
Abstract
Abstract
Cosmetics legislation in Europe has driven the validation and acceptance of non-animal alternatives, most recently in the area of skin sensitization. Despite use of these methods to meet regulatory needs, it is also essential that they allow evaluation regarding human safety. For cosmetic product safety, it is necessary to understand how they can be used and with what limitations, and thereby reveal what remains to be addressed. A dataset of 165 ingredients (137 cosmetic ingredients +28 reference substances) has been identified, curated, and subjected to testing using accepted in vitro methods, with additional information, including physicochemical data and in silico results. The inputs from multiple determinants of skin sensitizing activity have been used in five individual supervised classification models (or machine learning approaches), which were then collated in a robust statistical manner, a stacking meta-model, to deliver a prediction with an optimized level of confidence. For the training set, with the probability cutoffs at 70% and 30%, predictive sensitivity was 97%, specificity was 88%, the overall accuracy was 93%, and kappa was 85%. A further 52 substances were used to test the effectiveness of the model: the predictive sensitivity was 89%, specificity was 95%, overall accuracy was 91%, and kappa was 82%. In conclusion, this stacking meta-model delivers improved performance and therefore enhanced confidence in the discrimination of skin sensitizers from nonsensitizers. The key remaining gap, prediction of skin sensitization potency, may benefit from a similar approach, maximizing use of evidence from individual strands of prediction, while minimizing the impact of the limitations from any particular one.
Introduction
T
The formalization of the adverse outcome pathway (AOP),13,14 including the identification of the key events in the mechanism of skin sensitization, facilitated the processes associated with validation and acceptance on non-animal alternatives. What followed quickly was the successful validation of three in vitro skin sensitization methods (the direct peptide reactivity assay—DPRA, KeratinoSens™, and the human cell line activation test—h-CLAT) and their adoption into OECD test guidelines. Thus the goal for the replacement of in vivo assays by non-animal alternatives appears to have been reached.15–17 In addition, several further methods are in the final stages of review at the OECD, including U-SENS™18,19 (www.oecd.org/env/ehs/testing/TG-Usens-draft-TG_Dec15-2016-clean.pdf) and IL8 Luc 20 (www1.oecd.org/env/ehs/testing/Draft-IL-8-Luc-TG-15Dec_clean.pdf), or under consideration, including LuSens 21 and SENS-IS. 22 Although there remains some debate, the current consensus holds that none of the methods in isolation is sufficient for hazard identification, which means that strategies to combine outputs from these methods must be developed.23–25 Toward this end have been directed a range of activities/proposals with their associated publications.11,26–30 Indeed, for the primary step of the identification of skin sensitization hazard in the context of regulations such as REACH in Europe, a simple majority verdict based on “yes/no” outputs from these assays has been deemed by many to be equivalent, or even better, than the Local Lymph Node Assay (LLNA).11,29,31,32
Obviously, this progress in the avoidance of animal testing for the skin sensitization end point is laudable for many reasons. When a substance is identified as a “nonsensitizer,” the level of uncertainty associated with that determination is by no means definitive. In principle, it should be possible to use a truly nonsensitizing cosmetic ingredient in any product type and at any desired level (subject of course to an absence of toxic effects other than skin sensitization). However, this can only be done with equanimity if there is a high level of confidence in the prediction that the ingredient is truly nonsensitizing.
In light of these perspectives, we have adopted an approach based on practical application of published statistical tools for the optimized combination of multiple predictive assays.33,34 A condensed and preliminary version of this work was shared with the OECD to assist in their program concerning integrated approaches to testing and assessment 24 ; in this article, we present an updated and completed version of our work.
Materials and Methods
Data sources
Material has been derived from both the published literature (72 substances) and internal studies conducted by L'Oréal Laboratories on proprietary materials (93 substances). Details of the 165 substances used for the training (n = 113) and the test (n = 52) datasets are presented in Tables 1 and 2. Note that for the proprietary materials, the CAS number has been replaced by a L'Oréal internal coding number. Chemicals were randomly allocated to each set, by a process that was repeated until the training and test datasets were balanced as far as possible regarding the proportion of sensitizers (S) and nonsensitizers (NS). In Figure 1, several aspects (cosmetic classes, sources of data, and so on) of the complete chemical set are presented, illustrating the fact that the set is quite balanced, including the LLNA potency used to define potency subcategories Figure 1A and B. This balance between S and NS has been maintained in the training set (47 NS and 66 S) and in the test set (21 NS and 31 S).
