
Abstract
Cybersecurity protects and recovers computer systems and networks from cyber attacks. The importance of cybersecurity is growing commensurately with people's increasing reliance on technology. An anomaly detection-based network intrusion detection system is essential to any security framework within a computer network. In this article, we propose two models based on deep learning to address the binary and multiclass classification of network attacks. We use a convolutional neural network architecture for our models. In addition, a hybrid two-step preprocessing approach is proposed to generate meaningful features. The proposed approach combines dimensionality reduction and feature engineering using deep feature synthesis. The performance of our models is evaluated using two benchmark data sets, namely the network security laboratory-knowledge discovery in databases data set and the University of New South Wales Network Based 2015 data set. The performance is compared with similar deep learning approaches in the literature, as well as state-of-the-art classification models. Experimental results show that our models achieve good performance in terms of accuracy and recall, outperforming similar models in the literature.
Introduction
Network intrusion detection systems (NIDS) are essential information security tools. They are used to detect malicious activities in computer networks. An NIDS is designed to monitor traffic traveling through the network. When an attack or a violation is detected, an NIDS raises an alert to notify the network administrator to take the proper action. 1 It is important for organizations to have effective network security measures in place to protect their valuable information, business reputation, and continuity. Combined with other traditional security tools, such as firewalls, access control systems, and antivirus software, NIDS are used to protect information and communication systems against attacks. 2
In the literature, NIDS are classified into either signature-based NIDS (SNIDS) or anomaly detection-based NIDS (ADNIDS). 3 SNIDS, also called misuse detectors, are used when there exists a list of predefined attacks. They work by checking the traffic against the existing attack list. Research suggests that SNIDS are effective for detecting known attacks and have less false-alarm rates than ADNIDS. 3
However, when it is required to detect new types of attacks, SNIDS becomes less effective. 3 This problem is solved by switching to ADNIDS, which are able to detect unusual traffic patterns. ADNIDS are more effective at detecting attacks that have not been previously observed. While these systems have a higher false-positive rate than SNIDS, they have gained wide acceptance in the research community on the grounds that they are theoretically capable of detecting new forms of attacks. 3
For an NIDS to detect intrusions, it considers network traffic-related features, such as duration, source address, protocol, and flag. It should then detect attacks accurately with a minimum of false alarms. In general, network intrusion detection can be formulated as a classification problem. An NIDS might classify a connection as normal or as an attack, called binary classification, or alternatively, classify a connection as normal or attack, while specifying the type of attack, called multiclass classification.
Research in intrusion detection systems (IDS) began in the 1980s, and ever since many algorithms have been used to build ADNIDS. Traditional machine learning algorithms such as random forests (RF), self-organized maps, support vector machines (SVM), and artificial neural networks (ANN) have been widely used in developing ADNIDS. However, as data sets are evolving in terms of size and type, traditional machine learning algorithms become increasingly unable to cope with real-world network application environments. 1
Despite several decades of research and applications in IDS, there are still many challenges to be addressed. In particular, better detection accuracy, reduced false-positive rates, and the ability to detect unknown attacks are all required.4,5 Recently, researchers have effectively employed deep learning-based methods in a range of applications, including image recognition, 6 emotion detection, 7 and handwritten-character recognition. 8 Deep learning has the ability to identify better representations from raw data, 9 compared with traditional machine learning approaches.
The key motivation for this work is to address these challenges. An effective model is a function of both a robust machine learning algorithm and a representative data set with relevant features. We aim to overcome the shallow learning problem via developing a deep learning-based model for ADNIDS, with the objective of classifying novel attacks by examining the structures of normal behavior in network traffic, while improving detection accuracy and reducing the false-positive rate. Feature engineering is the process of creating new and meaningful features from raw ones. The goal of feature engineering is to exploit the most relevant features for improved model performance. We investigate feature engineering compared with a simple two-dimensional (2D) representation of hand-crafted features. In addition, we wish to compare the efficacy of two deep learning approaches, namely fully connected deep neural networks (DNNs) and convolutional neural networks (CNNs), at detecting network attacks, to establish the appropriate approach for ADNIDS.
