
Abstract
The use of machine learning (ML) allows us to automate and scale the decision-making processes. The key to this automation is the development of ML models that generalize training data toward unseen data. Such models can become extremely versatile and powerful, which makes democratization of artificial intelligence (AI) possible, that is, providing ML to non-ML experts such as software engineers or domain experts. Typically, automated ML (AutoML) is being referred to as a key step toward it. However, from our perspective, we believe that democratization of the verification process of ML systems is a larger and even more crucial challenge to achieve the democratization of AI. Currently, the process of ensuring that an ML model works as intended is unstructured. It is largely based on experience and domain knowledge that cannot be automated. The current approaches such as cross-validation or explainable AI are not enough to overcome the real challenges and are discussed extensively in this article. Arguing toward structured verification approaches, we discuss a set of guidelines to verify models, code, and data in each step of the ML lifecycle. These guidelines can help to reliably measure and select an optimal solution, besides minimizing the risk of bugs and undesired behavior in edge-cases.
Introduction
Over the past decade, huge improvements have been made in the field of machine learning (ML) 1 to solve various industrial problems. Extensive research has been done to train and tune optimal models, which has ultimately led to automated ML (AutoML), an approach that can efficiently search over a vast set of potential ML pipelines. 2 This development made the possibility of democratizing artificial intelligence (AI) appear realistic. On the downside, these solutions are often impractical for real-world applications or fail shortly after deployment.
One of the reasons for such behavior is that modeling can be automated via AutoML, whereas the verification of potential solutions is still a manual and unstructured process, often resulting in suboptimal choices. In software development, this is avoided by verification: “Did I build what I told” and validation: “Did I build what is needed.”
This differs in ML context: Here only, Validation is considered for the ML model alone whereas Verification needs to be done over the whole system in which the model is integrated. In the majority of cases, only validation is performed via common approaches such as cross-validation (CV) or explainable AI (XAI) and verification is either missing or ignored. This is because a huge focus is placed on improving the predictive performance of the models that validation ensures, whereas many other crucial metrics and tests for verifying the stability/robustness (verification tests) are neglected, making the ML models unsuitable for real-world scenarios.
For instance, commonly used ML models (ex. Deep Neural Networks [DNNs]) are a black box and judging the reliability of the ML models purely based on validation techniques such as CV cannot be justified. This makes the verification tests crucial, but as discussed, verification needs to be done for the whole ML systems, that is, the systems utilizing ML models, and not looking at the model in isolation.
In this article, we discuss a set of best practices and guidelines to perform structured verification at each phase of the ML development process (ML lifecycle) in three dimensions, namely data, code, and model. The verification of these three components at every phase could indicate the verification of the ML system at whole.
The data component would constitute the data used for training the model as well as the data obtained from the model's predictions, which are used by other systems/as an end result. The code component would include a code for model interfaces, data generation/preprocessing, model training/testing and inference, etc. The model component constitutes the ML model itself on which validation such as CV is performed. The phases of the ML lifecycle along with the defined dimensions are introduced next:
ML lifecycle
We structure the ML process in the following lifecycle scheme consisting of five phases that are dynamically linked and allow continuous iterations throughout the lifespan of the ML product. The used lifecycle scheme has a close correspondence to the CRISP-DM model, 3 DevOps, 4 and MLOps.* In contrast to MLOps, we do not separate the phases between modeling and deployment, but we assume them to be interlinked. The five phases, namely business understanding (BU), data acquisition and exploratory data analysis (DA & EDA), Modeling, Deployment, and Monitoring, along with their interrelations are illustrated in Figure 1.
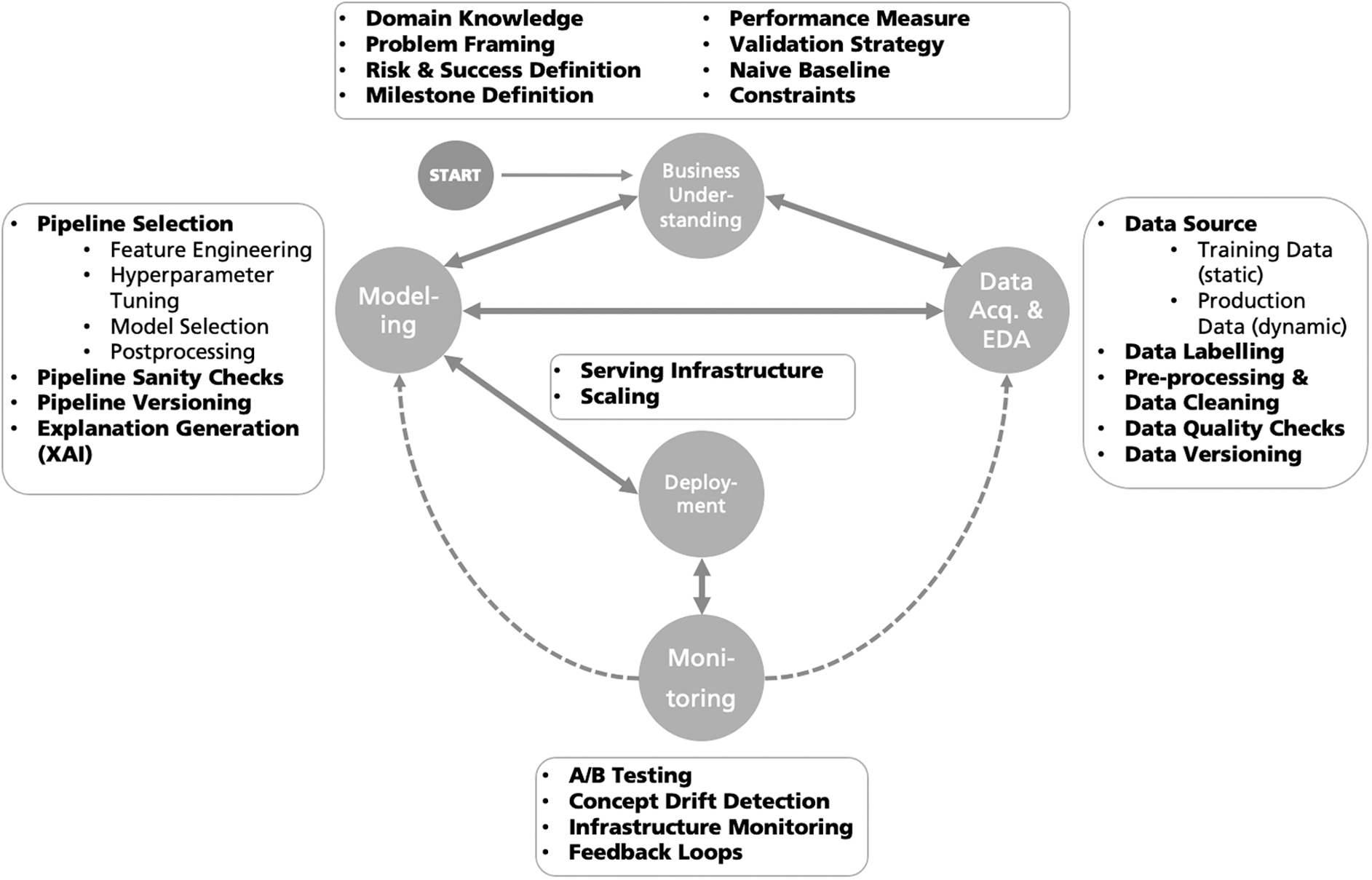
The ML lifecycle with five phases and their interconnections. ML, machine learning.
