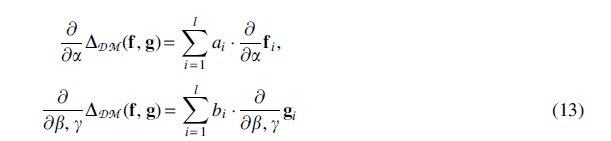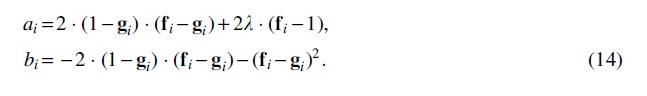Minimizers are widely used to sample representative k-mers from biological sequences in many applications, such as read mapping and taxonomy prediction. In most scenarios, having the minimizer scheme select as few k-mer positions as possible (i.e., having a low density) is desirable to reduce computation and memory cost. Despite the growing interest in minimizers, learning an effective scheme with optimal density is still an open question, as it requires solving an apparently challenging discrete optimization problem on the permutation space of k-mer orderings. Most existing schemes are designed to work well in expectation over random sequences, which have limited applicability to many practical tools. On the other hand, several methods have been proposed to construct minimizer schemes for a specific target sequence. These methods, however, only approximate the original objective with likewise discrete surrogate tasks that are not able to significantly improve the density performance. This article introduces the first continuous relaxation of the density minimizing objective, DeepMinimizer, which employs a novel Deep Learning twin architecture to simultaneously ensure both validity and performance of the minimizer scheme. Our surrogate objective is fully differentiable and, therefore, amenable to efficient gradient-based optimization using GPU computing. Finally, we demonstrate that DeepMinimizer discovers minimizer schemes that significantly outperform state-of-the-art constructions on human genomic sequences.
1. INTRODUCTION
Minimizers (Roberts et al, 2005; Schleimer et al, 2003) are k-mer sampling methods from a sequence such that sufficient information about the identity of the sequence is preserved. Minimizers are widely used to reduce memory consumption and run-time in bioinformatics applications such as genome assemblers (Ye et al, 2012), read mappers (Jain et al, 2022; Li, 2018), and k-mer counters (Deorowicz et al, 2015; Erbert et al, 2017).
Given a choice of k-mer length k, a window length w, and a total ordering over all k-mers, a minimizer scheme selects the lowest priority k-mer from every overlapping window in the target sequence according to . We typically measure minimizer performance by its density (Marçais et al, 2017) on a target sequence. Although alternative measures of performance are available (Edgar, 2021; Hach et al, 2012), this article will only focus on the density performance metric.
The choice of has been known to significantly impact the resulting density on the target sequence. The theoretical lower-bound of density achievable by any minimizer scheme is given by (Schleimer et al, 2003). On the other hand, a random initialization of will yield an expected density of (Marçais et al, 2017; Schleimer et al, 2003), which is frequently used as a baseline for comparing minimizer performance. This motivates the question: How do we effectively optimize to improve the performance of minimizers?
Exhaustively searching the combinatorial space of suffices for very small k, but it quickly becomes intractable for large values of k used in practice (e.g., ) (Section 3.1). To work around this, many existing approaches focus on constructing minimizer schemes from mathematical objects with appealing properties such as universal hitting sets (UHS) (Ekim et al, 2020; Marçais et al, 2018; Marçais et al, 2017; Orenstein et al, 2017; Zheng et al, 2020). Although these schemes provide upper-bound guarantees for expected densities on random sequences, they only obtain modest improvements over a random minimizer when used to sketch a specific sequence (Zheng et al, 2020).
Learning minimizer schemes tailored toward a target sequence has been previously explored, although to a lesser extent. Current approaches include heuristic designs (Chikhi et al, 2016; Jain et al, 2020), greedy pruning (DeBlasio et al, 2019), and construction of k-mer sets that are well spread on the target sequence (Zheng et al, 2021). However, these methods only learn crude approximations of by partitioning k-mers into disjoint subsets with different priorities to be selected. Within each partition, the relative ordering among k-mers depends on the choice of heuristic tie-breaking method (e.g., lexicographic or random). Hence, the resulting minimizer schemes are not necessarily optimal. We give a detailed overview of these methods in Section 2.
This article instead tackles the problem of directly learning a total order . We note that the difficulty of this task comes from two factors, which we will review in detail in Section 3.1: (1) The search space of k-mer orderings is factorially large; and (2) the density minimizing objective is discrete. To overcome these challenges, we reformulate the original problem as parameter optimization of a deep learning system. This results in the first fully differentiable minimizer selection framework that can be efficiently optimized using gradient-based learning techniques. Specifically, our contributions are as follows:
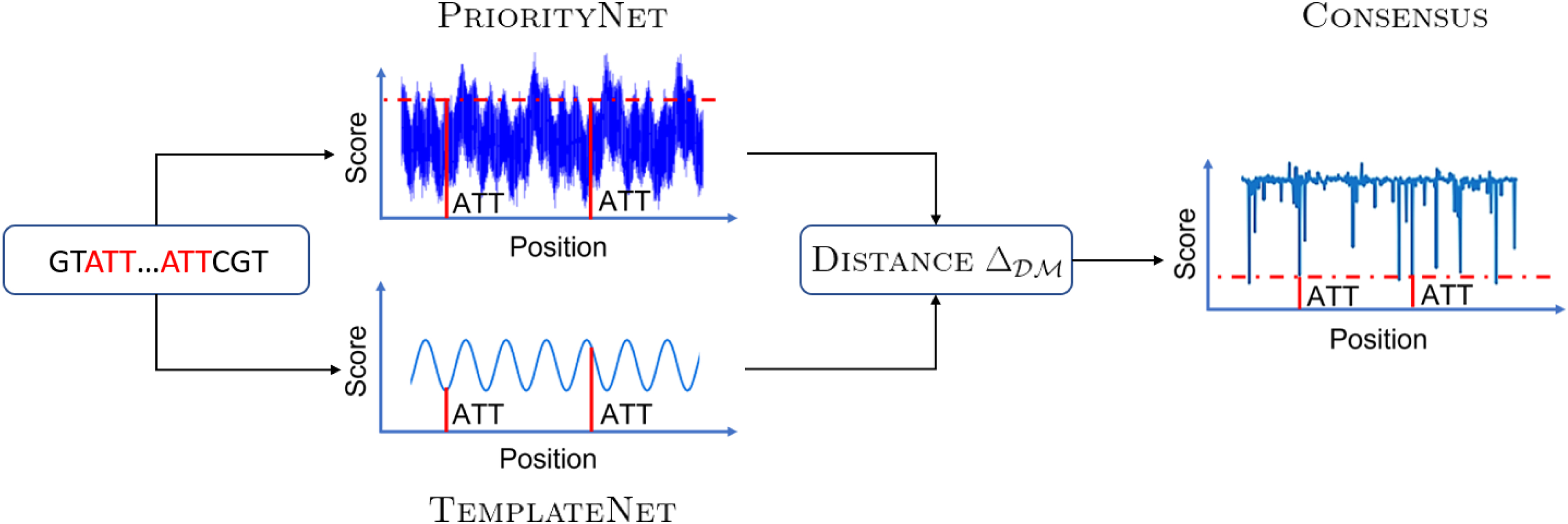
We define a well-behaved search space for k-mer permutations that can efficiently leverage gradient-based optimization. This is achieved by representing k-mer orderings as continuous score assignments, output by a convolutional neural network called PriorityNet, whose architecture guarantees that any score assignment will correspond to a valid minimizer scheme (Section 3.2).
We then approximate the discrete density minimizing objective by a pair of surrogate sub-tasks: (a) generating valid minimizers; and (b) generating low density score assignments. As (a) is achieved by PriorityNet, we further design a complementary neural network called TemplateNet, which outputs potentially invalid assignments that are guaranteed to have low densities on the target sequence (Section 3.4). Minimizing the difference between the outputs of these networks using our proposed distance metric (Section 3.5) results in a valid consensus score assignment with low density. This results in the first fully differentiable objective (Section 3.3) for minimizer optimization.
Finally, we compare our framework, DeepMinimizer, against various state-of-the-art minimizer construction methods on human genomic data. We observe that DeepMinimizer yields sketches with significantly lower densities on various settings (Section 4) and obtains favorable running times through leveraging GPU computing.
2. RELATED WORK
2.1. UHS-based methods
Most existing minimizer selection schemes with performance guarantees over random sequences are based on the theory of UHS (Marçais et al, 2018; Orenstein et al, 2017). Particularly, a -UHS is defined as a set of k-mers such that every window of length w (from any possible sequence) contains at least one of its elements. Every UHS subsequently defines a family of corresponding minimizer schemes whose expected densities on random sequences can be upper-bounded in terms of the UHS size (Marçais et al, 2017). As such, to obtain minimizers with provably low density, it suffices to construct small UHS, which is the common objective of many existing approaches (Ekim et al, 2020; Marçais et al, 2017; Zheng et al, 2020).
In the context of sequence-specific minimizers, there are several concerns with this approach. First, the requirement of UHS to “hit” all windows of every possible sequence is often too strong with respect to the need of sketching a specific string and results in sub-optimal UHS (Zheng et al, 2021). In addition, since real sequences rarely follow a uniform distribution (Zhang et al, 2007), there tends to be little correspondence between the provable upper-bound on expected density and the actual density measured on a target sequence. In practice, the latter is usually more pessimistic (Zheng et al, 2021; Zheng et al, 2020) on sequences of interest, such as the human reference genome, which drives the development of various sequence-specific minimizer selection methods.
