
Abstract
Recently, emotion recognition in conversation (ERC) has become more crucial in the development of diverse Internet of Things devices, especially closely connected with users. The majority of deep learning-based methods for ERC combine the multilayer, bidirectional, recurrent feature extractor and the attention module to extract sequential features. In addition to this, the latest model utilizes speaker information and the relationship between utterances through the graph network. However, before the input is fed into the bidirectional recurrent module, detailed intrautterance features should be obtained without variation of characteristics. In this article, we propose a residual-based graph convolution network (RGCN) and a new loss function. Our RGCN contains the residual network (ResNet)-based, intrautterance feature extractor and the GCN-based, interutterance feature extractor to fully exploit the intra–inter informative features. In the intrautterance feature extractor based on ResNet, the elaborate context feature for each independent utterance can be produced. Then, the condensed feature can be obtained through an additional GCN-based, interutterance feature extractor with the neighboring associated features for a conversation. The proposed loss function reflects the edge weight to improve effectiveness. Experimental results demonstrate that the proposed method achieves superior performance compared with state-of-the-art methods.
Introduction
Emotion representing an individual's mental state, which is a combination of feelings and thoughts, is a key semantic component for communication. In C. Darwin's third major work of evolutionary theory, 1 he has hypothesized that emotions are linked to their origins in animal behavior. His biological emphasis leads to a focus on six emotional states: happiness, sadness, fear, anger, surprise, and disgust. Plutchik 2 identified eight primary emotions, visualized by the wheel of emotions, as illustrated in Figure 1. These eight emotions can be grouped into polar opposites: joy and sadness, acceptance and disgust, fear and anger, and surprise and anticipation.
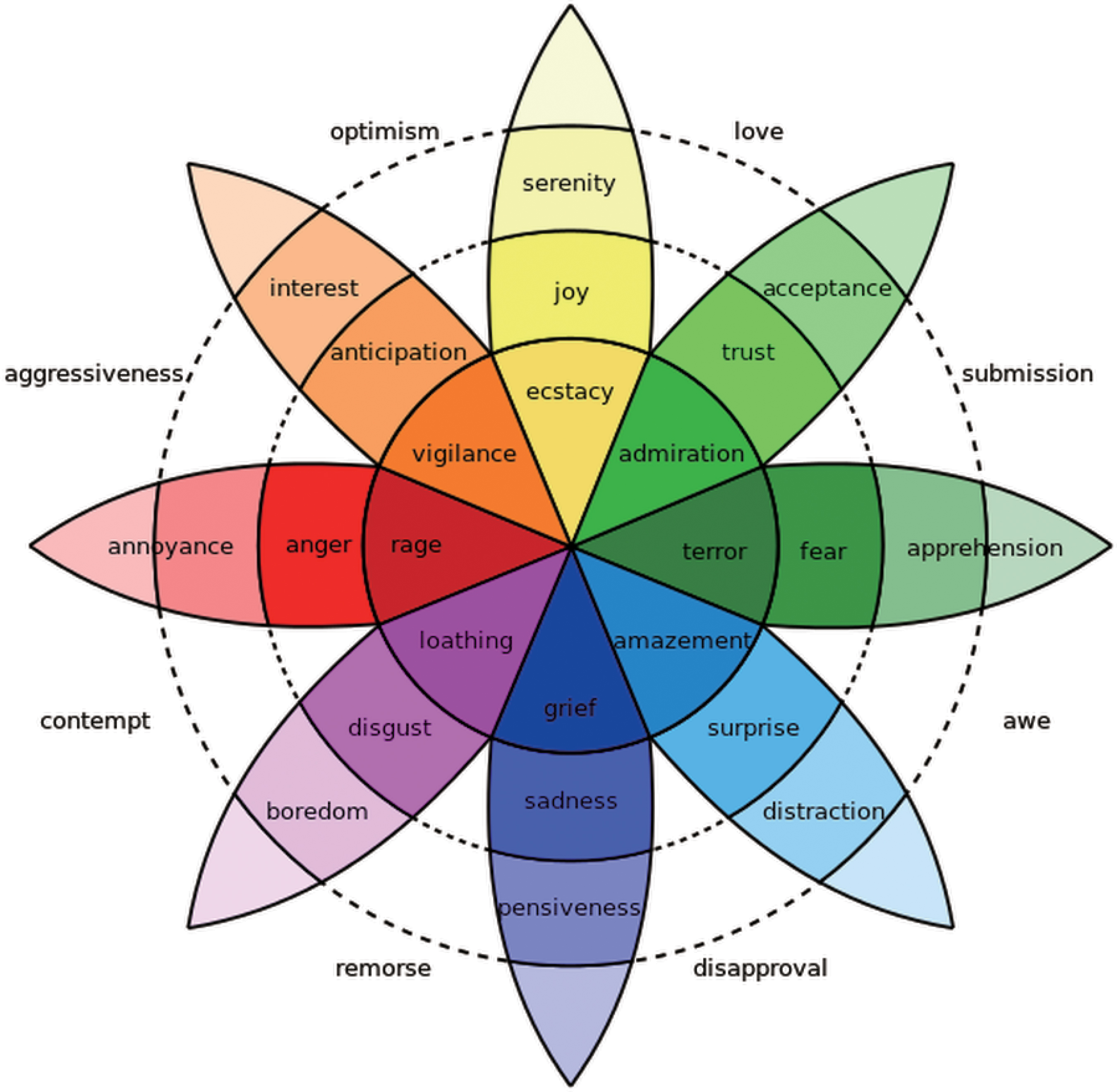
Plutchik's wheel of emotion. 2 Color images are available online.
