
Abstract
INTRODUCTION
Whole Genome Duplications (WGDs) are evolutionarily far-reaching events in which the content and structure of a genome is doubled. There are lineages with multiple known WGD events (Dehal and Boore, 2005) and WGDs are typically followed by large-scale loss of genetic content (Scannell et al., 2006).
For genome rearrangement studies, the classic framework for analyzing WGD events is the Genome Halving Problem (GHP). Broadly speaking, the task formulated by the GHP is, given a present-day genome, to reconstruct a genome with the specific structure that is expected to arise after a WGD. This genome is required to have the minimal distance under some rearrangement model to the given present-day genome. A popular rearrangement model is the Double-Cut and Join (DCJ) model (Yancopoulos et al., 2005; Bergeron et al., 2006). This model has been applied to the GHP by Mixtacki (2008), but as a pure rearrangement model, this solution was not able to account for the losses frequently observed after WGD events. Savard et al. (2011) were able to provide a solution to the GHP under DCJ that accounts for lost markers, but not for the loss event itself, meaning they were not able to account for its contribution to the distance. This is likely due to the fact that the DCJ-Indel model, which accounts for costs of segmental Indel events, was only first formulated around the same time (Braga et al., 2011).
Another issue is the limitation of GHP solutions on input genomes with markers occurring at most two times. So far, there are multiple publications addressing this problem in a distance context (Shao et al., 2015; Bohnenkämper et al., 2021), but with many examples of multiple rounds of WGDs and other duplication events occurring in tandem, we can expect markers to occur more than two times in many practical GHP scenarios. We call these markers with more than two occurrences ambiguous, and genomes with arbitrary distributions of markers natural genomes.
The need for theoretical inclusion of natural genomes in the context of WGDs has been recognized by Avdeyev and Alekseyev (2020), who created an approximate solution for a generalized variant of the GHP. However, as far as we are aware, no exact solutions for the GHP under the DCJ-Indel model have been proposed as of yet.
In Sections 2 and 3, we develop a simple view on the DCJ-Indel model that can be derived independently from the ones presented in Braga et al. (2011) and Compeau (2013). We apply this conceptualization to solve the GHP for genomes without ambiguous, but lost or gained markers in polynomial time in Section 4. We note that the GHP is NP-hard for natural genomes under the DCJ-Indel model. Therefore, we give an integer linear program (ILP) to solve the generalized problem for natural genomes in Section 5. We evaluate the ILPs performance in Section 6 on both simulated and real data.
PROBLEM DEFINITION
For the purposes of this work, we view a genome
Each path in

Genome with one circular and two linear chromosomes. Adjacencies are drawn as double lines.
Each marker is unique, so to find structural similarities, we borrow a concept from biology, namely homology. We model homology as an equivalence relation on the markers, that is,
We now introduce the Supernatural Graph (SNG), a graph structure that will be useful later and meanwhile illustrates our conceptualization of homology.
This graph is a variant of the natural graph as used in Mixtacki (2008) with the difference that adjacencies are modeled as edges instead of vertices and the possibility of more than one homolog per extremity. An example of an SNG can be found in Figure 2.
