
Abstract
Abstract
We consider the task of determining the number of chances a soccer team creates, along with the composite nature of each chance—the players involved and the locations on the pitch of the assist and the chance. We infer this information using data consisting solely of attacking events, which the authors believe to be the first approach of its kind. We propose an interpretable Bayesian inference approach and implement a Poisson model to capture chance occurrences, from which we infer team abilities. We then use a Gaussian mixture model to capture the areas on the pitch a player makes an assist/takes a chance. This approach allows the visualization of differences between players in the way they approach attacking play (making assists/taking chances). We apply the resulting scheme to the 2016/2017 English Premier League, capturing team abilities to create chances, before highlighting key areas where players have most impact.
Introduction
Within this article, we look to explain an English Premier League team's style of attacking play from data that consist of attacking events only: the details of a chance and the corresponding assist. We determine the number of chances a team creates, along with identifying the players involved and from where on the pitch the chance took place.
The English Premier League is an annual soccer league established in 1992 and is the most watched soccer league in the world.1,2 It consists of 20 teams, who, over the course of a season, play every other team twice (both home and away), giving a total of 380 fixtures. It is the top division of English soccer, and every year the bottom three teams are relegated to be replaced by three teams from the next division down (the Championship). In recent times, the Premier League has also become known as the richest league in the world, 3 through both foreign investment and a lucrative deal for television rights.4,5
To compete in the English Premier League, teams employ different styles of play, often determined by the manager's personal preferences and the players who make up the team. Examples of attacking styles of play include counter attacking (quickly moving the ball into scoring range) or passing build-up (many short passes to find a weakness in the opposition's defense). For further discussion of styles of play, we direct the reader to References.6,7
Methods to model a soccer team's style of play/behavior have been explored previously by a number of authors. Occupancy maps defined using a given metric (e.g., the mean or an entropy measure of an activity) have been used by Lucey et al. 8 to determine a team's style of play, with the aim of showing that a team strives to “win home games and draw away ones.” Occupancy maps are also used by Bialkowski et al., 9 who take spatiotemporal player tracking data and develop a method to automatically detect formation and player roles.
Player and ball tracking data are used by Lucey et al. 10 to create spatiotemporal maps of a team's playing style just before they take a shot. Gaussian processes are utilized by Bojinov and Bornn 11 to form a spatial map to capture each team's defensive strengths and weaknesses. Pass locations are used by Brooks et al. 12 to determine teams based on their passing styles, before whether pass locations can be used to predict the importance of shots is investigated. All of these methods are applied to dense and expensive data (both in price and in collection expenditure), which consists of all events in a soccer match, with some further utilizing GPS data for the location of the players. Such data are not available to us here.
Methods from the network analysis toolbox are employed by References13–15 to draw conclusions about a team/player's use of possession. How the players on a team interact is discussed in Grund 16 and Kim et al. 17 estimate the global movements of all players to predict short-term evolutions of play. Outside of soccer, Miller et al. 18 investigate shot selection among basketball players in the NBA, combining matrix factorization techniques with an intensity surface, modeled using a log-Gaussian Cox process. Defensive play in basketball is captured by Franks et al., 19 who take player tracking data and apply spatiotemporal processes, matrix factorization technique,s and hierarchical regression models. Finally, spatiotemporal data are used by Wei et al. 20 to predict shot locations in tennis.
More generally, the statistical modeling of sports has become a topic of increasing interest in recent times, as more data are collected on the sports we love, coupled with a heightened interest in the outcome of these sports due to the continuous rise of online betting. Soccer is providing an area of rich research, with the ability to capture the goals scored in a match being of particular interest.21–23
