
Abstract
Minimum flow decomposition (MFD) is an NP-hard problem asking to decompose a network flow into a minimum set of paths (together with associated weights). Variants of it are powerful models in multiassembly problems in Bioinformatics, such as RNA assembly. Owing to its hardness, practical multiassembly tools either use heuristics or solve simpler, polynomial time-solvable versions of the problem, which may yield solutions that are not minimal or do not perfectly decompose the flow. Here, we provide the first fast and exact solver for MFD on acyclic flow networks, based on Integer Linear Programming (ILP). Key to our approach is an encoding of all the exponentially many solution paths using only a quadratic number of variables. We also extend our ILP formulation to many practical variants, such as incorporating longer or paired-end reads, or minimizing flow errors. On both simulated and real-flow splicing graphs, our approach solves any instance in <13 seconds. We hope that our formulations can lie at the core of future practical RNA assembly tools. Our implementations are freely available on Github.
INTRODUCTION
Flow decomposition (FD), the problem of decomposing a network flow into a set of weighted source-to-sink paths that perfectly explains the flow values on the edges, is a classical and well-studied concept in computer science. For example, it is a standard result that any flow in a directed acyclic graph (DAG) with m edges can be decomposed into at most m weighted paths (Ahuja et al, 1988). Such a decomposition can be computed in polynomial time by iteratively removing weighted paths that saturate at least one edge. However, the optimization version of the problem where we seek an FD with a minimum number of paths (minimum flow decomposition [MFD]) is NP-hard (Vatinlen et al, 2008), even on DAGs.
It is also hard to approximate: Hartman et al (2012) showed that there is some ɛ > 0 such that MFD cannot be approximated to within a (1 + ɛ) factor, unless P = NP. The current best approximation ratio for the problem is exponential and was given by Mumey et al (2015). More recent work by Kloster et al (2018) showed that the problem is fixed-parameter tractable (FPT), where the parameter is the size of the minimum decomposition. It is also possible to decompose all but an ɛ-fraction of the flow within a O(1/ɛ) factor of the optimal number of paths (Hartman et al, 2012). On the heuristic side, approaches have centered on greedy methods that choose the widest or longest paths (Vatinlen et al, 2008) in the network. Shao and Kingsford (2017a) showed that these methods can be improved by making iterative modifications to the flow graph before finding a greedy decomposition.
FD is also a key step in numerous applications. For example, some network routing problems (Cohen et al, 2014; Hartman et al, 2012; Hong et al, 2013; Mumey et al, 2015) and transportation problems (Ohst, 2015; Olsen et al, 2020) require FDs that are optimal with respect to various measures. MFDs in particular are used to reconstruct biological sequences such as RNA transcripts [e.g., in tools such as StringTie (Pertea et al, 2015), Scallop (Shao and Kingsford, 2017a), Traph (Tomescu et al, 2013), Ryuto (Gatter and Stadler, 2019), and FlipFlop (Bernard et al, 2014)] and viral quasispecies genomes (e.g., in the tool VG-Flow; Baaijens et al, 2020). However, despite the history of algorithmic work on MFD detailed previously, an exact solver that is fast for instances with large optimal solutions or large flow values has remained elusive. Thus, all practical bioinformatics tools in fact use heuristics for MFD or solve a simpler version of the problem ignoring some information that is available from the sequencing process, resulting in tools that may not reconstruct the correct sequence, even if no other errors are present.
Indeed, various researchers have noted this tradeoff between solving algorithmic problems in DNA assembly exactly and solving them quickly. Nagarajan and Pop (2013) explained that the lack of exact solvers for many of the subproblems involved in DNA sequencing has led to heuristic and ad hoc tools with no provable guarantees on the quality of solutions. In addition, some authors (Bernard et al, 2014; Canzar et al, 2016) have noted that there is a tradeoff between the complexity of the model for RNA assembly (i.e., how much of the true possible solution space that it supports) and its tractability. But if a fast exact solver for MFD exists, this tradeoff may not be necessary for multiassembly.
MFD in multiassembly
One of the most prominent research areas in bioinformatics is the assembly of genetic sequences from short substrings called reads, which can be generated cheaply and accurately from next-generation sequencers. In some cases, such as assembly RNA transcripts or viral quasispecies genomes, we must assemble not just a single sequence but a mixed sample of sequences. This version of assembly is called multiassembly (Xing et al, 2004). Additional details are provided on both RNA transcript assembly and viral quasispecies genome assembly hereunder.
