High-dimensional statistics deals with statistical inference when the number of parameters or featurespexceeds the number of observationsn(i.e.,). In this case, the parameter space must be constrained either by regularization or by selecting a small subset offeatures. Feature selection through-regularization combines the benefits of both approaches and has proven to yield good results in practice. However, the functional relation between the regularization strengthand the number of selected featuresmis difficult to determine. Hence, parameters are typically estimated for all possible regularization strengths. These so-called regularization paths can be expensive to compute and most solutions may not even be of interest to the problem at hand. As an alternative, an algorithm is proposed that determines the-regularization strengthiteratively for a fixedm. The algorithm can be used to compute leapfrog regularization paths by subsequently increasingm.
1. Introduction
In statistics and machine learning, a common problem is to learn a model of the form
with coefficients and where fj denotes the j th feature computed from the input data z. In statistics, is called mean function, whereas in machine learning it is commonly referred to as activation function. The model is typically estimated by minimizing a given loss function on a set of n observations.
For instance, in linear regression, the mean function is and the parameters would be estimated by minimizing the sum of squared residuals, also called ordinary least squares (OLS). In the case of artificial neural networks, represents a single output neuron and fj denotes the jth output of the preceding layers of the network. The activation function is typically either a sigmoid function or some variant. Neural networks are estimated by minimizing, for instance, the mean squared or cross-entropy error.
Two fundamentally different ways can be found in the literature of how features fj are estimated. Some machine learning methods, such as neural networks, treat each fj as a parametric function, which is optimized jointly with the model parameters . In contrast, in statistics a fixed set of features is considered, from which a subset of size m is selected. Although the former is computationally more tractable, it often leads to nonconvex optimization problems. The focus of this study lies in the latter. In particular, it is assumed that the feature space is very large and that only a small subset of size m must be selected (). Ideally, the parameters of a statistical model are estimated for a given loss function by minimizing subject to the constraint . However, this approach is generally not feasible since it requires to test all subsets of size m.
Several strategies exist to compute approximate solutions. For instance, matching pursuit (MP) (Tropp et al., 2007) is a greedy strategy that selects one feature at a time until the desired number of m features is reached. This algorithm was found to be overly greedy in practice (Efron et al., 2004) and may provide poor subset selections. A more powerful strategy is to consider the constraint (Tibshirani, 1996). In practice, this leads to the equivalent unconstrained optimization problem
where the penalty strength is a parameter that controls the sparseness of and is often chosen so that . Although this approach often selects nearly optimal subsets, it comes with the difficulty of determining the penalty or regularization strength .
Unfortunately, there exists no known functional relation between m and . However, grid search can be used to compute solutions of the optimization problem P0 for a manually specified set of regularization strengths. More efficient algorithms, such as least angle regression (LARS) (Efron et al., 2004) and the homotopy (Osborne et al., 2000) algorithm, initially start with for which all coefficients are zero. These methods decrease and determine breakpoints at which features either become active (nonzero coefficient) or inactive (zero coefficient). By interpolating between breakpoints a regularization path is obtained, which contains solutions for all feasible regularization strengths.
Computing full regularization paths is costly for large feature spaces and complex models. In such cases, the regularization path is only computed up to a maximal . Furthermore, a solution of the optimization problem P0 with m features will often behave very similarly to a solution with features. Therefore, the focus of this study is to present and test an algorithm that computes leapfrog regularization paths containing solutions such that , where is a given sequence of cardinalities. The main advantage of this algorithm is that mq can be chosen much larger than with existing regularization path algorithms, because it does not compute all solutions of the regularization path. Furthermore, the sequence of cardinalities can be selected so that a clear difference in performance for mk and is observed.
2. Algorithmic Background
Many feature selection methods were first developed for linear regression and later extended to more complex models, such as generalized linear models (GLMs). Hence, linear regression may serve as a role model for introducing feature selection methods. Let denote the covariates or data matrix with n observations and p features . For linear regression, is the identity function so that and the objective function is the sum of squared residuals defined as
Furthermore, is a vector of n dependent variables, also called response, and is referred to as residuals. If and X has full rank p then the coefficients can be estimated by OLS, which minimizes the sum of squared residuals . When , parameters can be estimated by minimizing the -penalized loss , that is
The following interpretation of OLS (Hastie et al., 2009) is essential for understanding many feature selection methods. In the dot product is a point in the hyperplane H spanned by the columns of X and y is a vector typically not contained in H. The point in H that minimizes the length of the residual vector is located directly below y, that is, it is the projection of y onto H. It follows that
where is a projection matrix. Therefore, the OLS solution can be interpreted as the scalar projection of y onto H. If the covariates are appropriately normalized, that is, Most importantly, XTy can be interpreted as the correlation of y with X. The OLS solution satisfies , which shows that the residuals are uncorrelated with X. Many feature selection methods decrease the correlation iteratively starting with until the residuals are orthogonal to X.
