
Abstract
An online experiment (N = 384) examined when and how the identity of the comment moderator (artificial intelligence [AI] vs. human) on a news website affects the extent to which individuals (a) suspect political motives for comment removal and (b) believe in the AI heuristic (“AI is objective, neutral, accurate, and fair”). Specifically, we investigated how the provision of an explanation for comment removal (none vs. real vs. placebic), and opinion congeniality between the remaining comments and the user's opinion (uncongenial vs. congenial) qualify social responses to AI. Results showed that news users were more suspicious of political motives for an AI (vs. human) moderator's comment removal (a) when the remaining comments were uncongenial, and (b) when no explanation was offered for deleted comments. Providing a real explanation (vs. none) attenuated participants' suspicion of political motives behind comment removal, but only for the AI moderator. When AI moderated the comments section, the exposure to congenial (vs. uncongenial) comments led participants to endorse the AI heuristic more strongly, but only in the absence of an explanation for comment removal. By contrast, the participants' belief in AI heuristic was stronger when a human moderator preserved uncongenial (vs. congenial) comments. Apparently, they considered AI as a viable alternative to a human moderator whose performance was unsatisfactory.
Introduction
With artificial intelligence (AI) increasingly taking over various roles and performing tasks once considered to belong exclusively to humans, questions arise as to how people judge and respond to AI differently as compared with humans, what types of tasks are more and less appropriate for AI to perform, and what ethical and legal issues might emerge.1–6 To predict and explain how people interact with AI, scholars have taken a special interest in the so-called machine heuristic, which refers to the generalized belief that “machines are more secure and trustworthy than humans.”7(p1) Considering that people tend to rely on heuristics (i.e., cognitive shortcuts that enable fast judgments) when judging the credibility of information online, 8 machine heuristic is expected to guide how individuals make sense of their interaction with AI.1,7,9
AI and comment moderation on news websites
One area wherein the machine heuristic seems directly pertinent is the moderation of user comments on news websites. Although user comments have become an integral part of online journalism for some years now, their popularity has also raised a host of issues across countries, such as hate speeches, mis/disinformation, and coordinated voting to misrepresent and ultimately sway public opinion.10–15 In response to the mounting public pressure to address the toxicity of comments sections, Naver, the most dominant news aggregator in South Korea, 16 implemented an AI-based content moderation service called CleanBot in 2019, which constantly monitors and hides user comments that violate its guidelines.
What appears to be a well-intended and socially responsible action, however, might invite public resistance and skepticism. Once framed as a virtual public sphere, the comments section often serves as “an ideological battleground, wherein partisans' organized efforts to dominate the space are frequently suspected.”15(p60) Given the exceptionally low level of trust in news media in South Korea, coupled with strong preferences for ideologically congenial news sources, 16 the mega news portal's intervention is likely to raise news users' suspicion about its ulterior motives. The recent Supreme Court's ruling on the illegal attempts to populate the comments sections with pro-government propagandist claims during the 2017 presidential election 17 substantiates such concerns.
If people tend to consider algorithm agents as more objective and impartial in the handling of personal information à la machine heuristic, 7 AI-based comment moderation might alleviate news users' skepticism. Previous research, however, portrays a more complicated picture. For instance, a news story authored by AI (vs. human) activated the machine heuristic, which subsequently mitigated hostile media bias, 1 and AI-based content moderation reduced news users' perception of the bias in news articles. 18 In stark contrast, AI agents that had deleted comments containing hate speech and encouraging civility were perceived as less “just” (measured by perceived fairness, trustworthiness, legitimacy, and unbiasedness), as compared with human agents who had executed the same tasks. 6 When human-authored and AI-authored news articles were compared, Graefe et al. 19 found that articles attributed to human sources were assessed more favorably, directly contrasting Waddell's study. 9
When Do We Treat AI and Human Differently?