One mechanism by which complex organisms create a vast array of proteins is alternative splicing of gene sequences, where multiple different RNA transcripts (which are then translated into different proteins) can be created from the same gene (Stamm et al, 2005). In humans, >90% of genes are believed to produce multiple transcripts (Wang et al, 2008). Reconstructing the specific RNA transcripts has proved essential in characterizing gene regulation and function, and in studying development and diseases, including cancer (Kim et al, 2008; Shah et al, 2012). A second multiassembly problem is the reconstruction of viral quasispecies, for example, the different HIV or hepatitis strains present in a single patient sequencing sample, or the different SARS-CoV-2 strains present in a sewage water sample. Because viruses evolve quickly, there can be many distinct strains present at one time, and this diversity can be an important factor in the success or effect of the virus (Vignuzzi et al, 2006).
Although the biological realities underlying the different multiassembly problems may yield some differences in how the problems can be solved, at their heart many approaches contain the algorithmic step of decomposing a network flow into weighted paths. The basic setup and approach for multiassembly is as follows: Given a sample of unknown sequences, each with some unknown abundance (e.g., a set of RNA transcripts or virus strains), all sequences are multiplied and then broken into fragments that can be read by next-generation sequencers to produce millions of sequence reads ranging from hundreds to tens of thousands DNA characters in length.
Many approaches are reference based [e.g., those of Tomescu et al (2013); Trapnell et al (2010); Maretty et al (2014); Pertea et al (2015); Kovaka et al (2019); Bernard et al (2014); Li et al (2011b) for RNA assembly and Zagordi et al (2011); Töpfer et al (2013) for viral quasispecies assembly], meaning that they use a previously constructed reference genome to guide the assembly process. These approaches construct a graph using the sequences contained in the reads where nodes are strings, edges represent overlaps, and weights on edges give the counts of reads that support each overlap. Because a reference is used, these graphs are always DAGs. In the nonreference case (called de novo), graphs may have cycles; we address this further at the end of the article. If errors are minimal, the weights on the edges should form a flow on the network, and the underlying sequences and their abundances must be some decomposition of the flow into weighted paths.
For RNA assembly, recent works by Kloster et al (2018) and Williams et al (2021) have confirmed the common assertion (e.g., by Tomescu et al, 2013; Shao and Kingsford, 2017a; Kovaka et al, 2019; Mao et al, 2020; Zhao et al, 2021; Lin et al, 2012; Mangul et al, 2012) that the true transcripts and abundances should be MFD. No such study has been carried out for viral quasispecies assembly, but existing tools do explicitly seek minimum-sized decompositions (e.g., as in Baaijens et al, 2020; Westbrooks et al, 2008). However, although the abovementioned tools seek minimum-sized FDs, because MFD is NP-hard, they in fact compute decompositions that are not guaranteed to be minimum (and thus may not give the correct assembly, even when no other errors are present).
Limitations of current integer linear programming solutions
One promising direction for fast exact solvers for MFD is integer linear programming (ILP). Existing ILP solvers like Gurobi (Gurobi Optimization, LLC, 2021) and CPLEX (Studio, 2017) incorporate optimizations that allow for fast runtimes in practice for problems that should be hard in general; in fact, ILP is already used in various bioinformatics applications, such as those described in Gusfield (2019). In particular, many existing multiassembly tools use ILP to solve MFD as one step in their process. The basic idea behind these existing formulations is to consider some set of source-to-sink paths through the graph and assign each a binary variable indicating whether or not it is selected in the optimal solution, along with constraints to fully encode the FD problem (i.e., that the selected set of paths—with the weights derived for them by the ILP—form an FD) and to model further practical aspects of the specific multiassembly problem.
However, the number of paths in a DAG is exponential, meaning that if the tools enumerate all paths (and thus can be guaranteed to find the true optimal solution), they are impractical for larger instances. One such example is Toboggan (Kloster et al, 2018), which implements an FPT algorithm for MFD by generating all possible paths. The most common strategy in practical tools is to preselect some set of paths, either for all instances [e.g., VG-flow (Baaijens et al, 2020); CLIIQ (Lin et al, 2012)], or only when the input is large [e.g., MultiTrans (Zhao et al, 2021) and SSP (Safikhani et al, 2013)]. But by preselecting paths, these formulations may not find the optimal MFD solution for the instance.