2.1. Matching pursuit
MP is a greedy feature selection algorithm (Tropp et al., 2007) that selects one feature at a time. Let the columns of X have unit length, that is, for all . The first feature is computed as . Hence, the algorithm selects the feature j with the largest scalar projection of y onto fj, or the feature that is most correlated with y.
All remaining features are selected accordingly. Let denote the set of active features and the covariate matrix restricted to . Furthermore, let
denote the residuals at iteration t with . At iteration the algorithm computes
that is, it selects that feature j for which the scalar projection of onto fj is largest. Alternatively, can be interpreted as the correlation of the jth feature with the residuals .
The MP algorithm has been applied to several other models, including logistic regression (Lozano et al., 2011), although the correlation might be less informative.
2.2. LARS and homotopy algorithm
LARS is an iterative feature selection method for linear regression (Efron et al., 2004). The algorithm is related to MP, but it is less greedy and gives only as much weight to each feature as it deserves (Hastie et al., 2009). Another method is the homotopy algorithm (Osborne et al., 2000), which is identical to LARS except that it also allows features to be removed within an iteration. It is referred to as LARS with Lasso modification in the literature (Efron et al., 2004; Donoho and Tsaig, 2008). Both methods are introduced hereunder. X is typically assumed to be standardized so that the correlations are not tainted by heterogeneous scaling.
The LARS and homotopy algorithms maintain a set of active features all equally correlated with the residuals for the current estimate . In contrast, features not in are less correlated with the residuals. Both algorithms initially set . In each subsequent iteration, the coefficients are updated so that the correlations of all features in uniformly shrink toward zero until some other feature is equally correlated with the residuals. For the next iteration, is added to the active set . The homotopy algorithm also removes a feature j from the active set when the coefficient becomes zero. In this way, is incrementally reduced from its maximum value, where all features are inactive (), to zero, where all coefficients are nonzero (). The values of at which a feature enters or leaves the active set are referred to as breakpoints.
More specifically, the decrement in correlation at which a feature enters the active set is given by
where min+ is the minimum over positive elements and denotes the jth element of For LARS without Lasso modification, the step size equals ; however, the homotopy algorithm also removes a feature j from the active set when for some
so that . The subsequent breakpoint is given by .
LARS with Lasso modification is equivalent to solving the Lasso problem (P1) for all regularization strengths . A direct application of LARS or the homotopy algorithm to GLMs is not possible, because the path along which the correlations uniformly decline is nonlinear. As a consequence, there is no analytical solution to the position of breakpoints. Nevertheless, a linear approximation for GLMs exists (Park and Hastie, 2007). The algorithm, however, requires several iterations until a breakpoint is reached.
3. Computing Leapfrog Regularization Paths
LARS and the homotopy algorithm compute full regularization paths for all feasible regularization strengths . These algorithms start with and decrease the regularization strength until the unconstrained model is obtained. The full and exact regularization path is computed by linear interpolation between breakpoints. Extensions of LARS to GLMs (LARS-GLM) instead compute approximate regularization paths, because is nonlinear between breakpoints and there exists no analytical expression to compute at what values of breakpoints occur.
For certain applications the full regularization path can be very costly to compute, especially when the number of features p is large. In such cases, the algorithms can be stopped when a maximum number of features mq is reached. Nevertheless, because LARS-GLM successively decreases the regularization strength , it might take very long until a desired number of features m is reached. Furthermore, estimated models with m and selected features might behave very similarly, for instance, in terms of classification performance. For such situations, an algorithm is introduced that computes for an a priori defined sequence the estimates such that . The set of estimates is called a leapfrog regularization path. The algorithm can be derived from proximal gradient descent (Boyd et al., 2004) or from a modification of LARS-GLM.
Let denote the objective function and the jth partial derivative at the current estimate . Given a fixed the following update rules are iterated until convergence:
The algorithm has converged when is identical between two successive iterations. The first update step computes a new active set . All features with nonzero coefficients remain in the active set. Additional features are added based on the absolute value of the partial derivatives. An estimate of the optimal parameter is obtained during this step. In the second step, the coefficients of the active set are re-estimated, all other coefficients remain zero. The re-estimation is computationally cheap if , because the gradient descent method operates only on m selected features. Once the algorithm has converged for a fixed , the procedure is repeated for (see Algorithm 1).
Algorithm 1 relies on -regularization for feature selection. Compared with MP it is much less greedy, because it does not simply select one feature per iteration (Hastie et al., 2009). Instead, the active set is refined until a solution to optimization problem (P0) is found. The algorithm is more similar to LARS-GLM, but it uses a different method for determining the regularization strength . Whereas LARS estimates the position of subsequent breakpoints, Algorithm 1 iteratively updates until a given number of m features is selected.
Despite extremely high-dimensional feature space, the estimation of parameters is relatively cheap when , because the gradient descent method operates only on a small subset of m features and not the full feature space of size p. In other words, estimating the coefficients of the logistic regression with a gradient method takes steps, where T is the number of iterations of the gradient descent method. This is much faster than estimating the parameters on the full feature space, which would take steps.