One possible explanation for such inconsistent findings concerns the less than robust operation of the machine heuristic, subject to the influence of potential moderators that either facilitate or inhibit it. More important, the unspoken assumption that people would respond to AI and human agents differently needs to be revisited. According to the computers are social actors (CASA) paradigm, 20 people treat computers as if they were humans. To account for the seemingly inappropriate applications of “social” rules and expectancies to “asocial” entities, Nass and Moon 21 invoked mindlessness. When encountering certain cues traditionally associated with humans, such as the use of language, interactivity, and social roles, people mindlessly exhibit social responses. If so, one can predict that the extent to which people respond differently to AI and human moderators would vary depending on how mindful people are in a given situation. To investigate this possibility, we considered two situational factors: (a) the tone of remaining comments and (b) the presence of an explanation for comment removal.
First, people tend to believe that their own behavioral choices and judgments are more common and appropriate than alternative responses (i.e., the false consensus effect 22 ). As such, exposure to several user comments that oppose one's own opinion, which deviates from news users' expectation, would likely prompt them to search for an explanation. 23 Considering that people tend to accept what confirms, rather than disconfirms, their existing beliefs (i.e., confirmation bias 24 ), and thus, examine belief-confirming (vs. belief-disconfirming) evidence less critically, 25 encountering user comments that confirm their own opinion is unlikely to raise questions about the removed comments—after all, that's the way they think it is.
When the remaining comments directly challenge their own position, however, two things are expected to follow. First, one (relatively easy) way to deal with this uncomfortable reality is to blame the biased operation behind the scenes (“Aha! They must have selectively removed those comments that support my side!”). That way, they can reduce dissonance aroused from the exposure to counter-attitudinal comments. Second, as they become more mindful in making sense of the situation, they are more likely to take into account the ontological identity of the moderator (AI vs. human) in their subsequent judgments. That is, rather than mindlessly equating AI with human, as CASA posits, 21 they would become more likely to distinguish between the two entities.
H1: Participants are more likely to suspect political motives for comment removal when the remaining comments are politically uncongenial, rather than congenial to their personal opinion.
H2: Participants are more likely to make different attributions of the human and the AI moderators' comment removal when the remaining comments are politically uncongenial, rather than congenial to their personal opinion.
Another factor that might alter news users' interpretations of the AI-based (vs. human-based) comment moderation is the provision of an explanation. Research has shown that informing (vs. not informing) participants how the algorithm uses personal information collected 26 and how the algorithm arrived at its decision 27 induces greater trust toward the application/service. If so, an explicit explanation for why some comments have been removed should attenuate individuals' suspicion of ulterior political motives. Moreover, such an effect would be greater when the remaining comments are predominantly counter-attitudinal (vs. pro-attitudinal), for they are more likely to trigger motivated attribution of political purposes in the first place.
H3a: Participants become less likely to suspect political motives for comments removal when presented with an explanation (vs. none).
H3b: Such a tendency is more pronounced when the remaining comments are uncongenial (vs. congenial).
At the same time, when presented with an explicit explanation as to why certain comments were removed, people are less likely to heed additional cues to make sense of the situation. They no longer need to second-guess why. By contrast, in the absence of a legitimate explanation, people would become more mindful in their processing of information and consider who moderated the comments in deciding how to respond.
H4: Participants become less likely to attribute the human and the AI moderators' comment removal differently when an explanation is provided (vs. none).
Although explainability has received much attention in the realm of AI (i.e., explainable AI28–30 ), the power of “reason” in gaining compliance is well established in interpersonal contexts, suggesting potentially equivalent effects of the provision of an explanation, regardless of the agent type.31,32 Moreover, Liu 27 found that a placebic explanation consisting of a tautological statement that adds no information reduced uncertainty and enhanced trust toward an online decision-making system only in the human agency, but not in the machine agency condition. Such findings were interpreted as indicating greater scrutiny of information produced by a machine rather than a human, which would suppress the impact of a placebic explanation.
H5: Exposure to a real explanation (vs. no explanation) lowers participants' suspicion of political motives for both AI and human moderators. The suspicion-suppressing effect of a placebic explanation, however, is more likely for a human (vs. AI) moderator.