A player performance rating system (the EA Sports Player Performance Index) was developed by McHale et al., 24 which aims to represent a player's worth in a single number, whereas McHale and Szczepański 25 identify the goal scoring ability of players. Which game-related statistics or performance indicators characterize success (or failure) are determined within References.26,27
The length of possession as a predictor of win, lose, or draw was investigated by Jones et al., 28 where more successful teams had shorter possessions. Players are rated for a number of abilities, before using them to aid the prediction of goals scored in Whitaker et al. 29 Finally Kharrat et al. 30 develop a plus–minus rating system for soccer.
In this article, we propose a method to capture the number of chances a team creates during a given section of a match, along with determining the players involved in a chance, where on the pitch the chance was created and where it was taken from. Our work differs from previous studies in this area in a number of ways. First, previous work has used complete touch data (where every location that a player touches the ball in a game is recorded) to model a team's attacking play. In this study, we use only the location of the assist and the chance. Thus, our proposed method is less computationally intensive and allows inferences from coarser and significantly cheaper data.
Previous work has also focused on modeling the spatial dynamics of a team as a whole, whereas our method identifies the individual spatial contributions of players. Where specific players have been modeled in the past, this is often not accompanied by spatial analysis. Instead, player-to-player relationships are considered. We note that the model proposed within this article has a wide variety of applications, of which we illustrate a few.
The remainder of this article is organized as follows. The data are presented in The Data section. In The Model section, we outline our model to capture a team's chances, before discussing an approach to identify the players involved with each chance and from which spatial locations. Applications are considered in Applications section and a discussion is provided in Discussion section.
The Data
The data available to us are Stratagem Technologies' Analyst data. This is a collection of data that marks the significant events during a soccer match, including goals, cards (both yellow and red), and chances created. For each of these events, a time is recorded (in minutes), the team and player involved with the event, and for the goals/chances the location on the pitch is marked. If the event is a goal/chance, both the player taking the chance and the player assisting the chance are recorded (along with the spatial location of the chance and the assist). From here on, we consider goals and chances to be the same for our purposes (a goal being a chance that is scored after all)—we refer to them collectively as chance. A section of the data is shown in Table 1. The data cover the 2016/2017 English Premier League season and consist of roughly 32,000 events in total, which equates to ∼85 events for each fixture in the data set. We also have the date of each fixture. We note that the data previously used by References8,9,11 to address the types of problems considered in this article typically consist of ∼600,000 events.
Locations on the pitch are represented by
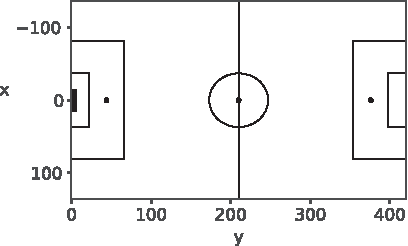
Map of the pitch, the point (0, 0) represents the center of the defended goal (shaded box). Further key reference points are detailed in Table 2.
Further to that mentioned, it is possible to extract additional statistics from the data set. These include the game state and the red card state for a team at a given time point. The game state is the number of goals a team is winning or losing by at that point in time, for example, a team winning 1-0 would have a game state of +1, a team losing 1–3 would be −2, and, if the game is currently a draw, both teams would have a game state of 0. The red card state is defined similarly, and is the difference in the number of players on each team. To elucidate, if a team has a player sent off, its red card state would be −1, whereas the opposition would be +1.
The Model
In this section, we define our model to capture a team's chances, followed by our approach to determine the composite nature of each individual chance. Each chance consists of an assist player, a player taking the chance (chance player), the spatial location from which the assist was made, and the location of the chance.
First, the number of chances a team has in a given period (N) is sampled using a Poisson model. Then for each chance (E), we draw an assist player (A) and a chance player (C) from discrete distributions, with an assist location