The Internet of Things (IoT) technology is the network of physical objects that are embedded with sensors, software, and communication functions for connecting each other. The internet-connected objects exchange and analyze data and provide learned information to users. In our daily life, we generate vast amounts of data through various activities. These data consist of important information related to our lifestyle, daily routine, various activities, personality, thoughts, and emotions.
As the IoT environment with connections increases, the big data-driven approach becomes the key connecting point to provide intelligent and very personalized services. The representative technology is deep learning based on the deep neural network (DNN).3–7 By analyzing the enormous amount of information (data) from diverse internet-connected objects, we can make a more effective learning system that can provide efficient smart services such as a smart home, smart city, and smart health care.
For the interactive smart home, smart city, and smart health care, emotion recognition is indispensable in all areas that require an automated assistant service. Especially, artificial intelligence (AI) speakers are trying to understand the emotional status of users from their conversations. In this field, the deep learning scheme is very popular with a large amount of conversational data as the big data-driven approach.
Recently, with the growth of user-friendly IoT devices such as AI speaker and ChatBot, the IoT technology has further improved the conveniences of life. From these assistant devices, users expect empathy in addition to accurate information. Emotions play an important role in providing services with empathy. By enhancing the performance of emotion recognition in the IoT environment, we can expect better IoT services.
Nowadays, emotion recognition has started receiving more attention in the field of natural language processing (NLP)8–10 due to its increased demand in recommendation systems, health care, and so on. Emotion recognition in conversation (ERC) is obviously important in a dialog system with an automatic assistant. Establishing an AI assistant with strong emotion recognition ability is a step toward the construction of an artificial secretary very close to a real person.
In ERC, context modeling of both the individual utterances and the relationship between them is required. Recent works on ERC utilized a DNN to extract meaningful context information and recognize the emotions of utterances. The bidirectional encoder representations from transformers (BERT) 11 is a pretrained language representation model based on the transformer structure 12 to obtain effective context representations. The transformer model can quickly and accurately process sequential data based on a self-attention mechanism without using a recurrent structure. The BERT representations can be fine-tuned for application in various NLP tasks.
Most of the state-of-the-art methods13–15 in ERC have structures in which a multilayer, bidirectional, recurrent feature extractor such as long short-term memory (LSTM), 16 the gated recurrent unit 17 and self-attention. 12 Since conversation flows in order, a bidirectional recurrent structure is suitable for extracting temporal information using previous and subsequent sentences. In various fields of researches,12,18–20 the attention weighting mechanism that captures strong features by fusion of meaningful features has been used. Especially, the self-attention mechanism has been proven by the BERT model to be efficient in many NLP classification tasks. Therefore, it is possible to emphasize the context of each sentence through the self-attention process in ERC.
However, this mechanism-based existing ERC model does not consider speaker information associated with the utterances and the relative positions of other utterances from the target utterance. Recognizing the emotion of a sentence is strongly associated with recognizing the emotion of the speaker, therefore speaker information is the essential key.
In particular, when a speaker's emotion changes, considering the speaker information is crucial since it is mostly caused by the utterances of the other speaker. In addition, the relative positions of target and other utterances are necessary to decide how past utterances influence future utterances, and vice versa. The dialog graph convolution network (DialogueGCN) 21 alleviated this problem by modeling the conversation using a directed graph. To fit the conversation into the GCN22–24 structure, the nodes represent individual utterances and edges represent the dependency between a pair of utterances.
Although there is structural improvement by using the GCN, there are still limitations. Feeding the input dialog with the pretrained embedding technique directly into the bidirectional recurrent module has the potential to lose the unique characteristics of individual utterances. To minimize distortion of attributes, sufficient intrautterance features should be extracted before executing the temporal dependence module.
Moreover, the existing method uses the edge weight of the graph when calculating the node features, but does not use it for classification as an independent component. The edge weight in the GCN is crucial to represent a correlation between utterances. For this reason, if the edge weight is predicted incorrectly, the node feature is likely to be represented improperly. Although node features are eventually used as the final probability of classification, the prediction accuracy of edge weights is also an important factor that is worth considering.