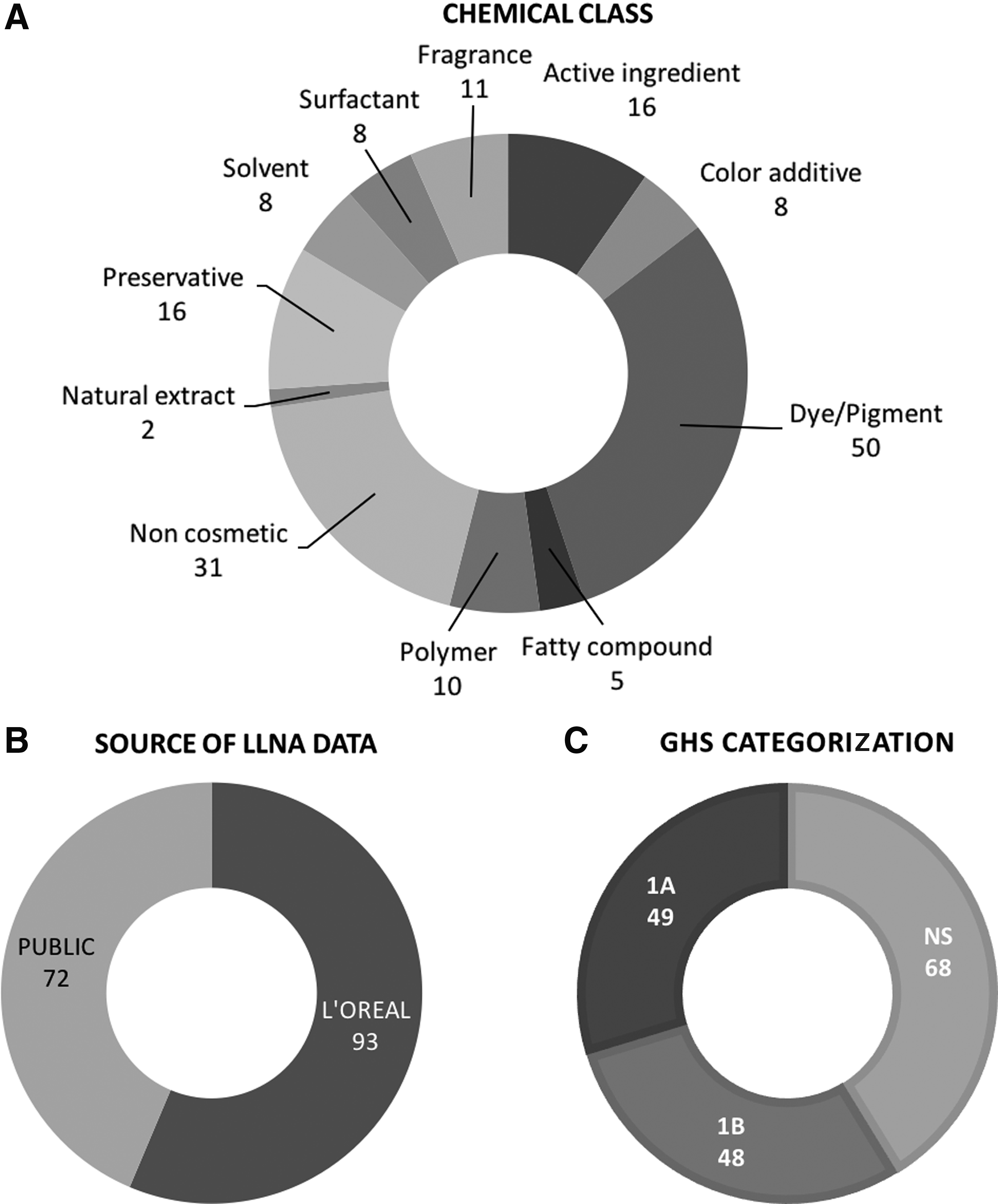
Displays information concerning the combined test and training set of chemicals.
Stacking probability scale is 0–100.
NA, not applicable (for in silico methods); R, reactive; NR, not reactive; NS, non-sensitizer; S, sensitizer; −, negative; +, positive; INC, inconclusive; LLNA, local lymph node assay.
Subsequently, a number of inputs were selected, those aiming to ensure proper coverage of the key events of the AOP using validated tests (DPRA, KeratinoSens, and U-SENS), as well as the most statistically impactful physicochemical parameters, pH and volatility, 35 together with in silico predictions (ToxTree and TIMES-SS), the latter including aspects of metabolic activation. Each of these is detailed below.