2.2. Heuristic methods
Several minimizer construction schemes rank k-mers based on their frequencies in the target sequence (Chikhi et al, 2016; Jain et al, 2020), such that non-repetitive k-mers are more likely to be chosen as minimizers. These constructions, nonetheless, rely on the assumption that non-repetitive k-mers are spread apart and ideally correspond to a sparse sampling. Another greedy approach is to sequentially remove k-mers from an arbitrarily constructed UHS, as long as the resulting set still hits every w-long window on the target sequence (DeBlasio et al, 2019). Though this helps to fine-tune a given UHS with respect to the sequence of interest, there is no guarantee that such an initial set will yield the optimal solution after pruning.
2.3. Polar set construction
Recently, a novel class of minimizer constructions was proposed based on polar sets of k-mers, whose elements are sufficiently far apart on the target sequence (Zheng et al, 2021). The sketch size induced by such a polar set is shown to be tightly bounded with respect to its cardinality. This reveals an alternate route to low-density minimizer schemes through searching for the minimal polar set. Unfortunately, this proxy objective is NP-hard and currently approximated by a greedy construction (Zheng et al, 2021).
Remark 1.In all of the above methods, the common objective to be optimized can be seen as a partition of the set of all k-mers into disjoint subsets. For example, frequency values are used to denote different buckets of k-mers (Chikhi et al, 2016; Jain et al, 2020). Others (DeBlasio et al, 2019; Ekim et al, 2020; Zheng et al, 2021; Zheng et al, 2020) employ a more fine-grained partitioning scheme defined by the constructed UHS/polar set. Each subset has an assigned priority value, such that k-mers from higher priority subsets are always chosen over k-mers from lower priority subsets. However, it remains undetermined how k-mers from within the same subset can be optimally selected to recover a total ordering. Practically, these methods resort to using a pre-determined arbitrary ordering to resolve such situations. In contrast, our work investigates a novel approach to directly learn this ordering.
3. METHODS
3.1. Background
Let be an alphabet of size and S be a sequence containing exactly l overlapping k-mers defined on this alphabet, that is, . For some such that , we define a -window as a substring in S of length , which contains exactly w overlapping k-mers. For ease of notation, we further let denote the number of -windows in S. We will also assume that w and k are fixed and given as application-specific parameters.
Definition 1. (Minimizer) A minimizer scheme is uniquely specified by a total ordering on . Here, we encode as a function that maps k-mers to its position in . Given a -window , m then returns the smallest k-mer in according to :
where denotes the indicator function, denotes the i-th k-mer in , and indicates s precedes in . We break ties by prioritizing k-mers that occur earlier in (i.e., to the left of) the window.
When applied to a sequence S, the scheme cited earlier selects one k-mer position from every overlapping window to construct the sequence sketch , with denoting the window in S. Naturally, a smaller sketch leads to more space and cost savings. As such, we measure minimizer performance by the density factor metric , which approximates the number of k-mers selected per window (Marçais et al, 2017). The minimizer selection problem is then formalized as density minimization with respect to :
This objective, however, is intractable to optimize for two reasons. First, the number of all k-mer permutations scales super-exponentially with k and (i.e., ), thus rendering any form of exhaustive search on this space impossible under most practical settings. Further, the set counting operation is non-differentiable even if the solution space is continuous, which makes efficient gradient-based optimizers inaccessible. The remainder of this section, therefore, proposes a deep-learning strategy to address both these challenges, and it is organized as follows.
Section 3.2 describes a unifying view of existing methods as reparameterizations of (Definition 1). We then propose a novel deep parameterization called PriorityNet that relaxes the permutation search space of Equation (2) into a well-behaved weight space of a neural network. Section 3.3 shows that density optimization with respect to PriorityNet can be approximated by two sub-tasks via introducing another complementary network, called TemplateNet.
This approximation can be formalized as a fully differentiable proxy objective that minimizes distance between TemplateNet and PriorityNet. Sections 3.4 and 3.5 then, respectively, discuss the parameterization of TemplateNet and the distance metric in our proxy objective, thus completing the specification of our framework (Fig. 1).
Our DeepMinimizer framework employs a twin network architecture. PriorityNet generates valid minimizers, but it has no guarantee on density. In contrast, TemplateNet generates low-density templates that might not correspond to valid minimizers. We minimize the distance between the outputs of these networks to obtain a consensus with low density on the target sequence.
3.2. Search space reparameterization
We first remark that many existing methods can be seen as re-parameterizations of in Definition 1. For example, can be parameterized with frequency information from the target sequence (Chikhi et al, 2016; Jain et al, 2020), that is, ; or instantiated with a UHS (Ekim et al, 2020; Zheng et al, 2020), that is, . Similar set-ups have been explored in the context of sequence-specific minimizers using a pruned UHS (DeBlasio et al, 2019) and a polar set (Zheng et al, 2021) constructed for the target sequence. Here, we note that the notation is overloaded to admit different parameter representations. This is mainly to highlight the unification of existing methods, and it has no implication on the mathematical consistency of our formulation.
There are fewer discrete values potentially assigned by than the total number of k-mers in all these re-parameterizations. As such, these methods still rely on a pre-determined arbitrary ordering to break ties in windows with two or more similarly scored k-mers. When collisions occur frequently, this could have an unexpected impact on the final density. DeepMinimizer instead employs a continuous parameterization of using a feed-forward neural network parameterized by weights , which takes as input the multi-hot encoding of a k-mer (i.e., a concatenation of its character one-hot encodings) and returns a real-valued score in .
This continuous scheme practically eliminates the chance for scoring collisions. Further, the solution space of this re-parameterization is only restricted by the modeling capacity encoded by our architecture weight space. This limitation quickly diminishes as we employ sufficiently large number of hidden layers in the network. We can subsequently rewrite Equation (2) as optimizing a neural network with density as its loss function:
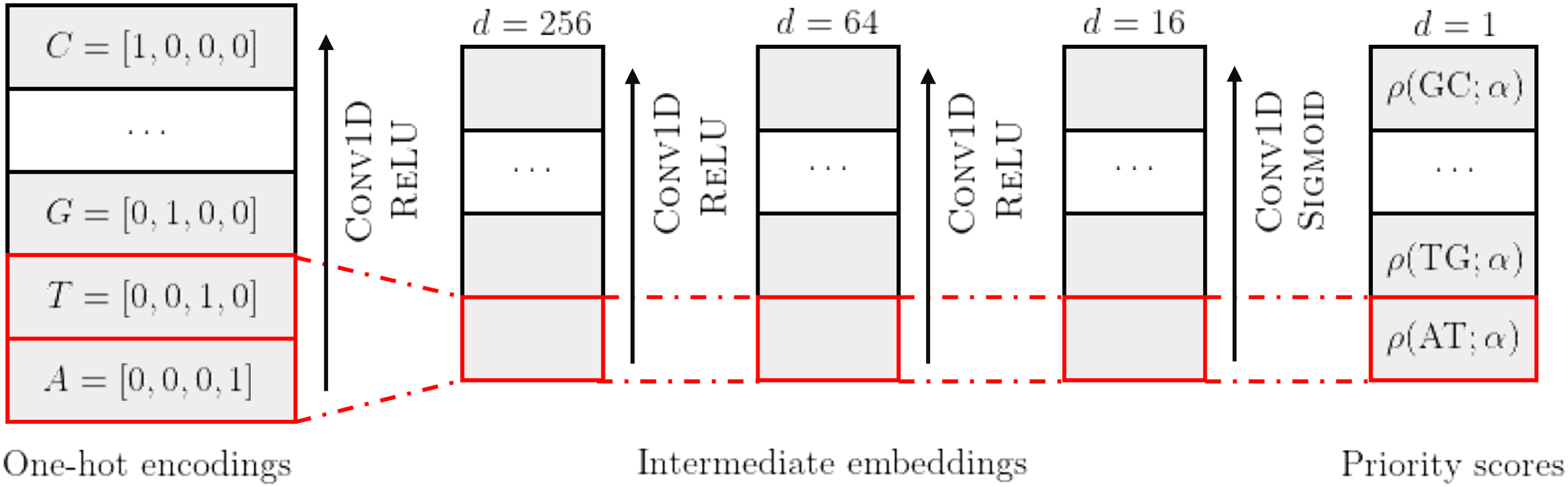
Applying this network on every k-mer along S can be compactly written as a convolutional neural network, denoted by f, which maps the entire sequence S to a score assignment vector. We require this score assignment to be consistent across different windows to recover a valid ordering from such implicitly encoded . Specifically, one k-mer cannot be assigned different scores at different locations in S. To enforce this, we let the first convolution layer of our architecture, PriorityNet, have kernel size k, and all subsequent layers to have kernel size 1. An illustration for is given in Figure 2.
Our PriorityNet architecture for , parameterized by weights , maps sequence multi-hot encoding to priority scores through a series of three convolution layers with kernel size and embedding channels, respectively. Fixing network weights , the computation of assigned priority score to any k-mer is deterministic given its character one-hot encodings.
3.3. Proxy objective
The density computation in Equation (3), however, is not differentiable with respect to the network weights. As such, cannot be readily optimized with established gradient back-propagation techniques used in most deep learning methods. To work around this, we introduce a proxy optimization objective that approximates Equation (3) via coupling PriorityNet with another function called TemplateNet. Unlike the former, TemplateNet relaxes the consistency requirement and generates template score assignments that might not correspond to valid minimizer schemes. In exchange, such templates are guaranteed to yield low densities by design.