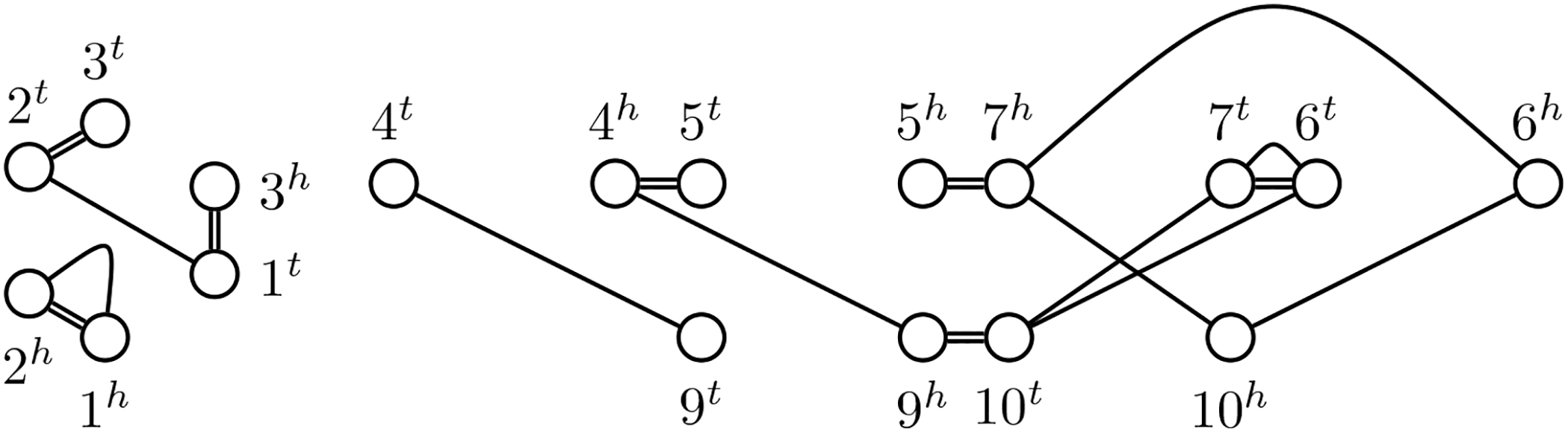
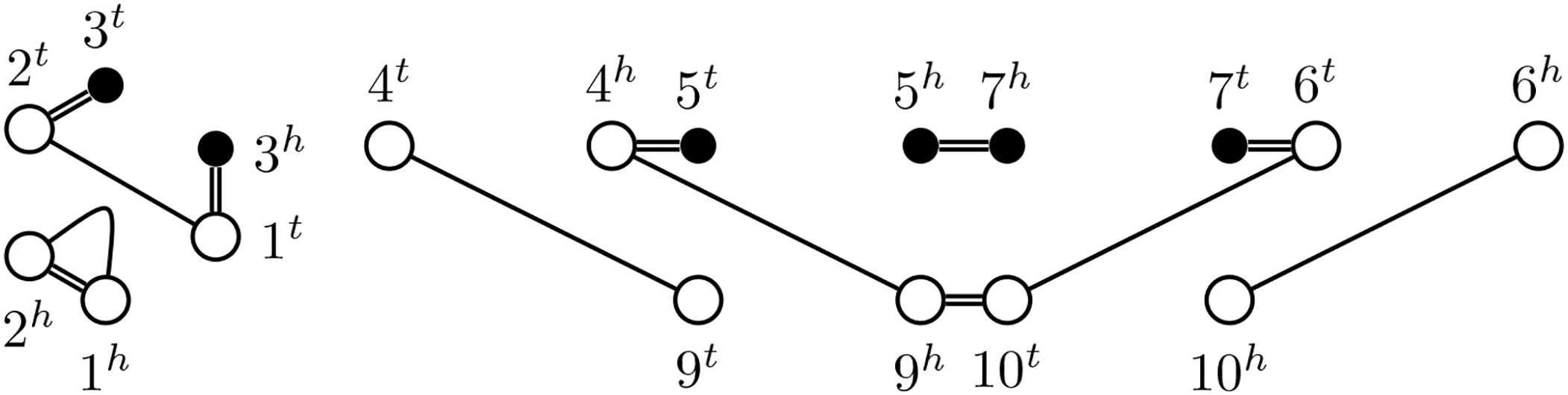
Genomes following a WGD possess a very particular structure due to the nature of this event. Not only is its marker content duplicated, but also its adjacency information is preserved. On some homologies this is easy to detect, namely if each family contains at most two markers. We call such homologies resolved. For more complex homologies, it is helpful to find an artificial resolved homology, called a matching.
We note that when the homology is resolved, at most one extremity edge connects to each vertex in the SNG. Because adjacencies form a matching on the extremities, the resulting SNG consists of only simple cycles and paths. We, therefore, call such an SNG simple. An example is given in Figure 3. We also note that the simple SNG
A genome resulting from a WGD is called structurally doubled (SD). To formally define that each marker as well as adjacency information is doubled, we define it in terms of a matching.
Note that for a resolved homology, this definition corresponds directly with the definition of a perfectly duplicated genome as in Mixtacki (2008). We give an example of an SD genome in Figure 4.