This research presents the following contributions to the literature: (1) a hybrid two-step preprocessing approach that combines dimensionality reduction and feature engineering using deep feature synthesis (DFS), 10 (2) a novel binary classification ADNIDS based on DNNs, (3) a novel multiclass classification ADNIDS based on DNNs for network intrusion detection, and (4) to the best of our knowledge, this is the first work studying the efficacy of skip connections to augment network architecture for anomaly detection, and finally, (5) this article presents a comparison of deep architectures for ADNIDS. We use a CNN architecture, and we evaluate the performance of our proposed models using two benchmark data sets: the network security laboratory-knowledge discovery in databases (NSL-KDD) 11 and University of New South Wales Network Based 2015 (UNSW-NB15) 12 data sets. We compare our results with similar deep learning approaches and state-of-the-art classification models. Our proposed models achieved high accuracy and precision values, outperforming other models in the literature, and are designed to deal with the binary and multiclass classification problems.
The rest of the article is organized as follows: The Related Work section covers the previous studies in the area of anomaly detection using deep learning and machine learning techniques. In the Methods section, an overview of our proposed models for ADNIDS is presented. In the Results section, experimental settings and performance measures are outlined, and then, we present our performance evaluation. Our conclusions and planning for future work are provided in the Conclusion section. We provide a list of acronyms used in this article in Table 1. The Appendix A1 presents some background information on preliminaries and deep learning methods.
Nomenclature of abbreviations
Related Work
NIDS play an important role in network security by monitoring traffic traveling between all devices on the network. The problem of identifying abnormal network traffic has been widely studied in the literature, and many machine learning algorithms13,14 have been used, such as Naive Bayes (NB), 15 ANN, 16 and fuzzy clustering, SVM.17,18
Although traditional machine learning techniques have been widely used to detect network attacks, they still require significant preprocessing. Such algorithms require feature engineering and assume the availability of handcrafted features. 19 However, with fast-paced technological advancements, the size of everyday data sets available to organizations is growing. Thus, shallow learning with traditional machine learning algorithms may not be suitable to deal with real-world environments since it relies on high levels of human involvement in data preparation.19,20 In addition, these techniques have the disadvantage of low detection accuracy. 20 Deep learning has emerged recently and demonstrated success in many real-world problems. It has the ability to automatically capture features and correlations in large data sets. 20
Aldweesh et al. 21 presented a survey on deep learning approaches for anomaly-based intrusion detection systems, including a taxonomy of various IDSs and future research directions. A review of IDS based on deep learning approaches by Ferrag et al. 22 also presented the various data sets used in NIDS and the performance of seven deep learning models under two new real traffic data sets.
A highly scalable and hybrid DNN framework called scale-hybrid-IDS-AlertNet was proposed in the study by Vinayakumar et al. 5 The framework may be used in real time to effectively monitor network traffic to alert system administrators to possible cyber attacks. It was composed of a distributed deep learning model with DNNs for handling and analyzing very large-scale data in real time. The authors tested the framework on various data sets, including NSL-KDD and KDD’99. On NSL-KDD, the best F-Measure for binary classification was 80.7% and 76.5% for multiclass classification.
A DNN model was proposed by Tang et al. 23 to detect anomalies in software-defined networking context. Basically, a simple DNN was used with an input layer, three hidden layers, and an output layer. Training was conducted using the NSL-KDD data set. With six features, the model achieved an accuracy value of 75.75% in the binary classification problem.
A self-taught learning (STL) deep learning model for network intrusion detection was proposed by Javaid et al. 6 The first component of the model was the unsupervised feature learning, in which a sparse autoencoder was used to obtain feature representation from a large unlabeled data set. Then, the second component was an ANN classifier that used Softmax regression classification. Using the NSL-KDD data set, the model obtained accuracy values of 88.39% and 79.10% for two-class and five-class classification, respectively.
Yin et al. 20 proposed a model for intrusion detection using recurrent neural networks (RNNs). RNNs are especially suited to data that are time dependent. The model consisted of forward and back propagation stages. Forward propagation calculates the output values, whereas back propagation passes residuals accumulated to update the weights. The model consisted of 20 hidden nodes, with Sigmoid as the activation function and Softmax as the classification function. The learning rate was set to 0.1, and the number of epochs to 50. Experimental results using the NSL-KDD data set showed the accuracy values were 83.28% and 81.29% for binary and multiclass classification, respectively.
Deep learning and traditional machine learning can be hybridized to improve intrusion detection accuracy. A combination of sparse autoencoder and SVM was proposed by Al-Qatf et al. 24 The sparse autoencoder was used to capture the input training data set, whereas the SVM was used to build the classification model. The model was trained and evaluated using the NSL-KDD data set. The obtained accuracy values were 84.96% and 80.48% for two-class and five-class classification, respectively. These results outperform the performance of traditional methods, such as J48, naive Bayesian, RF, and SVM.