Intuitively, the goals of these networks are complementary: PriorityNet generates valid minimizer schemes in the form of consistent priority score assignments, whereas TemplateNet pinpoints neighborhoods of low-density score assignments situated around its output templates. This reveals an alternative optimization route where these networks negotiate toward a consensus solution that (a) satisfies the constraint enforced by PriorityNet; and (b) resembles a template in the output space of TemplateNet, thus potentially yielding low density. Let f and g denote our proposed PriorityNet and TemplateNet, respectively parameterized by weights and ; we formalize this objective as minimizing some distance metric between their outputs:
In the remainder of this article, we detail the full specification of our proxy objective, which requires two other ingredients. First, Section 3.4 discusses the parameterization of our TemplateNetg to consistently generate templates that achieve the theoretical lower-bound density (Marçais et al, 2017) on the target sequence. Further, we note that the proxy objective in Equation (4) will perform best when the distance metric reflects the difference in densities of two score assignments.
Section 3.5 then discusses a practical choice of to accurately capture high-performing neighborhoods of minimizers. These specifications have strong implications on the expressiveness of the solution space and directly influences the performance of our framework, as shown in Section 4.
3.4. Specification of TemplateNet
The well-known theoretical lower bound for density factor (Marçais et al, 2017) implies that the optimal minimizer, if it exists, samples k-mers exactly w positions apart. As a result, we want to construct TemplateNet such that its output approximates this uniform assignment pattern given any initialization of its parameter . To obtain this construction, we first impose that our TemplateNet function is specified by a continuous function such that concatenates evaluations of h at integer indices (i.e., k-mer positions). Then, Proposition 1 given next shows a sufficient construction of h such that approximately yields the optimal density.
Proposition 1.Letbe a periodic function, with fundamental period w, such that h has a unique minimum value on every w-long interval. Formally, h satisfies:
Then, the templatedefined by h induces a sketch with density factoron S when S is sufficiently long (i.e., ).
Proof. We first re-express the density factor of S in terms of the template score assignment . Note that this expression will hold for a general continuous score vector and is appropriate regardless of whether satisfies the consistency constraint (Section 3.2). Let be the minimum index of window , and let indicate the event that the t-th window picks a different k-mer than the -th window. Particularly, and . Then, the density factor of the minimizer scheme induced by is given by:
For any value of , we further define the integer interval . As the density of the entire sequence is simply the sum of density for each interval , it is then sufficient to derive the values of for all values of t in some arbitrary interval .
Without loss of generality, we assume since this can always be achieved via adding a constant phase shift to h. As h has a period of w, this implies , which further reduces to when condition (2) holds. Then, it follows that , we have . In addition, we also have by definition of . Together, the facts cited earlier imply that and consequently for all , since .
For , we trivially have by definition. For any , we have , and , which imply . Finally, using the earlier cited derivations, we have:
where is the remainder of the sequence that does not make up any complete interval. The second equality follows from the derived values of for . Finally, using the fact that and the sufficient length assumption , we have:
which concludes our proof.□
Note that the resulting sketch induced by h does not necessarily correspond to a valid minimizer. Although this sketch has guaranteed low density, it does not preserve the sequence identity like a minimizer sketch; hence, it is not useful for downstream applications. However, it is sufficient as a guiding template to help PriorityNet navigating the space of orderings.
Remark 2.By Proposition 1, TemplateNetcan be as simple asto induce a near-optimal score assignment. This naive specification, however, encodes exactly a single set of template minima (i.e., one that picks k-mers from the set of interval positions), which might not be in proximity of any valid minimizer scheme. For example, consider a sequence S in which some particular k-mer uniquely occurs at positions. The ideal assignment would then be for the template minima to occur at these locations, which is not possible given the above choice of h.
It is, therefore, necessary that the specification of TemplateNet is sufficiently expressive for Equation (4) to find an optimal solution. To model this family of template functions, we subsequently propose several parameterization strategies using (1) an ensemble of sinusoidal functions with integer phase shifts or (2) a Fourier series model that encodes any arbitrary sinusoidal function. We further propose an independent positional phase-delay component that can be combined with (1) and (2) to encode template functions with an approximately constant period.
3.4.1. Ensemble template model
This section gives a construction of a periodic model such that every k-mer position appears in at least one template encoded by its parameter space. To achieve this, we employ a linear combination of multiple sine functions with fixed integer phase shifts , each of which encodes a set of minima with a unique positional offset such as . In particular, we define:
where the sigmoid activation function ensures that appropriately maps to and outputs scores on the same scale as PriorityNet; are optimizable amplitude parameters such that and . Optimizing then determines the dominant phase shift , which, in turn, controls the final offset of the template minima. In addition, by allowing the amplitudes of the ensemble components to be optimizable, we also generate sufficient slack room such that the template scores can be accurately matched against the priority scores.
3.4.2. Truncated Fourier series template model
A more general way to encode any periodic function with period w is via using a Fourier series that linearly combines an infinite number of sine and cosine functions whose frequencies are integer multiples of :
where are optimizable amplitude parameters. For computational efficiency, we approximate this template model by a finite truncation up to the first R summands of the Fourier series cited earlier:
Similar to the ensemble template model, optimizing the amplitude parameters of this model also determines the offset of the minima locations and adds slack room to help matching against the priority score assignment. The key difference between these two template models is that the ensemble model requires all w phase shifts (and hence, all w component functions) to encode every k-mer location, whereas the Fourier model can achieve the same with a fixed value of R and remains compact even for large w.
The Fourier model, however, will admit periodic functions whose minima do not coincide with integer indices; therefore, condition (2) cited earlier will be less likely to hold in practice. We will explore this trade-off in our empirical study given next (Section 4).
3.4.3. Positional phase-shift model
By Proposition 1, all template score assignments encoded by the earlier cited -parameterized families of functions correspond to near-optimal minimizer schemes with approximately perfect density factors. However, we note that this set of template solutions is usually unrealistic and cannot be mirrored exactly by PriorityNet, especially on complex problem instances with more difficult scoring constraints. For example, although the theoretical lower bound for density factor is , the actual optimal density factor attainable given a specific sequence is often considerably larger and occurs when consecutive minimizer locations are not always exactly w locations apart.
Motivated by this observation, we further extend our template model with a learnable component that adaptively adjusts the local frequencies of every encoded periodic function through adding positional noise to their phase-shift parameters. That is, let be a noise generating function parameterized by and let be the output noise vector corresponding to the input sequence S. We define the -augmented template function as:
where denotes the i-th entry of the noise vector. This will allow every entry in the template score assignment to be adjusted by a phase shift of up to in magnitude. When , this space of template functions coincides with that of the exact periodic template model, thus encoding all theoretical optimal assignments. On the other hand, as increases, more template assignments are admitted, but the optimal density guarantee becomes less certain. We will explore the effect of this trade-off in Section 4.
3.5. Specification of the distance metric
As standard practice, we first consider instantiating with the distance. For ease of notation, let and , respectively, denote the score assignments output by PriorityNet and TemplateNet given S; then, . This metric, however, places an excessively strict matching objective at all locations along and . Such perfect matching is often unnecessary, as long as the k-mers outside selected locations (by the induced minimizer scheme) are assigned higher scores. In fact, enforcing a perfect matching will only take away the degrees of freedom needed for the proxy objective to satisfy the constraints implied by PriorityNet.
As such, we are interested in constructing an alternative distance metric that: (a) prioritizes matching and around the neighborhoods of minima; and (b) allows flexible assignment at other positions to admit more solutions that meet the consistency requirement. To accomplish these design goals, we propose the following asymmetrical distance metric:
Specifically, the intuition behind the first component in the summation is to weight each position-wise matching term by its corresponding template score: The weight term implies stronger matching preference around the minima of where the template scores are low; and vice-versa weaker matching preference at other locations where are high. The second component , on the other hand, encourages PriorityNet to maximize its output scores whenever possible, which prevents the system from settling for a trivial solution where both and are squashed to zero.
The trade-off between these two components is controlled by the magnitude of the hyper-parameter . Finally, we confirm that this distance metric is fully differentiable with respect to , and ; hence, it can be efficiently optimized using gradient-based techniques. Particularly, the parameter gradients of both networks are given by:
where the partial derivatives of network outputs are obtained via back-propagation and their respective constants are given by:
4. RESULTS
4.1. Implementation details
We implement our method using PyTorch and deploy all experiments on a RTX-2060 GPU. Due to limited GPU memory, each training epoch only computes a batch loss that averages over randomly sampled subsequences of length . We set and use architectures of PriorityNet and TemplateNet as given in Figure 2 and Section 3.4, respectively. Network weights are optimized using the ADAM optimizer (Kingma and Ba, 2015) with learning rate . Our implementation is available at https://github.com/Kingsford-Group/deepminimizer.
4.2. Comparison baselines
We compare DeepMinimizer with the following benchmarks: (a) random minimizer baseline; (b) Miniception (Zheng et al, 2020); (c) PASHA (Ekim et al, 2020); and (d) PolarSet Minimizer (Zheng et al, 2021). Among these methods, (d) is a sequence-specific minimizer scheme. For each method, we measure the density factor obtained on different segments of the human reference genome: (a) chromosome 1 (Chr1); (b) chromosome X (ChrX); (c) the centromere region of chromosome X (Miga et al, 2020) (which we denote by ChrXC); and (d) the full genome (Hg38).