The genome 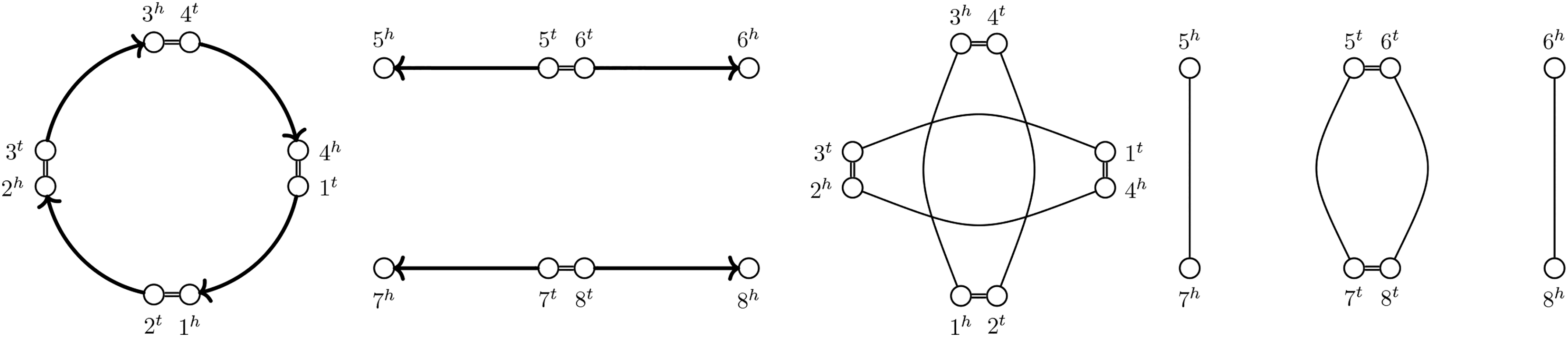
Over time this specific structure after a WGD is typically erased by rearrangements and losses. Rearrangements in our transformation distance are modeled by the Double-Cut and Join (DCJ) operation. In principle, a DCJ operation cuts in two places (adjacencies or telomeres) in the genome and reconnects the incident extremities. More formally, we can write as in Bergeron et al. (2006):
To account for losses or possibly gains following a WGD, we introduce segmental insertions and deletions.
A deletion of length l removes the chromosome segment
To reconstruct an SD ancestor to a present-day genome, we require this ancestor to be as closely related as possible under our model. We define the GHP first as an abstract problem with an arbitrary set of operations.
 We call
We call
For the DCJ-Indel model, the operations used are DCJs (Definition 4) and Indels (Definition 5) of arbitrary length. Initially, any sequence of DCJs and Indels is legal. However, we will soon see that it makes sense to restrict legal scenarios to avoid an excess of Indels.
We call
The original DCJ-Indel model allowed Indel operations only for singular markers, in that only singular markers could be deleted and at most one homolog of a singular marker could be inserted (Braga et al., 2011). When restricting legal scenarios in Problem 2 to only include such Indel operations, we speak of the restricted halving distance. For a resolved homology
Note that the restricted halving distance only works properly for a resolved homology, because in an unresolved homology, ambiguous families with odd numbers of markers cannot be dealt with. However, we can use a matching to circumvent this problem. Since being SD implies a matching
A typical issue that arises in these types of problems once one introduces segmental insertion and deletion operations is that without restrictions, the shortest way to sort is often by just deleting one genome and inserting another, resulting in an empty matching. We, therefore, work within an established framework, namely Maximum Matching (Fertin et al., 2009).
We can then formulate the GHP for the Maximum Matching model as follows:
For resolved homologies
A proof for this proposition based on Caprara's alternating cycle decomposition problem (Caprara, 1997) is given in Bohnenkämper (2023b, section D).