In this article, we propose a residual GCN (RGCN) for ERC. For extracting an independent intrautterance feature, we utilize the residual network (ResNet), 25 which is widely used as a feature extractor in the computer vision field. ResNet effectively extracts features, even if the set of layers is deeply constructed, by adding the input feature of the layer to the output feature. Along with this, we design a new loss function consisting of node loss and edge loss. By adding a loss term for the edge weight in addition to the loss function for the predicted final node feature, we enhance the sophistication of the loss function.
This article is organized as follows. In the Related Work section, we introduce the related works. In the Methodology section, we present our methodology. The experimental results are shown in the Experiments section. Finally, the Conclusions section makes the concluding remarks for this article.
Related Work
A prior study on emotion recognition used the sentiment analysis. Sentiment analysis is one of the methods used for opinion mining, which is one of the most active research areas in NLP. The main use of sentiment analysis is to examine texts such as posts and reviews uploaded by users regarding the opinions about a product, service, media, and so on. For that reason, numerous researches of sentiment analysis have explored the general texts related to specific domains such as social media analytics,26,27 marketing,28,29 and finance. 30 In general, sentiment analysis aims to classify three classes: positive, negative, and neutral classes.
As an extension of sentiment analysis, emotion recognition predicts the emotions of texts such as happiness, sadness, fear, anger, surprise, and disgust. Recently, ERC has become a new trend in NLP. As one of the early ERC methods, Poria et al. 13 proposed bidirectional contextual LSTM (bc-LSTM) to capture contextual information from their surroundings. Gupta et al. 31 proposed a method to detect and enhance the emotion of the user on social media by analyzing the electroencephalogram signals from the brain. Hazarika et al. 32 proposed a conversational memory network for dyadic dialogs utilizing speaker-specific context modeling.