These phases are further divided into three dimensions (data, code, and model) on which verification is performed. We define these dimensions next, already outlining key challenges that we see within each dimension when it comes to verification.
Data
ML is preferred for problems where data are complicated, and formalizing an intended solution analytically is not possible. In many cases, the nature of data can pose additional challenges while designing ML systems. For instance, temporal data differ from the usually expected independent and identically distributed (i.i.d) data due to its dependence on time component and the procedure to model on these data are different. Thus, there is a need to capture/verify the distinctive nature of the data for proper modeling.
Code
Code is written for the majority of phases in the ML lifecycle, starting from transforming and extracting the raw data, labeling (in supervised learning), feature engineering, feature selection, model building, performance evaluation, and deployment. The verification of such code is necessary to detect bugs in earlier stages of the pipeline, and failing to do so leads to error propagation across various stages of the ML lifecycle. We argue for the need of unit or integration tests analogous to software verification tests in the ML lifecycle to catch code bugs effectively.
Model
In many cases, additional data are collected based on predictions of a trained model and these new data are used to update the model via feedback loops. If the model is biased, the updates further worsen the model due to bias amplification.5–7 So, the trained ML model needs to be verified against such biases besides (adversarial) robustness and user requirements. These are discussed in detail in each phase to highlight the need for verification tests to catch such model regressions. Gathering information about the model also helps in modeling an ML governance process to check the model's behavior against inherent bias, skew and edge-cases, 8 as well as in understanding the decision-making process of the model.
Nevertheless, the developers of ML systems are not the end-users (at least in the industrial applications we consider in the Applications and Methods section) and hence quality assessment such as model performance solely from a developer's view cannot be guaranteed. This can be solved by either testing the systems via crowdsourcing platforms such as Mechanical Turk † or through experimentation on real users via beta testing. 9
The importance and goal of verification
Before digging deeper into the structured verification of ML systems in next sections, we discuss the importance of verification and elaborate on the verification and validation (V&V) performed in traditional business processes that vary for ML applications.
In the Business to Consumer scenario, an error might only lead to small losses due to customer churn or a marketing issue whereas an error in industrial settings might lead to more severe consequences. For example, when utilizing ML for visual part inspection (VPI) to identify contamination in food production or person identification in self-driving cars, errors can easily lead to casualties. With such increasing usage of ML in these applications, the correctness of the holistic ML system needs to be ensured, not just the correctness of the model.
In quality management systems such as ISO 9000, business processes are defined, which ensures that the customer requirements are fulfilled. In these processes, there is a distinction between V&V. Verification checks that the product or service fulfills the specifications, whereas validation on the other hand checks that the system meets the operational needs of the user. Although V&V ideally ensures the correctness of the system under test, this can rarely be guaranteed or proven. Formal verification aims at verifying the formal specifications. This cannot be achieved in ML systems, if training data is considered the (partial) specification of the system's behavior.
Hence, the goal of the V&V process is to reduce the risk of a problem in the system. In software engineering, this is typically achieved by means of several test methods such as unit tests, integration tests, etc. These tests typically do not check the SUT under all conditions but are designed well enough to cover the most important situations, typically including, for example, boundary conditions. This implies that the passing of all run tests indicates the correctness of the SUT. However, in ML, tests are done by means of examples. Therefore, crafting the right test would include selecting examples that correspond to the boundary conditions, where the boundary conditions are changing due to the nature of the ML model and the right text example is not in the data set used for training it.
However, more important is that if one test fails, it is an indication that one needs to dig deeper because it is likely that many more uncovered errors are present in the system. A method that is often applied compared with well-designed tests is the so-called random testing methodology, which tests the SUT with random situations. Here, independent samples are generated randomly from the input domain and passed to the SUT to test its behavior.
Although random testing is rather an effortless testing method, it suffers from its reliance on randomness, for example, the test could fail simply because it was unlucky in selecting a nonpassing test sample. The typical testing methods in ML, such as CV, correspond to random testing, as the cases are drawn from a pool of data. CV tries to overcome the randomness in random testing since one unluckily selected fold would be averaged out over the other folds. Still, it remains important in CV to measure not only the mean but also the variance over the folds.
Often, it is recommended to utilize XAI to overcome these effects. However, inspecting the results and decisions based on a single run is similar to debugging in software engineering. The XAI methods may not provide any conclusive evidence or proof for correctness but can only generate human trust into the correctness, such as debugging does in software engineering. Hence, XAI should not be used for generating evidence in a V&V process but only to identify issues in the SUT.
Checklist for structured verification in ML systems
Providing a common structured verification approach that can be applied to any domain is hardly possible due to the necessary complexities involved. Hence, we propose a methodology to derive such a set of guidelines that can be applied in the development of ML systems. Many teams have a specific domain or use-case cluster, for which a structured verification list can be derived by using our proposed methodology.
Our approach is adopted from the principles in the realm of software development. The first principle is the idea of Test-Driven Development, 10 that is; for each function/feature, an automated test is developed before it is implemented. A functionality is only developed if it fixes (or passes) a test and this principle guarantees that the code is error free. The second principle is that for any mistake that has occurred once, it must be ensured that it will not occur again. In the context of software, this means that the root cause of the bug is identified, which can be in either the user specifications or the code itself. Afterward, the current automated tests are analyzed to check whether they are complete enough and free of redundancies.