Shone et al. 25 also combined deep learning and traditional machine learning algorithms. A nonsymmetric deep autoencoder (NDAE) was used for unsupervised feature learning. Then, an RF was used for the classification task. Two NDAEs were arranged in a stack, where each NDAE was composed of three hidden layers. In each hidden layer, the number of neurons is the same as the number of features. The KDD’99 data set was used to evaluate the model. Results showed an accuracy of 97.85% for five-class classification.
The effectiveness of several deep learning algorithms in classifying the KDD’99 data set was assessed by Vinayakumar et al. 26 The authors tested CNN and the combination of CNN with other architectures, such as RNN, long short-term memory (LSTM), and gated recurrent unit. Experimental results showed that the CNN-LSTM outperformed other network structures in multiclass classification, whereas the simple CNN surpasses all other network structures in binary classification. The CNN-LSTM obtained accuracy values of 96.4% and 98.7% for two-class and five-class classification problems, respectively.
Li et al.
27
presented an image conversion method for NSL-KDD data. The preprocessing stage converts various feature attributes into binary vectors, and then, the data are converted into an image. Several experiments were carried out for the binary classification problem using two CNN models: ResNet-50 and GoogLeNet. Using NSL-KDD Test
Wu et al. 28 built a CNN and an RNN for the classification of the NSL-KDD data set. The authors focused on solving the data imbalance problem by using the cost function-based method. The cost function weight coefficients of each class are set based on the training sample number. The reported accuracies of the deep learning models outperformed traditional machine learning algorithms, such as J48, NB, NB tree, RF, and SVM. However, the accuracy of the CNN model was slightly lower than that of the RNN model.
Altwaijry et al. 29 developed an intrusion detection model using DNN. The proposed model consisted of four hidden fully connected layers and was trained using NSL-KDD data set. The DNN model obtained accuracy values of 84.70% and 77.55% for the two-class and five-class classification problems, respectively. The proposed model outperformed traditional machine learning algorithms, including NB, J48, RF, Bagging, and Adaboost in terms of accuracy and recall.
Although deep learning has demonstrated success in many applications, its performance is not ideal when dealing with small or unbalanced data sets. 4 Tavallaee et al. 11 observed that the KDD’99 data set has redundant records, in both the train and test sets. This implies that reported accuracy values for the majority of models in the literature may not be representative of the performance of the models on real-world data. We believe that most classifier's performance (on KDD’99) would degrade when tested on the NSL-KDD data set. The performance of published ADNIDS models using balanced and representative data sets is yet to be investigated.
In addition, research efforts in developing ADNIDS models using machine learning or deep learning techniques show that better results are obtained in the binary classification of intrusions compared with multiclass classification. 11 In general, the performance of ADNIDS machine learning models for multiclass classification is not satisfactory. Thus, the ADNIDS problem remains an open problem.
A more recent trend sees ADNIDS researchers studying the applicability of the proposed models to real-world data sets. For this reason, we choose to study the performance of our models on NSL-KDD, an unbiased but old data set, to validate our model with known works, and UNSW-NB15, 12 a more recent data set that is representative of real-world data.
Methods
In this study, we use a CNN architecture to build binary and multiclass classification models for ADNIDS. CNNs are one of the best learning algorithms that are capable of understanding complex structures and have shown excellent success in tasks related to image segmentation, object detection, and computer vision applications. The key benefit of CNNs is their power to leverage spatial or temporal correlation in data. CNNs have also been used in the context of intrusion detection for both feature extraction and classification. 21 Fewer parameters are required in a CNN compared with other deep learning architectures. Thus, model complexity is reduced, and the learning process is improved. In the following subsections, we describe the data sets, preprocessing, and the architectures of our proposed models.
Data set description
This research is carried out over two data sets: the NSL-KDD data set 11 and the UNSW-NB15 data set. 12 In the next sections, we briefly describe the characteristics of our chosen data sets. A more in-depth treatment of the data sets is available in Appendix A1.
Network security laboratory-knowledge discovery in databases
The NSL-KDD data set is an improved version of the KDD’99 data set.
11
It is a smaller data set that provides better evaluation of classifiers since redundant records are removed.11,30 Redundant records cause learning classifiers to be biased toward the more frequent records during training, as well as increasing classification accuracy whenever these same records appear in the test set. The training set KDDTrain
University of New South Wales Network Based 2015
Although the NSL-KDD data set solved the problems of data imbalance and redundancy found in KDD’99, it is an old data set that does not include new types of attacks. The UNSW-NB15 data set 12 is a recent data set created in 2015 by the Australian Centre for Cyber Security (ACCS). It is being recently used in some studies as it overcomes the limitations of both KDD’99 and NSL-KDD data sets. It contains a combination of normal activity and contemporary synthesized attacks in network traffic. The data set has the following 10 classes: Normal, Fuzzers, Analysis, Backdoor, DoS, Exploits, Generic, Reconnaissance, Shellcode, and Worms.