Lastly, we assessed the possibility that the AI heuristic might not be as uniformly shared as is often assumed. AI heuristic refers to categorical beliefs about key attributes of AI—specifically, AI being objective, neutral, accurate, and fair. Although it taps the same perceptual dimensions of the object as the machine heuristic does, it is limited to AI, rather than technological artifacts in general. Although the machine heuristic seems to be often taken for granted in previous research, the degree to which individuals endorse the AI heuristic would vary contingent on a host of factors, such as media narratives about AI and their personal experiences with AI-based services.
In fact, after seeing an algorithm making occasional errors, participants developed pessimistic beliefs about it and preferred human agents, despite the AI agent's still superior performance (i.e., AI aversion 33 ). If so, more research is warranted that probes what informs “intuitive, informal theories that individuals develop to explain the outcomes, effects, or consequences of technological systems” (i.e., folk theories34 (p3165)), especially because most people have only fairly limited contact with and understanding of AI.
Therefore, rather than treating the belief in AI heuristic as a constant and examining its effects on how people respond to specific AI applications and services, we investigated the reverse possibility: How a brief experience with AI-based content moderation alters user’ endorsement of the AI heuristic. Specifically, we predicted that when the AI moderator retained pro-attitudinal comments and provided a clear explanation for why it had removed certain comments, participants would rate AI in general to be more objective, neutral, accurate, and fair. Observing a human moderator's performance, however, would exert little influence on how they evaluate AI, due to their independent operations.
H6: Participants are more likely to endorse the AI heuristic when the AI agent has preserved congenial, rather than uncongenial user comments. No corresponding effect occurs when the comments were moderated by a human.
H7: Participants are more likely to endorse the AI heuristic when the AI agent has provided an explanation (vs. none) for comments removal. No corresponding effect occurs when the comments were moderated by a human.
Method
A 2 (moderation agent: human vs. AI) × 3 (explanation for comment removal: no vs. real vs. placebic explanation) × 2 (tone of user comments: liberal vs. conservative) between-subjects design experiment was conducted online. Participants were recruited via an online survey company in South Korea (N = 384; 192 females; age M = 39.37, SD = 11.05). This study was approved by the IRB at Seoul National University, Republic of Korea.
All participants viewed three identical news articles on controversial political issues (“impeachment of a conservative judge,” “building a nuclear power plant in North Korea,” “allowing a queer parade in downtown Seoul”) and associated user comments. Among the eight comments presented in random order, two were purportedly “removed” by the moderator. For each “removed” comment, participants were told (a) who had deleted it and (b) why.
Specifically, for the no-explanation condition, it was merely stated that “This comment was removed by a moderator/CleanBot (AI).” For the placebic explanation, a bogus reason was added: “… because it violated the code of conduct.” Lastly, those in the real explanation condition were shown two randomly selected reasons out of three official criteria that Naver News actually uses to moderate its comment section, such as “… because it contained extremely profane and vulgar language” (see Table 1 for the list of statements). The six remaining comments expressed either predominantly liberal or conservative view (5:1 ratio) on the issue. After reading three articles in random order, participants answered post-test questions.
Manipulation of the Moderator's Identity and Explanation for Comment Removal
AI, artificial intelligence.
For the suspicion of political motives for comment removal, we asked participants to list up to three reasons why they thought the comments had been removed. For each open-ended response that the participants provided, two independent coders judged whether the response was related to political causes (e.g., “Because the comment expressed strong political views”; Krippendorff's α = 1.00 for intercoder reliability). We then counted the number of times that each participant mentioned political reasons (0–3, M = 0.37, SD = 0.68). For the belief in AI heuristic,5,18 participants indicated how well they thought the following adjectives described AI (1 describes very poorly; 7 = describes very well): “objective,” “neutral,” “accurate,” and “fair” (α = 0.89, M = 4.22, SD = 1.29). Online news use, the frequency of posting comments on news Web sites, and education were included as covariates to increase statistical power (see Table 2).