Physicochemical data
Volatility was assessed using the MPBPWIN™ model from the open source Episuite™ software. 36 Based on the structure of a given chemical, the model estimates vapor pressure (VP) from various physicochemical equations. These values were converted into volatility classes 37 : VP <10−7 mmHg = non volatile; VP between 10−7 and 10−1 mmHg = semi volatile; VP between 10−1 and 380 mmHg = volatile; and VP >380 mmHg = very volatile. Pragmatically, these last two groups were grouped together into a “very volatile” class. All pH values were obtained using a method adapted from OECD Guideline for the Testing of Chemicals No. 122. 38
In silico inputs
ToxTree, an open-source in silico prediction software from Ideaconsult Ltd containing skin sensitization alerts based on the reaction mechanistic domains classification, was used (http://toxtree.sourceforge.net). Its “Skin Sensitization Alerts” decision tree using “SMARTS,” which relies on a Reaction Mechanistic Domains classification, delivers alerts for a parent chemical structure. These alerts are transparent as for each chemical, the applied decision rules are shown in the software's interface. Where nucleophilic aromatic substitution (SNAr), bimolecular nucleophilic substitution (SN2), acyl transfer agent, Michael acceptor, and Schiff base formation alerts are identified, the chemical is classified as reactive (sensitizer), whereas in the absence of reactivity alerts, it is classified as nonreactive (nonsensitizer). 39
The in silico TIssue MEtabolism Simulator (TIMES-SS) from OASIS-LMC (http://oasis-lmc.org/products/software/times.aspx), integrating the Skin Sensitization prediction model, analyzes the parent molecular structure as well as its simulated metabolites to predict skin sensitization potency based on structural alerts and 3D-QSARs. For each chemical, detailed information on the applied mechanistic structural alerts and metabolite simulation is available in the software's interface. The overall “in domain” prediction that is retained is that of the most potent structure among parent and metabolites, and is expressed as one of following three classes: nonsensitizer, weak sensitizer, or strong sensitizer. 40 For this work, weak and strong sensitizers have been grouped together [as hereafter identified as positive (+)].
In vitro methods
The DPRA 15 represents key event 1 on the skin sensitization AOP.13,14 The reactivity assay DPRA is based on the depletion measurement of two synthetic peptides (containing either cysteine or lysine amino acids) after reaction with the test chemical. Chemicals that induce peptide depletion above a defined threshold are considered to be reactive and thus give a prediction. 41 If the reactivity is below this level, the prediction is negative. Sometimes, the result is regarded as inconclusive, due to the co-elution of both synthetic peptides and the test material.
The KeratinoSens assay 16 models key event 2 of the AOP by measuring the activation of the Nrf2-Keap-1 pathway, the cellular sensor of electrophilic/redox stress, which is induced in skin cells in response to sensitizers31,42,43 and, in particular, in keratinocytes. In brief, HaCaT Nrf2-luciferase reporter cells are exposed to concentrations of the test chemical for 48 hours. A positive prediction occurs when the Imax (maximal gene induction) is statistically significantly higher than 1.5 × basal luciferase activity and the estimated concentration (EC) 1.5 value is below 1000 μM in at least two out of the three repetitions. In addition, at the lowest concentration with a gene induction above 1.5-fold, the cellular viability should be above 70% and the dose response for luciferase induction should be similar between the repetitions. If these conditions are not met, the prediction normally is negative except in the specific situation where a sufficiently high concentration could not be tested, in which case the result is inconclusive. 16
Key event three of the AOP was assessed using the U-SENS assay. 44 This U937 activation test models the maturation of dendritic cells (DCs), which then activate naive T cells. The cell surface marker CD86, one of the classical markers of DC maturation, binds to molecules on T cell surface and is key in the T cell priming process. U-SENS measures the induction of CD86 in U937 cells, which serve as a surrogate for DCs. 42 The individual conclusion of a U-SENS run is considered negative if the stimulation index (SI) of CD86 is less than 150% at all non-cytotoxic concentrations (cell viability ≥70%) and if no interference (solubility, color, or cytotoxicity) is observed. In all other cases, an SI of CD86 higher or equal to 150% and/or if interference is observed, the individual conclusion of a U-SENS run is considered positive. The final prediction is based on the majority concordant results.18,19 This simplified prediction model was peer reviewed by EURL ECVAM. The U-SENS underwent an industry-led validation study designed primarily to address the reproducibility of the method [Within Laboratory Reproducibility (WLR) and Between Laboratory Reproducibility (BLR)]. The WLR assessed in four laboratories on the basis of concordant classifications for 15 chemicals was around 90%. The between-laboratory reproducibility was 84% (n = 38). The accuracy of the method in discriminating between sensitizers and nonsensitizers (LLNA classifications) was 93% (sensitivity 99% and specificity 88%) with the chemical tested in the validation study (n = 38). In addition, predictive capacities (toward LLNA in vivo data) on a larger set of 166 substances tested in-house were provided, indicating an accuracy of 86% (sensitivity 91% and specificity 65%) against LLNA data. This binary prediction from the U-SENS assay was used in the model detailed below.