Visual representation of the model for a single team in a given fixture.
A team's number of chances
Consider the case wherein we have K matches, numbered
For simplicity, we outline the model for a single fixture first. We split a fixture into 15-minute blocks, giving six blocks in total (Fig. 3). Our choice of time resolution was decided after a discussion with in-house expert soccer analysts, who agreed that this level of time resolution captures enough temporal variability without unnecessarily complicating the implementation of the model. Typically, a soccer match will have a small amount of extra time at the end of each half. Throughout this article, any chances that occur within these periods of extra time are included in either t3 or t6 (using the block structure illustrated in Fig. 3).

One possible way to split a fixture into blocks.
For a given match k, let
where
The notation introduced in Equation (2) is described as follows. A team's baseline propensity to create chances is represented by parameter
For identifiability purposes, we follow Karlis and Ntzoufras
22
(among others) and impose the constraint that the
The thinking behind this model construction is that if a team is creating chances, the other team cannot. Although this assumption is limiting by construction, given defensive tactics and other tangential aspects of play, it is the easiest (and possibly most meaningful) setup derived from the data, which consists of attacking instances only. From Equations (1) and (2), the likelihood is given by
We note that it is possible to model the number of chances a team creates using an approach similar to that implemented by References21–23,29 (although for goals a team scores). However, we find little or no difference in the sum-of-squares, bias, or empirical predictive distributions under the two setups. Thus, we proceed with the simpler model (in terms of the number of parameters) given by Equations (1)–(3).
Chance composition
Once the number of chances created by a team is determined as mentioned, we break
with
First, let us consider the task of determining the assist and chance players involved with each event. We make the assumption that a player cannot assist a player on an opposing team (such as assisting an own goal, by forcing the error), and neither can they take a chance created by a player from the opposition (e.g., running onto a bad back pass). In the context of soccer, these events are reasonably rare, and by implementing this assumption, we can consider the players of one team to be independent from the players of another team (in relation to assisting and taking chances).
A player can switch teams part way through a season (in January) or at the end of a season by means of a transfer. However, we consider them to be a new player to be learned, as they may have different dynamics with their new teammates and possibly play in a different system (e.g., by playing in a new position to that at their previous team). We model the probability of each assist player (and chance player) using a “Multinoulli” (i.e., categorical) distribution.
Let
Defining
with
Similarly, for the chance player
where
Next, we consider the spatial locations, which we model using a mixture model. For a general discussion of mixture models, we refer the reader to McLachlan and Peel.
31
Given the nature of the spatial locations, we implement a Gaussian mixture model, with M components. We denote the weighting of the mixture components (for a given player i, in a given block tr) by
Furthermore, let the observations for a given player, in a specific block, be
where
To simplify our approach, we choose to predetermine the number of components that make up our mixture model. After discussion with inhouse expert soccer analysts, we decided upon eight components, whose locations we determine through k-means clustering. Thus, we set
The locations of the cluster centroids are shown in Figure 4 (indicated by a cross), where we also plot the data, shaded according to cluster assignment under k-means. We see the different scale on the

Cluster centroids (cross) under k-means with all data points classified by cluster assignment. Top assist (location of chance creation), bottom
To add some context to the cluster centroids, for the assist locations, the furthest right centroid
The
We note that, although the confines of the pitch are bounded, the mixture of Gaussians has infinite support. Here, we ignore this aspect for computational simplicity and fit flexible covariance matrices to mitigate the effect—through our explorative analysis we believe this effect to be negligible.
Having outlined the two components of our model, namely, the number of chances a team generates and the composition of these chances, we must consider an appropriate way to fit the model, which is the subject of the next section.
Bayesian inference
To estimate the parameters in the model, we use a Bayesian inference approach. The joint posterior is given by
where
To fully specify the model, we implement the following priors
where
The form of Equation (11) admits a Gibbs sampling strategy with blocking, which we can extend to form five independent full conditionals for the number of chances, the assist player, the chance player, the location of the assist, and the
Applications
In the previous sections, we described our model for the spatial composition of goal chances according to latent player abilities. In this section, we test the proposed method in real-world scenarios. Given the independence between the components that constitute the model, we consider two applications. In the first, we learn a team's ability to create chances and, in the second, we examine which players are involved, and where on the pitch these events occur.
For both applications, we use the data described in The Data section, namely the 2016/2017 English Premier League. We note that Chelsea won the league, with Tottenham Hotspur, Manchester City, and Liverpool getting UEFA Champions League places. Therefore, we may expect these four teams to be the best. In contrast, Sunderland, Middlesbrough, and Hull were relegated at the end of the season, meaning these three teams were perhaps the worst.
Determining a team's chance ability
We fit the model defined by Equations (1)–(3) using the priors specified in Equation (12). We found little difference in results for alternative priors. We ran the model for 2000 iterations, after an initial burn-in of 100 iterations. Trace and autocorrelation plots for