In the context of the structured verification for ML systems, the tests correspond to the items that need to be checked throughout the development process of the ML model. In addition, it is desired to automate these verification tests wherever possible. In later sections, we define these tests in the BU phase of the ML lifecycle, and we implement them for verification in the corresponding phases of the lifecycle that are derived for typical industrial application fields.
Applications and methods
We focus on three applications that are typical in the industrial settings: (1) quality inspection (QI) 11 , (2) predictive maintenance (PM), and (3) anomaly detection (AD). This serves as a preliminary for the further sections, where specific challenges of those applications are discussed within the concept of the ML lifecycle. The interdependence of these applications is depicted in Figure 2.
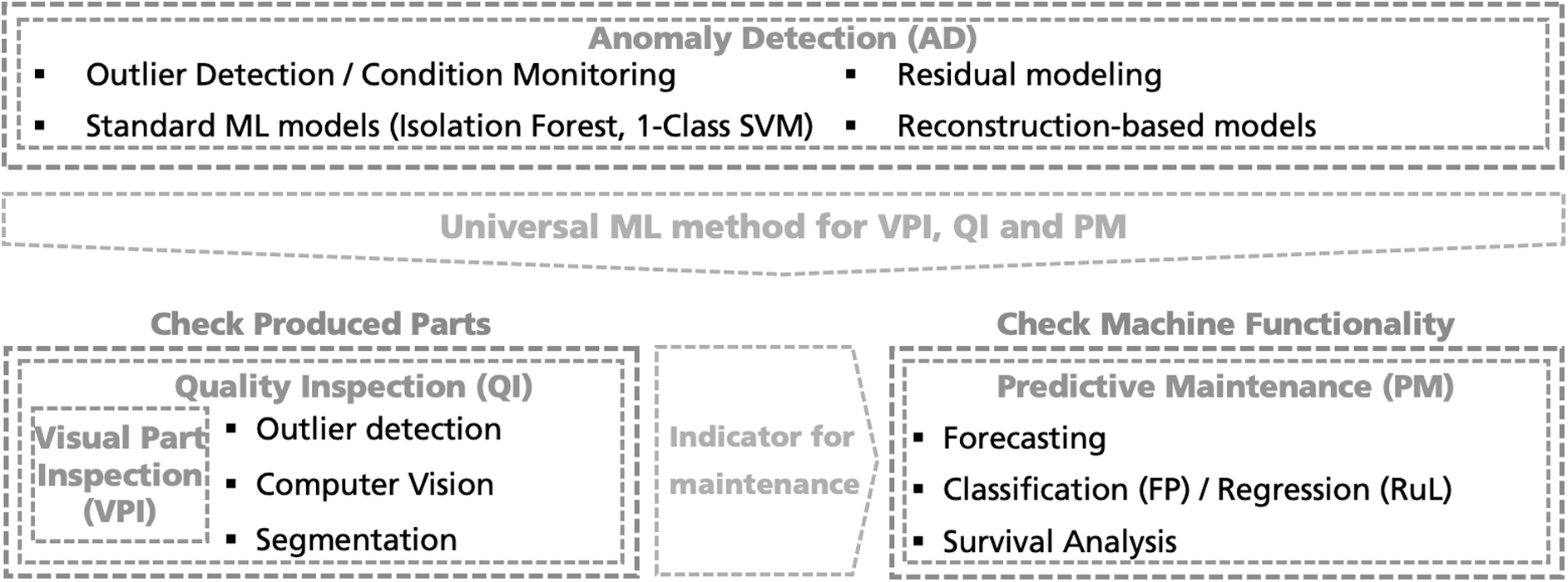
ML applications within industrial production that are treated in this work.
To summarize, the article is focused toward bridging the gap between software engineers having limited knowledge on ML processes and the ML researchers/engineers lacking the ability to bring ML into production. We attempt to bring these two worlds together, and our key contributions are as follows:
We structure the ML process in a lifecycle scheme consisting of five phases and further disentangle each phase into data, code, and model dimensions to identify and understand the key issues in detail. We distinguish between V&V of the ML models and argue that solely performing validation of an ML model cannot be considered as an indicator for its reliability. Hence, we insist on the structured verification of the ML system at every phase of the ML lifecycle. We propose a methodology that can assist in deriving a checklist for structured verification in each phase of the ML lifecycle focusing on certain industrial applications.
In the realm of this work, the rest of the article is organized as follows: The Related Work section discusses on the prior literature. In the Structured Verification in ML Lifecycle section, we will discuss on the structured verification for the complete ML lifecycle, which comprises five phases that are further divided into three dimensions: data, code, and model. Finally, we conclude our study in the Conclusion section.
Related Work
Previous research8,12,13 advocates for the management and versioning of model and data in addition to the code. This is due to the fact that the issues exist at a system level rather than the code level and the data influence the behavior of ML models. Sculley et al. 12 discussed these issues as hidden technical debt in ML systems analogous to software engineering and argued that this debt needs to be reduced to avoid huge maintenance costs. In a similar notion, Breck et al. 13 provided tests specifically for data, model, and infrastructure and formulated an ML test score to help reduce this technical debt.
In addition to the technical debt, our work also relates with issues discussed under the terminologies of shortcut learning, 5 underspecification, 14 ML fairness, 6 adversarial robustness 15 and drifts, 16 among others. Especially, we relate our finding across different dimensions to shortcut learning and underspecification, which are discussed in brief here.
Shortcut learning
Shortcut learning describes a phenomenon where the model utilizes nonrobust features to distinguish between different objects of interest. Geirhos et al. 5 state that many of these shortcut opportunities are a consequence of natural relationships, for instance, grazing cows are typically surrounded by grass lands and the model uses this unintended background for its prediction rather than taking the characteristics of the cow into consideration. In the famous Pascal VOC dataset, 17 all images labeled as horse contained a source tag where removing the tag removed the ability of the ML model to classify it as a horse. 18
In literature, this is also typically referred to as the Clever Hans effect. 19 The ML models that learn these spurious correlations present in the data are prone to shortcut learning and fail to perform well on unseen real-world data.
Underspecification
Due to the expressiveness of modern ML models, a limited data set will almost always lead to situations where multiple predictors may solve a single task with similar predictive risk. 14 In other words, the ML pipeline may return one among many similar models that might or might not encode credible inductive bias. This degrades the trust over the ML system, and D'Amour et al. 14 propose different stress tests to evaluate the obtained model's behavior for robustness and against requirements that are not guaranteed by evaluations on i.i.d data.