Later, Hazarika et al. 33 proposed an interactive, conversational memory network, which is an improved approach of their previous research. 32 Majumder et al. 14 proposed a dialog recurrent neural network (DialogueRNN) that keeps the order of the individual party states in the sequential utterances. Zhong et al. 15 proposed a knowledge-enriched transformer (KET), which applies dynamic knowledge from external knowledge bases and emotion lexicons. The current state-of-the-art model in ERC is the DialogueGCN proposed by Ghosal et al. 21 DialogueGCN solved the problem related to context propagation issues in DialogueRNN through the graph network.
The graph neural network (GNN) has recently received a lot of attention because it can represent data as a graph structure. The earliest study on GNNs was proposed by Scarselli et al. 22 Later, Kipf and Welling 23 proposed GCNs, which generalized the feature of the convolution filter to the graph. Schlichtkrull et al. 24 proposed a model of relational data with the GCN.
The existing architecture of the GCN is inappropriate for ERC. Each utterance in a dialog to be used as a node requires additional information as well as the text itself such as speaker information and the order of sentences. Ghosal et al. 21 organized the structure of the GCN to fit the dialog data.
Methodology
In this section, we introduce the proposed RGCN for ERC and loss function in detail. We first define the ERC task problem. After that our model and loss function are specifically explained.
Task problem definition
Given a conversation C, the ERC task aims to predict the emotions of constituent utterances
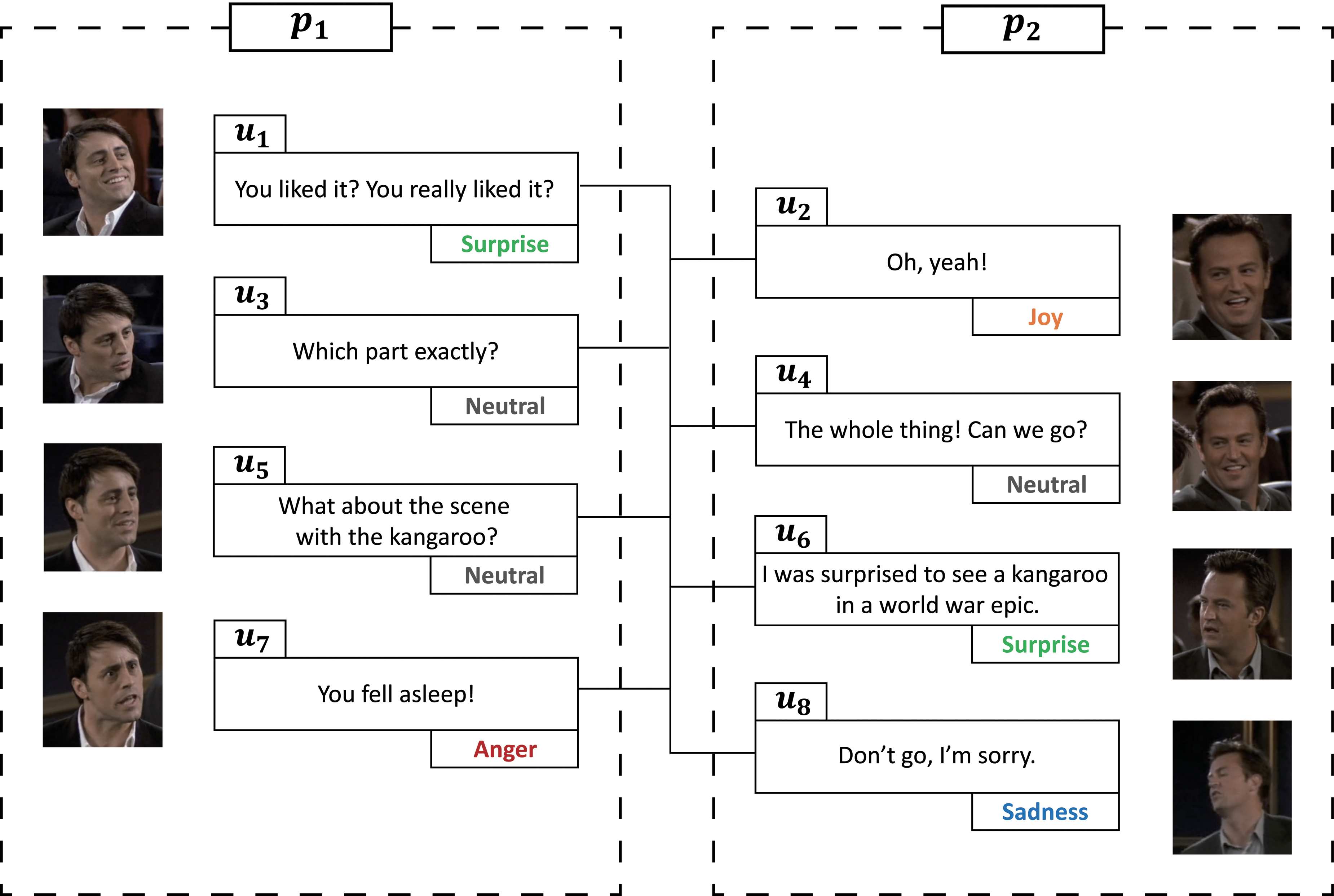
An example of an ERC task from MELD. 34 ERC, emotion recognition in conversation; MELD, multimodal EmotionLines dataset. Color images are available online.
Overview
Our RGCN for ERC is illustrated in Figure 3, which consists of three modules, intrautterance feature extraction, interutterance feature extraction, and classification. In intrautterance feature extraction, the context features for each utterance can be obtained. For this stage, the input utterances become the robust features that represent the meaningful characteristics of sentences. In interutterance feature extraction, using the intra features, we can obtain more advanced features based on the relationships between utterances and between speakers. As a final stage, the classification module outputs the probabilities of each label.
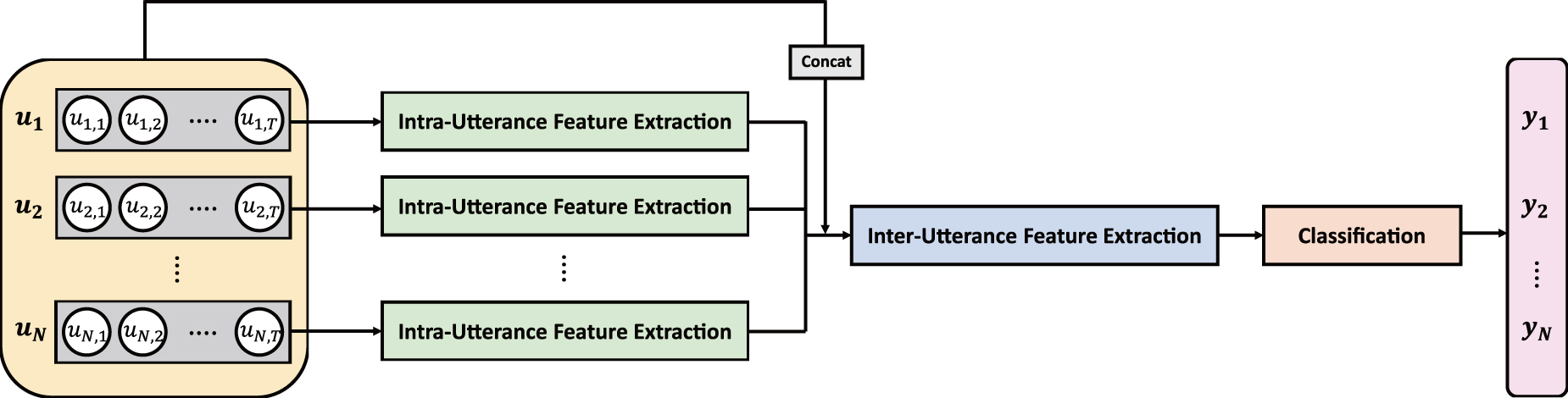
The network architecture of the proposed RGCN for ERC. RGCN, residual-based graph convolution network. Color images are available online.