Trace and autocorrelation plots for
The posterior means for a team's ability to create chances (
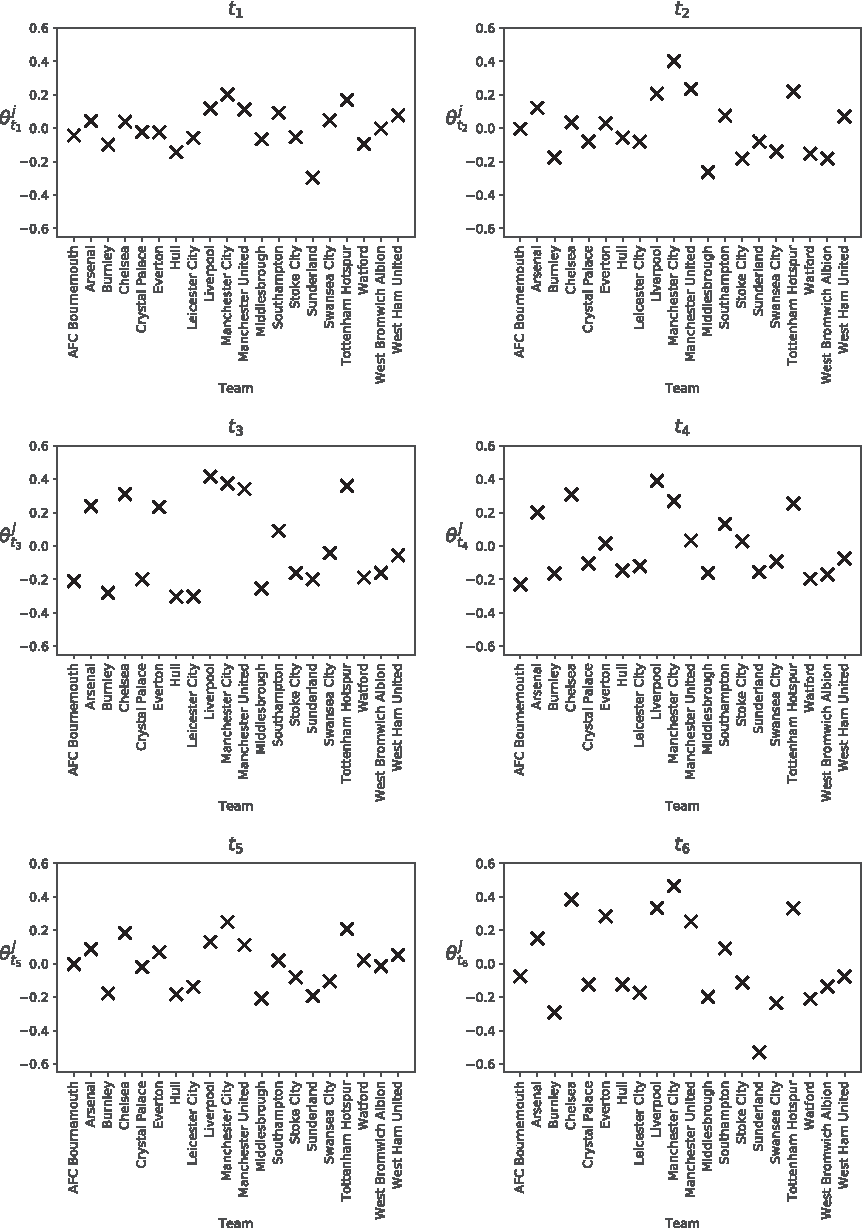
A team's mean ability to create chances,
These are the values shown in Figure 6.
Manchester City has the highest value in t1, t2, and t6, meaning that they started and finished games well. These values highlight Pep Guardiola's playing style, along with the quality of Manchester City's substitutes (they can replace good players with equally good players). Chelsea does not have as high values as some of the other top teams (even though they won the league), suggesting they did not create as many chances as other teams, but they were more clinical with those they did create.
The teams that were relegated at the end of the season (Sunderland, Middlesbrough, and Hull) have some of the lowest values in the table. Sunderland has the worst ability to create chances in t1 and t6, with Middlesbrough having a similar ability across all blocks, leading to them being the two lowest scoring teams in the league.
Figure 7 shows the posterior mean for the home effect in each block over the entire 2016/2017 season, along with 95% credible intervals. The credible intervals in each block are of near identical size, meaning that we have similar levels of uncertainty surrounding all