We used lexicographic ordering for PASHA as suggested by Zheng et al. (2020). Random ordering is used to rank k-mers within the UHS for Miniception, and outside the layered sets for PolarSet. In most settings, we employ the Ensemble template model (Section 3.4.1) with no positional phase-shift component (Section 3.4.3) for DeepMinimizer. However, for scenarios with large w values, we demonstrate that the Fourier template model with positional phase-shift is able to achieve better performance (Section 4.8)
4.3. Visualizing the mechanism of DeepMinimizer
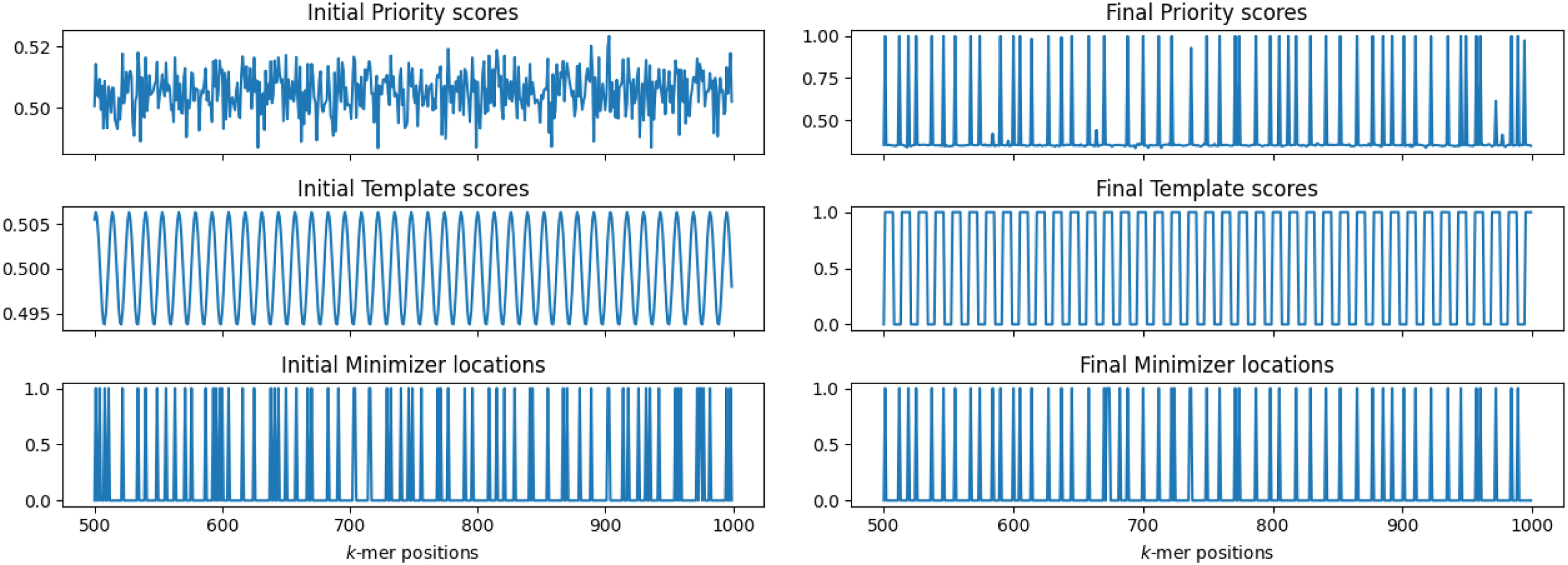
First, we show the transformation of the priority scores assigned by ScoreNet and TemplateNet over 600 training epochs. Figure 3 plots the outputs of these networks evaluated on positions 500 to 1000 of ChrXC, and their corresponding locations of sampled k-mers.
Visualization of PriorityNet and TemplateNet score assignments on positions of ChrXC with , . Left: Initial assignments (); Right: Final assignments after 600 training epochs (). The bottom plots show corresponding locations of sampled k-mers: a value of 1 means selected, and 0 otherwise.
Remarks 3.For ease of implementation, we employ the standardMaxPooloperator from PyTorch to select window maxima as minimizer locations (instead of window minima, as previously formulated). As a result, we expect the sampled locations inFigure 3to coincide with the peaks of the priority scores (instead of the troughs). We also note that to accommodate this implementation, every relevant term in theDeepMinimizerobjective has been properly negated.
Initially, the PriorityNet assignment resembles that of a random minimizer and expectedly yields . After 600 training epochs, the final TemplateNet assignment converges with a different phase shift than its initial assignment, but its period remains the same. Simultaneously, PriorityNet learns to match this template, hence it induces a visibly sparser sketch with . This result demonstrates the negotiating behavior of our twin architecture to find optimal consensus score assignments.
4.4. Convergence of our proxy objective
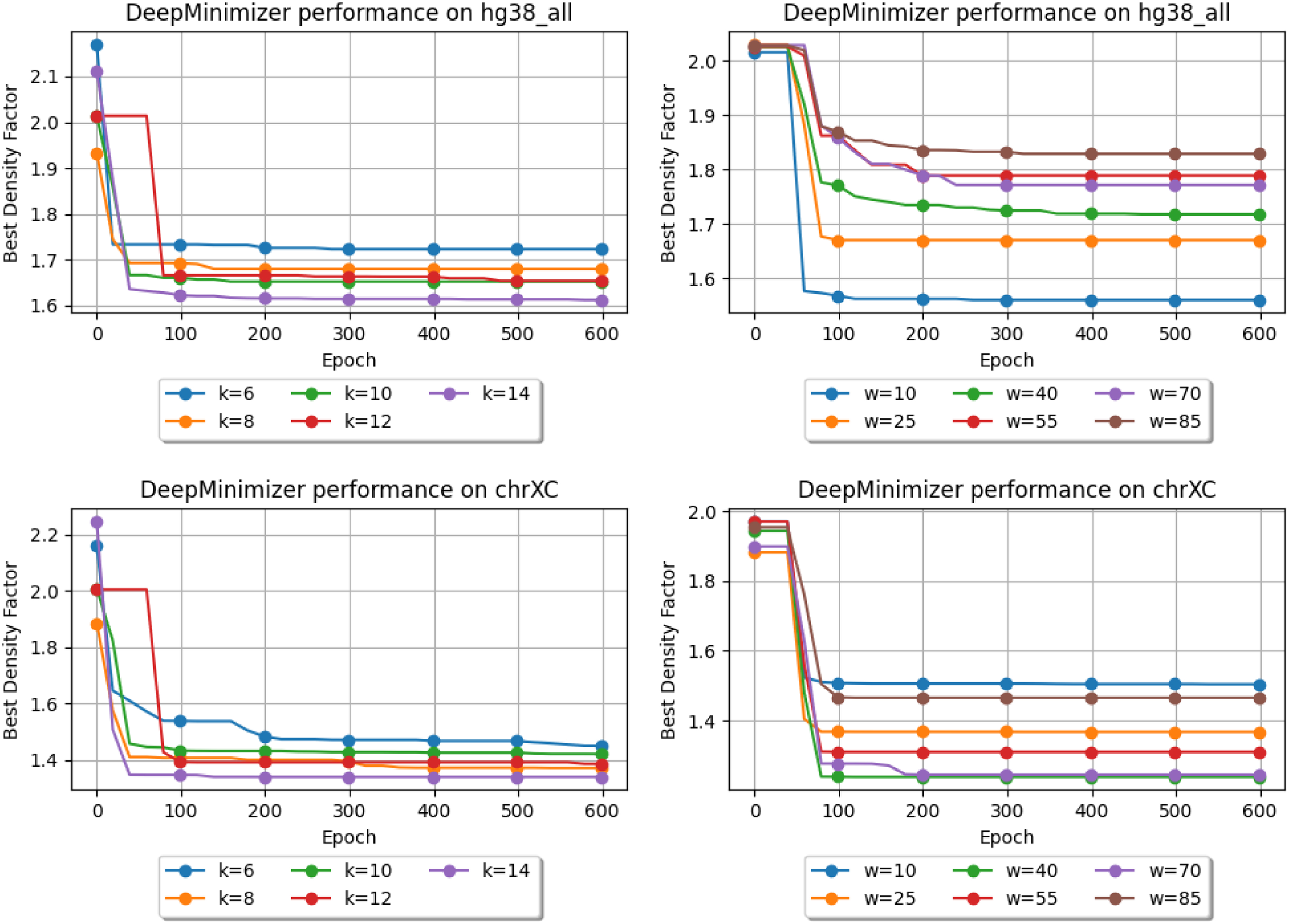
We further demonstrate that our proxy objective meaningfully improves minimizer performance as it is optimized. The first two columns of Figure 4 show the best density factors achieved by our method over 600 epochs on two scenarios: (a) varying k with fixed w; and (b) varying w with fixed k. The experiment is repeated on ChrXC and Hg38. In every scenario, DeepMinimizer starts with , which is only comparable to a random minimizer. We observe a steady decrease of over the first 300 epochs before reaching convergence, where total reduction ranges from 11% to 23%.
Best density factors obtained by DeepMinimizer on Hg38, ChrXC over 600 training epochs. Left: fix , and vary ; Right: fix , and vary .
Generally, larger k values lead to better performance improvement at convergence. This is expected since longer k-mers are more likely to occur uniquely in the target sequence, which makes it easier for a minimizer to achieve sparse sampling. In fact, previous results have shown that when k is much smaller than , no minimizer will be able to achieve the theoretical lower-bound (Zheng et al, 2020). On the other hand, larger w values lead to smaller improvements and generally slower convergence. This is because our ensemble parameterization of TemplateNet scales with the window size w and becomes more complicated to optimize as w increases.
4.5. Evaluating our proposed distance metric
Figure 5 shows the density factors achieved by our DeepMinimizer method, respectively specified by the proposed distance metric in Equation (12) and distance. Here, we fix and vary . We observe that with the distance, we obtain performance similar to a random minimizer in most cases. On the other hand, with our divergence function, DeepMinimizer obtains significantly lower densities, which confirms the intuition in Section 3.5.
Comparing best density factors obtained by DeepMinimizer with and on Hg38 (left) and ChrXC (right) over 600 training epochs.