3.1. Derivation from proximal gradient descent
The optimization problem P0 is commonly solved using proximal gradient descent (Boyd et al., 2004). In general, proximal gradient descent can be used to compute minimizers of functions , where g is convex differentiable and h is convex but not differentiable. The update equation is given by
and is the step size. The proximal operator can be solved analytically for . Note that the equation inside the proximal operator is a simple gradient descent step applied to .
For the optimization problem the following update equations are obtained:
where is the result after the gradient descent step and before applying the proximal operator. Assume that for a feature j the coefficient is zero. The coefficient remains zero during subsequent update steps unless the gradient update is large enough, because of the application of the proximal operator. More specifically, for any step size , a coefficient remains zero unless .
3.2. Derivation from LARS
In each iteration, LARS either removes a feature from the active set or selects a new one. The focus here is on the selection of new features, that is, Equation (1). By assuming that , a much simplified step size
is obtained, which shows that and remember that for linear and logistic regression . Hence, m features can be selected by setting equal to the mth largest absolute correlation or partial derivative.
4. Applications to Large-Scale Logistic Regression
Algorithm 1 can be easily applied to GLMs, such as logistic regression, as demonstrated in the following. The closest method in the literature is LARS-GLM and the GNU-R library glmpath is used for comparing it with Algorithm 1. Decisive for the computational cost is the number of steps required for computing a regularization path. A step here refers to the estimation of parameters for a fixed regularization strength , that is, solving optimization problem . For Algorithm 1 this corresponds to one evaluation of the two update equations. In addition, the number of passes of the gradient descent method through the entire data set (epochs) is informative. However, because different gradient descent methods are used for Algorithm 1 and LARS-GLM, a direct comparison in terms of epochs is not possible.
Enhancers are regulatory elements in the genome that control the cell type-specific expression of genes. The DNA sequence of an enhancer is predictive of the cell types in which it actively controls gene expression (Lee et al., 2011; Hashimoto et al., 2016; Kelley et al., 2016; Yang et al., 2017). Training and test data sets were compiled from DNA sequences of enhancers active in embryonic mice at day 15.5 in brain (positive set) and nonbrain tissues (negative set). Enhancers were detected using ModHMM (Benner and Vingron, 2020) and the data are available online (Benner, 2020). For each enhancer sequence, the K-mer content is determined. K-mers are short DNA subsequences of length K. In this example, K-mers of variable length are considered. The resulting data matrix has n rows (observations) and p columns (features), where is the number of occurrences of the jth K-mer in the ith enhancer sequence. A logistic regression model is used to discriminate between brain and nonbrain enhancers. The average negative log-likelihood (average loss) is given by
where is the sigmoid function and is a vector of n class labels. Analogously to linear regression, when , parameters are estimated by minimizing the -penalized average logistic loss (penalized average loss), that is
For logistic regression the objective function is convex and the optimum must satisfy . SAGA (Defazio et al., 2014) is used as gradient descent method to compute solutions of this optimization problem. To guarantee stable convergence of the gradient descent method, the data are normalized to unit variance.
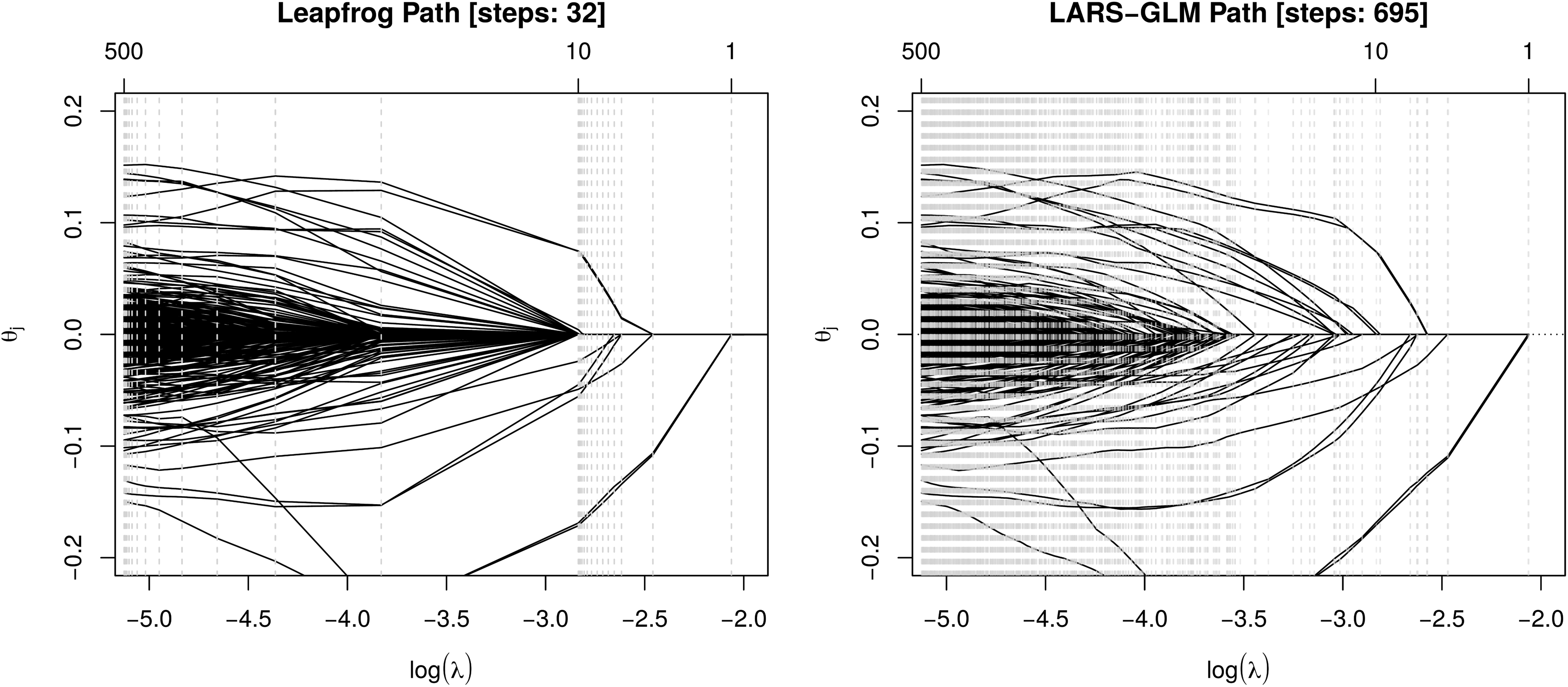
In a first example, K-mers of length are used, that is, . This leads to a feature space of size , where only K-mers that actually occur in the data set are considered. Figure 1 shows the leapfrog regularization path computed with Algorithm 1 for . In addition, a regularization path computed with LARS-GLM is shown and the algorithm was stopped when it reached 500 features. The example shows that the computation of the leapfrog path requires much fewer steps, however, at the expense of not evaluating the full path up to 500 features. Nevertheless, for larger feature spaces and larger m the LARS-GLM algorithm quickly becomes computationally too expensive.
Comparison of regularization paths. Leapfrog regularization path (left) with and LARS-GLM regularization path (right). Vertical dashed gray lines show steps of the path algorithms, that is, values for which parameters were estimated
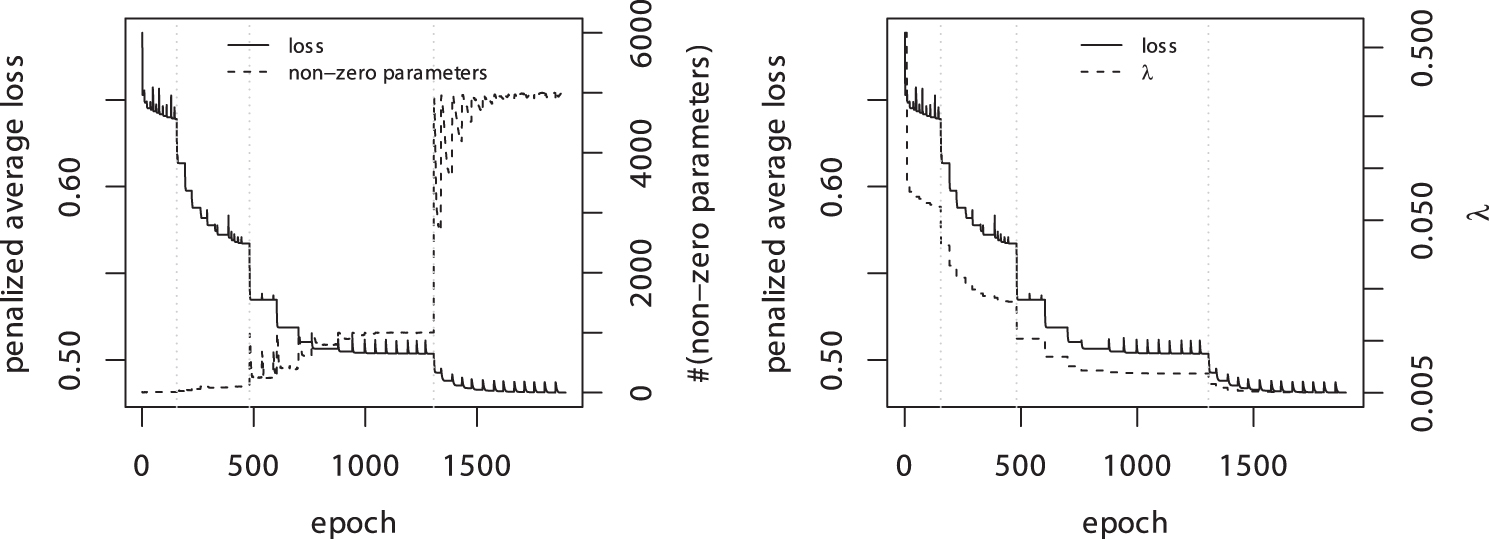
In a second example, the set of K-mers is extended to lengths of , that is, , which results in a feature space of size . Figure 2 shows the estimation of parameters for a leapfrog regularization path with Algorithm 1 and targets . The algorithm successively decreases the penalty strength until a target is reached. After only 1500 epochs, corresponding to ∼50 steps of Algorithm 1, the leapfrog regularization path is computed. In contrast, extracting the 5000 most important K-mers with the LARS-GLM algorithm is computationally not feasible.