In the next section, we discuss the different phases of the ML lifecycle as proposed in Figure 1 across data, code, and model dimensions along with recommended practices to avoid pitfalls and to design better ML models. The categorization of dimensions and phases in the ML lifecycle is not strict and is made for the sake of our convenience.
Structured Verification in ML Lifecycle
We now discuss on verifying each phase of the ML lifecycle focusing on the industrial applications mentioned earlier (c.f. the Applications and Methods section). At the end of each phase, we also summarize the checks that can be performed over all the three dimensions (data, code, and model). It must be noted that the list is not exhaustive and only contains a subset of checks that we consider crucial for each phase.
Business understanding
This is arguably the most important phase in ML projects, as there is always a risk involved that a data scientist makes a decision aimed at improving the performance of the model without necessary domain understanding. 20 This phase marks the first step of all ML projects and includes discussions between the ML Experts and the Domain Experts, which also involves product owners and stakeholders (customers) in case of industrial projects. To yield a realistic understanding and evaluation of the problem, reasonable baseline estimates and potential constraints are discussed. This allows one to estimate the underlying risks of the project and also points toward expected successes.
Mistakes in this phase often result in a complete restart from scratch. Therefore, it is important that the interaction between the ML experts and the stakeholders is not to be limited to this phase only and should be part of all phases for a successful ML project.
With the help of domain knowledge, the problem is framed and the performance metrics as well as evaluation strategies are selected while taking stakeholder's requirements into consideration. We mention the selection of such performance metrics 21 separately in Figure 3. Additionally, we provide a brief overview of the selection of perfomance metrics based on the nature of data in Table 1.

Selection of performance metrics.
Overview of the choice of performance metrics based on data
AD, anomaly detection; AUC ROC, area under ROC; ML, machine learning; PR, precision-recall; VPI, visual part inspection.
As discussed, the correct problem framing is key in ML projects. For instance, in PM, the task can be framed as a regression (estimated time until machine breakdown), classification (probability of machine breakdown in a given time span), or survival analysis problem (survival probability of the machine over time). 27 Hence, a proper framing of the problem, quality of model's prediction, and choice of proper performance metrics are considered as the most important challenges.
The key result of this requirements engineering is to ensure all the requirements from the stakeholders are collected pertaining to data, model, and code and to decide on a set of verification tests to verify against these requirements. These verification tests act as Definition of Done for the subsequent phases.
Issues in this phase also arise in case of miscommunication between the Domain Experts and the ML Experts, which could result in erroneous project requirements. In many companies, this phase is handled by a Requirements Engineer. Requirement Engineering for ML is challenging, especially when the model is integrated into conventional (software) systems, which have their own requirements. Apart from playing an integral role in formulating the user/stakeholder's requirements, the Requirements Engineer needs to be aware of other requirements such as General Data Protection Regulation (GDPR), freedom from discrimination, etc. 20 These requirements can also be considered as Quality Assurance in an ML context and are elaborated across the three defined dimensions later.
Data
A major challenge for Domain Experts is to distinguish normal from flawed behavior. This information is crucial since unclear information would lead to incorrect labeling, thereby resulting in incorrect ML models. For example, in QI, a sample (e.g., image of a production part) may be labeled as a defect only if there is a specific broken part, but not if there are only visual defects. In some other situations, both the cases can be considered a defect. Since it largely depends on the task at hand, the requirements should specify such data complexities to construct correct labels in the later stages to avoid undesirable results.
The Requirements Engineer also needs to collect the requirement on how the model should generalize on the data and decide on the validation strategy to later perform train, validation, and test splits. This is especially important, as an improper validation scheme can give an overoptimistic estimate over the test set whereas the ML system can fail dramatically in a real/production environment incurring huge potential losses. 28 This can be avoided by choosing a proper CV technique that largely depends on the nature and size of data.
This CV technique does not help to learn better models but to deliver reliable estimates of the true performance of the model in deployment. 28 However, since CV is time consuming, it might not be suitable for large datasets and data heavy deep learning (DL) applications. We mention some potential problems and appropriate CV techniques to be used in such situations in Table 2.
Overview of cross-validation techniques
CV, cross-validation; DL, deep learning; OOS, Out-of-Sample Evaluation.
The datasets used in CV must also be analyzed to ensure that there is no overlap between train, validation, and test sets. For instance, many datasets are temporal in nature and a random split assuming i.i.d data would result in validation and test sets not matching the real world.
Further, this phase should consider the fairness aspects to exclude potential harmful features and include only ethical/legally okay ones. It is because the learned patterns may encode prejudices degrading the credibility of ML systems. In addition, a few sensitive features may need to be collected to check the model's bias against them. For instance, MAC/device address is sensitive data and should not be utilized for ML modeling whereas gender might not be used for ethical reasons but needs to be collected to control/verify the model's fairness against this feature.
Nevertheless, eliminating such sensitive features is challenging, if a model is trained on sensitive features and we remove the attribute, the model might find a redundant encoding in terms of other features and wind-up modeling sensitive features without explicitly being asked. 6 Hence, requirements on how to ensure our model is fair against bias (fairness constraints) need to be defined here and accounted for in modeling and monitoring phases.
As the ML training is dependent on both code and data, testing of data quality needs to be considered as a separate new class of requirements. The requirements should not be on the quantity but rather on the diversity of the samples and must be checked for completeness, consistency, and correctness 20 of the data. Completeness refers to sparsity of the data to cover a whole range of possible values; consistency refers to a uniform format and representation of data in the complete dataset. Correctness refers to the degree of trust that the data are truly from the data-generating process (e.g., free from adversaries) 32 and need to be verified by verification tests after ML modeling.
All these requirements depend vastly on the way the data are collected and how they should reflect the real-life data. We explain ways to verify these requirements in detail in the subsequent phases.
On a side note, it is important to verify these requirements regarding data quality even for validation techniques such as CV, because the reliability of the estimation obtained by CV depends on the data and cannot be trusted if the quality is not verified; this further strengthens our claim that validation tests such as CV that are performed over the model in isolation are not sufficient to ensure the system's performance in real-life data.
