrospective cohort study trained and tested a risk prediction model for progression from prediabetes to diabetes among a large, diverse U.S. adult population. Compared with the diabetes progression rate of 25%–50% over 5 years using A1C alone, 19 the performance of the eight-variable ML prediabetes risk classifier represents a substantial improvement with an overall AUC value of 0.87.
The most important predictors were initial A1C, initial serum glucose, A1C slope, serum glucose slope, initial HDL, HDL slope, age, and sex. Somewhat unexpectedly, elevated HDL (initial and slope) accounted for 20% of the prediabetes risk classifier model. Although HDL is well known for its cardioprotective effects, there is a growing body of literature that demonstrates elevated HDL is, in fact, complex and independently associated with deleterious outcomes, including increased cardiovascular mortality, macular degeneration, and dementia. 22 –24 To be sure, recent data by Lee et al. reported that elevated HDL and high HDL variability might be linked to incident diabetes in a Korean cohort. 25 Although further investigation is required, the results herein among a large U.S. population raise the possibility that dysregulated HDL may occur early in the course of disease and/or serve as an important harbinger of progression from prediabetes to diabetes.
This study has several strengths. The first is that the prediabetes risk classifier leverages existing and readily obtainable laboratory information. This feature streamlines predictive risk assignment without sacrificing performance and without relying on parameters that may be subjective and/or cumbersome to acquire in a busy primary care setting (e.g., waist circumference, birth history, and parental history). 26,27 Moreover, it largely obviates the need for esoteric (and often costly) biomarkers. 28,29 The model is also derived from real-world data across a geographically diverse outpatient cohort, which includes participants residing in the Southwest, Northeast, Mid-South, and West/Pacific regions of the United States. Together, these findings enhance the overall usability, cost efficiency, and generalizability of the model.
The final strength of this investigation is that the risk prediction model is based on ML RF survival analysis, which may be better suited to solve complex problems with continuous features. 30 –32 Among continuous variables, serum glucose, A1C, and HDL slope were the most significant contributors to the classifier and, together, account for 40% of the variable importance to the risk classifier. The findings suggest that interpreting these results is best performed on a series of studies rather than in isolation. In addition, the importance of glucose, A1C, and HDL velocity as contributors to predicting progression to diabetes is congruent with a change in relevant laboratory biomarker values over time as a clinically significant event in other disease entities, such as myocardial infarction, chronic lymphocytic leukemia, and chronic kidney disease. 33 –35 Our results underpin an important role for glucose, A1C, and HDL slope in predicting incident diabetes.
Recently, Zueger et al. 36 and Cahn et al. 37 successfully generated risk prediction models for progression from prediabetes to diabetes (AUC = 0.75 and AUC = 0.82, respectively). Although there are similarities, the present study uniquely leverages a large and diverse U.S. population, exclusively utilizes routine laboratory results, and demonstrates improved discrimination (AUC = 0.87). By contrast, the Zueger and Cahn ML models were trained on data procured from an Israeli cohort and relied on up to 48 clinical variables. Moreover, continuous variables (e.g., A1C slope, serum glucose slope, and HDL slope) were not included in the Zueger and Cahn models and may, in part, explain the differences in performance. Taken together, these data underscore the overall success of ML risk classifiers using a variety of independent variables and methods. Indeed, the findings from this emerging field are dynamic, and prospective, head-to-head studies are required to establish the optimal predictive model for progression to diabetes.
There are several limitations to this investigation that should be considered. First, the study cohort defined prediabetes based primarily on laboratory values rather than established clinical diagnosis. However, multiple studies have demonstrated that prediabetes in the general population is frequently undiagnosed. 1 As a result, studies that exclusively rely on clinically confirmed prediabetes and diabetes preclude interrogation of a significant undiagnosed population. Owing to the robust size and inclusion of undiagnosed disease, the findings seen here may be more applicable to the general prediabetes population in the United States. If implemented broadly, it could also improve the overall recognition and diagnosis of disease. Second, the study design did not evaluate important clinical variables, including body–mass index, blood pressure, smoking, marital status, medications, and other risk factors. 38,39 Although incorporating these elements may have improved the accuracy, it would also have added more complexity and, arguably, decreased the overall application and usability of the model. Nevertheless, these limitations raise an important question of how the risk prediction model functions in targeted populations associated with prediabetes. This question and others should be answered in prospective cohorts, enriched for nonlaboratory risk factors linked with progression to diabetes.
Conclusions
Developed and validated using ML analysis in 15,029 patients, the prediabetes risk classifier was accurate and achieved an AUC of 0.87. Compared against the established 5-year risk of progression to diabetes of 25%–50%, the performance of the prediabetes risk classifier represents a substantial improvement over the current standard using A1C alone. The most important predictors of progression to diabetes were initial A1C, initial serum glucose, A1C slope, serum glucose slope, initial HDL, HDL slope, age, and sex. The model was derived from routine demographic and laboratory values in a very large and geographically diverse U.S. outpatient cohort, which strengthens its overall generalizability and usability. To our knowledge, it is the first known ML model derived from a large, general U.S. outpatient population to predict progression from prediabetes to diabetes. Given the rapidly emerging role of novel therapeutics (e.g., glucagon-like peptide 1 receptor agonists and sodium–glucose cotransporter-2 inhibitors) in glycemia management, 40 –42 the ML prediabetes progression risk classifier has the potential to significantly improve timely, cost-effective risk stratification for a heterogeneous prediabetes population at an earlier stage for intervention.
Footnotes
Acknowledgments
The authors thank the leadership, investigators, and participants of Sonic Healthcare USA for their valuable contributions to this study.
Authors’ Contributions
J.A.: Conceptualization, formal analysis, investigation, methodology, and writing—original draft. O.K.: Formal analysis, investigation, methodology, and writing—reviewing and editing. C.K.: Formal analysis, investigation, methodology, and writing—reviewing and editing. Z.N.: Writing—reviewing and editing. J.H.: Conceptualization. M.S.: Conceptualization and writing—reviewing and editing.
Author Disclosure Statement
The authors declare no conflicts of interest.
Funding Information
No funding was received for this article.
Supplementary Material
Supplementary Figure S1
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.