4.6. Comparing against other minimizer methods
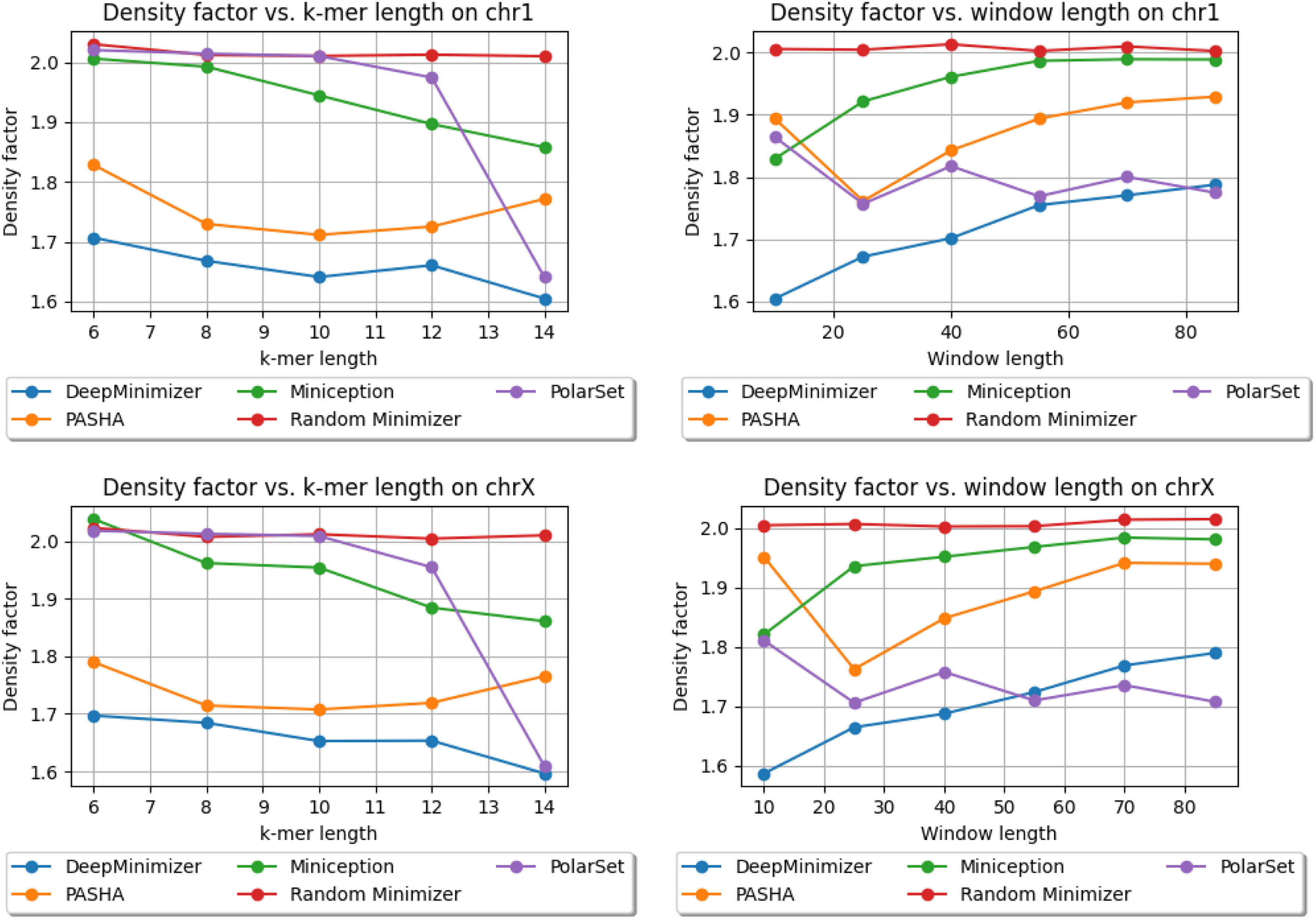
We show the performance of DeepMinimizer compared with other benchmark methods. In this experiment, DeepMinimizer is trained for 600 epochs with ensemble TemplateNet and no positional phase-shift. Figures 6 and 7 show the final density factors achieved by all methods, again on two comparison scenarios: (a) fix , and vary ; and (b) fix , and vary . DeepMinimizer consistently achieves better performance compared with non-sequence-specific minimizers (i.e., PASHA, Miniception) on all settings.
Density factors obtained by DeepMinimizer (600 training epochs), Random Minimizer, PASHA, Miniception and PolarSet on Chr1, ChrX. Left: fix , and vary ; Right: fix , and vary .
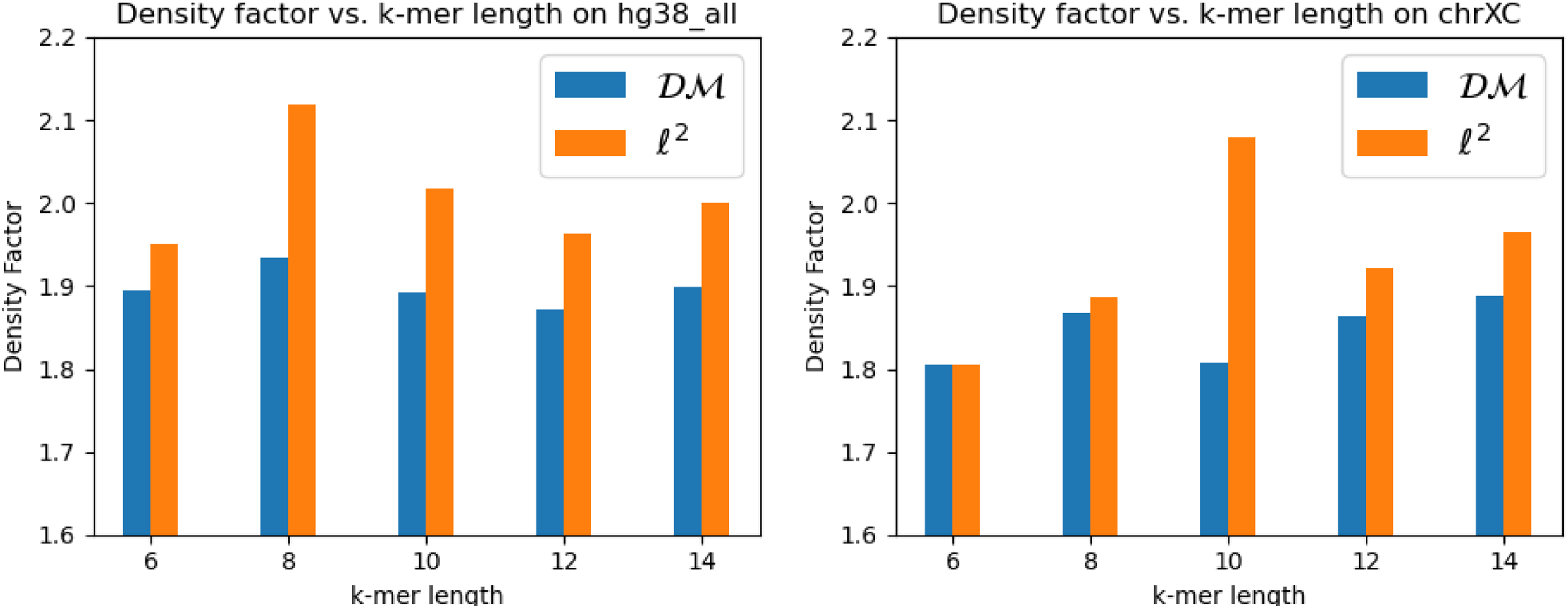
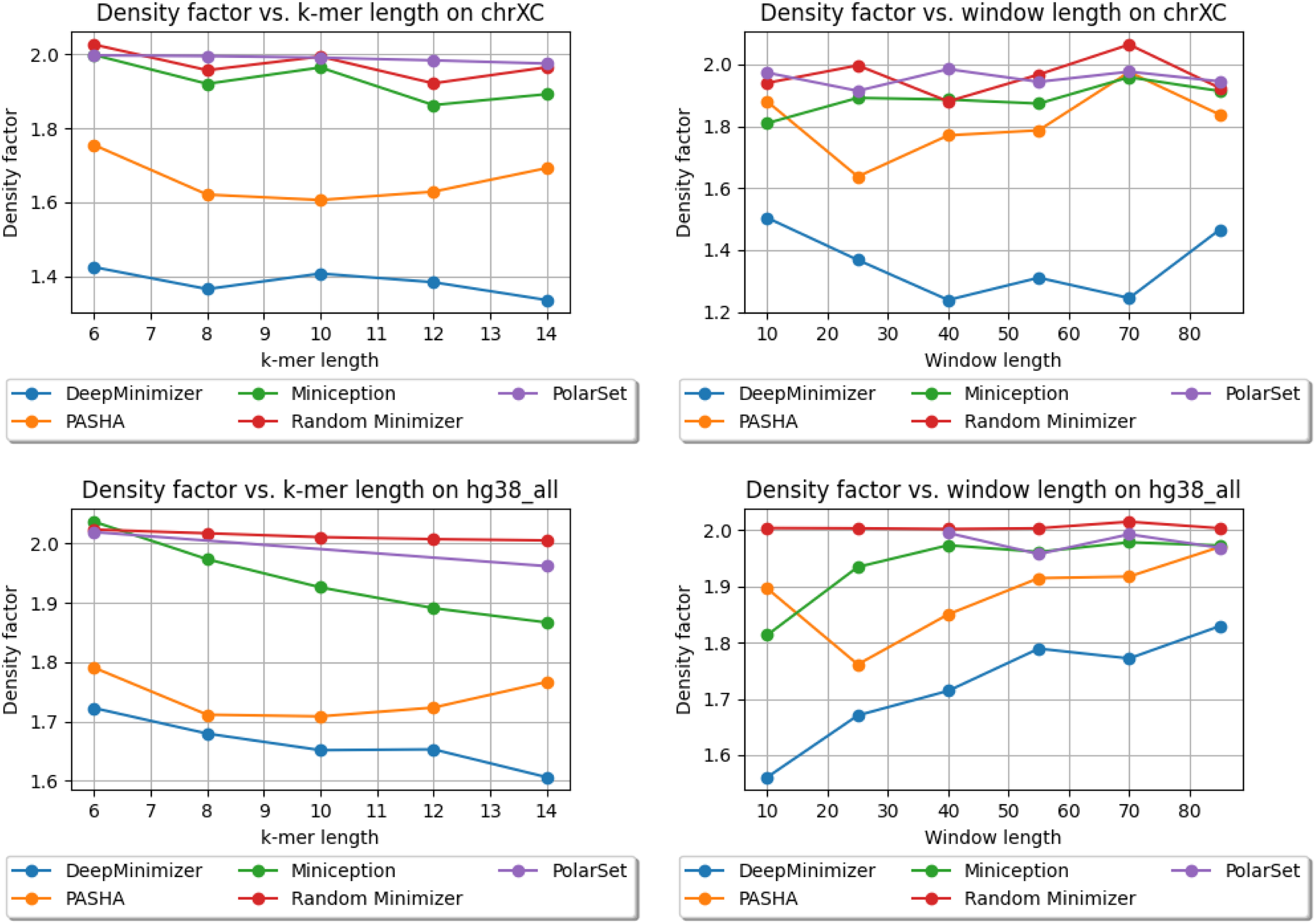
Density factors obtained by DeepMinimizer (600 training epochs), Random Minimizer, PASHA, Miniception and PolarSet on ChrXC, Hg38. Left: fix , and vary ; Right: fix , and vary .