Each record in the UNSW-NB15 full connection records data set has 47 features, divided into 5 groups as follows: Flow features, Basic features, Content features, Time features, and Additional generated features.
Both data sets have imbalanced classes, especially in the multiclass classification case.
Determining optimal architecture and hyperparameter settings
To choose the optimal architecture for our CNN model, we ran 3 trials on the following architectures, for 20 epochs each:
Three convolution layers with 8, 16, and 32 feature maps, followed by 1 max-pooling layer and 4 fully connected layers. Five convolution layers with 8, 16, 8, 16, and 32 feature maps, followed by 2 max-pooling layers and 4 fully connected layers. Five convolution layers with 8, 16, 8, 16, and 32 feature maps, with skip connections to the second and fourth convolution layers, followed by 2 max-pooling layers and 4 fully connected layers.
The third model achieved the best performance with regard to classification in both the binary and multiclass classification cases, and as such, we chose it as our basic architecture. Next, we set our hyperparameters on this model. First, we run our model for 10 epochs and monitor the performance as the learning rate is varied in the following set [0.0001, 0.003, 0.009, 0.001, 0.003]. We set the learning rate to 0.001. Next, we experiment with rectified linear unit (ReLU), Parametric ReLU, and Leaky ReLU with values ranging from [0.1 to 0.3], and select Leaky ReLU with
CNN models
Data preprocessing
Both NSL-KDD and UNSW-NB15 contain nonnumeric data. We preprocess our data in two ways and compare performance based on the different types of preprocessing.
2D representation
Here, the network connections are simply transformed into a 2D format suitable for the deep learning architecture. First, we convert the nonnumeric features to numeric features using one hot encoding. For the NSL-KDD data set, the categorical features are converted into indicator values and then combined with the numerical features to get a total of 121 numeric features. These are represented as an 11 × 11 × 1 matrix. For the UNSW-NB15 data set, we converted the categorical features into indicator values and then combined with the numerical features to get 196 numeric features. These are represented as a 14 × 14 × 1 matrix. We normalize features by subtracting the mean and scaling to unit variance. A sample of our input is visualized in Figure 1a. We refer to the models trained using the 2D representation of the data set as BCNN and MCNN for binary classification and multiclass classification, respectively.

Sample input using the different preprocessing methods for the same data point.
Principal component analysis–deep feature synthesis
Instead of relying on hand-crafted features, we propose a hybrid two-step preprocessing approach that combines dimensionality reduction and feature engineering. First, the nonnumeric features, or categorical features, are converted into numeric features using nominal integer encoding and then centered around the mean and scaled to unit variance. Then, we use principal component analysis (PCA) on the continuous features, such that 95% of the variance is retained. As the data sets can contain a number of redundant or highly correlated features, the performance of classification algorithms can suffer. PCA is basically a dimensionality reduction technique that we use to increase interpretability, while minimizing the loss of information. 31 PCA has the advantage of being less sensitive to noise compared with other techniques, such as Isomap, locally linear embedding, and Hessian locally linear embedding.32,33 These steps produce a total of 27 and 26 features from the NSL-KDD and UNSW-NB15 data sets, respectively. These features are then converted using addition and multiplication primitives in DFS. 10
For the binary classification case, the classes in both data sets are balanced; however, the classes are severely imbalanced in the multiclass case. There are many techniques for oversampling to handle imbalanced data sets. In this study, we use the synthetic minority oversampling technique (SMOTE), 34 which is one of the most widely used techniques. The basic idea is to synthesize new points from the minority class. A data point, x, is randomly selected from the minority class in the data set. Then, the k neighbors of x are determined, with k usually set to 5. One of the identified neighboring points, y, is then chosen. A new synthetic record, z, is generated at a randomly selected point between points x and y in the feature space. SMOTE has been applied in a variety of applications with demonstrated success. 35 The technique has also been shown to be robust and to perform better than simple oversampling. SMOTE is also effective for the reduction of overfitting.
Feature engineering refers to the process of creating new and meaningful features from raw ones. The goal of feature engineering is to select the most relevant features for better model accuracy. In DFS, new deep features are generated by stacking multiple primitives. A feature's depth is essentially the amount of primitives that are required to create the feature.