Estimation of a leapfrog regularization path with . The vertical lines show the epoch at which m is increased. An epoch is one pass of the gradient descent method through the entire data. For a fixed penalty strength , the gradient descent method is iterated until convergence. If the number of nonzero parameters does not match the target m, is updated and the parameters are re-estimated.
4.1. Bias-variance trade-off
In statistics and machine learning one is often confronted with the task of choosing a model family that captures the underlying structure of the observed data, but also generalizes well to new observations. The bias-variance trade-off suggests that both cannot be accomplished with arbitrary precision. When the capacity of is too small, the estimated models has poor performance on the observed data as well as on new observations. The underfitting of the estimated models is caused by a strong (inductive) bias of . As the capacity of increases, the model is capable of extracting more complex patterns from the training data, but the variance of parameter estimates across samples increases. If the capacity of is too large it causes overfitting, that is, the estimated models will perform very well on the training data but generalize poorly. A model family that generalizes well must minimize both sources of error, the bias and the variance.
For instance, in the case of linear or logistic regression, the capacity of can be increased by using more features (i.e., increasing p). Regularization, in contrast, constrains the parameter space and, therefore, reduces the capacity of (Hastie et al., 2009). In practice, it is often observed that models generalize best if regularization is used in combination with very large p (Bühlmann and Van De Geer, 2011).
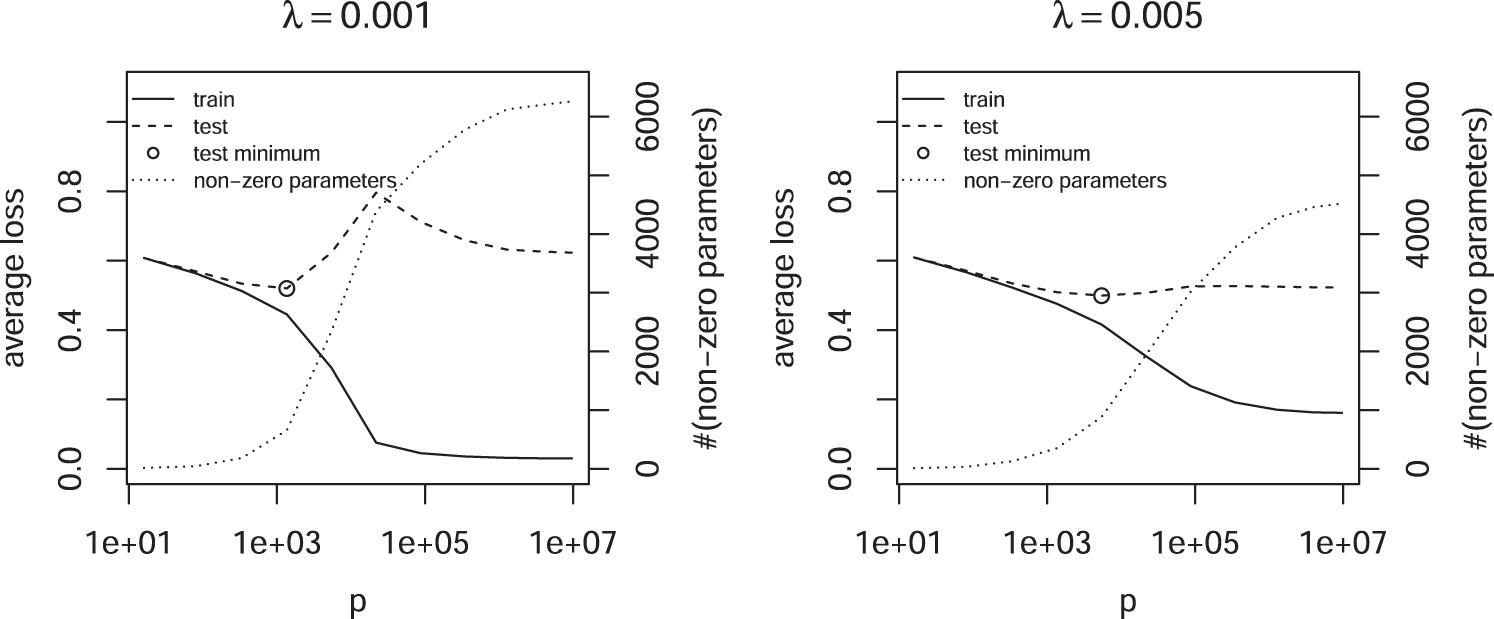
In this section, the effect of regularization and the size of the feature space p on the capacity of is studied. A balanced set of n = 10,000 brain and nonbrain enhancers is used. The size of the feature space p is controlled by the maximal length of K-mers. Figure 3 shows the training and test error for a fixed penalty and increasing p. Whereas the training error decreases monotonically, the test error starts to decrease after it reaches a maximum. This double descent has been observed before (Vallet et al., 1989; Opper et al., 1990; Duin, 2000; Belkin et al., 2019) and is theoretically expected (Cheema and Sugiyama, 2020). It shows that the capacity of is the result of a complex interplay between the size of the feature space p and the regularization strength .