The input utterances
ResNet-based, intrautterance feature extraction
ResNet is extensively utilized for feature extraction in the DNN in the computer vision field. In the general CNN, when the network is deeper, the problem of vanishing/exploding gradients occurs. ResNet introduces a skip connection that adds the input x to the output after few weight layers:
Since recent datasets on ERC include long sentences, the task becomes more challenging. In addition, the output vector size of most embedding mechanisms35,36 is not small, with 300, 600, and 1024 dimensions. Such being the case, the feature extractor of each utterance in conversation should be performed in a sufficiently deep network. For this reason, the ResNet-based structure is more suitable.
We design the intrautterance feature extractor based on ResNet, as illustrated in Figure 4. For the input of our network, a pretrained GloVe vector representation
35
is applied for the embedding mechanism. GloVe is widely used because it can capture fine-grained syntactic and semantic regularities. After obtaining the embedded utterances
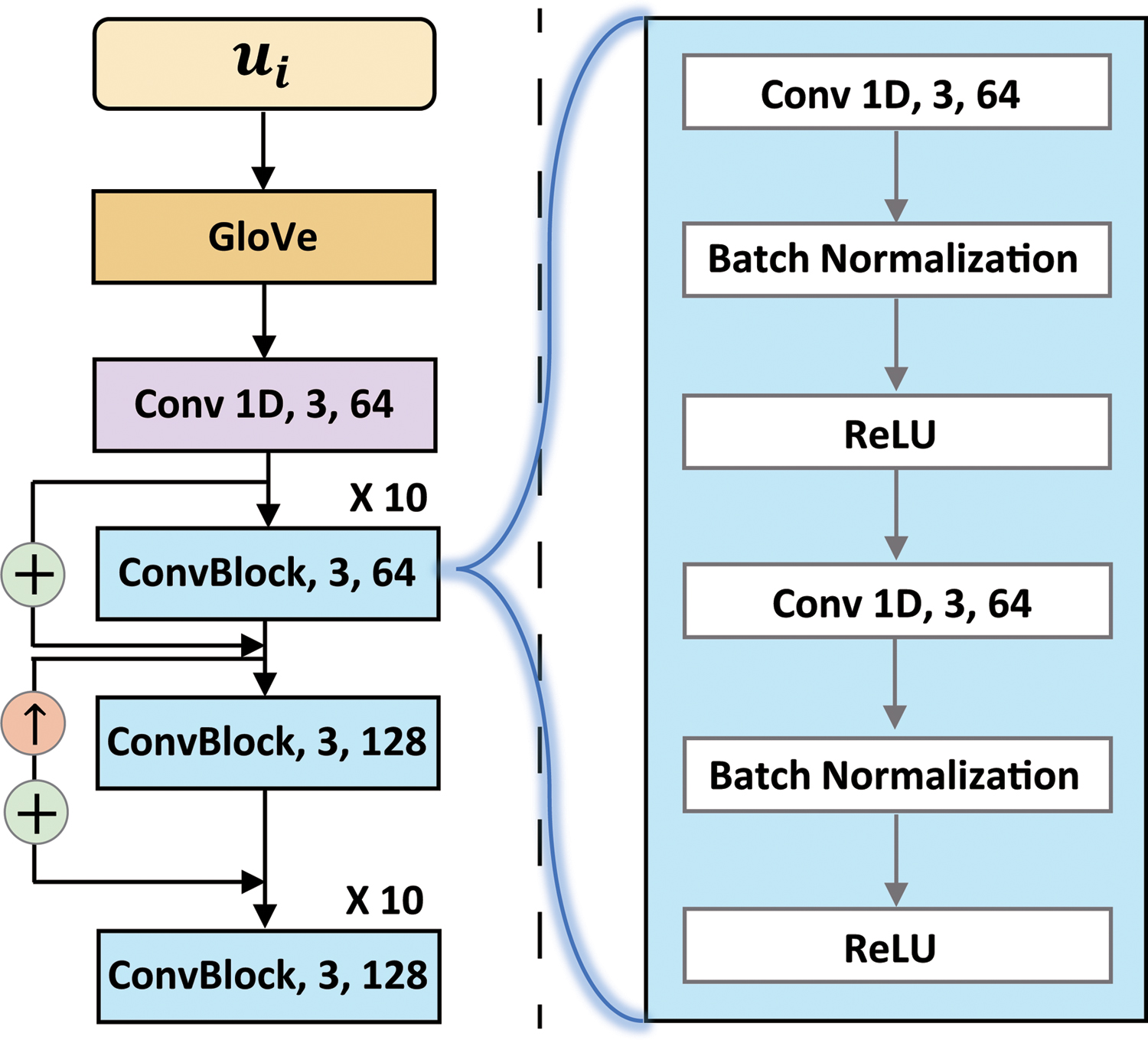
Structural details of the ResNet-based, intrautterance feature extractor. ResNet, residual network. Color images are available online.
Each convolutional block consists of a structure in which the convolutional layer, batch normalization layer, and rectified linear unit activation are repeated twice. The kernel size of all the convolutional layers is 3.
By exploiting the ResNet for the intrautterance feature extractor, we can generate a fine sentence-level feature. In other words, it can avoid the misrepresentation of its own context of utterance.