This proof, but also our derivation of the halving distance formula, relies heavily on properties of the SNG. These properties are shared with other data structures, such as the Multi-Relational Diagram in Bohnenkämper et al. (2021). To make our results as reusable as possible, we start by making observations about a generalized version of the SNG:
Similar to the SNG, we refer to rearrangement graphs with at most one extremity edge connecting to each vertex as simple. Because then
In this section, we examine the general properties of rearrangement graphs, which we will later use in Section 4 to derive our result on the halving distance. We denote the universe of simple cycles and paths by
We will characterize DCJ and Indel operations by their effects on different quantities, such as cardinalities of component subset instances. To that end, we define the following:
Before we can characterize the effect of different operations, we need to distinguish between different component subsets by different characteristics, such as the genome of certain vertices or the number of extremity edges. We use a similar distinction as in Compeau (2013). We call a component odd if the number of extremity edges it contains is odd and even otherwise. We denote the component subset of all cycles by
We denote the subset of even paths of this kind by
Classification of components in a simple SNG. Lava vertices filled black.
To not create chimeric genomes, we only allow operations if all vertices involved have the same genome label. We can then conceptualize a DCJ operation not as an operation
We notice that this can be generalized for any number of component subsets as long as they are disjoint.
Cycles form a special case of Observation 1. Notice that a DCJ operation with a cycle C and another component K as sources will always integrate the cycle into K, forming a composite component
The only DCJ operations reducing the number of cycles in a rearrangement graph are of the form C, K → K′, or C → PXX. Squiggled lines represent arbitrary paths in the graph.
We also notice that the cardinality of the more specific component subsets of even and odd cycles can only be reduced in the same manner. All DCJ operations have an inverse. Therefore, the only operations increasing the respective cardinalities must be the “mirror image” of those seen in Figure 6.
For even cycles, things are even more specific. In this case, for
Next, we observe that DCJ operations affect only adjacency edges, so lava vertices in sources are transferred to resultants. Thus, at most one viaduct can be among the resultants of an operation with a lava vertex in its sources (see also Fig. 7).
DCJ operations involving at least one pier or pontoon as a source have at least one resultant that is a pier or pontoon.
 the number of any type of viaduct can increase by at most 1, that is,
the number of any type of viaduct can increase by at most 1, that is,  for any genomes
for any genomes
Pontoons contain two lava vertices, which are distributed to both resultants (see also Fig. 8). Thus, if their number is reduced, the number of viaducts cannot increase.
DCJ operations with a pontoon as a source either result in two components with at least one lava vertex each or a pontoon and a cycle.
 the number of any type of viaduct does not increase, that is,
the number of any type of viaduct does not increase, that is,  for any genomes
for any genomes
Lastly, a DCJ operation cannot change the number of extremity edges in the components it affects. Thus, the total parity of sources and resultants of a DCJ operation is preserved. To capture this, we use the notation
 holds
holds
We have so far thoroughly investigated the effects of the DCJ operation. We now briefly touch on Indel operations. Since we have seen in Problem 3 that we can reformulate the GHP, such that only singular markers have to be part of Indels, we permit only deletions removing lava vertices or insertions creating homologs for lava vertices. First, we study only the deletion of a single marker and the insertion of a single adjacency, which refer to as uni-Indels collectively. While a uni-Indel deletion is always a legal operation under the DCJ-Indel model, a uni-Indel insertion is not necessarily legal. However, we will soon see that they are useful for describing insertions, so we permit them as an intermediate step of an incomplete insertion. Both types of uni-Indels remove two lava vertices from the graph and connect their adjacent vertices into one component. The similarity is visualized in Figure 9. Since the number of extremity edges is changed by 2 if at all, the total parity is again conserved.
Uni-indels transform the rearrangement graph in similar ways, joining two paths ending in a lava vertex into a path or cycle (if 

for some genomes
We can conceptualize a deletion of l markers as first summarizing the stretch of markers only separated by
We can conceptualize an insertion of l markers as first inserting the circular chromosome
 and a DCJ operation d on the same rearrangement graph for which holds
and a DCJ operation d on the same rearrangement graph for which holds
We now have all ingredients to address the GHP for a resolved homology. Similar to Compeau (2013), the following can be shown as in Bohnenkämper (2023b, section A.2).
where
Circular singletons can therefore be dealt with in preprocessing and we need not consider them from now on. We start by establishing a lower bound for the problem without circular singletons.
where
Recall that
We start our proof of Proposition 3 by showing the following:
Proof. If there are no singular markers, H reduces to
which is the DCJ halving formula by Mixtacki (2008) and, therefore, has already been shown to be 0 if and only if
We observe that DCJ operations can change H by at most 1.