Data analysis
Prediction methods for binary outcome belong to the wide set of supervised classification techniques. In this article, five methods representing five broad families of statistical models were selected (Boosting, Naïve Bayes, Support Vector Machines, Sparse Partial Least Squares Discriminant Analysis, and Expert Scoring); although very different, all these methods provide binary membership probabilities. Each method has its own variable selection based on a split into three subsamples: learning, test, and validation. To avoid any bias (nonpertinent decision rules) that may be induced by a particular choice of subsets, the splitting procedure is repeated several times (six times for this particular piece of work). The final selection then comprised the variables that were selected in all subsets (full details relating to this process has already been published34,35).
Stacking is known to be a successful way of linearly combining several models.45,46 The global stacking meta-model used for this work was constructed with the complete learning set and was prepared using the seven input variables detailed above (pH, volatility, ToxTree, TIMES-SS, DPRA, KeratinoSens, and U-SENS). These were entered into the model where they were run in the five different supervised classification models (Boosting, Naïve Bayes, Support Vector Machines, Sparse Partial Least Squares Discriminant Analysis, and Expert Scoring), each providing a probability of being a sensitizer. Details of each of these techniques have already been presented elsewhere.24,34,35 The intermediate probabilities delivered by each of the five methods, which are expected to be highly positively correlated (see Urbisch et al. 33 ), are then used in the stacking meta-model to provide a final probability that a substance is a sensitizer, following the general principles already published.45,46 An open software of our stacking model is available in the Supplementary Data (Supplementary Data are available online at www.liebertpub.com/aivt).
Results
As detailed in Tables 1 and 2, the substances chosen for this study contained all reactive classes determined in silico with ToxTree, SNAr, SN2, Acyl transfer agent, Michel acceptor, and Shiff base formation; the wide range of measured pH values (from 1.5 to 11.5) indicates that the set contained a wide variety of acids, bases, and neutral chemicals. There was also a good spread of volatility, but note that to obtain an equilibrated set for the stacking meta-model purpose, the two Spicer classes “volatile” and “very volatile” were grouped together into one “very volatile” class. In the set, all three classes predicted in silico with Times are represented, with the weak and strong sensitizers grouped into “sensitizers” in the stacking meta-model.
A comprehensive overview of the results for the 113 substances used as the training set for this work is presented in Table 1. This set includes 47 substances identified as negative in the LLNA and 66 that were reported to be positive. LLNA results were derived from the database publications47,48 supplemented by historical unpublished data on proprietary substances within the L'Oréal Laboratories database. The training set was used to derive prediction probabilities in each of the five individual models. The relative weights (contribution) of these five models are shown in Table 3. These were then subjected to the stacking analysis to provide an overall probability of being a skin sensitizer. A key benefit of this is that the distribution of the probabilities provided by stacking becomes more bimodal than any of the other models individually, with the consequence that it leads to clearer conclusions for a greater number of chemicals. The probability thresholds to discriminate sensitizers from nonsensitizers can be varied to optimize the balance between predictivity (Kappa) and rate of inconclusive calls (INC) using the seven input variables (Fig. 2). As can be observed on the graph, as the gap between the probability cutoffs is widened, the kappa value increases, but this also impacts the number of inconclusive results, which increase markedly. Accordingly, a balance has to be struck, with the 30%/70% limits being adopted. Therefore, the optimal decision criteria of the model are defined below:
• Chemicals with probability to be sensitizer ≥70% are predicted “Sensitizer”; • Chemicals with probability to be sensitizer ≤30% are predicted “Nonsensitizer”; • Chemicals with probability between those two thresholds are predicted “INC.”