GCN-based, interutterance feature extraction
The filter of convolution has a limitation, in that it is effective for fixed grid-type data such as an image. The GCN appeared to enable effective feature extraction even from nongrid data through the structure using a graph that gives the same effect as a convolution filter. The GCN is suitable for extracting an interutterance feature in the ERC task where the relationship between utterances and the relationship between speakers can be important factors.
The architecture of the GCN-based, interutterance feature extractor is shown in Figure 5. First, we feed the intra feature into bidirectional LSTM to derive the sequential feature,
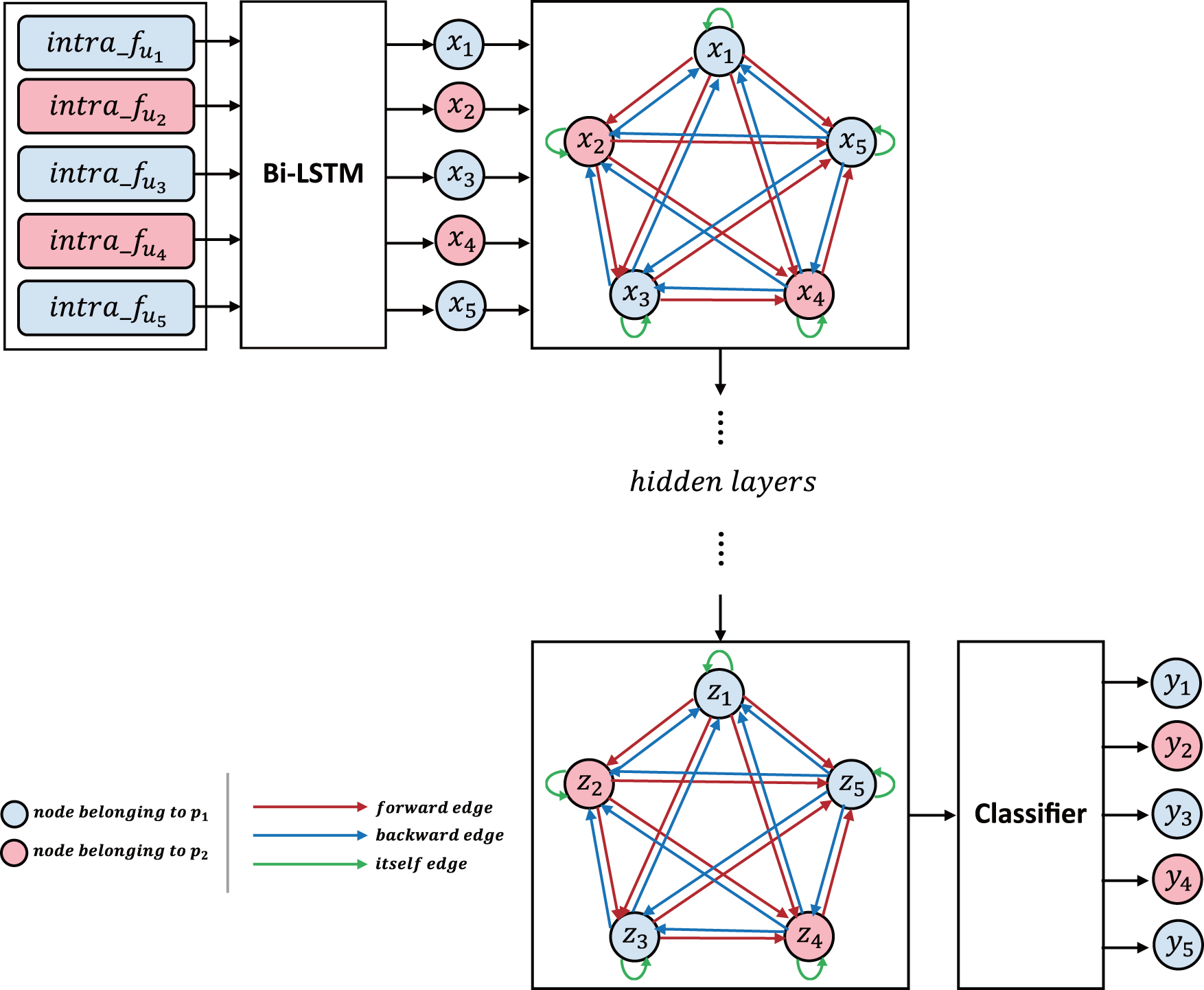
Structural details of the GCN-based, interutterance feature extractor. Color images are available online.