Measures and Descriptive Statistics for Covariates
Data were log-transformed due to their positively skewed distribution.
Results
A manipulation check confirmed that participants perceived the tone of comments (liberal vs. conservative) as intended for all three issues, t(382) = 8.46, p < 0.001 for “impeachment”; t(382) = −5.67, p < 0.001 for “nuclear power plant”; and t(382) = −4.49, p < 0.001 for “queer parade.”
Suspicion of political motives for comment removal
We estimated a Poisson regression model with (a) all the main and interaction effects involving the experimental factors and (b) the covariates as explanatory variables (Table 3). Political congeniality was constructed based on the congruency between the participant's political identity (liberal vs. conservative) and the manipulated tone of remaining comments (liberal vs. conservative).
Results of Poisson Regression and Analysis of Covariance
N = 384. For suspicion of political motive for comment removal, contrasts of marginal linear predictions (chi-squared statistics) were obtained from Poisson regression to produce ANOVA-style tests of main and interaction effects.
p < 0.10, *p < 0.05, **p < 0.01.
ANOVA, analysis of variance.
There was no significant main effect of political congeniality on the suspicion of political motives for comment removal (H1), p = 0.742. However, a significant interaction emerged between moderation agent and political congeniality, χ 2 (1) = 5.99, p = 0.014 (see Fig. 1A). Supporting H2, when the remaining comments were incongruent with their political leanings, participants were more likely to attribute political motives to the AI (vs. human) moderator, b = 0.18, 95% confidence interval (CI) [0.01–0.36], p = 0.040. By contrast, there was no significant AI-human differentiation among those who read congenial comments, p = 0.188.
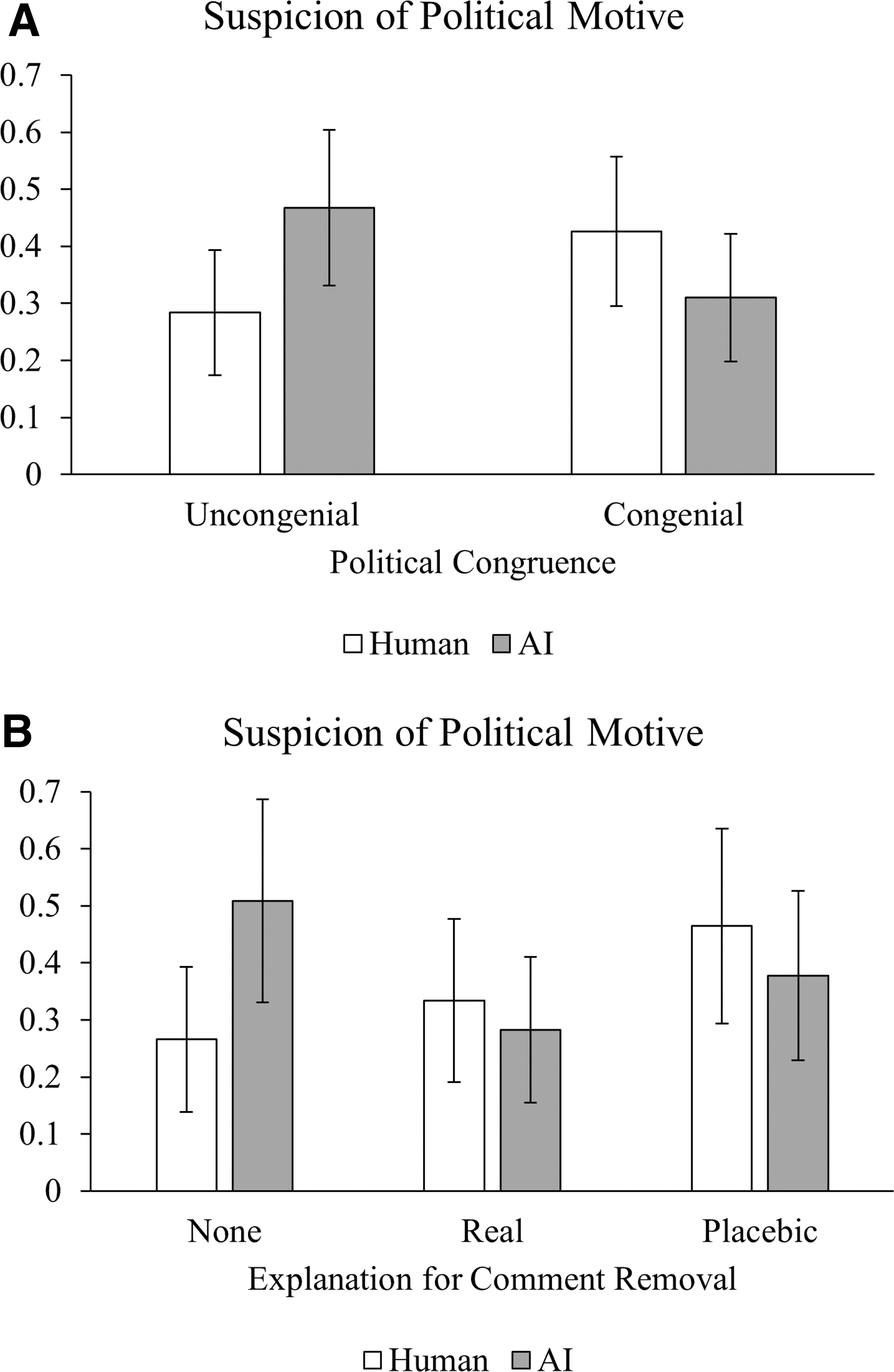
Interaction effects on suspicion of political motives for comment removal [Political Congeniality × Moderation Agent