Average loss as a function of p and fixed penalty .
The dependency between and p makes it difficult in practice to find optimal values for both parameters, especially when double descents are possible, because an extensive search is required to eliminate the possibility of being in a local optimum. Instead of adding more parameters by increasing p, Algorithm 1 is utilized to control the number of active features m for a fixed p. Figure 4 shows that in this case no double descent is observed, suggesting a monotonic relation between m and the capacity of , as expected from the bias-variance trade-off. Furthermore, the test error increases rapidly as the interpolation threshold is crossed, that is, the point where the model is able to perfectly discriminate between the positive and negative class.
Average loss as a function of m and fixed p.
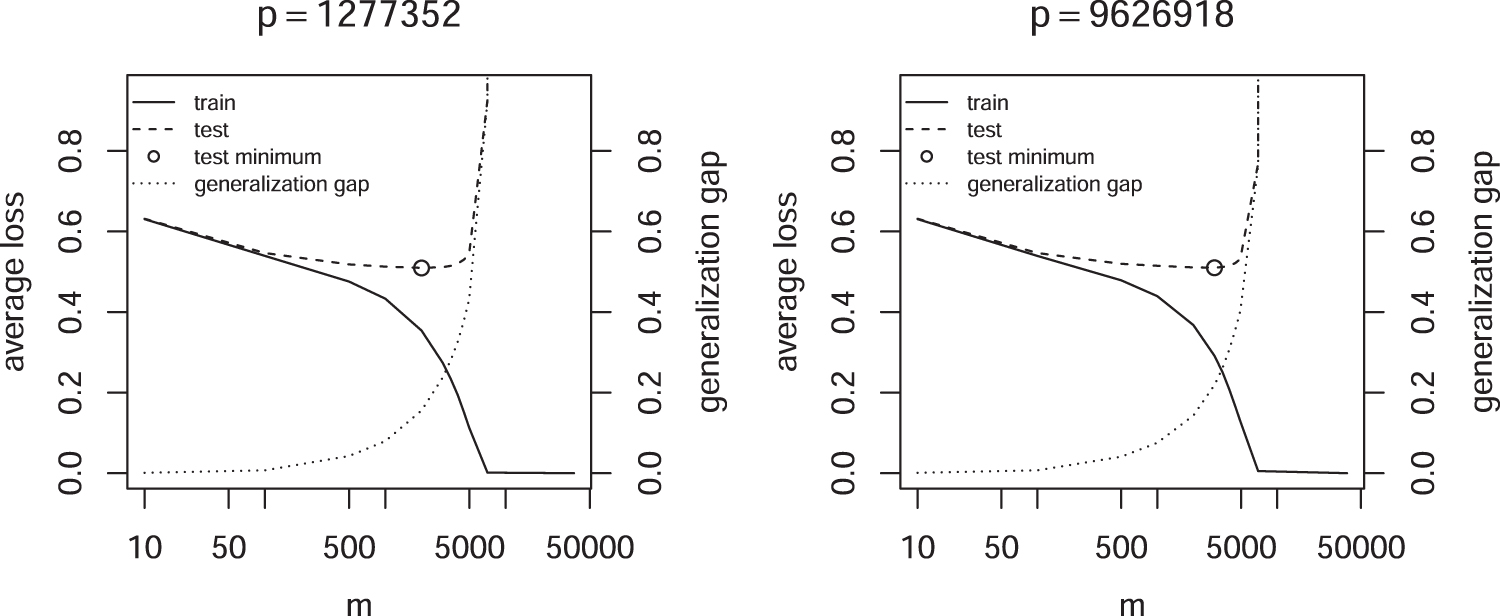
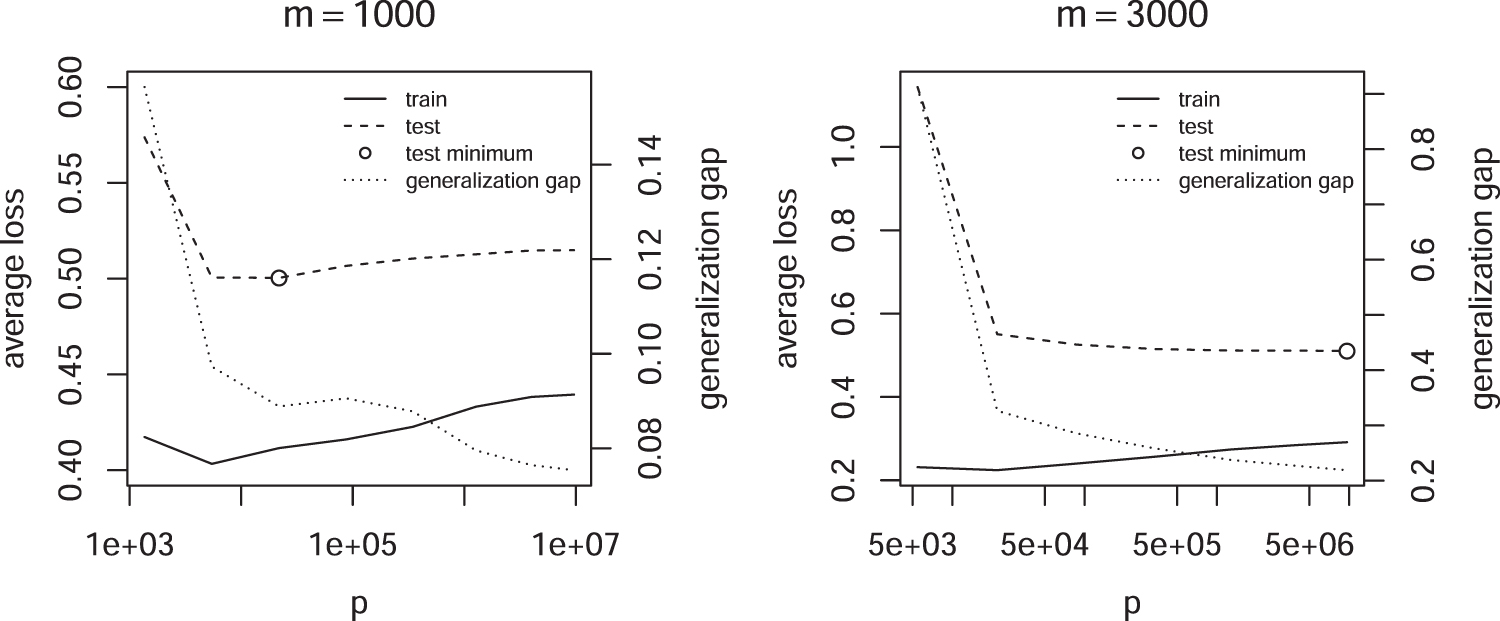
Figure 5 shows the converse case, the average loss for fixed m but variable p. Also in this case no double descent of the test error is observed. However, the training error increases with p after reaching a minimum, because the regularization strength must increase to keep m fixed. The generalization gap, that is, the difference between test and training loss, steadily decreases, showing that the capacity of seems to decline.
Average loss as a function of p and fixed m.
5. Conclusion
Several iterative feature selection methods were discussed in this study. MP is among the simplest methods, but can lead to poor subset selection because of its overly greedy strategy (Hastie et al., 2009). More advanced methods, such as LARS and the homotopy algorithm, often yield better results in practice. The estimates of LARS with Lasso modification are equivalent to solving the Lasso problem (P1) for all regularization strengths . Extensions to GLMs are more expensive to compute, because there exists no analytical solution to the values at which the active set of features changes. As a result, many more iterations are required to compute a full regularization path. In practice, one is often not interested in the full solution, because estimates with m and features provide very similar predictions.