Another potential pitfall regarding the data is the construction of the features that are based on the independent variables that are inputs to the ML model. In some situations, the features are faulty, unavailable, or engineered differently during training and serving time (when the models are integrated into a different system), which may lead to degradation in model performance or failed deployment. The root cause in such issues can be identified by distributing a raw holdout dataset during deployment along with the trained model artifact and reassess the model performance on this raw holdout dataset. 8
For example: If a sensor providing certain data is broken and passed to the model, the model would deliver faulty predictions. This can be identified either by sanity checks on the model's input data or by integration testing. In addition, we can also assess the performance of the model on a holdout set and make sure it is the sensor that is broken and not the model. This strategy is defined in this phase as a requirement to create a holdout set and should be used as a verification test along with other tests (such as sanity checks) in the deployment phase.
Code
In bigger teams, a common challenge that the ML lifecycle faces is that different teams own different parts of the code and there is a handover across different phases without a clear expectation of how to cross these boundaries. 8 For instance, the transfer of code without clear documentation from DA & EDA to the Modeling phase might lead to delays and friction in the project if they are handled by different people, which is a common scenario in larger teams.
Another potential threat is in writing code for performance evaluation, which is done before any development following the test driven development (TDD) principle. Here, even small logical bugs in the generation of such tests can lead to big estimation errors. 33
The requirements should also include information regarding the deployment to ML systems, where the trained models need to be converted into a different format for faster inference such as on edge devices (embedded devices, android/iOS devices, etc.). One commonly used format is Open Neural Network Exchange (ONNX), ‡ and the deployed models can be verified against the original model via differential testing. Such differential tests test the dissimilarity of the outputs of two similar systems given the same input and are capable of catching errors that cannot be caught via regular testing.
In some cases, the interface of external services/applications consuming the model can change that might lead to failure in the deployment. For example: The external system that was earlier utilizing the ML model's prediction probabilities might now only use binary or Boolean output. This issue is generally identified by means of Contract tests in software engineering. So, the possibility of such occurrence in ML systems needs be noted in this phase so that they can be verified later in the deployment phase by means of Contract tests.
Model
The aspects of security and transparency of a model comes under the Non-Functional Requirements of ML systems. 34 In cases having legal and regulatory requirements (e.g., GDPR), explainability or transparency may be even more important than predictive power. 20 This is possible either by constraining the model to derive explanations or via XAI techniques. 35 Still, explainability might not be helpful because the model is prone to adversaries 36 and shortcut learning due to its reliance on nonrobust features. A Requirements Engineer needs to explicitly include explainability requirements from a user's point of view and focus on specifying situations that demand explanations. 20
The model also lacks the ways to distinguish between the type of patterns it utilizes while training (leading to shortcut learning, underspecification, and adversarial attacks), so it is not possible to rectify them even by increasing the size of datasets. 37 The only way to verify the occurrence of such issues is to test the models on adversaries and out of distribution (o.o.d) datasets that are systematically different from the i.i.d training data used.
These tests can reveal a mismatch between intended and learned rules such as making decisions only based on pixels or background rather than the object characteristics. For example, in VPI, we need the ML model to identify the defective parts only based on the Region of Interest (say deformation in machine gears) and not the background. So, we must define such o.o.d test cases in this phase that need to be implemented in later phases to verify the model's prediction quality and ensure trust in the model's correctness. 38
Another important aspect of this phase is the definition of baseline methods jointly with the Business Experts. Reasonable baselines are crucial to place the model performance in perspective, as it can be trivial to present a very complex model with great performance without mentioning the fact that a simpler method was not too far behind. 33 Such baselines could range from simple ones such as majority voting based on the training data distribution to more complex rule-based systems that might be already in place at the client side. In the Modeling phase, these baselines will be implemented and the desired models are evaluated against them.
Lastly, this phase should also include the freshness requirements of the model, a Requirements Engineer should specify how often retraining is necessary to protect against data/concept drifts 39 and adversarial attacks based on what the client considers as risk. Besides, the requirements must also contain details of desired metrics that needs should be considered to satisfy the quality requirements. 13 For example, if the model is provided as a service, then constraints such as latency, uptime, power consumption, etc. should be mentioned in service level agreements (SLAs) and models must be verified against this after deployment.
The summary of checks for this phase is provided in Table 3.
Summary of checks for business understanding phase
BU, business understanding; o.o.d, out of distribution; SLAs, service-level agreements.
Data acquisition and exploratory data analysis
This phase is deeply entangled with the first phase, requiring close cooperation and reiterations with the Domain Experts. Understanding the data profoundly is preliminary to both, understanding the business problem and to better assess the feasibility of the project. This phase aims at acquiring, verifying, and preparing the datasets for the subsequent modeling phase. In addition, we extensively discuss verifying the data via sanity checks because the varied properties of data mainly constrain the ML application.
Data
It is desired to have data free from any kind of bias, because it is almost evident that the data are biased when humans are involved in labeling it. This is known as Data bias and can be introduced via selection bias, capture bias, and label bias among others. 40 This poses a major challenge to pick verification techniques for developing well-generalizing models. Instead, we can try to create unbiased datasets. Although it is very difficult to remove bias from the data, Torralba and Efros 40 provide recommendations on developing datasets that avoid or at least minimize the effects of the biases mentioned earlier.
The raw data are often obtained from multiple sources and need to be checked for missing data, uniformity, bias, robustness, and stability of data-generating sources. This data generation can happen both ways, either data points are from different sources or the features are created separately.
It is vital to know such dependencies before modeling to save the time and effort of acquiring all the features in data (feature extraction might be costly in some cases). Instability in data can also arise when the input of our ML model is dependent on another ML system and the changes occurring in that ML system are not known to the downstream dependencies. This causes data drift in our intended model (detailed in monitoring phase). Other data dependencies include 13 :
usage of legacy features that were included early in the development but become redundant over time,
using many features to slightly increase the performance, at a cost of increased vulnerability,
unknowingly using a correlated feature instead of a real (causal) one.
These dependencies result in a nonrobust ML model, because the learning may happen via shortcut learning, making them also prone to adversarial attacks. To a certain extent, we can mitigate the issues arising from (1) and (2) by keeping track and using only sufficient features but it is not possible to tackle (3) as it is very difficult to determine the features that influence ML model predictions.