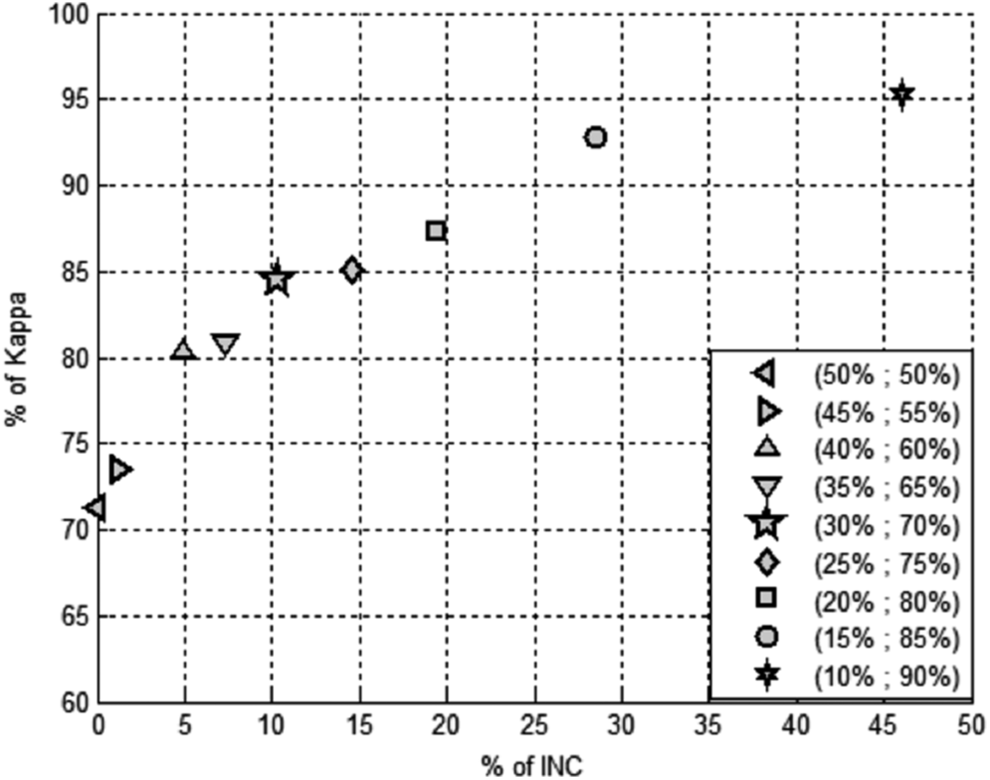
Displays the behavior of the stacking meta-model (% of Kappa and% of Inconclusive data) using different cutoff options.
With these thresholds, the increased performance of the stacking meta-model compared to the individual methods is clearly evidenced in the performance data shown in Table 2. Confidence (kappa) in the stacking meta-model used to integrate the data sources proved to be very high (Fig. 2), and its overall accuracy was better than those from the five individual machine learning approaches, confirming that the stacking meta-model minimized the potential bias of individual statistical models and therefore the uncertainty linked to the structure of the prediction model (data not shown).
For the training set of substances, with the probability cutoffs set at 70% and 30%, the predictive sensitivity was 97%, specificity was 88%, the overall accuracy was 93%, and kappa was 85%. Inconclusive outcomes occurred for 11 substances (4 sensitizers and 7 nonsensitizers) (Table 1). Figure 3 presents the outputs of the stacking meta-model in graphical form.
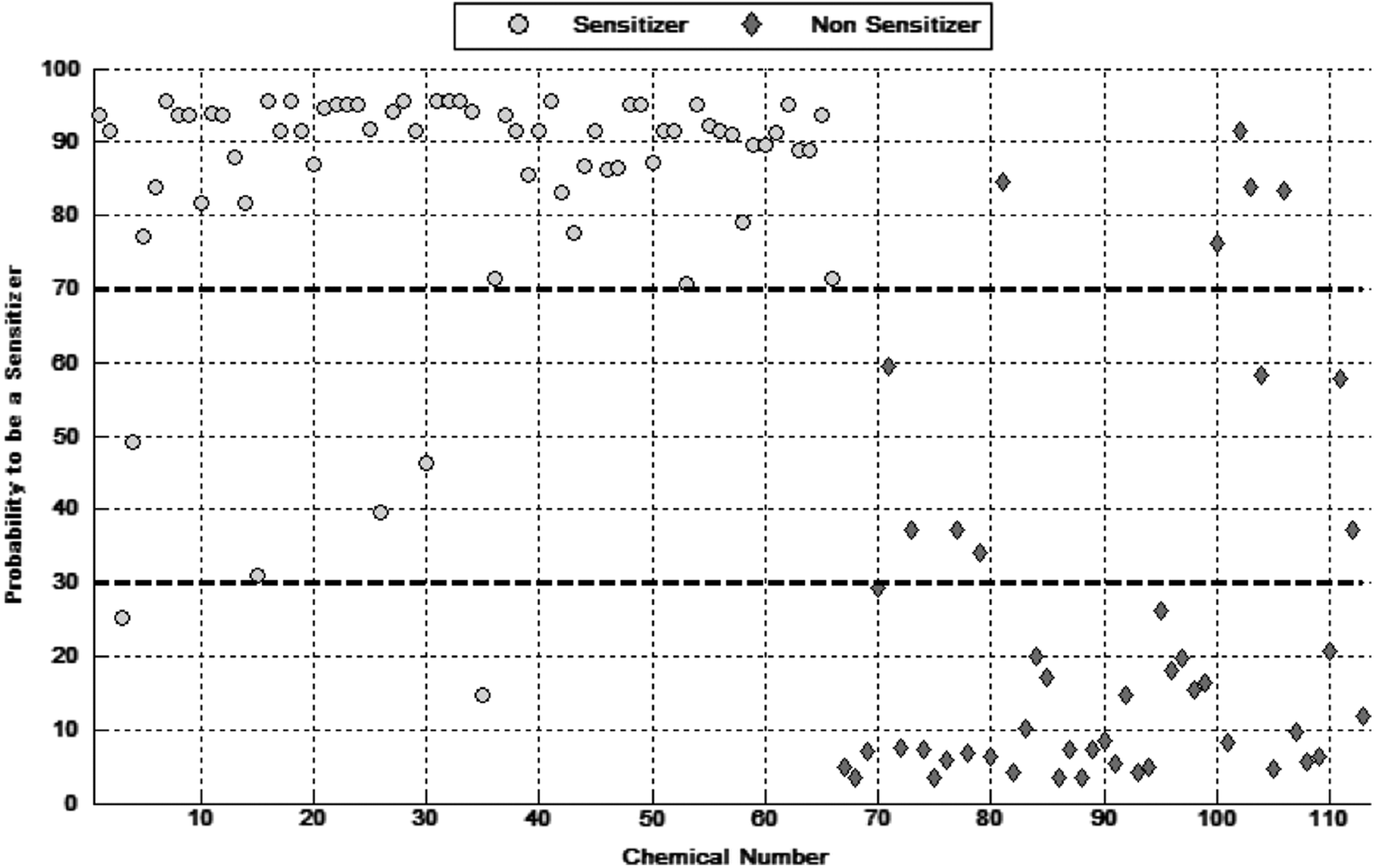
Displays in graphical form the distribution of final probabilities in the stacking meta-model for the training set of 113 substances, with in vivo skin sensitizers shown as “circles” and in vivo nonsensitizers presented as “diamonds.”
A further 52 substances (31 sensitizers and 21 nonsensitizers according to the LLNA) were subsequently assessed to test the effectiveness of the model developed with the training set of chemicals. All the results used to feed the model and the outcome of the final predictions for these 52 substances are presented in Table 2. The LLNA results were obtained from the same sources as those used for the training set. Figure 4 presents the outputs of the stacking meta-model in graphical form. The predictive sensitivity was 89%, the specificity 95%, the overall accuracy was 91%, and kappa was 82%, an outcome very much in line with the training set (Table 4). Also, a similar proportion of substances (n = 6) was deemed inconclusive (Table 2).