Algorithm 1 instead computes for an a priori defined sequence a leapfrog regularization path . This algorithm can be derived from proximal gradient descent or a simple modification of LARS for GLMs. It is very effective for high-dimensional problems where only a small subset of features is required for making accurate predictions. It is less greedy than MP, because it does not simply select one feature per iteration. As opposed to LARS, which computes subsequent breakpoints, Algorithm 1 iteratively refines the regularization strength until a given number of m features is selected.
On a data set of DNA sequences the algorithm very efficiently computes the leapfrog regularization path despite the high-dimensional feature space, where LARS-GLM is computationally too expensive. In addition, the number of selected features m allows a good control of model complexity. An implementation of the algorithm is available at: https://github.com/pbenner/kmerLr
Footnotes
Acknowledgments
I thank Martin Vingron and Kirsten Kelleher for their comments on the article and many inspiring discussions.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
P.B. was supported by the German Ministry of Education and Research (BMBF, Grant No. 01IS18037G).
References
1.
BelkinM., HsuD., MaS., and MandalS.2019. Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proc. Natl. Acad. Sci. U.S.A. 116, 15849–15854.
BennerP., and VingronM.2020. ModHMM: A modular supra-Bayesian genome segmentation method. J. Comput. Biol. 27, 442–457.
4.
BoydS., BoydS.P., and VandenbergheL.2004. Convex Optimization. Cambridge University Press, Cambridge, United Kingdom.
5.
BühlmannP., and Van De GeerS.2011. Statistics for High-Dimensional Data: Methods, Theory and Applications. Springer Science & Business Media, Berlin, Germany.
6.
CheemaP., and SugiyamaM.2020. A Geometric Look at Double Descent Risk: Volumes, Singularities, and Distinguishabilities. arXiv preprint arXiv:2006.04366.
7.
DefazioA., BachF., and Lacoste-JulienS.2014. Saga: A fast incremental gradient method with support for non-strongly convex composite objectives. In Ghahramani, Z., ed. Advances in Neural Information Processing Systems, 1646–1654. Curran Associates, Inc., New York, NY.
8.