Mean home effect (solid line) and 95% credible intervals (dotted line) in each block in the 2016/2017 English Premier League.
There is a rise in the home effect in t3 (the end of the first half), this is possibly due to fan pressure to perform well. If a team is losing going into half time, fans want to see their team trying to get back into the game (by creating more chances), if they are drawing, they want to try to gain an advantage, or if they are winning, they want to see them press home their advantage. This level of home effect carries into the second half
The trend seen in Figure 7 complements the findings of Lucey et al., 8 which a team will play more defensively away from home, with the suggestion that if an away team is winning or drawing in the final 15 minutes of a game (t6), they will attempt to hold onto what they have (by defending more and creating less chances).
Predicting a team's number of chances
By fitting the model to a certain point in the season and combining parameters, we are able to construct out-of-sample predictive distributions for the number of chances home and away teams create in a given block of a specific fixture. In particular, we fit the model up to a given week and predict the next week's fixtures. The predictive distributions for three randomly selected fixtures and blocks are presented in Figure 8, with the observed value indicated by the line, jittered by adding 0.5 for ease of visualization. From the figure it is clear to see that the observed value falls within the predictive distribution in each case, indicating we have a reasonable model fit and predictive performance.

Predictive distributions for the home (left column) and away (right column) teams in three random fixtures and random blocks (each row). The observed value is indicated by the line.
There is a variety of shape to the distributions, suggesting that the model is able to capture the differences between teams, as well as the differing opposition, and the different blocks in which chances can take place. Overall, the results presented in this section suggest the model is able to capture a team's number of chances reasonably well, as well as offering sensible predictions for the future.
Determining locations
Having determined the number of chances a team will create, we now fit the model defined through Equations (6) and (8)–(10) to capture the composition of these chances. Initially, we focus our attention on the assist and
Christian Eriksen created the most chances in the 2016/2017 English Premier League. Figure 9 shows the locations of these assists in each block through a Voronoi diagram, shaded according to the mean weighting of each mixture component

Eriksen assist locations for each block in the 2016/2017 English Premier League, shaded according to the mean weighting of each mixture component.
As we are implementing the model within the Bayesian paradigm, we can fit the model to a certain point in the season, before updating our beliefs once more data become available (more matches are played). To this end, we learn the model parameters using data up until January 1, 2017 (roughly half the season), and then proceed to update our beliefs after each subsequent month.
Voronoi diagrams for Riyad Mahrez's assists in t5 after each of these months (along with the season as a whole) are shown in Figures 10 and 11. Mahrez was one of the stars for Leicester City when they won the league in 2015/2016; however, he was not playing as well under manager Claudio Ranieri in 2016/2017 (our data set); this is suggested by the middle row of plots shown in Figure 10 (based on the mean weights), where high weights are only assigned to the LC. Ranieri was sacked in February and Craig Shakespeare became manager, who was seen to get Mahrez back to playing somewhere near his best. The figures support this, with the middle row of Figure 11 (again based on the mean weights) showing assists coming from more areas of the pitch, those being, the left-hand side, drifting to more central positions.

Mahrez assist locations in t5 after different periods of time, shaded according to the weighting of each mixture component. Top row weights based on 5% quantile, middle row weights based on the mean, and bottom row weights based on 95% quantile.