Using DFS, 729 and 676 features are automatically produced from the NSL-KDD and UNSW-NB15 data sets, respectively. We select 121 and 196 features, retaining about 99% of the variance, for the NSL-KDD and UNSW-NB15 data sets. A sample of our input is visualized in Figure 1b. Compared with Figure 1a, we observe that there is more interfeature variance, which indicates that redundant features have been eliminated. We refer to the models trained using the PCA-DFS of the data sets as BCNN-DFS and MCNN-DFS for binary and multiclass classification, respectively.
CNN architecture
We propose two CNN models: BCNN and MCNN, where the first model (BCNN) is used for binary classification, and the second model (MCNN) is used for multiclass classification of network attacks.
Input layer
The input layer is either an
Hidden layers
Our model is composed of a total of five convolutional layers, two pooling layers, and four fully connected layers. Our input image is small, either
The first convolutional layer has as input an
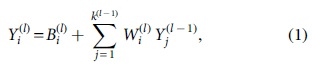
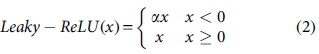
The second convolutional layer has as input an
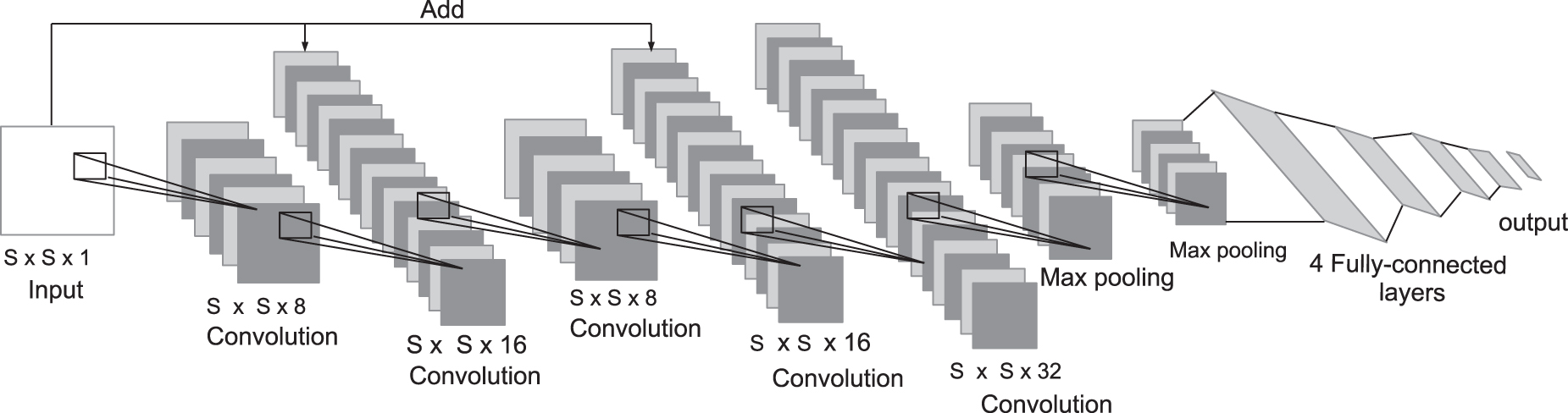
Proposed CNN model. CNN, convolutional neural network.
Next, we have two max-pooling layers that have a
Output layer
The output layer is a 5 class Softmax layer (one class for each attack type, plus the normal class). Softmax outputs a probability-like prediction for each character class, see Equation (3), where N is the number of output classes. Our CNN architecture is shown in Figure 2.
Our model incorporates various methods to reduce overfitting. In particular, our model incorporates a dropout layer, where randomly selected activations are set to 0 during training, so that the model becomes less sensitive to specific weights in the network. In addition, our model has weight decay, also called L2 regularization, which reduces overfitting by penalizing model weights. We also incorporate batch normalization, which normalizes the input values of the layer, reducing overfitting and improving gradient flow through the network. Finally, our model incorporates a data augmentation technique, specifically SMOTE, which is also effective for the reduction of overfitting. We report the performance of the final model on a separate unseen test set, which contains new attack types not present in the training set.
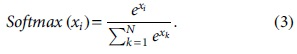
Optimization
In our model, we tested two optimizers: Stochastic Gradient Descent and Adam,
37
and selected Adam as it was found to work better. The loss function used is the categorical cross-entropy loss, which is widely used to calculate the probability that the input belongs to a particular class. It is usually used as the default function for multiclass classification. In our model, we set the learning rate to
Results
Experimental settings
The proposed models were implemented using Tensorflow, 38 an open source machine learning library, utilizing Keras. 39 Experiments were carried out using GPUs running on the Google Colab environment. 40
Performance measures
To evaluate the performance of BCNN and MCNN, the following performance measures are calculated: accuracy, precision, detection rate, and F-measure.