The provision of an explanation did not have a significant main (H3a) or interaction effect with the tone of remaining comments (H3b), ps > 0.383. Instead, it altered the effect of moderation agent, χ 2 (2) = 6.05, p = 0.049 (Fig. 1B). Specifically, participants exhibited stronger suspicion of political motives when the comments were deleted by AI than by a human, only when no explanation was offered, b = 0.24, 95% CI [0.02–0.46], p = 0.029. With either a real or a placebic explanation, the human-AI difference was not significant, both ps > 0.45. Therefore, H4 was supported.
With respect to H5, when a human moderated the comment section, exposure to a real or placebic explanation (vs. no explanation) did not significantly alter participants' suspicion about ulterior motives, b = 0.07, 95% CI [−0.12 to 0.26], p = 0.488 and b = 0.20, 95% CI [−0.01 to 0.41], p = 0.066, respectively. In contrast, when the moderation agent was AI, the provision of a real explanation (vs. no explanation) lowered participants' suspicion of political motives, b = −0.23, 95% CI [−0.44 to −0.01], p = 0.043. No such effect was found for the placebic explanation (vs. no explanation), p = 0.268. Taken together, H5 was partially supported for the AI condition only.
Belief in AI heuristic
A 2 × 3 × 2 (moderation agent × explanation for comment removal × political congeniality) between-subjects analysis of covariance (ANCOVA) was conducted on the belief in AI heuristic with the same covariates as above (Table 3). A significant interaction emerged between moderation agent and political congeniality, F(1, 368) = 4.00, p = 0.046, ηp 2 = 0.01. In support of H6, when AI moderated the comments, those who viewed congenial comments rated AI as more reliable than those who read uncongenial comments, b = 0.42, 95% CI [0.06–0.79], p = 0.023; when the comments were moderated by a human, however, participants' ratings of AI did not differ as a function of the congeniality of comments, p = 0.576 (Fig. 2A). Because the three-way interaction was marginally significant, p = 0.072, however, we decomposed the interaction for each explanation condition for further analyses.