Proof. DCJ operations do not affect n. As we have seen in Observation 3, if
Together with Corollary 1, we are able to derive
We see that the only way the numerator  From Observation 6, we know that
From Observation 6, we know that  from which follows
from which follows  and therefore
and therefore
We are left to examine the effect of Indel operations. Regarding Observation 7, we see that a uni-Indel either concatenates two piers or pontoons, thereby possibly creating a viaduct or a cycle from an even pontoon. From this follows that a uni-Indel u has either
Conceptualizing insertions as an insertion of a circular chromosome followed by a DCJ (see Observation 9), we see that the insertion of a circular chromosome with l markers increases n by l. On the other hand, the l uni-Indels creating its adjacencies decrease
Altogether, from Observations 11 and 12, and Propositions 4 and 5 follows Proposition 3.

We give a sorting algorithm that attempts to achieve the lower bound given in Proposition 3 in Algorithm 1. Every step in the algorithm is conceived as a DCJ operation  instead. If creating Z would generate a circular singleton, we simply replace the operation by the deletion
instead. If creating Z would generate a circular singleton, we simply replace the operation by the deletion
We now regard the assertions written as comments. Most assertions in the algorithm simply follow from the preceding while-conditions. Only the assertion in Line 18 might need some clarification. Each linear chromosome of a genome ends in two telomeres, each of which is associated with exactly one pier and vice versa. Therefore, the number of piers is always even. Since there is only one type of pier in the graph at that point (see Line 17), the number of that type must be even.
Our algorithm reduces H by 1 in almost every step by either having
Changes to Terms of H in Algorithm 1
The only step that does not guarantee
where
Proof. Algorithm 1 shows that Theorem 1 is an upper bound on the halving distance. What remains to be seen is whether it is a lower bound as well.
We write
(I) For the first, let us presume that after the operation,
(II) Let us now presume that after the operation still
1. Let
2. For
We thus see that in all cases for DCJ operations holds
For uni-Indels, we see using Observation 7 that to reduce
Since
We will now generalize what we have seen in Section 4 to arbitrary homologies, that is, natural genomes. Since the GHP under DCJ-Indel and Maximum Matching is NP-hard for this case, we give an ILP solution for the problem. Because of the fairly simple distance formula derived in Section 4, our ILP works without computing a capping, that is, the circularization of linear chromosomes. This is in contrast to similar solutions of other problems (e.g., Shao et al., 2015 or Bohnenkämper et al., 2021). The advantage is that the size of our ILP is linear with respect to the number of linear chromosomes, while solutions relying on capping grow quadratically in the number of linear chromosomes, which leads to a dramatic increase in the search space (Rubert and Braga, 2022).
We give the constraints of the ILP, named hang for halving natural genomes in Algorithm 2 and its domains in Table 2.
Domains for Algorithm 2
Domains for Algorithm 2
To avoid edge-cases, such as paths containing only single vertices, we nonetheless need to make a modification to the supernatural diagram described in Section 2. First, we add an additional vertex
Like the aforementioned solutions to other problems, our halving solution solves the problem by finding a matching (see Problem 3) on the given homology that minimizes the resulting halving distance. We have seen in Section 2 that this is equivalent to finding the minimally scoring consistent decomposition of the corresponding SNG. The term consistent in the literature refers to the fact that an extremity edge


An efficient encoding for consistent decompositions in ILP form was found by Shao et al. (2015) and extended upon for losses in Bohnenkämper et al. (2021). We build upon their solutions and include this general framework as Constraints C.01 to C.05. The constraints compute a consistent decomposition and label each edge e with
We also adapt the way of counting circular singletons from earlier works in Constraints C.33, C.34.
In contrast to Bohnenkämper et al. (2021), we ensure the enforcement of the maximum matching model with a constraint by allowing at most one marker to be deleted if the corresponding family is of odd size (C.06).
The remaining constraints aim to distinguish the different component types (as previously visualized in Fig. 5) from each other. To that end, we define the following binary “report variables” for each adjacency edge e:
First, we introduce a variable av that identifies telomeres (or more precisely, pseudo-caps) by being set to 0 at a pseudo-cap (see C.07) and to 1 at a lava vertex (see C.08). We require this variable to be “passed” through the edges of a component, which is, we require the variable to be the same for two vertices connected by an active edge (see C.09). We only allow a change in this variable within a component if reporting a pier (C.10).