Although the conference version of this article was in print, the recent RNA transcript assembly method JUMPER (Sashittal et al, 2021) was brought to our attention. JUMPER appears to be, to our knowledge, the only prior method incorporating the search for paths in a DAG into an ILP. However, their solution is slightly less general, because it works only for DAGs having a Hamiltonian path. If Hamiltonicity holds, any source-to-sink path can be encoded as a subset of edges that do not pairwise overlap in the Hamiltonian path (i.e., the tail of an edge does not appear before the head of another edge in the Hamiltonian path). As such, to avoid such pairwise edge overlaps they require a number of constraints that is quadratic in the size of the graph.
Our contributions
We give a new ILP approach to the MFD problem on DAGs, and we show that it can be used on both simulated and real RNA assembly graphs under conditions used in many reference-based multiassembly tools.
In Section 3.1, we show for the first time that it is not necessary to enumerate all paths through a general DAG to encode them in an ILP. The key idea is that any path must have a conserved (unit) flow from its start to its end, and that this concept can be encoded using only a number of variables and constraints that is linear in the size of the graph (rather than exponential, as is the case when the model enumerates all possible paths). This is a standard integer programming method for expressing paths in DAGs, used for example in Taccari (2016).
An implementation of our ILP formulation using CPLEX finds optimal FD solutions on RNA assembly graphs (simulated and assembled from real reads) in <13 seconds over all the datasets tested. This is several times faster than the state-of-the-art MFD solver Toboggan (Kloster et al, 2018), depending on the dataset. Although heuristic solvers such as Catfish (Shao and Kingsford, 2017b) or CoasterHeuristic (Williams et al, 2021) finish within a few seconds, we show that they do not provide optimum solutions. Another benefit of our ILP solutions is that all optimum solutions can be reported by the ILP solver, thus potentially helping in “identifying” the correct RNA multiassembly solution, a practical issue acknowledged by both Zheng et al (2022) and Khan et al (2022).
In Sections 3.2 and 3.3, we show that our ILP formulation can be extended to handle common variants on MFD that are solved in practical multiassembly approaches. For example, many tools account for paired-end reads by requiring that they be included in the same path. Another common strategy is to incorporate longer reads such as subpath constraints or phasing paths (Pertea et al, 2015; Shao and Kingsford, 2017a; Williams et al, 2021), which again must be covered by some predicted transcript (i.e., path in an FD). In Section 3.2, we give additional constraints that are expressive enough to not only encode paired-end reads and subpath constraints, but also any generic set of edges that must be covered by a single path [e.g., as when modeling the recent Smart-seq3 protocol producing RNA multi-end reads (Hagemann-Jensen et al, 2020)].
In addition, owing to sequencing or read mapping errors, the weights on edges may not be a flow (i.e., flow conservation might not hold). One approach in this case is to consider intervals of edge weights instead, as in Safikhani et al (2013) and Williams et al (2019). We give a formulation to handle this approach in Section 3.3. Our implementation solves subpath constraint instances in similar time to standard instances, whereas the existing exact solver could not complete on many instances in <60 seconds. Moreover, although the existing interval heuristic is fast, it finds decompositions that are far from optimum. Although all these additional constraints are naturally expressed in ILP (further underlining the flexibility of our approach), the novelty here is their integration with the ILP encoding of all possible paths in the DAG from Section 3.1.
In Section 3.4, we give MFD formulations dealing with the total error over all edges. We can consider an upper bound on the total error, or seek a minimum decomposition that also achieves the minimum error, as studied in Tomescu et al (2015) and used in RNA assemblers such as those given by Li et al (2011a), Li et al (2011b), Bernard et al, (2014), and Tomescu et al (2013). Finally, we note that our formulation could also be used to find decompositions for any of the above variants using a fixed, or upper bounded, number of paths, which is useful if further information is available to restrict the solutions that should be considered.