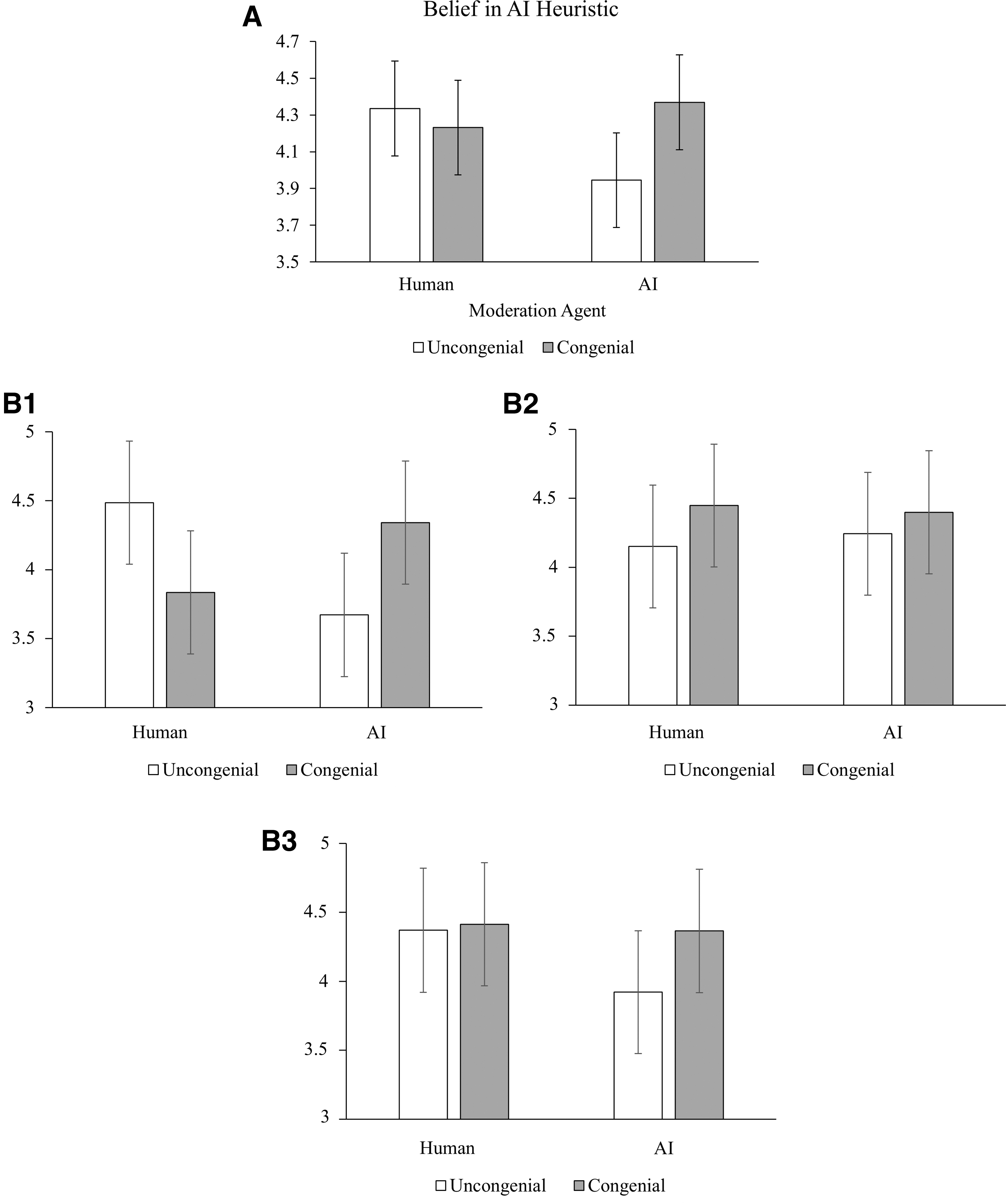
Interaction effects on belief in AI heuristic [Moderation Agent × Political Congeniality
Results confirmed that the moderation agent by political congeniality interaction was significant only in the no-explanation condition, F(1, 368) = 8.34, p = 0.004, ηp 2 = 0.02 (Fig. 2B1). When no explanation was offered for the comment removal by the AI agent, the exposure to congenial (vs. uncongenial) comments enhanced participants' evaluation of AI in general, b = 0.67, 95% CI [0.04–1.30], p = 0.038. However, when the comments were moderated by a human, the opposite was true, with uncongenial (vs. congenial) comments leading to more positive evaluation of AI, b = −0.65, 95% CI [−1.29 to −0.02], p = 0.044. No such interaction emerged when a real or a placebic explanation was presented, ps > 0.381 (Fig. 2B2, 2B3). Lastly, the effect of an explanation for comment removal (no vs. real vs. placebic) did not differ by the moderator's identity (H7), p = 0.694.