The a variable allows us to detect path type based on endpoints, that is, we could now distinguish between viaducts, piers, and pontoons. However, we still need parity to definitely distinguish all types of components. To determine parity, we introduce a variable bv, which is 0 at the end of a path (see C.11, C.12) and flips upon crossing an extremity edge (see C.13). For adjacency edges, we again require the b-variables to be the same, except when reporting an odd component type (C.14).
We now need to ensure that no path of type Z could be reported as another type
To ensure components with negative influence are only reported once, we only allow them to be reported at a reporting vertex (see C.15). Note that because there is no reporting vertex in components with lava vertices, this constraint also removes the possibility to report a pier or pontoon as a component with negative contribution to
We also ensure that no even component could be reported as an odd component by requiring b-variables to be different when reporting odd components (see C.16). Note that odd components can already not be reported as even ones as they require the b-variable to flip along at least one adjacency edge in the component.
To avoid paths being reported as cycles, we require there to be no telomeres when reporting cycles (see C.17). To avoid report variables being used to alter parity or a-variables in components without lava vertices, we require that no z variables are set by setting the y variables of the component to 0 (see C.18).
Finally, to canonize where components will be reported, we require viaducts and pontoons be reported at the telomere end (see C.19) and restrict the reporting of pontoons at the lava vertex (see C.20). This requires pseudo-caps to have lower indices than regular vertices (
Constraints C.21 to C.29 then summarize the reports to the terms found in the formula.
To set the variable
Note here that the solver can also find an alternative solution where it can increase
The ILP has a linear number of constraints and variables with respect to the size of the graph with the vast majority of variables being binary variables.
We implemented the ILP introduced in Section 5. The program as well as the evaluation pipeline can be found here: https://gitlab.ub.uni-bielefeld.de/gi/hang.
Simulated data
To evaluate the ILP's performance on genomes with varying characteristics, we extended the simulation program introduced in Bohnenkämper (2023b) to handle simulating arbitrary trees as well as WGDs. For all of our simulations, we used the same linear tree topology, given in Newick format here:
We always set the number of operations to be performed branches R to S and D to G to be the same, but set the deletion rate to 0 on branch R to S as deletions would not have any impact on the scenario before the WGD.
Our default simulation parameters were 5000 markers on one linear chromosome for R, 2500 operations performed from D to G with operations performed according to the following rates relative to the number of DCJs: An insertion rate of
To obtain ILP solutions, we used gurobi-10.0 running on a single thread on an AMD EPYC CPU on a virtual machine with a set time limit of 1 hour (3600 seconds).
For our first experiment, we examined the influence of the genome size on the ILP performance. To that end, we simulated root genomes (R) of sizes 1000 to

ILP solving times for:
Arguably the strongest influence on the size of the solution space is the number of extremity edges in the graph, that is, the number of ambiguous markers in the genome. We, therefore, performed an experiment varying the duplication rate in the simulation from
Another factor we can expect to influence runtimes is the complexity of the resulting supernatural diagram, that is, the length and nesting of the paths and cycles of its decompositions. Since this complexity rises with more rearrangements applied on the branch after the WGD, we performed an experiment gradually increasing the total number of rearrangements, Indels, and duplications performed from 100 to 4000. The runtime results are found in Figure 10C. We observed a similar, if not more drastic increase in solving times in this experiment, with even 33 samples of the last tier exceeding the time limit.
Compared with related ILPs, such as that in Bohnenkämper et al. (2021), hang does not perform as well as expected. While its size scales linearly with the size of the graph, we hypothesize that the SNG of a natural genome is on average more complex than the graph data structure used for distance comparisons of a pair of natural genomes. For example, the graph used in Bohnenkämper et al. (2021) is bipartite with respect to extremity edges, possibly leading to less nested structures from ambiguous markers.