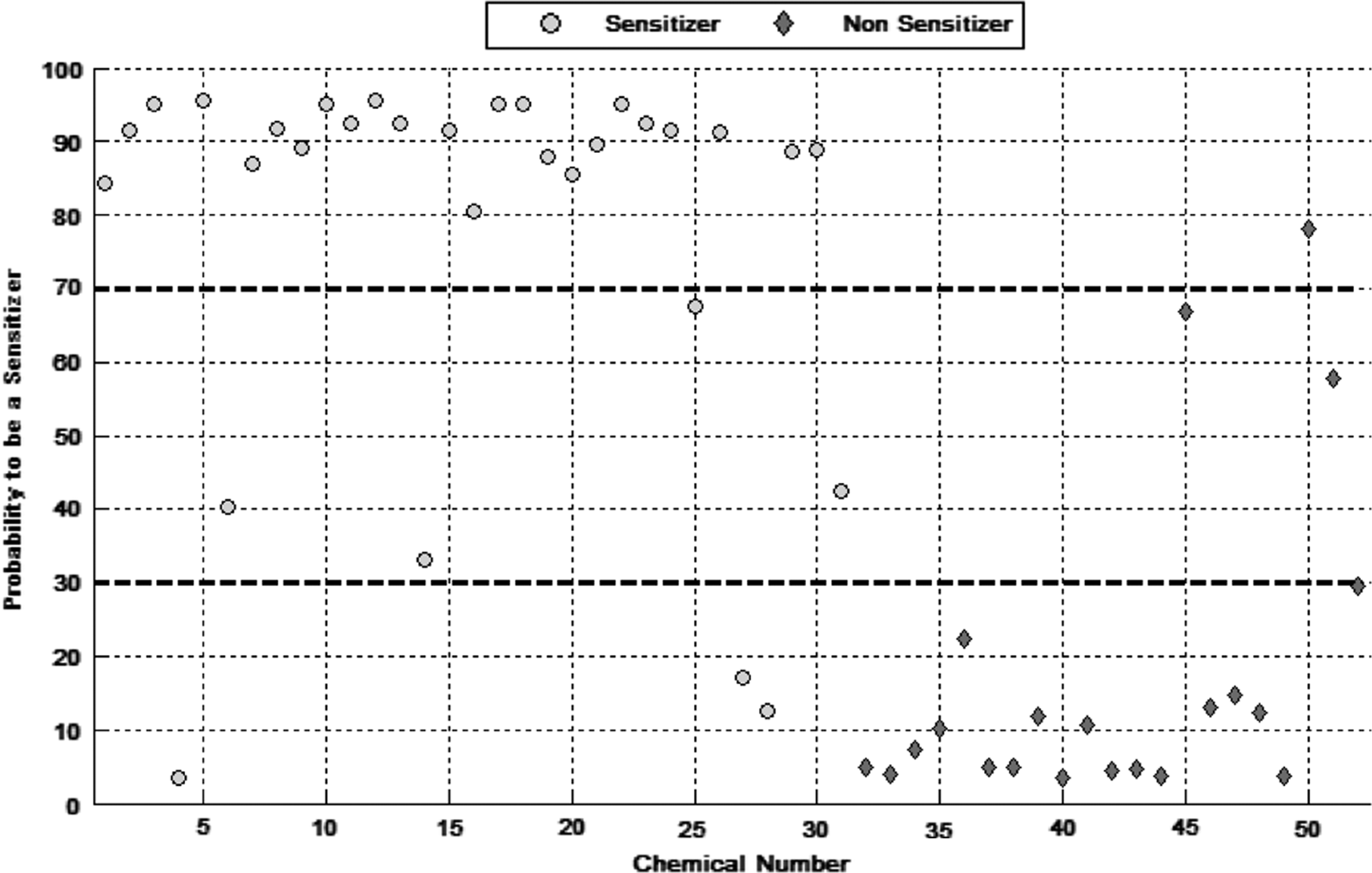
Presents the individual probability to be a skin sensitizer for each substance of the test set of substances given by the stacking meta-model.
The table displays individual performance characteristics for the five inputs to the stacking meta-model to facilitate comparison with the performance of that model.
Performances are calculated relatively to the number of predicted chemicals (excluding INC and/or NA). The number of chemicals tested and predicted varies for the five input models due to the limitations of those methods such that they are unable to address certain types of chemistry (see Tables 1 and 3 for individual results). It is important to note that the performances are defined from different chemical set, therefore no strict comparison should be made.
Across both sets, 17 substances fell into the inconclusive category, resulting from a lack of sufficient data or conflicting datasets. There was not a dominant functional group associated with these, nor physicochemical properties (MW, cLogP, aand volatile class) or skin sensitization reactivity binding class (SN2, Schiff base formation, acyl transfer agent, and Michael acceptor). Neither were there any dominant in vivo drivers of classification for INC (eight sensitizers and nine nonsensitizers in the LLNA). For any of these substances and depending upon their functional importance, it might be appropriate to consider the conduct of further in vitro or in silico work, perhaps together with the application of expert judgment, to clarify their skin sensitization potential. Indeed, a similar strategy could be appropriate for the characterization of any positive substance.
If the training and test datasets were combined, 148 substances in total with the 17 inconclusives excluded, the stacking meta-model offered an overall predictive accuracy of 93%. Despite this high performance, a few substances were clear “outliers,” for example, isopropyl myristate, coumarins, and three proprietary chemicals, OA2, OA57, and OA58. These will be considered in more detail in the discussion.