Accuracy is the percentage of records classified correctly, and it is calculated using the following equation:
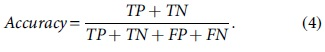
Precision (P) is the percentage of records correctly classified as anomaly out of the total number of records classified as anomaly. Precision is calculated as follows:

Detection rate (DR), also called True Positive Rate or Recall, is the percentage of records correctly classified as anomaly out of the total number of anomaly records. The detection rate can be calculated as follows:
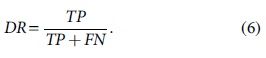
F-measure (F) is a measure that combines both precision and detection rate, and it is calculated as follows:
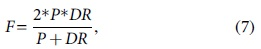
where TP (true positive) indicates the number of anomaly records that are identified as anomaly. FP (false positive) is the number of normal records that are identified as anomaly. TN (true negative) is the number of normal records that are identified as normal. FN (false negative) is the number of anomaly records that are identified as normal.
Performance evaluation
Our experiments are designed to evaluate the ability of BCNN and MCNN at detecting network intrusions. Two data sets are used for this purpose: the NSL-KDD data set and the UNSW-NB15 data set. For both data sets, the experimental results are compared with (1) the results of similar approaches in the literature and (2) results of various state-of-the-art classification algorithms. In particular, we compare our models with NB, J48, RF, Bagging, and Adaboost implemented in Waikato Environment for Knowledge Analysis.
41
All models were trained on KDDTrain
We present our results in the following two sections. The NSL-KDD results section presents the results of BCNN and MCNN on the NSL-KDD data set. Binary classification classifies network traffic into: normal or anomaly. Multiclass classification classifies network traffic into five labels: normal, DOS, R2L, U2R, and Probe.
The UNSW-NB15 results section presents the results of BCNN and MCNN on the UNSW-NB15 data set. Binary classification classifies network traffic into: normal or anomaly. Multiclass classification classifies network traffic into 10 labels: normal, Fuzzers, Analysis, Backdoor, DoS, Exploits, Generic, Reconnaissance, Shellcode, and Worms.
NSL-KDD results
Binary classification
In this section, we present the classification results of BCNN and BCNN-DFS on KDDTest
Performance comparison with several related literature approaches for binary classification on network security laboratory-knowledge discovery in databases
The highest performance measures obtained are shown in bold.
BCNN , binary classification convolutional neural network; BDNN, binary classification deep neural network; TSE-IDS, two-stage classifier ensemble for intelligent anomaly-based intrusion detection system.
We note that BCNN outperformed all models in the literature, achieving an accuracy of 88.81%, while detecting 89% of all attacks, with an F-measure of 89%.
However, with the hybrid feature engineering approach, BCNN-DFS, we find that it outperforms BCNN and all other models in the literature, achieving an accuracy of 90.14% on KDDTest
Next, we compare our work with various state-of-the-art classification algorithms, as shown in Table 2. Both BCNN and BCNN-DFS achieve the higher accuracy and F-measure compared with all other models. Their detection rate outperforms all other models by a large margin, where they are able to detect 89.00% and 90% of all attacks, with an F-measure of 89% and 90%.
Multiclass classification
In this section, we present classification results on KDDTest
Performance comparisons with several related literature approaches for multiclass classification on NSL-KDD
The highest performance measures obtained are shown in bold.
MCNN, multi classification convolutional neural network; MDNN, multi classification deep neural network.
Our multiclass CNN model, MCNN, achieves an accuracy of 81.1% and is able to detect 81% of all attacks. Its overall F-measure is 80%, outperforming multi classification deep neural network (MDNN), 29 and all other models in the literature except for RNN-IDS, 20 which it is comparable to. MCNN-DFS achieves a comparable result outperforming MCNN slightly. Table 3 also presents the comparison of our multiclass models with state-of-the-art classification algorithms. MCNN and MCNN-DFS achieve the best results in terms of accuracy, precision, recall, and F-measure, outperforming all the evaluated models.
UNSW-NB15 results
Binary classification
In this section, we present the performance evaluation of BCNN and BCNN-DFS using UNSW-NB15. In addition, for the sake of comparison, we conduct a study on the performance of our previously published model, binary classification deep neural network (BDNN), 29 using UNSW-NB15. Unfortunately, the number of studies conducted on the full UNSW-NB15 data set is fewer than those using NSL-KDD. Table 4 shows the performance measures of BCNN and BCNN-DFS compared with similar approaches in the literature. The results show that BCNN achieves the highest accuracy and F-measure values, except for two-stage classifier ensemble for intelligent anomaly-based intrusion detection system (TSE-IDS). 14 In terms of precision, BCNN, BCNN-DFS, and BDNN outperform all the compared state-of-art machine learning algorithms. However, AlertNet 5 has the best precision value. As for the recall, our models perform better than AlertNet and NB.