We observe up to reduction of density factor (e.g., on ChrXC, , ), which clearly demonstrates the ability of DeepMinimizer to exploit sequence-specific information. Further, we also observe that DeepMinimizer outperforms our sequence-specific competitor, PolarSet, in a majority of settings. The improvements over PolarSet are especially pronounced for smaller k values, which are known harder tasks for minimizers (Zheng et al, 2020). On larger w values, our method performs slightly worse than PolarSet in some settings. This is likely due to the added complexity of optimizing TemplateNet, as described in the convergence ablation study of our method.
Notably, the centromere region of chromosome X (i.e., ChrXC) contains highly repetitive subsequences (Fukagawa and Earnshaw, 2014) and has been shown to hamper performance of PolarSet (Zheng et al, 2021). Figure 7 shows that PolarSet and the UHS-based methods perform similarly to a random minimizer, whereas our method is consistently better. Moreover, we observe that DeepMinimizer obtains near-optimal densities with ChrXC on several settings. For example, we achieved when , , which is significantly better than the results on Chr1 and ChrX. This suggests that ChrXC is not necessarily more difficult to sketch, but rather good sketches have been excluded by the UHS and polar set reparameterizations, which is not the case with our framework.
4.7. Number of unique k-mers in the final minimizer set
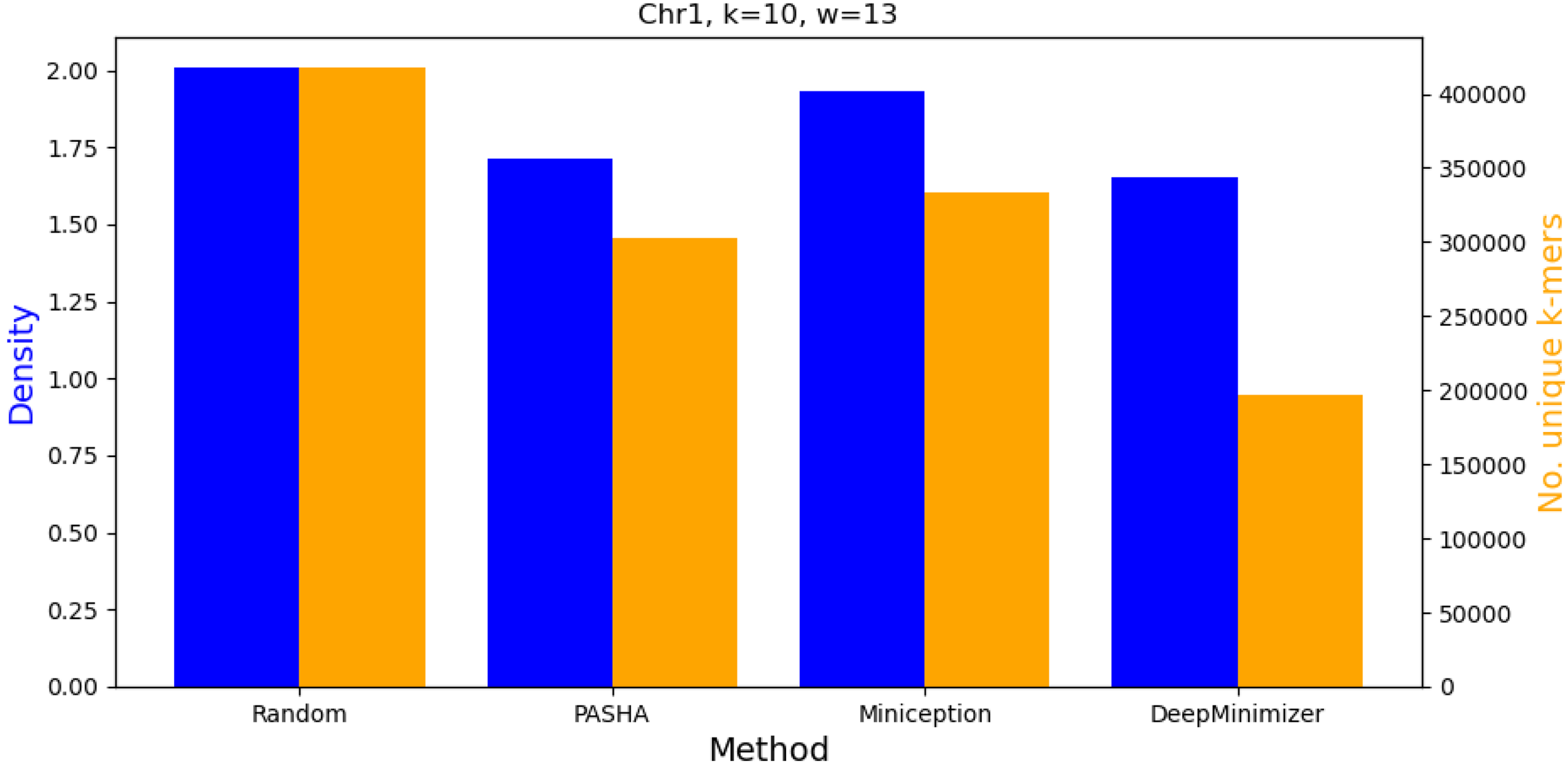
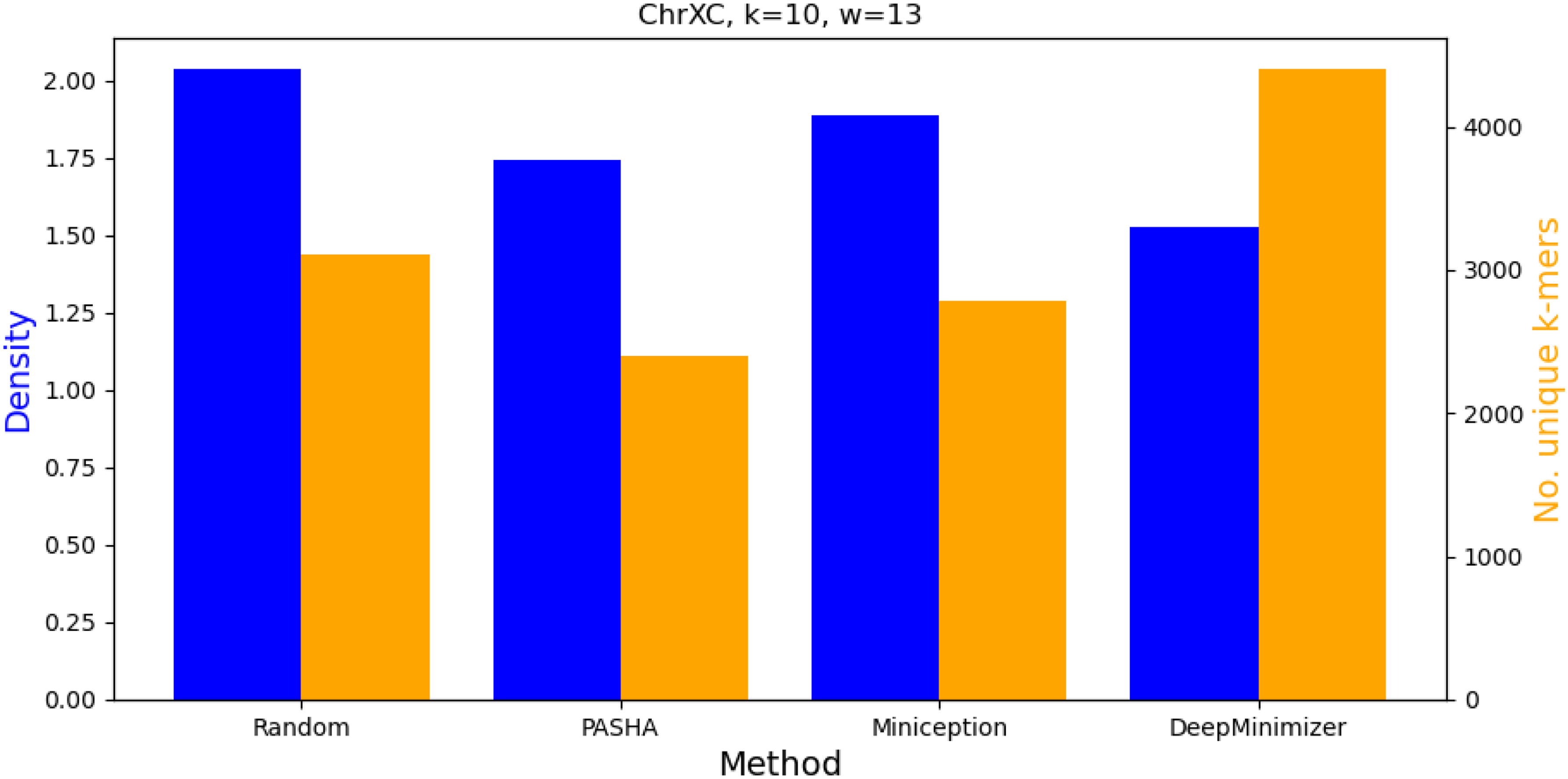
This section investigates the numbers of unique k-mers in the final minimizer sets obtained by random ordering, PASHA, Miniception, and DeepMinimizer. On Chromosome 1, with and , Figure 8 shows that the density factors and numbers of unique k-mers obtained by each method are strongly correlated. This agrees with the intuition of many other minimizer methods that a small set of high priority k-mers (e.g., a small UHS in the case of PASHA and Miniception) tends to induce a low-density sketch on the target sequence. This observation is also expected since the 10-mer distribution of Chr1 is fairly similar to that of a random sequence, which aligns with the premise of most UHS-based minimizer theories.