PRELIMINARIES
Given a graph G = (V, E), with vertex set V and edge set

Given a flow network, a FD for it consists of a set of source-to-sink flow paths, and associated weights strictly >0, such that the flow value of each edge equals the sum of the weights of the paths passing through that edge. In other words, the superposition of the weighted paths of the FD equals the flow of the network (Fig. 1). Formally:

Our above definitions assume integer flow values in the network and integer weights of the flow paths, as is natural because these values count the number of sequenced reads traversing the edges, and are also consistent with previous works such as Kloster et al (2018). However, in practical applications, one could have both fractional flow values and flow path weights, as in for example, Pertea et al (2015). Note also that the integer and fractional decompositions to the problem may differ. For example, Vatinlen et al (2008) observes that there are integer flow networks which admit a k-FD with fractional weights, but no k′-FD with integer weights, for any

Example of a flow network and of two FDs of it.
Minimum flow decomposition
In this section we consider the following problem of finding a minimum size FD.
Our solution for problem MFD is based on an ILP formulation of a FD with a given number k of paths (a k-FD). Using this, one can easily solve the MFD problem by finding smallest k such that the flow network admits a k-FD. Notice that any DAG admits an FD of size at most
Thus, if there is a k-FD, there is also a k′-FD, for all
We start by recalling the standard formulation of a path used for example by Taccari (2016) for the shortest path problem. If an s – t path repeats no edge (which is always the case if the graph is a DAG) then we can interpret it simply as the set of edges belonging to the path. If we assign value 1 for each edge on the path, and value 0 for each edge not on the path, then these binary values correspond to a conceptual flow in the graph (V, E) (different from the input flow). Moreover, this conceptual flow induced by the (single) path is such that the flow out-going from s is 1 and the flow in-coming to t is 1. It can be easily checked (cf. e.g., Taccari, 2016) that if the graph is a DAG, then this is a precise characterization of an s – t path.
Thus, for every path
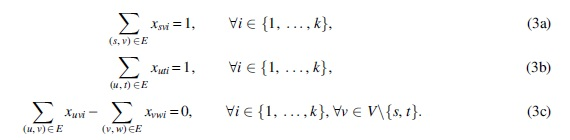
Having expressed a set of k s − t paths with already known ILP constraints, we need to introduce the new constraints tailored for the k-FD problem. That is, we need to state that the superposition of their weights equals the given flow in the network (2). Thus, for each path i we introduce a positive integer variable wi corresponding to its weight, and add the constraint:
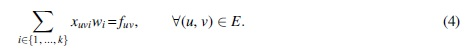
To get the ILP formulation, it remains to linearize Equation (4), which is nonlinear because it involves a product of two decision variables. Let us remark that although nonlinear programming solvers exist [such as IPOPT (Wächter and Biegler, 2006)], they are inefficient, do not scale to a large number of variables, and are nonprofessional grade. Instead, having an ILP formulation means that we can make use of popular solvers such as CPLEX (Studio, 2017) and Gurobi (Bixby, 2007).
Since the decision variables involved in the product in Equation (4) are bounded (xuvi is binary and wi is at most the largest flow value of any edge), this equation can be linearized by standard techniques as in for example, Furini and Traversi (2019) and Liberti (2007). For that, we introduce the integer decision variable πuvi, which represents the product between wi and xuvi, and a constant
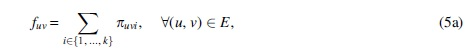
In these constraints, Equation (5b) ensures that πuvi is 0 if πuvi is 0, and Equations (5c) and (5d) ensure that πuvi is wi if xuvi is 1. For completeness, we list hereunder the full ILP formulation for k-FD (Table 1).

Notation for k-Flow Decomposition Integer Linear Programming
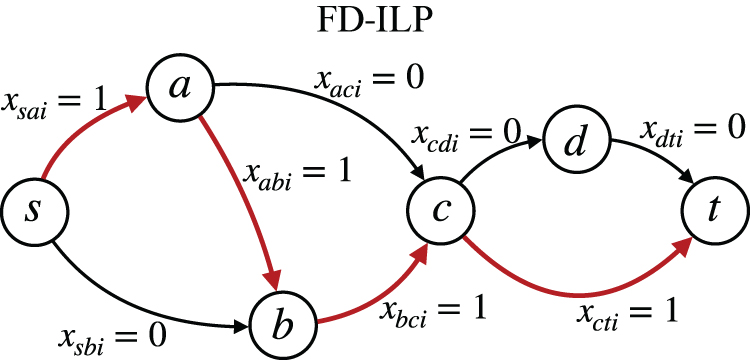
Example of the edge variables of the i-th path, satisfying Equations (3a–3c).