DonohoD.L., and TsaigY.2008. Fast solution of l1-norm minimization problems when the solution may be sparse. IEEE Trans. Inf. Theory. 54, 4789–4812.
9.
DuinR.P.2000. Classifiers in almost empty spaces. In Proceedings 15th International Conference on Pattern Recognition. ICPR-2000, volume 2, 1–7. IEEE, Barcelona, Spain.
10.
EfronB., HastieT., JohnstoneI., TibshiraniR. et al.2004. Least angle regression. Ann. Stat.. 32, 407–499.
11.
HashimotoT., SherwoodR.I., KangD.D., et al.2016. A synergistic DNA logic predicts genome-wide chromatin accessibility. Genome Res. 26, 1430–1440.
12.
HastieT., TibshiraniR., and FriedmanJ.2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer Science & Business Media, New York, NY.
13.
KelleyD.R., SnoekJ., and RinnJ.L.2016. Basset: Learning the regulatory code of the accessible genome with deep convolutional neural networks. Genome Res. 26, 990–999.
14.
LeeD., KarchinR., and BeerM.A.2011. Discriminative prediction of mammalian enhancers from dna sequence. Genome Res. 21, 2167–2180.
15.
LozanoA., SwirszczG., and AbeN.2011. Group orthogonal matching pursuit for logistic regression. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 452–460. JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL.
16.
OpperM., KinzelW., KleinzJ., and NehlR.1990. On the ability of the optimal perceptron to generalise. J. Phys. A Math. Gen. 23, L581.
17.
OsborneM.R., PresnellB., and TurlachB.A.2000. A new approach to variable selection in least squares problems. IMA J. Numer. Anal. 20, 389–403.
18.
ParkM.Y., and HastieT.2007. L1-regularization path algorithm for generalized linear models. J. R. Stat. Soc. Series B Stat. Methodol. 69, 659–677.
19.
TibshiraniR.1996. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Series B Stat. Methodol. 58, 267–288.
20.
TroppJ., and GilbertA.C.2007. Signal recovery from partial information via orthogonal matching pursuit. IEEE Trans. Inform. Theory, 53, 4655–4666.
21.
ValletF., CailtonJ.-G., and RefregierP.1989. Linear and nonlinear extension of the pseudo-inverse solution for learning Boolean functions. Europhys. Lett. 9, 315.
22.
YangB., LiuF., RenC., et al.2017. Biren: Predicting enhancers with a deep-learning-based model using the DNA sequence alone. Bioinformatics, 33, 1930–1936.

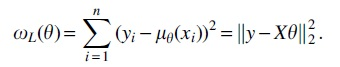
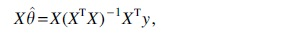
 is a projection matrix. Therefore, the OLS solution
is a projection matrix. Therefore, the OLS solution 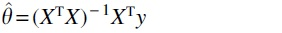 can be interpreted as the scalar projection of y onto H. If the covariates are appropriately normalized, that is,
can be interpreted as the scalar projection of y onto H. If the covariates are appropriately normalized, that is, 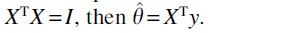 Most importantly, XTy can be interpreted as the correlation of y with X. The OLS solution satisfies
Most importantly, XTy can be interpreted as the correlation of y with X. The OLS solution satisfies 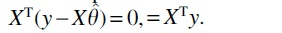 , which shows that the residuals are uncorrelated with X. Many feature selection methods decrease the correlation
, which shows that the residuals are uncorrelated with X. Many feature selection methods decrease the correlation 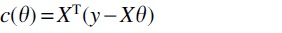 iteratively starting with
iteratively starting with 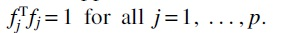 for all
for all 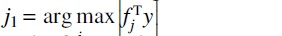 . Hence, the algorithm selects the feature j with the largest scalar projection of y onto fj, or the feature that is most correlated with y.
. Hence, the algorithm selects the feature j with the largest scalar projection of y onto fj, or the feature that is most correlated with y. the covariate matrix restricted to
the covariate matrix restricted to 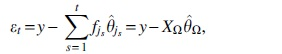
 can be interpreted as the correlation of the jth feature with the residuals
can be interpreted as the correlation of the jth feature with the residuals  might be less informative.
might be less informative.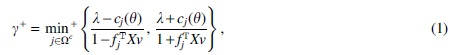
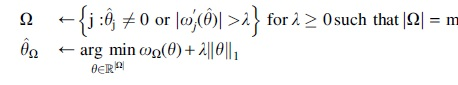
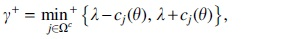
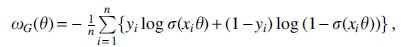
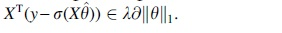 . SAGA (Defazio et al., 2014) is used as gradient descent method to compute solutions of this optimization problem. To guarantee stable convergence of the gradient descent method, the data are normalized to unit variance.
. SAGA (Defazio et al., 2014) is used as gradient descent method to compute solutions of this optimization problem. To guarantee stable convergence of the gradient descent method, the data are normalized to unit variance.