Discussion
The evolution from in vivo-based toxicological evaluation to predictions based entirely on in vitro and in silico information presents a number of intellectual and practical challenges. Not least among these is how to combine multiple data inputs into a single coherent conclusion. For skin sensitization, one effective strategy could be to adopt a minimalist approach using as little as the results from two non-animal assays, where, unless both results are negative, the substance is regarded as a classifiable sensitizer. 49 Similar approaches involving three assays have been more widely promoted.11,29,50,51 All of these offer a level of predictive performance for regulatory decision-making, 52 which is similar to that of in vivo methods that preceded them, in other words, in the region of 85%. Interestingly, in terms of basic hazard identification for such regulatory classification, more complex statistical analyses and neural network approaches appear to perform at a fairly similar level.27,53
For consumers using cosmetic products, the avoidance of skin allergy is an important and topical health protection end point and goes well beyond the basic requirements of regulatory toxicology. In this regard, the work reported here is directed toward gaining an increased degree of confidence in the predictions from in vitro and in silico methods. The application of seven data inputs to five decision models, followed by application of a statistically based stacking meta-model, delivered an analysis that markedly enhanced both sensitivity and specificity, with an overall accuracy in excess of 90% (Table 4). As noted earlier, for substances falling into the inconclusive category, the conduct of additional assessments could be considered a means to provide greater clarity, but this is highly likely to be on a case by case basis.