To minimize errors in the presence of such multiple data-generating sources, we need tests to verify input data against an expected schema. This is important to maintain uniformity and can also help to localize errors to a particular source. 41 The schema tests need to verify the features to fall within expected ranges (numeric features) or take only certain values (categorical features). 28 Also, the schema should be flexible enough to accommodate drifts in the feature distribution in training data due to changes in real-world distribution. 41 These checks can be considered as static checks that are performed before modeling, and Breck et al. 13 provide detailed information on constructing such a schema and tests over this schema can be considered as sanity checks.
In addition, we can also use Pipeline tests as sanity checks to verify the data given to the model at batch time (i.e., when new data arrives). It reduces pipeline debt, which occurs when unclear and forgotten features are buried inside the codebase as the system matures. Libraries such as Great Expectations § provide a framework in the form of assertions to test such data pipelines easily.
Apart from this, verifying the data quality in train, test, and validation sets is equally important. The validation and test sets should reflect data on which we expect the model to generalize well. Both these sets must be chosen from the same distribution, and the test set should be large enough to accommodate diverse samples to give high confidence in the overall performance of the model. 42
Especially, the quality of test data is crucial as it influences the acceptance criteria of the trained model over a chosen performance metric. Mani et al. 43 stress the necessity to measure the test dataset quality and propose test case generations to broaden its coverage over the training set. Their study on the quality of most common datasets on popular DNNs such as VGG-19, 44 LeNet, 45 etc. showed that the performance over test data is not a proper metric if the test dataset is not good enough. We also discuss about Neuron Coverage in the Modeling phase that can be used to generate test cases over the trained ML model.
Code
The impact of code bugs is tremendous if not rectified in earlier stages, so quantifying it in case of ML applications is nontrivial. In cases where the decision regarding feature construction takes place before data collection, unit testing of all the feature generation code is crucial. If not, it results in faulty data for both training and test sets, which remain unnoticed until the monitoring phase where we will observe a drift from the real distribution even though we obtained better performance while modeling as the test set is also faulty.
In the majority of cases, an engineer may end up writing a massive amount of supporting (wrapper) code to get data in and out of generic packages such as Pytorch, Tensorflow, etc., which makes code maintenance difficult. Sculley et al. 12 discuss such anti-patterns occurring in ML systems due to glue code and further state that the systems might end up being less expensive by creating a native solution rather than using many different generic packages. Another issue discussed is the pipeline jungles that occur due to the presence of intermediate file artifacts, temporary patches, multiple joins, etc. creating unmaintainable pipelines and technical debt. These can be avoided by better data collection and feature engineering practices.
Model
As discussed in the BU phase, we need to verify the model's performance on samples dissimilar to the training data (o.o.d). Geirhos et al. 5 argue toward making such o.o.d test cases a standard practice by adding to the current i.i.d tests. These o.o.d tests can be related to edge cases in software systems. One example for such a test is to verify shortcut learning in QI, where only the pixels from Region of Interest (ROI) can be passed to the model and its output is verified. Another test would be to simply black out the ROI pixels and verify whether the model's output is based on the background or the ROI itself.
It is also vital to verify models against adversarial attacks, because Neural Networks are vulnerable to adversarial samples. 32 To test the models against such adversaries, we can design adversarial samples before the modeling and check the model's robustness in the next phase (similar to TDD in software development). If the model fails the test, then the first step would be to make the model more robust and if the issue still persists, then another model should be selected that is less prone to adversaries.
Carlini and Wagner 46 proposed advanced attack models that can be used to design such test cases. In addition, ML model verification tools and techniques are becoming predominant to check robustness against such adversaries.47,48 However, it is not possible to test against all the adversarial attacks, but if these tests are passed, we can only hope that our selected model is robust but cannot guarantee its robustness against all kinds of adversarial attacks.
The summary of checks for this phase is provided in Table 4.
Summary of checks for data acquisition and exploratory data analysis phase
DA & EDA, data acquisition and exploratory data analysis.
Modeling
Modeling constitutes the third phase where we take the preprocessed data and configure the ML pipeline. This pipeline consists of feature engineering, model selection, hyperparameter tuning, and postprocessing.
The ML models created in this phase are dynamic in nature and are not only limited to change in hyperparameters or initializations but also in its input, where a change in the input feature would shift its effect on the predicted output. This phenomenon is commonly known as CACE (Change Anything Changes Everything),12,49 which makes it necessary to evaluate the data and model simultaneously.
Data
The quality of test data for ML modeling is crucial, and metrics such as Neuron Coverage 50 and its variants51,52 are used in the literature to generate test cases under the implicit assumption that increasing Neuron Coverage would increase the test set quality. These are analogous to code coverage in traditional software development. Recent advances 53 showed that Neuron Coverage cannot to be considered as a meaningful criterion since it is easy to generate samples with 100% coverage that are less natural/nonrealistic.
Another important aspect is to verify the collected data for leakage to avoid overoptimistic estimates of model performance after deployment. Data leakage can occur when training samples are also used in testing unintentionally. It can also occur when the features of data are normalized altogether before CV and then split into train, validation, and test sets. This is because the distribution of test data leaks indirectly by the normalization to the train data.
In addition to leakage, data contamination can also occur if the data in CV are used for tuning the hyperparameters of the ML model. This can be avoided by using the nested CV approach, which can be computationally expensive in some cases. There are also various ways in which data can be contaminated and potential solutions also exist to avoid them. 28
Code
During modeling, improper maintenance of code paths/branches increases difficulty in maintaining backward compatibility. 12 Most of the branches are never to be integrated and only contain a code that is usually not relevant. It is always suggested to clear out dead and experimental code paths that grow over time and version the required code along with data for reproducibility.
Apart from the regular code versioning tools such as Git, there are many tools available that can be used for versioning both data and code, in addition to model management. Examples of such tools include Data Version Control, ** Mlflow, †† Weights & Biases ‡‡ that help to visualize multiple experiments along with their parameters and performance metrics. 8
Also, for mature systems, the complexity of configuration files can even exceed traditional software. This makes it more vulnerable to mistakes and cannot be detected by code tests. 49 A solution for this issue should be to maintain modularity even in configuration files, which can be achieved via tools such as Hydra §§ and review configuration files in code review.
Model
The goal for this phase is to create a model that generalizes well to new, unseen data. It is always a good practice to move from simple models to complex ones for improving over the baseline established in the BU phase. This also helps to prevent model overfitting, which happens when the model memorizes the training set or starts to model random noise in the training data and eventually fails to generalize over unseen data. This commonly occurs when large/complex models are trained with comparatively less data; hence, it is crucial to mitigate this overfitting on the training data. This is ensured by the aforementioned evaluation strategies discussed in BU and the use of methods such as regularization, early stopping, etc.