Comparing density and number of unique k-mers in the minimizer sets obtained by various benchmarks on Chr1 with and .
However, on the chromosome region of ChrX, which contains many highly repetitive sub-sequences, Figure 9 shows that to achieve the best density (i.e., ), DeepMinimizer actually had to pick more high priority k-mers, not fewer. This interestingly demonstrates that minimizing the size of the UHS is not always a desirable surrogate objective on certain specific sequences, hence it asserts the need for a robust sequence-specific optimizer.
Comparing density and number of unique k-mers in the minimizer sets obtained by various benchmarks on ChrXC with and .
4.8. Comparing template models on large window values
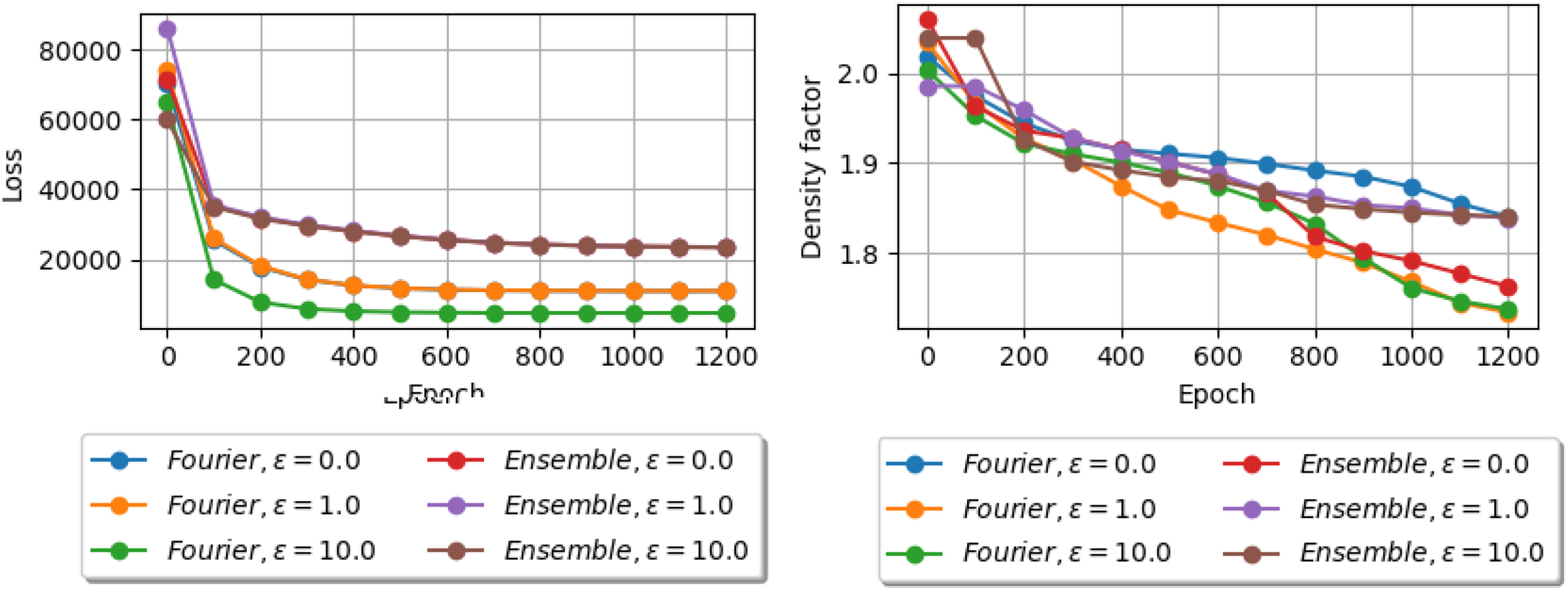
In this section, we investigate the performance of DeepMinimizer on a large window size with different template models. Particularly, we fixed and compare the best density factor obtained by DeepMinimizer over 1200 training epochs using the ensemble template model (Section 3.4.1) and the truncated Fourier series template model (Section 3.4.2). We further pair each template model with a positional phase-shift component (Section 3.4.3), with . We note that in each case, corresponds to the original template model.
Figure 10 shows the respective loss and density factor over 1200 training epochs of these template models. First, we observe that in all models, the loss values correlate positively with the corresponding density factor. Generally, as the DeepMinimizer loss decreases, the induced minimizer scheme also yields lower density factor on the input sequence, which suggests that our loss function is a good surrogate for the discrete density objective.
Comparing loss (left) and best density obtained (right) over 1200 training epochs on Chr1 between ensemble and truncated Fourier series template models. Each template model is paired with a positional phase-shift component with .
Further, we observe that among variants of the Fourier template model, both and perform significantly better than . This is most likely because adding local phase perturbations, indeed, allows TemplateNet to encode more realistic near-optimal score assignments. In contrast, among variants of the ensemble template model, performs the best. This is most likely because the ensemble model has already accounted for all possible integer phase-shifts. As such, adding noisy phase perturbations with a magnitude greater than will negatively affect the convergence of DeepMinimizer.
Finally, pairing Fourier template model with a positional phase-shift component of magnitude achieves the best performance out of all variants. This aligns with our intuition in Section 3.4.2 regarding the trade-off between the certainty of Proposition 1 and the expressiveness of the admitted set of template score assignments.
4.9. Runtime performance
Finally, we confirm that DeepMinimizer runs efficiently with GPU computing. In all of our experiments, each training epoch takes ∼30 seconds to 2 minutes, depending on the choice of k and w, which controls the batch size. Performance evaluation takes between several minutes (ChrXC) to 1 hour (Hg38), depending on the length of the target sequence. Generally, our method is cost-efficient without frequent evaluations. Our most cost-intensive experiment (i.e., convergence ablation study on Hg38) requires a full-sequence evaluation every 20 epochs over 600 epochs, thus it takes ∼2 days to complete.
This is faster than PolarSet, which has a theoretical runtime of and takes several days to run with Hg38. We note that in real applications, we only have to evaluate once by the end of the training loop, which is much faster compared with PolarSet, whose running time above only involves building the minimizer scheme.
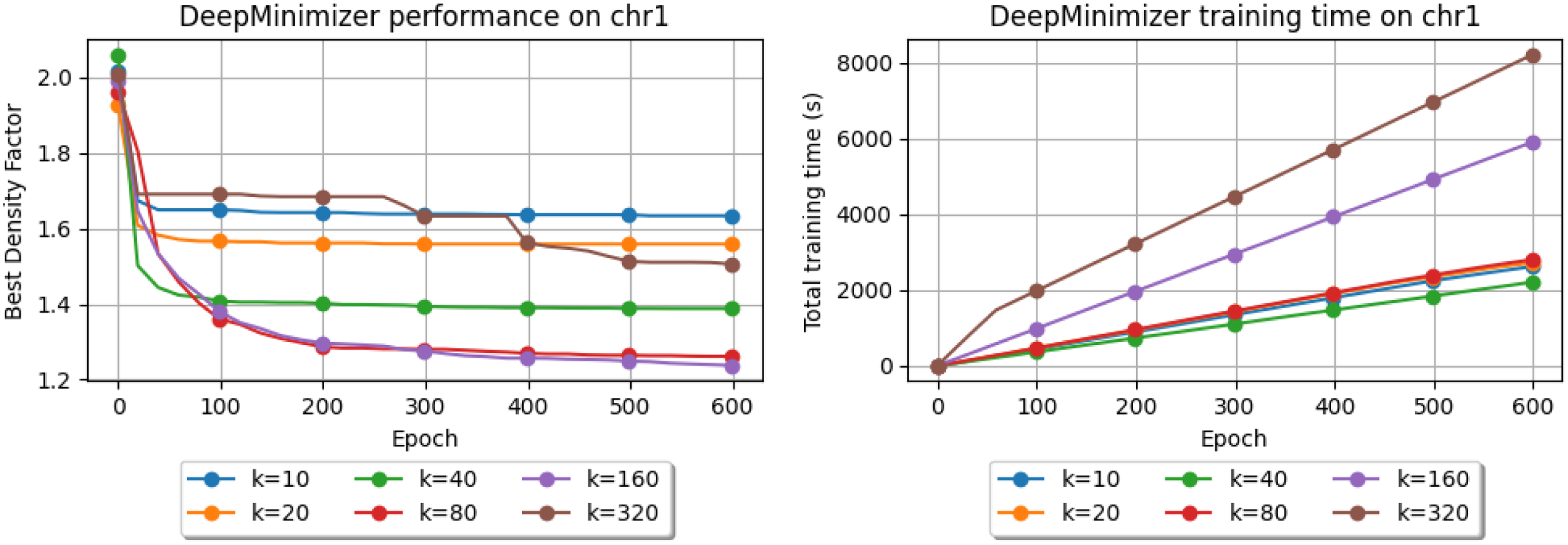
Figure 11 (right) measures runtime (in seconds) of DeepMinimizer on Chr1 over 600 epochs. Larger k values require PriorityNet to have more parameters. We expect running time for to increase in the same order. For and 20, however, the running times are approximately the same as . We note that a smaller k value means there are more k-mers in the same sequence. As such, even though PriorityNet is more compact for these values of k, we will incur some overhead from querying it more often. For completeness, we also show the corresponding density performance plot in Figure 11 (left), which confirms that our model converges well even for large k.