In this section we consider the FD variant where we are also given a set of subpath constraints that must appear (as a subpath of some path) in any FD. Among all such decompositions we must find of one with the minimum number of paths. In multiassembly, subpath constraints represent longer reads that span three or more vertices; they are used in popular RNA assembly tools such as StringTie (Kovaka et al, 2019) and Scallop (Shao and Kingsford, 2017a) and their usefulness for that problem was confirmed empirically in Williams et al (2021). Such subpath constraints can also naturally model long RNA-seq reads, and we note that, as several authors also acknowledge [Zhang et al (2021); Amarasinghe et al (2020); Voshall and Moriyama (2018)], long reads do not render the RNA assembly problem obsolete, because they do not always capture full-length transcripts (owing to the conversion from RNA to cDNA), and do not fully capture low-expressed transcripts.
Formally, the problem can be defined as follows (see also Fig. 3a).
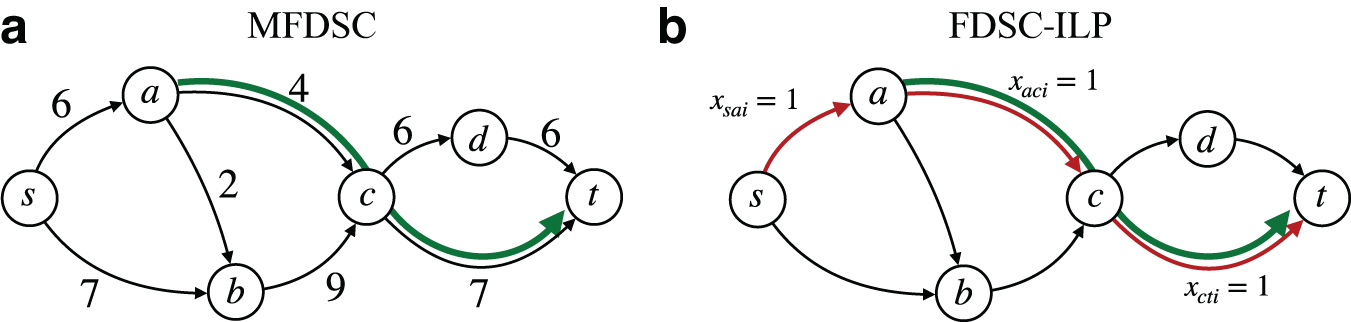
The flow network from Figure 1 with a subpath constraint (which is satisfied by the 4-FD from Fig. 1c, but not by the one in Fig. 1b), and example of a path satisfying the constraint.
We can expand the previous ILP formulation for k-FD to incorporate the conditions necessary to represent the subpath constraints. Let
Another variant of the FD problem is when the given values on the edges of the flow network do not satisfy the conservation of flow property. Instead, they are required to belong to a given interval, for each edge. Thus, we are looking for an inexact FD, namely one such that the superposition of its weights belongs to the given interval of each edge. This model was studied in Williams et al (2019) and is used in the practical RNA assembler SSP (Safikhani et al, 2013), which seeks a set of transcripts explaining the read coverage within some user-defined error tolerance (i.e., interval around the observed weights) on all edges.
The problem is formally stated as follows.
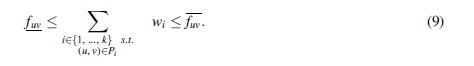
In this variant, the same formulation as presented k-FD can be expanded to accommodate the inexact flow component. By simply replacing the flow conservation expressed in Equation (4) [in the linearized form in Eq. (5a)], with the following two constraints:
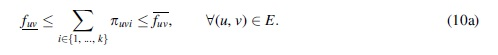
Imperfect flow
An alternative approach to handle a graph whose weights to not satisfy the flow conservation property flow consists of directly taking the observed read coverages, and trying to find a set of path whose superposition best explains the observed coverages under some error model, penalizing the difference between the observed coverage of an edge and the sum of the weights of the paths going through that edge. This problem has been formalized in Tomescu et al (2015) and also proven NP-hard. To formalize this problem, we denote by imperfect flow network any DAG (V, E) with unique source s and unique sink t, where for every edge we have an associated integer positive value fuv (not necessarily satisfying the flow conservation property).