Simplicity of a model is also preferred where the explanation of predicted results is more important than the model's performance. It is easier to obtain explanations for simple ML models than complex black box Neural Networks. For instance, a high-performing complex DL model may be created by utilizing sensitive features whose transparency is required by the law (GDPR). However, obtaining explanations for such a model is challenging and hence a tradeoff between performance and transparency is made. One possible solution to obtain a higher performing fair model is to engineer features that are uncorrelated with the sensitive attributes in the feature space. 6
This is generally not possible in high-dimensional data such as images. Other potential solutions involve applying XAI techniques such as LIME, 54 SHAP, 55 etc. to the trained ML models that can provide information regarding features influencing the model's prediction and help detect correlated features, which might also include sensitive attributes. However, the explanations generated from these techniques may not detect all such correlations and removing them based on these explanations may not guarantee a model free from discrimination/bias.
This makes it crucial to verify the performance of the trained model for inherent bias in the training data. There might be more data points for a given value of feature than others. For example, the gender male can be present in the majority of data points, making the model biased toward it. So, it is important to check the performance across different slices of data and visualize the slices and feature distribution in the datasets. 8 Barocas et al. 6 provide methods to reduce bias by incorporating fairness in a model agnostic manner without the need of retraining.
As discussed briefly in the Data Acquisition and Exploratory Data Analysis section (model dimension), it is impractical to test the ML model against all adversaries and the defined tests can only verify the model's robustness against selected adversaries, which creates the need for designing robust models. Especially, DNNs are prone to such adversarial samples because they are typically overparameterized and there is a significant redundancy, making them susceptible to adversarial attacks. Han et al. 56 discuss pruning redundant connections that can reduce overparameterization and help in making the models robust to adversarial attacks.
Finally, once a suitable model is determined, it is important to verify it against other user-specific requirements decided in the BU phase to ensure that it does not break any contract with its customers after deployment. 8
The summary of checks for this phase is provided in Table 5.
Summary of checks for modeling phase
XAI, explainable AI.
Deployment
In this phase, the model output is finally delivered to the client, which can be a human decision maker as well as a subsequent machine. There exist different levels of deployment complexities that are often constrained by hardware infrastructure. However, before delivery, the selected model must be verified for its compatibility to the client's infrastructure and more importantly against SLAs specified in the BU phase.
Data
The access of data at deployment also depicts a common challenge in ML pipelines but does not correspond to the availability of data. We expect the ML pipelines that are developed over the static training data to perform equally well with dynamic real-world data streams, which usually is not the case. Moving from a static to dynamic setting comes with two general issues, which needs to be handled:
First, it must be ensured that during deployment, the data are available in a complete and trusted manner. This can be done by verifying the new incoming data using the sanity checks that were implemented in the DA & EDA phase.
Second, some ML applications require real-time availability of the data, meaning that model inference must be done within certain time bounds. For instance, in PM tasks, this real-time availability is crucial and is not met if the databases are updated only on a daily/weekly basis.
Code
As a good coding practice, we should try to reuse the code wherever possible between training and deployment pipelines to avoid training serving skew 9 and potential errors that might occur due to bugs in the code. The tests for this skew are most important but least implemented in the majority of ML projects. 13
As discussed in BU, we need to perform differential testing before deployment to make sure that the predictive performance achieved by the productionized model is the same as the original one. 8
If required, we also need to implement Contract tests as discussed in the BU phase to verify the compatibility of our selected model's interface with the external consuming application.
Model
We need to test the quality of trained models to either reject or deploy them to production. This can be done by checking various thresholds via automated tests. For instance, the models can be thresholded over normalized error rate over holdout data and can be rejected if they are below a certain threshold percentage.
If the trained ML model is being integrated into an already existing system, we need to verify the proper functioning of the system and model together, which is done by means of integration testing. Here, we perform verification at a system level and ensure that the system works end-to-end without any issues, especially at the interfaces.
We also perform Unit Testing of the deployed model on the raw holdout data, 8 which was set aside before modeling (discussed in the BU phase). This is helpful in assessing whether the trained model that is integrated into the existing system is at fault, if the performance of the whole system drops. If the unit test passes, then the performance drop can be attributed to the change/fault in the dependent systems.
For instance, imagine a VPI task where the model was trained on raw images processed by imaging system A. Between the modeling phase and the deployment phase, the firmware to preprocess the images was secretly updated to system B. Here, the unit testing of the ML model on the raw holdout set would be helpful to detect this change in the image processing pipeline. If the unit test fails with the new system B but passes with the old system A, this allows detecting this hidden change on the system level and avoids faulty model predictions in the future.
In cases when the deployed model needs to be replaced with a newer version either due to the addition of new/better features or due to drift (detailed discussion in the next phase), shadow models 8 can be deployed. If the shadow model performs well, satisfying the user requirements, then it replaces the older model, immediately preventing downtime to customers.
The summary of checks for this phase is provided in Table 6.
Summary of checks for deployment phase
Monitoring
This constitutes the final phase of the lifecycle and only terminates if the underlying application or project is ended. The deployed model is continuously monitored according to defined measures in the BU phase to ensure the stability of both the model and incoming data. In this phase, model updating and retraining with new, incoming data might be initiated. In addition, the stability of the deployment infrastructure and hardware is continuously monitored and checked for breakdowns.
This phase is particularly important in the cases of online learning, because the models are retrained by the data collected in production, which has the capability to influence the model's prediction via feedback loops.
Direct feedback loops occur when the model is influenced by its own decision. This causes a shift in class distributions and is predominant in cases of bias amplification or AD tasks. 8
Hidden feedback loops are difficult to detect and they mainly occur in the presence of multiple ML models used for independent tasks but are interrelated, where an improvement of one system leads to the degradation of another.12,57
These online learning models use algorithms that improve their performance with the arrival of new data, making the versioning and monitoring of both training and production data important. For instance, it is crucial in the context of QI, where the information of broken parts is added to the data to enable continuous improvement of the model via retraining.