To test the accuracy of the halving distance calculated by hang, we retained the optimal solutions of the last experiment and compared the calculated halving distance to the simulated distance. This evaluation is shown in Figure 11. We see that for low distances hang calculates results very close to the simulated number of operations before tapering off to be consistently below the simulated distance. Notably, the variance of the calculated distances is small compared with the deviation from the simulated distance. This effect is reminiscent of the behavior of classic sequence edit distances, in which back mutations and similar effects shorten the minimal edit distance while the actual evolutionary distance grows. Given that this effect can be corrected for in classic edit distances, we conjecture that this could be done for halving distances as well if one finds a sufficiently powerful statistical modeling of DCJ, Indel, and duplication operations. However, one possible obstacle for this statistical correction is likely the dominance of losses after a WGD, which might more strongly obscure rearrangements in real data.

Number of simulated operations compared with the halving distance as calculated by hang. The line shows the identity function.
Overall, our simulated experiments show that the performance of hang is reasonable as long as not too many rearrangement events occurred after the WGD, although not as high as one would expect from related ILPs. Moreover, the calculated halving distances can be meaningfully interpreted, provided the effect of marker losses can be bounded.
To evaluate the efficacy of our method in practice, we analyzed a real example of a WGD.
We, therefore, downloaded the GenBank files of three yeast genomes known to have undergone a WGD before diverging (Scannell et al., 2006), namely those of Saccharomyces cerevisiae, Naumovozyma castellii, and Nakaseomyces glabratus. We proceeded to extract the longest coding sequences using a script of the software package FFGC (Doerr et al., 2018) and performed an all-vs-all BLAST (Altschul et al., 1990) comparison. We retained hits with an e-value of
We let our software create the ILPs and calculated solutions using gurobi-10.0 with 10 threads and a time limit of 9 hours on an Intel Xeon E7540 CPU.
The results are shown in Table 3. For two out of three runs, gurobi found an exact result within the time limit and an approximate result with a gap of
Genome Assemblies and Basic Statistics for the Three Taxa Used in Our Experiments
Genome Assemblies and Basic Statistics for the Three Taxa Used in Our Experiments
#amb. f., the number of ambiguous families, #markers, the number of coding sequences used as markers; #non-sing., the number of nonsingular markers; Assembly, Accession.version; gap, the gap reported by gurobi upon reaching the time limit; max. fs., the maximum family size; obj., the halving distance calculated as the objective by gurobi; Taxon, the taxon name.
Comparing the numbers of nonsingular markers, we can see that while all genomes consist mainly of singular markers, N. glabratus has a particularly low number of nonsingular markers. This is relevant, because—as in many rearrangement studies—the number of rearrangements detectable by the DCJ-Indel model in the halving problem is limited by the number of markers in the resulting matching. This can be seen by noting that the positive terms in the formula that do not depend on the number of chromosomes, namely n and
One possible solution to this problem might be an affine cost model that scores both the number of Indel operations as well as the length of the segments deleted.
After presenting some general statements about a generalization of simple SNGs, we were able to derive a compact formula for the halving distance under the DCJ-Indel model that can be computed in polynomial time for genomes with resolved homology. We note that the problem is NP-hard on arbitrary homologies. However, due to its compactness, the formula is generalizable into an ILP for natural genomes.
The ILP performs reasonably well on simulated genomes up to a few 10,000 markers, provided the genomes contain not too many duplicates and are not strongly rearranged. For real genomes the approach looks promising at least in terms of performance, although care needs to be taken in interpreting its results, particularly if the genome in question lacks sufficient nonsingular markers.
Footnotes
ACKNOWLEDGMENTS
The author thanks his Master Thesis supervisors, Jens Stoye and Marília D.V. Braga, for their helpful comments in discussions regarding notation, terms, and the overall structure of the article. Thanks also to Diego Rubert for pointing the author to the book by Fertin et al. Lastly, he thanks Daniel Doerr for making him switch from water to lava and for suggesting the catchy first part of this work's title.
AUTHOR'S CONTRIBUTIONS
L.B.: Conceptualization, methodology, software, investigation, and writing.
AUTHOR DISCLOSURE STATEMENT
The author declares there are no conflicting financial interests.
FUNDING INFORMATION
This work was supported by the BMBF-funded de.NBI Cloud within the German Network for Bioinformatics Infrastructure (de.NBI) (031A532B, 031A533A, 031A533B, 031A534A, 031A535A, 031A537A, 031A537B, 031A537C, 031A537D, and 031A538A).