A first formulation of such an MFD variant imposes a fixed bound on the total error of all of the edges.
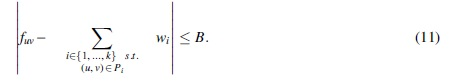
Notice that Problem 4 is a strict generalization of the MFD problem, which is obtained by taking B = 0. As carried out in Section 3.3, we can obtain an ILP for it by extending the ILP formulation for k-FD to express Equation (11) by the following two sets of linear equations:
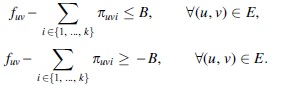
This model is for a fixed k value, and a full solution for Problem 4 is obtained by trying all values of k in increasing order until the ILP formulation admits a solution. Notice that the same upper bound
Another formulation, defined by Tomescu et al (2015) and at the core of RNA multiassembly tools such as Li et al (2011a), Li et al (2011b), Bernard et al (2014), and Tomescu et al (2013), asks to minimize the total sum of squared errors with a minimum number of paths.
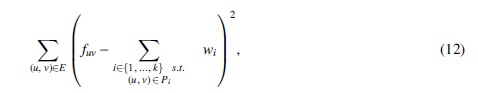
and among all such sets of paths, find one with minimum k (i.e., with minimum cardinality).
For a given number k of path, Equation (12) can be used as an objective function in an Integer Quadratic Problem, which can solved by commercial solvers such as CPLEX and Gurobi. The main requirement is that the objective function is quadratic and convex, such as:
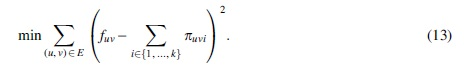
As before, to fully solve Problem 5, one can iterate over k from 1 to
EXPERIMENTS
Experiment design
Solvers
We denote by StandardILP, SubpathConstraintsILP, and InexactFlowILP our ILP formulations for Problems 1 (MFD), 2 (MFDSC), and 3 (MIFD), respectively. We implemented these using the
Datasets
To test the performance of the solvers under a range of biologically occurring graph topologies and flows weights, we used three human transcriptomic datasets containing a perfect (i.e., the edge weights satisfy conservation of flow) splice graph for each gene of the human genome.
The first dataset, produced by the authors of Shao and Kingsford (2017a) and also used in a number of FD benchmarking studies (Kloster et al, 2018; Williams et al, 2021), was built using publicly available RNA transcripts from the Sequence Read Archive with quantification using the tool (Salmon Patro et al, 2015). We use one of the larger transcriptomes
†
and call this dataset
For the subpath constraint experiments, we simulate four subpath constraints in each graph as in Williams et al (2021). For four of the groundtruth paths, we take the prefix of the path that includes three nontrivial junctions [equivalent to three edges in the contracted graph described in Kloster et al (2018), Lemma 13] as a subpath constraint. If a splice graph has fewer than four groundtruth paths, it is excluded from this experiment.
For the inexact flow experiments, we simulate interval flows as follows, similar to what was performed in Williams et al (2019). For each true edge flow fuv, we independently sample a perturbed flow 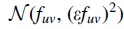 , the Gaussian distribution with mean fuv and standard deviation ɛ fuv. For this experiment we fixed ɛ = 0.05. We then create intervals as
, the Gaussian distribution with mean fuv and standard deviation ɛ fuv. For this experiment we fixed ɛ = 0.05. We then create intervals as
From all datasets, the trivial graphs made up of a single path (i.e., admitting a trivial FD) are excluded.
Metrics
For each dataset and each FD variant, we report
Results
The results for Problem MFD are given in Table 2. For all three datasets, the average time and the total time of Toboggan and Catfish outperform StandardILP for less complex genes, where the number of flowpaths is at most 10 or 15. However, as the genes becomes more complex (larger optimum FDs), StandardILP is capable of solving all instances within an average of 10 seconds, whereas Toboggan and Catfish require on average 16 and 11 seconds for the solved instances, respectively. In addition, Toboggan does not solve all instances even within the 5-minute time limit. Recall also that Catfish is a heuristic, and thus it does not always return optimum solutions (see column
Results for Problem Minimum Flow Decomposition
Results for Problem Minimum Flow Decomposition
Among the different datasets,
Finally, one of the key steps in the Toboggan implementation is a reduction of the graph [to simplify nodes with in-degree or out-degree equal to one, see Kloster et al (2018)], which is a key insight behind its efficiency. However, this observation is highly tailored to the MFD problem, and cannot be easily extended to other FD variants (in fact, it is not used by real RNA assemblers).