In general, the monitoring of ML models in production is done via Human in the Loop approach, where several aspects need to be monitored: 8
inputs to the model: to give visibility of emerging training-serving skew if any
outputs of the model: to understand the performance over real data and decisions that are being made with these outputs (in cases where the outputs of ML models are being used to control other systems)
model bias: the model's response/output against sensitive features such as race, gender, etc.
model interpretability: to understand which features influence the decision that can be obtained by using LIME, SHAP, saliency maps, 58 counterfactuals, 35 etc.
The aspects mentioned earlier can provide the maintainer with actionable insights to either retrain the model with additional data (via 1 or 2) or discard it if the learning is not as intended (via 3 or 4).
The major function of this phase is to detect the presence of drifts/distribution shifts and possibly determine its type to deal with the issue. In the majority of cases, drifts in the ML model can be attributed to either a change in the input/target distribution or the relationship between them and each type; these drifts and their occurrences are studied separately in Table 7. However, it is important to know the presence of these shifts/drifts because in cases where there is no drift, the standard models perform better. 63
Taxonomy of different drifts in machine learning (clear solutions of problems are under active research, so we only provide causes instead of potential solutions)
Data
In dynamically changing environments, the data evolve over time, making its underlying distributions of either input or target or both to change, leading to different kinds of drifts. These drifts may introduce new concepts or the previously seen concepts reoccur again. 16 If the occurrence of a specific drift is known, necessary modifications can be carried out to obtain better performance in the real world. Storkey 63 studied the occurrence of such drifts under the terminology of dataset shifts.
Along with unit and integration tests discussed in earlier phases, ML models need additional tests due to its tight integration with data. We can perform basic statistical tests to compare mean, median, and standard deviation min/max values between training and real distributions. 49
Advanced tests such as skew tests can help in determining the representativeness of training data over live/real data. These tests involve monitoring the percentage of missing data in training versus real data. The proportion of these missing data can also be assessed through the Chi-squared test, 64 analysis of variance or t-test if features are normally distributed 49 or a Kolmogorov-Smirnov test whether features are continuous and not heavily skewed. Apart from these, metrics such as Population Stability Index (PSI) and Character Stability Index (CSI) can be used to measure scores based on distribution changes and can determine the performance of deployed ML models.
Code
As this phase involves only monitoring of the ML systems after deployment, there is no code involved other than implementing verification tests for the other two dimensions.
Model
It is more important which actions are performed based on the model's output rather than its predictive performance. We must detect whether the selected performance metric aligns well with the requirements discussed in the BU phase. If a change in the feature attributes improves the direct objective function but degrades the performance of KPIs, then the objective function must be revisited.9,42
The model's output must be monitored for distribution changes to check the presence of label drift (c.f. Table 7), and this can be done with the same tests mentioned earlier, that is, Kolmogorov-Smirnov and Chi-squared tests. In addition, the model's predictions must be verified against the sensitive features defined in the BU phase (fairness constraints).
Apart from label drift, there are other kinds of drifts that may occur and need to be handled. Storkey 63 provides information on detecting and dealing with different kinds of shifts/drifts, where each drift can be dealt with via a different form of modeling and no single model can deal with all the kinds of mentioned drifts.63,65 In particular, concept drift can be adapted via change detection methods used in adaptive learning and is commonly known as concept drift adaptation. 16 However, for most of the adaptation techniques, we need the true label of the data soon after the model's prediction, which is not available in the majority of cases.
If the label is available soon after the prediction (e.g., will the user click on an ad or not), we can also judge the quality of the system by comparing the distribution between the model's output and observed labels. This can detect any bias in predictions and slicing it across various dimensions helps to localize the issues and alert the user. 12 It can also be achieved with PSI, where we compare the model's output with the observed label and set bounds on them to alert if the threshold limit is crossed.
The best way to handle drifts in ML models is via retraining, which is a common approach in dynamic systems. Here, we can log real/serving inputs and manually annotate the model's output as labels to create additional data to retrain the model. A slice of this can also be held out to verify the updated model prior to deployment 13 (as discussed in the deployment phase). However, once the model updates on new data, the distribution of output changes and thresholds in the earlier mentioned tests becomes invalid. 12 Hence, we need to update these older thresholds for adapting to the newer model but a manual update is a time-consuming process. Instead, these thresholds can be learned via simple evaluation on the held-out validation data. 66
However, in many cases, the models are not updated frequently and drift away due to their dependence on data and grow stale over time. This can be handled via generating alerts for retraining by monitoring the ages of both the model and data in production and thresholding them according to model freshness requirements mentioned in the BU phase. 13
Finally, there must be the possibility of a rollback to the previous version if the model performs poorly based on the metrics monitored in this phase.
The summary of checks for this phase is provided in Table 8.
Summary of checks for monitoring phase
ANOVA, analysis of variance; CSI, Character Stability Index; PSI, Population Stability Index.
Conclusion
In this work, we argued for the need of a structured verification approach for ML systems. We provided evidence for the need of such an approach by analyzing typical errors and performance issues in different industrial settings. As shown, these issues cannot be attributed to the model alone but code and data play prominent roles. Our experiences from applying ML in various industrial domains show that our incapability to provide quality data to the model impedes them from learning reliable/robust features and hence failing to generalize well in real-world environments. This nonrobust feature learning is the root cause that makes the models prone to drifts, discrimination, adversarial attacks, etc.
This cannot be detected entirely even from the existing validation techniques such as CV or XAI, making structured verification at each phase of the ML lifecycle essential. For instance, (1) the results from CV cannot be trusted if the quality of data used to perform CV is not verified; (2) the explanations derived from XAI techniques can detect incorrectness but cannot guarantee the confidence we want to place in the ML model, as they might be able to detect biases due to a specific feature but cannot assure that removing that feature would completely eliminate the biases.
By this review, we intend to provide a methodology that can aid practitioners to derive a checklist for verifying their domain-specific ML models, in addition to their own specific checks (c.f. the Checklist for Structured Verification in ML systems section). Our discussion, by no means, provides an exhaustive checklist due to the complexities involved in creating it.
We conclude that structured verification of data, code, and model at each phase is necessary to build trustworthy ML models and recommend ML practitioners to invest longer time in verifying the data quality, which is a prime necessity toward creating robust and trustworthy AI solutions.
Footnotes
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This work was supported by the Bavarian Ministry of Economic Affairs, Regional Development and Energy through the Center for Analytics – Data – Applications (ADA-Center) within the framework of BAYERN DIGITAL II (20-3410-2-9-8) and partially supported by the German Federal Ministry of Education and Research (BMBF) under Grant No. 01IS18036A.