The representation of feature vectors after intrautterance feature extraction as a directed graph is constructed with vertices
The attention mechanism is used to calculate the edge weights
Emotion classifier
After all the feature extraction processes are completed, the sequential feature xi and final hidden feature hi are concatenated. The final utterance feature fi is derived using the softmax function with the concatenated feature as follows:
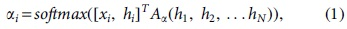
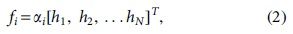
where
Eventually, the probabilities of classification for emotions of each utterance can be derived as follows:
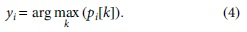
Loss function
We design a new loss function consisting of node loss Ln and edge loss Le terms. For the node loss Ln, we use the categorical cross-entropy loss function:
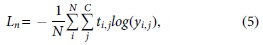
where i indexes samples and j indexes classes,
To refine the loss function for the relationship of vertices, we propose an edge loss term. Because the desired edge weight for itself should be 1, we design edge loss using this property. The proposed edge loss term is defined based on the sum of absolute deviations as
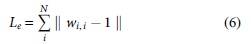
Finally, the total loss is defined as
where
Experiments
Datasets
In this article, we compare the proposed RGCN with edge loss with four methods using the interactive emotional dyadic motion capture (IEMOCAP), 37 MELD, 34 and EmoContext (EC) 38 datasets.
Interactive emotional dyadic motion capture
The IEMOCAP dataset is a multimodal dataset containing textual, visual, and acoustic information. In this article, we only target text. Each conversation consists of two speakers, namely a dyadic dialog. The emotion labels include happy, sad, neutral, angry, excited, and frustrated. Table 1 shows the data distribution of the IEMOCAP dataset.
Data distribution in the interactive emotional dyadic motion capture dataset *
Busso et al. 37
Multimodal EmotionLines dataset
The MELD is also a multimodal dataset containing textual, visual, and acoustic information generated from the Friends TV series. As the MELD consists of multiparty conversations, it is more challenging than other datasets. It is an extended version of the EmotionLines 39 dataset. It contains seven classes, neutral, surprise, fear, sadness, joy, disgust, and anger. Table 2 presents the data distribution of the MELD.
Data distribution in the multimodal EmotionLines dataset *
Poria et al. 34
EmoContext
A dialog of the EC dataset contains three utterances with two speakers. In the EC dataset, an emotion label is assigned to only the last utterance of each dialog. Examples of the EC dataset are shown in Figure 6. The emotion labels include others, angry, sad, and happy. Table 3 presents the data distribution of the EC dataset.
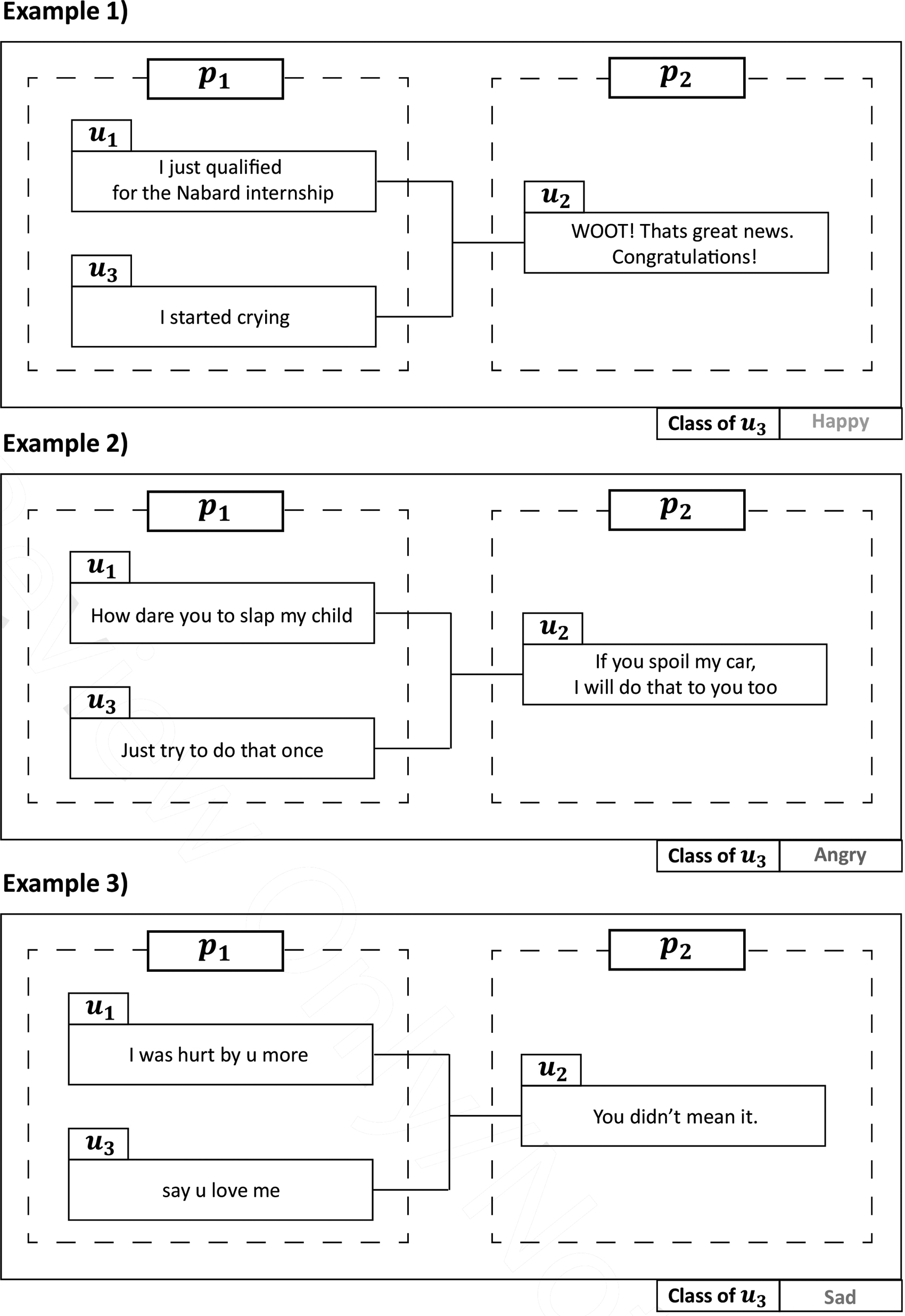
Examples of the EC 38 dataset. EC, EmoContext.