Best density obtained (left) and runtime (right) of DeepMinimizer for and on Chr1.
5. CONCLUSION
We introduce a novel framework called DeepMinimizer for learning sequence-specific minimizers. This is achieved via casting minimizer selection as optimizing a k-mer scoring function . We propose a more well-behaved search space for minimizers, given by a neural network parameterization of , called PriorityNet. Then, we introduce a complementary network, called TemplateNet, which pinpoints optimal scoring templates and guides PriorityNet to the neighborhood of low-density assignments around them.
Coupling these networks leads to a fully differentiable proxy objective that can effectively leverage gradient-based learning techniques. DeepMinimizer obtains better performance than state-of-the-art sequence-agnostic and sequence-aware minimizer selection schemes, especially on known hard tasks such as sketching the repetitive centromere region of Chromosome X.
Footnotes
AUTHORs' CONTRIBUTIONS
M.H. came up with the concept and methodology, implemented the software, conducted an empirical study, and wrote the original draft; H.Z. provided a discussion to formalize the methodology, curated data, ran benchmark experiments, and assisted in writing the article; C.K. provided a discussion to formalize the methodology, helped design the empirical study, and assisted in writing the article.
ACKNOWLEDGMENTS
The authors thank all Kingsford group members for providing insightful discussions and Guillaume Marçais for proof-reading the article. An earlier version of this work appeared in RECOMB 2022 and was deposited in the bioRxiv preprint server.
AUTHOR DISCLOSURE STATEMENT
C.K. is a co-founder of Ocean Genomics, Inc.
FUNDING INFORMATION
This work was supported in part by the Gordon and Betty Moore Foundation's Data-Driven Discovery Initiative (GBMF4554 to C.K.), by the U.S. National Institutes of Health (R01GM122935), and by the U.S. National Science Foundation (DBI-1937540).
References
1.
ChikhiR, LimassetA, MedvedevP. Compacting de Bruijn graphs from sequencing data quickly and in low memory. Bioinformatics, 2016;32(12):i201-i208; doi: 10.1093/bioinformatics/btw279
2.
DeBlasioD, GbosiboF, KingsfordC, et al. Practical universal k-mer sets for minimizer schemes. In: Proceedings of the 10th ACM Conference on Bioinformatics, Computational Biology. Association for Computing Machinery: New York, NY, USA,, 2019; pp. 167–176.
3.
DeorowiczS, KokotM, GrabowskiS, et al. KMC 2: Fast and resource-frugal k-mer counting. Bioinformatics, 2015;31(10):1569-1576; doi: 10.1093/bioinformatics/btv022
4.
EdgarR. Syncmers are more sensitive than minimizers for selecting conserved k-mers in biological sequences. PeerJ, 2021;9:e10805; doi: http://dx.doi.org/10.7717/peerj.10805
5.
EkimB, BergerB, OrensteinY. A randomized parallel algorithm for efficiently finding near-optimal universal hitting sets. In: Proceedings of the 24th Annual International Conference on Research in Computational Molecular Biology, 2020.
6.
ErbertM, RechnerS, Müller-HannemannM. Gerbil: A fast and memory-efficient k-mer counter with GPU-support. Algorithms Mol Biol, 2017;12:9; doi: 10.1186/s13015-017-0097-9
7.
FukagawaT, EarnshawWC. The centromere: Chromatin foundation for the kinetochore machinery. Dev Cell, 2014;30(5):496–508; doi: 10.1016/j.devcel.2014.08.016
8.
HachF, NumanagićI, AlkanC, et al. SCALCE: Boosting sequence compression algorithms using locally consistent encoding. Bioinformatics, 2012;28(23):3051–3057; doi: 10.1093/bioinformatics/bts593
9.
JainC, RhieA, HansenN, et al. Long-read mapping to repetitive reference sequences using Winnowmap2. Nat Methods, 2022;19(6):705–710; doi: 10.1038/s41592-022-01457-8
10.
JainC, RhieA, ZhangH, et al. Weighted minimizer sampling improves long read mapping. Bioinformatics, 2020;36(suppl 1):i111–i118; doi: 10.1093/bioinformatics/btaa435
11.
KingmaDP, BaJ. ADAM: A method for stochastic optimization. Comput Res Repository, 2015;1412.6980.
MarçaisG, PellowD, BorkD, et al. Improving the performance of minimizers and winnowing schemes. Bioinformatics, 2017;33(14):i110–i117. doi: 10.1093/bioinformatics/btx235
15.
MigaKH, KorenS, RhieA, et al. Telomere-to-Telomere assembly of a complete human X chromosome. Nature, 2020;585(7823):79–84; doi: 10.1038/s41586-020-2547-7
16.
OrensteinY, PellowD, MarçaisG, et al. Designing small universal k-mer hitting sets for improved analysis of high-throughput sequencing. PLoS Comput Biol, 2017;13(10):e1005777; doi: 10.1371/journal.pcbi.1005777
17.
RobertsM, HayesW, HuntB, et al. Reducing storage requirements for biological sequence comparison. Bioinformatics, 2005;20(18):3363–3369; doi: 10.1093/bioinformatics/bth408
18.
RobertsM, HuntBR, YorkeJA, et al. A preprocessor for shotgun assembly of large genomes. J Comput Biol, 2004;11(4):734–752; 2004;11(4):734-752; doi: 10.1089/cmb.2004.11.734.
19.
SchleimerS, WilkersonDS, AikenA. Winnowing: Local algorithms for document fingerprinting. In Proceedings of the 2003 ACM SIGMOD International Conference on Management ofData. 2003; pp. 76–85.
20.
YeC, MaZS, CannonCH, et al. Exploiting sparseness in de novo genome assembly. In: BMC Bioinformatics, Volume 13. BioMed Central,, 2012; pp. 1–8.
21.
ZhangZD, PaccanaroA, FuY, et al. Statistical analysis of the genomic distribution and correlation of regulatory elements in the encode regions. Genome Res, 2007;17(6):787–797; doi: 10.1101/gr.5573107
22.
ZhengH, KingsfordC, MarçaisG. Improved design and analysis of practical minimizers. Bioinformatics, 2020;36(suppl 1):i119–i127; doi: 10.1093/bioinformatics/btaa472

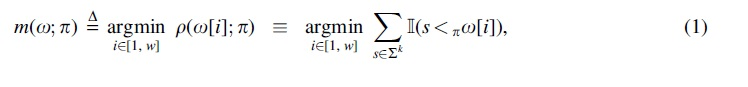
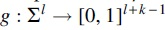 is specified by a continuous function
is specified by a continuous function 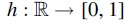 such that
such that 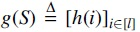 concatenates evaluations of
concatenates evaluations of 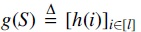

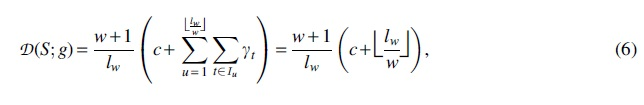
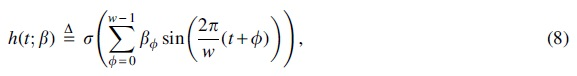
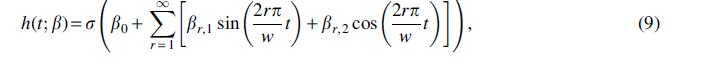
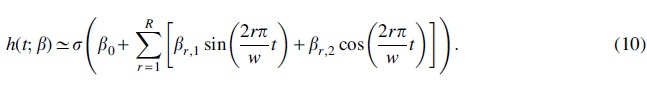
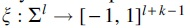 be a noise generating function parameterized by
be a noise generating function parameterized by 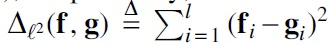 . This metric, however, places an excessively strict matching objective at all locations along
. This metric, however, places an excessively strict matching objective at all locations along 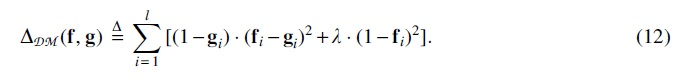
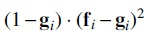 in the summation is to weight each position-wise matching term
in the summation is to weight each position-wise matching term 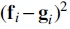 by its corresponding template score: The weight term
by its corresponding template score: The weight term 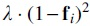 , on the other hand, encourages
, on the other hand, encourages