Discussion
Overall, the results confirmed some of our predictions while refuting others. First, exposure to uncongenial comments did not automatically trigger participants' suspicion about political motives behind comments moderation, but it led participants to heed the moderator's identity and infer different reasons for comment removal. As Lee's authenticity model 23 suggests, a deviation from expectancy (e.g., seeing mostly uncongenial comments) appeared to prompt participants to scrutinize message-related information, such as who deleted the comments, and subsequently ascribe different degrees of ulterior motives to the AI and the human agents. Interestingly, participants found the AI agent to be more, not less, suspicious than its human counterpart, showing “algorithm aversion” 33 in the face of undesirable outcomes.
Likewise, telling people why certain comments were removed did not uniformly make people trust in the moderator's good will. Instead, the provision of an explanation, regardless of its substance, had the effect of closing the trust gap between the human and the AI agents that existed when no explanation was given. Further analyses revealed that (a) the provision of an explanation reduced suspicion only for the AI moderator but only when (b) the explanation specified on what grounds some comments were removed.
Unexpectedly, when the human moderator presented a placebic explanation, it backfired as participants became more suspicious of the hidden motives than when no explanation was given altogether. On the one hand, these findings underscore the importance of designing explainable AI to build trust in the technological system. On the other hand, there seems to be no one-size-fits-all approach that works for both human and AI moderation systems.
Despite a large volume of research engaging with the notion of machine heuristic, relatively little is known about its formative basis. Our findings indicate that individuals' direct experience with AI does alter their belief in AI heuristic. When AI moderated the comments section, the exposure to congenial (vs. uncongenial) comments induced stronger endorsement of the AI heuristic, but only in the absence of an explanation for comment removal. Interestingly, even without any reference to AI, when a human moderator presented mostly uncongenial comments, participants evaluated AI more favorably, suggesting that they considered AI as a potential alternative to a human moderator whose performance was not satisfactory.
Some limitations deserve note. First, the placebic reason might not have been considered as entirely tautological; that is, removing some comments that violated the code of conduct can be seen as a sufficiently reasonable and legitimate action, although being a tad underspecified. If so, it is not surprising why the real and placebic reasons elicited similar reactions to the AI moderator. Second, we theorized that the provision of an explanation and the congruency of remaining comments would suppress the likelihood that people treat AI and human moderators differently, as people would be less motivated to process messages critically and thoroughly. Although the results supported our predictions, the presumed mechanism was not directly tested. To better understand not just when and how people interact with AI differently than humans, but why they do so, future research should examine the underlying psychological processes, with unambiguously placebic explanations.
In sum, our findings show that people's understanding of and responses to the AI comment moderator can take different forms and shapes depending on situational triggers that prompt mindful information processing. Departing from previous research supporting the operation of machine heuristic, we found differential reactions to the AI and the human agents only when participants were more strongly motivated to make sense of the situation. Moreover, when they distinguished between the AI and the human agents, they were more, not less, suspicious of the AI agent's ulterior motives, suggesting the possibility that blanket optimism about AI as the state-of-the-art technology might have started to dissipate in the face of different voices. At the same time, participants seemed to spontaneously consider AI as a replacement for a human moderator who produced disappointing outcomes, with no explanation. All in all, the current research once again highlights the importance of transparency, especially for AI-based moderation systems, not just for ethical reasons, but also for trust-building that is essential for the acceptance and continued use of such systems.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2021S1A5B8096358) and the Institute of Communication Research at Seoul National University.