Performance comparison with several related literature approaches for binary classification on UNSW-NB15
The highest performance measures obtained are shown in bold.
U-train is UNSW-NB15-training-set, and U-test is UNSW-NB15-testing-set.
UNSW-NB15, University of New South Wales Network Based 2015.
Multiclass classification
This section presents the classification results of MCNN, MCNN-DFS, and the previously published model MDNN 29 using UNSW-NB15 on the multiclass classification problem. Table 5 shows the performance measures of our models compared with similar approaches in the literature. Although the presented numbers reflect degraded performance of multiclass classification compared with binary classification, MCNN outperforms all the compared models on all measures. The performance of MCNN-DFS is comparable to MCNN.
Performance comparison with several related literature approaches for multiclass classification on the UNSW-NB15 data set
The highest performance measures obtained are shown in bold.
U-train is UNSW-NB15-training-set, and U-test is UNSW-NB15-testing-set.
What does the network learn? A case study
In this section, we will present a small case study, designed to showcase what our model learns and how it performs. For the purposes of this study, we select the UNSW-NB15 data set, in the multiclass classification case, using the MCNN-DFS model. We randomly select 10 samples, such that each is of a different class, from the data set. The samples and their corresponding model prediction are shown in Table 8. Our model's prediction accuracy on this small sample is 70%, which is to be expected from the results shown in Table 5.
In Table 9, we visually demonstrate what MCNN-DFS learns at each convolutional layer. Each of the layers has multiple filters, and each filter produces an activation map. We show only a subset of these activation maps at each layer. The convolutional network learns this hierarchy of filters. The filters at the earlier layers, in our case Conv-1, learn the low level features of the data. As we go through the network, in the middle layers, Conv-2 and Conv-3, we learn more complex features, and the last layers, Conv-4 and Conv-5, learn even more complex features and concepts. As learning progresses, we observe that the model captures more complex features at each stage. These features are then input into the fully connected portion of the network to produce the final classification output.
Computational time
In addition to evaluating the classification accuracy of the proposed models, it is important to measure the computational time in real situations of network intrusion detection. The computational complexity of our models for both data sets is shown in Table 10. The table shows both the training and prediction times.
In a real-life setting, our models would be trained offline, and as such, longer training times are acceptable. The second column in Table 10 shows the average training time needed by each model on each data set. In general, binary models complete training faster than multiclass models, and as the data set size increases, so does the training time. However, as the binary models train in a significantly shorter period, we suggest training and deploying the binary model on new data and then training the multiclass model if needed. In the third column, we show average prediction times for each model on each data set. Prediction times are for 100,000 sample network connections on a single machine. Faster times can be achieved if the models are deployed in parallel. As Table 10 shows, all models achieve high-throughput rates.
Discussion
One of the key questions that this research was intended to investigate is how to improve the prediction performance of NIDS systems using deep learning and feature engineering. For the NSL-KDD data set, we observe that the classification accuracy of our proposed multiclass models is lower than that of the binary class models. This observation is consistent with results in the literature. For the multiclass problem, achieving good results on the NSL-KDD data set is difficult. We believe that this is due to the fact that the NSL-KDD data set suffers from the class imbalance problem. For example, the U2R class represents 0.04% of the data set, whereas the R2L class represents 8% of the data set.
We note that the overall performance of the deep learning model with the proposed hybrid feature engineering technique slightly improves prediction accuracy over the NSL-KDD data set. However, the performance on UNSW-NB15 is slightly decreased. This might be attributed to the distribution of the training and testing data sets, which require further investigation. Looking into the confusion matrix of MDNN 29 shown in Table 6, we observe that the majority of predictions are placed into four classes only, namely Exploits, Fuzzers, Generic, and Normal. This means that MDNN 29 was unable to recognize the remaining six classes. As for MCNN, the confusion matrix in Table 7 shows that it has better performance than MDNN. 29 We note that there are 10,859 normal records classified as Fuzzers. We believe that the random nature of a Fuzzers attack makes it difficult for MCNN to detect a particular pattern. Distinguishing between these two classes could be improved in future work.
MDNN 29 confusion matrix on UNSW-NB15
DoS, denial of service.