Mahrez assist locations in t5 after different periods of time, shaded according to the weighting of each mixture component. Top row weights based on 5% quantile, middle row weights based on the mean, and bottom row weights based on 95% quantile.
Utilizing the posterior densities, we can assess the uncertainty surrounding the weighting of each mixture component. The top row of Figures 10 and 11 shows Voronoi diagrams based on the 5% quantile of the marginal posterior densities for the weights, whereas the bottom row is formed using the 95% quantile. We see that as the season progresses, from the first fit (to January 1) to the full 2016/2017 season fit, the distance between the plots constructed under the 5% and 95% quantiles narrows (the plots look more similar). This is an advantage of implementing the model within the Bayesian paradigm; we are able to update our beliefs as more data become available, and reduce uncertainty.
We note that we observe only a small reduction in the variance here, however, this is due to the small number of observations available for each player. Fitting the model through time, over multiple seasons, would help to reduce the uncertainty surrounding individual player's mixture weights (subject to the data being available). This approach (through Figs. 9–11) illustrates that we can model how a player plays throughout a game and over a season. Given we can update as more data become available, this allows us to capture when players change their style of play or when they start to become more/less important to a team.
Integrating over the posterior uncertainty of the spatial locations gives the marginal posterior densities for
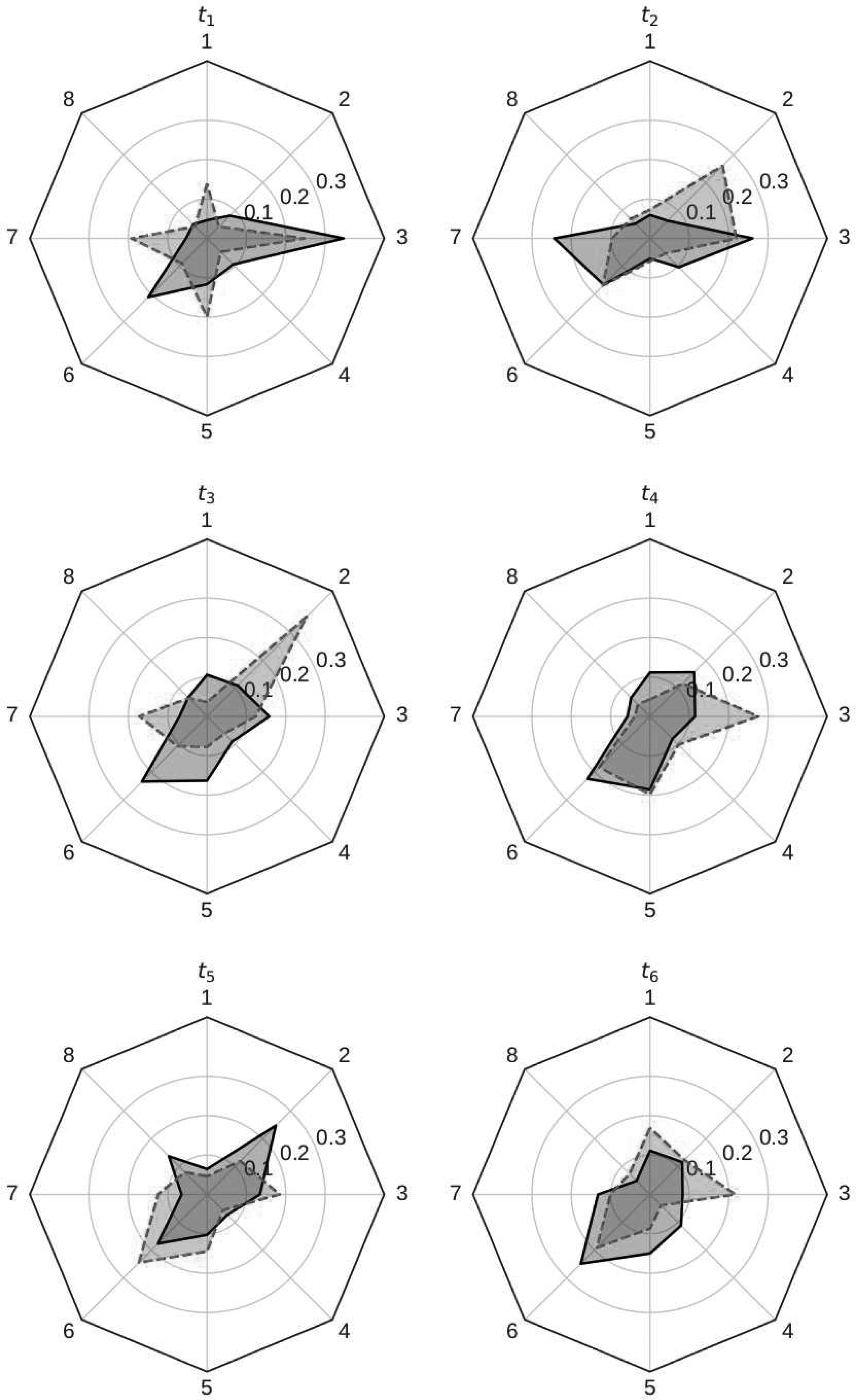
Radar plots of the mean
By marginalizing over the mixture weights