Data distribution in the EmoContext dataset *
Chatterjee et al. 38
Implementation details
In our experiments, the embedding mechanism of the 300-dimensional pretrained 840B GloVe was applied to the input of the network. We trained with setting the size of a minibatch to 32. We used the Adam optimizer
40
and initially set the learning rate to
Performance comparisons
We compared our RGCN with edge loss with several state-of-the-art methods, including bc-LSTM+Att, 13 DialogueRNN, 14 KET, 15 and DialogueGCN, 21 on three datasets. For the comparison models, we trained the models using each of the three datasets. We used the weighted average F1-scores for measuring the overall performance.
The quantitative results in terms of weighted average F1-scores on the IEMOCAP dataset are shown in Table 4. On the IEMOCAP dataset, our RGCN with edge loss achieves a new state-of-the-art F1-score of 65.08%, which is 1.15% better than the second-best model, DialogueGCN. The IEMOCAP dataset has many conversations with over 70 utterances. For the difference of performance, we can explain that extracting refined the intra features and considering edge weight for the loss function is critical in the dataset containing numerous utterances in a dialog.
Quantitative comparison with weighted average F1-scores on the interactive emotional dyadic motion capture dataset
bc-LSTM, bidirectional contextual long short-term memory; DialogueGCN, dialog graph convolution network; DialogueRNN, dialog recurrent neural network; KET, knowledge-enriched transformer; RGCN, residual-based graph convolution network.
Comparing the results for each emotion class, our RGCN does not show the best result for all emotions in the IEMOCAP dataset. Analyzing this result together with Table 1, it can be seen that other methods also show good results in the case of the emotion class with a large number of training datasets such as sad, excited, and frustrated. On the other hand, for the emotion class with a small number of training datasets, we can see that our RGCN produces the best performance. In other words, our RGCN can perform well even when the dataset is not huge. For the sad class, DialogueRNN 14 achieved the best result due to the RNN model. This means that temporal information was more effective to verify this emotion.
In Table 5, we show the quantitative results in terms of weighted average F1-scores on MELD and EC datasets. The MELD comprises multiparty dialogs with relatively short utterances. In addition, utterances rarely contain emotion-specific expressions. For that reason, emotion modeling is very difficult. Our proposed model exceeds the second-best model, DialogueRNN, by 0.41% on the MELD. Because it is a hard problem, this experimental result is good.
Quantitative comparison with weighted average F1-scores on multimodal EmotionLines and EmoContext datasets
EC, EmoContext; MELD, multimodal EmotionLines dataset.
On the EC dataset, the proposed model and DialogueGCN give the same result. The EC dataset consists of three short utterances in a dialog. It means that the intra feature extractor comprising deep layers is not suitable. Furthermore, because the dataset comprises a few edges, the proposed loss function did not play a significant role.
Conclusions
In various IoT-based systems such as smart home, smart city, and smart health care, technologies related to automated assistants that recognize the emotions of users lead to a high level of services. Particularly, the proposed algorithm can be employed in AI speakers and ChatBot to infer the emotional status of the user.
In this article, we have proposed the RGCN for ERC. Furthermore, we designed a new loss function comprising node and edge loss terms. In our network, the feature extraction module consists of intrautterance and interutterance feature extractors. The proposed intrautterance feature extractor derives its elaborate features using a ResNet-based structure with deep layers. The effective interutterance features can be extracted using the GCN structure that can utilize the relationship. Our RGCN outperforms the two datasets and gives the same result on a dataset compared with the existing state of the art. From experimental results, we verified that the proposed RGCN was suitable for datasets comprising numerous long utterances in a dialog.
Footnotes
Acknowledgments
This research project was supported by the Ministry of Culture, Sports and Tourism (MCST) and the Korea Copyright Commission in 2020.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
No funding was received.