MCNN Confusion matrix on UNSW-NB15
MCNN-DFS case study on UNSW-NB15

Class “Analysis” on UNSW-NB15

Computational complexity
Traditional machine learning algorithms have historically been widely used to solve the intrusion detection problem 4 and are still prevalent today.42–45 Although considered shallow learners, they are still being utilized for developing IDS, for example, for the internet of things and big data environments.46,47 NB classification assumes conditional independence; however, it is robust to noise. The J48 is an implementation of the C4.5 decision tree algorithm, which provides easy interpretation of the final model. RF, Bagging, and Adaboost have the advantage of being ensemble algorithms, which combine the classification of many weak classifiers. The UNSW-NB15, in particular, as a newer data set, has been used to evaluate fewer approaches in the literature compared with NSK-KDD. This study demonstrated the superiority of deep learning over traditional shallow learning for NIDS systems. The complex structures of deep learning models facilitate a better learning process than shallow models.
In this study, the performance of the proposed models has been evaluated using two data sets. First, NSL-KDD, a legacy data set that has been widely used to evaluate IDS models. Second, the UNSW-NB15, a modern data set that is representative of real-world data. A number of other modern network intrusion detection data sets are publicly available now, such as CIC-IDS201748 and CIC-IDS2018. 49 Thus, more studies, such as the work of Gamage and Samarabandu, 50 are required to investigate the performance of deep learning models and baseline models on a wider range of data sets.
AlertNet 5 used a traditional deep fully connected neural network architecture, as did CNN, 28 which used a traditional architecture with two convolutional layers, followed by two pooling layers. STL-IDS 24 encorporated sparse autoencoder, followed by SVM classifiers. Compared with the related work, as shown in Tables 2–4, our proposed models have minimal trade-off between precision and recall. As both measures are essential in the intrusion detection problem, having a system that balances both metrics are an advantage.
To the best of our knowledge, this is the first article incorporating skip connection methodology into CNNs to solve the anomaly detection problem. This has proven to be successful as shown in the Results section where our model outperformed previous models in the literature. This study highlights the benefits of skip connections; however, this line of research is yet to be investigated in other architectures. In addition, we achieve excellent results with a small network size that is trainable in a short period. This enables our network to be deployed for real-life anomaly detection situations. It has high accuracy at detecting anomalies, especially in the binary situation. When it comes to RNNs and other time-based architectures, their usefulness in anomaly detection is yet to be established given current data sets, where the time-based nature of connections is not evident or explicitly stated in the data set.
Conclusions
NIDS are essential tools for detecting malicious network traffic in today's computer systems. They are designed to differentiate between previously unseen abnormal network activity and normal patterns. In this article, we presented two novel network intrusion detection models based on deep learning, as well as two approaches to data preprocessing, a simple preprocessing approach and a hybrid two-step preprocessing approach to generate meaningful features. Our models employ the CNNs paradigm. We design our models for binary and multiclass classification.
Our models were able to achieve excellent performance compared with state-of-the-art classification algorithms. In particular, our models outperform NB, J48, RF, Bagging, and Adaboost in terms of accuracy and recall. In addition, they achieved excellent results compared with similar approaches in the literature. We observe that the classification accuracy of our multiclass models is lower than that of the binary class models.
The development of classifiers for ADNIDS is an essential step toward building a complete intrusion detection framework. The proposed models can be integrated into network systems to detect unusual events, such as new attacks and violations inside an organization's network. For future work, we plan to use an ensemble to combine the results of our classifiers, to improve predictions. In addition, the neural networks can be combined in a number of different ways to produce the classification result in one step. The proposed models themselves can be improved by increasing the number of hidden layers and neurons, or adding some convolutional layers, using different optimizers and trying new values for the learning rate. Also, methods to balance the various data set classes could potentially improve classification results. We also plan to study various sampling techniques to improve class variability. Finally, additional studies should be conducted to look into distinguishing Fuzzers attacks.
Footnotes
Authors' Contributions
Conceptualization: N.A. Methodology: I.A. and N.A. Experiments: N.A. Analysis: N.A. and I.A. Article drafting, editing, and final approval: I.A. and N.A.
Data Availability
The NSL-KDD
11
data supporting this study are from previously reported studies and data sets, which have been cited. The processed data are available at https://www.unb.ca/cic/datasets/nsl.html. The UNSW-NB15 data set
12
is publicly available at ![]() .
.
Author Disclosure Statement
No competing financial interests exist.
Funding Information
This research project was supported by a grant from the Research Center of the Female Scientific and Medical Colleges, the Deanship of Scientific Research, King Saud University.