The results for Problem MFDSC are given in Table 3. For all three datasets, SubpathConstraintsILP is capable of solving instances of any size within a few seconds. As an ILP formulation, the addition of the constraints corresponding to the subpath constraints does not hinder its scalability or efficiency. On the contrary, Coaster is both slow on small instances, and does not solve large instances. This shows that the Toboggan implementation is optimized to use many properties of the standard MFD problem, that are not generalizable to variants of it of practical applicability, such as Problem MFDSC. Moreover, similar to the Catfish heuristic, CoasterHeuristic does not return optimum solutions.
Results for Problem Minimum flow Decomposition with Subpath Constraints
The results for Problem MIFD are given in Table 4. For all three datasets, both formulations run on any instance in a small amount of time. In fact, InexactFlowILP generally has the same running time as StandardILP, which further underscores the flexibility and efficiency of our formulations. However, IFDSolver is a heuristic solver, having a significant difference with respect to the size of a minimum decomposition even for small k.
Results for Problem Minimum Inexact Flow Decomposition
FD is a key problem in computer science, with applications in various fields, including the major multiassembly problems from bioinformatics. Despite this, the only exact solution for MFD is the FPT algorithm of Kloster et al (2018), which does not scale to large values of k, and cannot be efficiently extended to model practical features of real data (such as long reads, or inexact flows). In fact, a large number of practical RNA assemblers use an ILP formulation at their core, thanks to their flexibility in modeling various aspects of real data. However, such formulations are based either on an impractical exhaustive enumeration of all possible s – t paths, or on a greedy heuristic to select a smaller set of candidate s – t paths that might be part of an optimum solution.
In this article we show an efficient quadratic-size ILP for MFD and variants, avoiding for the first time the current limitation of (exhaustively) enumerating candidate s – t paths. We also show that many constraints inside state-of-the-art RNA assemblers can be easily modeled on top of our basic ILP (i.e., subpath constraints, inexact, and imperfect flows). Further flexibility also comes from the fact that all our ILPs are based on modeling a specific type of FD with a given, or upper bounded number k of paths (thus, they do not need to solve the minimum version of the problem). On both simulated and real datasets, we show that our ILP formulations finish within 13 seconds on any instance, and within a few seconds on most instances.
On the practical side, we hope that our flexible ILP formulations can lie at the core of future reference-based RNA assemblers employing exact solutions. Thus, the current tradeoff between the complexity of the model and its tractability might not be necessary anymore. On the theoretical side, our ILP formulation represents the first exact solver for MFD scaling to large values of k, and it could be a reference when for example, benchmarking various other heuristic or approximation algorithms.
Given the maturity of ILP solvers and Toboggan's intrinsic exponential dependence on k, it is not surprising that an ILP for MFD using a quadratic number of variables performs significantly better than Toboggan for larger k values. However, since for small k values our ILP formulations are still slower, as future work it would be interesting to further devise more efficient MFD solvers (e.g., as a start, run Toboggan when the instance is detected as being “small enough”).
It would also be interesting to extend our ILP formulations to flow networks with cycles. While in this work we focus on reference-based approaches for multiassembly, de novo approaches [e.g., Grabherr et al (2011); Schulz et al (2012) for RNA assembly and Baaijens et al (2019), Baaijens et al (2020); Posada-Céspedes et al (2021); Chen et al (2018) for viral quasispecies assembly] may yield graphs with cycles. In this context, any flow in such a network can be decomposed into at most
Footnotes
AUTHORs' CONTRIBUTIONS
F.H.C.D.: Conceptualization, software, writing—original draft preparation. L.W.: Data curation, writing—reviewing and editing. B.M.: Methodology. A.I.T.: Conceptualization, writing—reviewing and editing, supervision, project administration.
AUTHOR DISCLOSURE STATEMENT
The authors declare they have no conflicting financial interests.
FUNDING INFORMATION
This work was partially funded by the European Research Council under the European Union's Horizon 2020 research and innovation program (Grant agreement No. 851093; SAFEBIO), partially by the Academy of Finland (Grant Nos. 322595, 328877, 308030), and partially by the US NSF (award 1759522).