Eriksen assist locations under the Gaussian mixture model for t1 in the 2016/2017 English Premier League.
Identifying a team's strengths and weaknesses
During the 2016/2017 English Premier League, many pundits questioned the ability of Liverpool's defense, highlighting a weakness on the left-hand side. Looking at the data, this criticism appears fair. Of the goals Liverpool concede, the assist leading to the goal is most likely to come from the left-hand side of the box (LB), with a
Let us consider the match Liverpool versus Crystal Palace (April 23, 2017)—Crystal Palace is a team that in recent years has caused Liverpool problems. We fit our model using all data available before the match is played. From the model, in both t3 and t5, we expect Crystal Palace to have one chance against Liverpool (in the match they had two chances in both t3 and t5).
By integrating over
The

Benteke

Assist locations under the Gaussian mixture model in t5 using data to April 22, 2017. Top Cabaye, bottom Puncheon.
Considering a team as a whole
In a similar style to Lucey et al. 8 and Bojinov and Bornn, 11 we can create maps to represent how a team plays overall. Our maps differ from those of References8,11 as they use complete touch data, whereas in this study we just use the locations of the chance and the assist. Our maps are, however, conceptually similar.
Integrating over
Figure 16 shows three such surfaces for Chelsea, Manchester City, and Burnley (using data until March 1). It is clear from the figure that this approach allows us to distinguish differences in the way teams play. Burnley is more regimented (and static) than either Chelsea or Manchester City; they make assists from clearly defined locations, and even create chances from long balls forward (the lighter circle in their own half).

Assist location maps for three teams using data until March 1. Top left Chelsea, top right Manchester City, bottom Burnley.
Chelsea and Manchester City are more free flowing in their assist making, and create more chances than Burnley. They have better players who can create chances all over the pitch, and as they are known for a passing style, they rarely rely on a long ball forward. Chelsea appears to favor the left box position for assists, whereas Manchester City uses the right corner and left box. The contours of both Chelsea and Manchester City are less tightly ringed than those of Burnley. We believe that these plots show that it is possible to make inferences about the way in which teams attack, distinguishing between teams, in a way similar to References,8,11 but from much coarser data.
Discussion
In this article, we provided a framework to infer how goal chances are created by a team, characterized by spatiotemporal player-level behavior on assisting a play or receiving assists. All is done within a Bayesian inference setting that by construction provides uncertainty measures and the ability to incorporate prior knowledge. We illustrated its value to professional analysts by showing how it can be used to visualize team behavior.
We envisage that such modeling and inference methods can be easily incorporated into the toolbox of any organization with an interest in soccer analytics, due to its simplicity of implementation that can be accomplished by off-the-shelf tools such as the Python package PyMC3. Our approach is computationally efficient and utilizes the combination of a Poisson and Gaussian mixture model.
We have shown in Applications section that inferences under the model are reasonably accurate and have close ties to reality, along with implementable applications, of which we only illustrate a few. In contrast to previous work, we exploit coarser data (consisting solely of attacking events) to identify individual player contributions, rather than modeling the spatial dynamics of a team as a whole.
There are a number of ways in which this work can be extended. First, smoothing techniques can be applied to
There is some dependence between the player assisting the chance and the player taking the chance. That is, it is expected that some players link up better with some players than others, further determined by the areas on the pitch in which they play. This dependence between A and C needs incorporating into the model, which could also allow some network analysis techniques to be implemented. Finally, as an extension to the applications for the proposed method, an interesting area of future work is anomaly detection. This would allow us to highlight a player's patterns that are unusual in given fixtures and blocks. Techniques discussed in Heard et al. 32 could be used as inspiration for methods to detect these changes.
Footnotes
Acknowledgments
This work was partially supported by the KTP Partnership KTP010441 from Innovate UK and by The Alan Turing Institute under the EPSRC grant EP/N510129/1.
Author Disclosure Statement
No competing financial interests exist.