Notwithstanding the above, improving confidence in the predictions from non-animal testing also requires that discrepancies are examined carefully. For example, in this test set of 52 substances, the first chemical in the list is isopropyl myristate, rightly regarded as a false positive in the LLNA, but which is confidently predicted as nonsensitizing by the stacking meta-model. This substance is an extremely rare sensitizer: probably the first case was in a feminine hygiene spray. 54 Over three decades later, a German review concluded that it was an “extremely weak sensitizer….or possibly not a sensitizer at all”. 55 This situation remains unchanged; isopropyl myristate likely represents a useful benchmark substance, being at the borderline of what can be detected clinically.
Next in the list is Coumarin, weakly positive at times in the LLNA, but a clear negative in the stacking meta-model. While this substance was often regarded as a very uncommon fragrance allergen, 56 more recent information has indicated an upturn in the frequency of positive reactions to coumarin. 57 However, the issue is complex: ToxTree indicates the substance is a Michael acceptor, yet both TIMES-SS and the DPRA are negative; in contrast, KeratinoSens and U-SENS are positive. Perhaps the key factor here is the purity of the material and the possible presence of other impurities. Thus, while a standard sample of coumarin was a weak skin sensitizer in the LLNA, the highly purified substance (99.9%) was nonsensitizing.58–60 It is reasonable to conclude that coumarin itself is not a sensitizer and should not be identified as such in the stacking meta-model.
The remaining three discordant results were all substances proprietary to L'Oréal Laboratories. OA57 and OA58 are two examples of apparent false negatives. OA57 is an acyl transfer agent, on which basis alone, some evidence of skin sensitization might be anticipated. Surprisingly then, negative results were obtained in U-SENS and KeratinoSens. However, the LLNA was positive with an EC3 value of 17%; so it would be reasonable to regard OA57 as a weak sensitizer. In contrast, OA58 is a linear structure organic chemical without any positive predictions from ToxTree, TIMES-SS, or DPRA. Nevertheless, it gave positive results in U-SENS and KeratinoSens and proved to be a moderate sensitizer in the LLNA. In the absence of any human data, it seems appropriate to conclude that OA58 is a sensitizer and thus a false negative in the stacking meta-model.
OA2 is a complex polymeric material, such that none of the predictions based on chemistry/reactivity could be applied. It had proven to be a borderline positive in the LLNA (EC3 value of 83%), but with positive results in U-SENS and KeratinoSens. However, a human repeated insult patch test (HRIPT) of OA2 carried out at a concentration of 40% was negative (L'Oréal, unpublished data). In the absence of any further information, OA2 might easily be concluded to be a false negative, but the fact that it was barely positive in the LLNA and failed to cause any effect at a very high concentration in a human test likely tips the balance in favor of the negative prediction, from the stacking meta-model being the most appropriate.
As the title of this article indicates, the purpose of the work reported herein is the development of a non-animal approach that will optimize the assurance of consumer safety for the skin sensitization end point. When an ingredient has been identified as a potential skin sensitizer, the assessment of risk normally requires measurement of its relative potency to complete the safety evaluation process.61,62 Current validated non-animal approaches remain somewhat deficient in that respect, although it must be recognized that considerable efforts are underway to address this problem.22,27,53,63,64 For identified skin sensitizers, this current absence of potency data means that strategies such as quantitative risk assessment (QRA) are difficult to employ, leaving only considerations such as the threshold of toxicological concern (TTC), which has only a limited area of applicability to very low use concentrations, as a way forward.65,66 In contrast, nonsensitizing ingredients need not be subject to any risk assessment/management (for this toxicology end point) and they may therefore be used at any level in a product. Consequently, it is essential to have a high degree of confidence in the identification of nonsensitizing materials. Non-animal testing strategies orientated toward regulatory acceptance for chemicals testing (such as REACH) commonly aim to identify sensitizers, and so usually enhance sensitivity, at the expense of specificity.29,67,68 By application of the most commonly used strategy, often referred to as the “2 out of 3” method,29,31,50 this dataset delivers a sensitivity of 93%, but with a specificity of only 59% due to the relatively high proportion of false positives. However, in the work reported here, while retaining a high sensitivity in terms of the accurate identification of skin sensitizing chemicals, confidence that an ingredient is truly non-sensitizing (specificity) has been increased to 90%.
In conclusion, the stacking meta-model reported in this article capitalizes on multiple inputs from seven individual predictions to deliver improved performance and therefore enhanced confidence in the discrimination of skin sensitizers from nonsensitizers. It is suggested that the key remaining gap in this toxicology domain, the prediction of skin sensitization potency, may benefit from a similar approach, maximizing the use of evidence from individual strands of prediction, while minimizing the impact of the limitations from any particular one of them.
Footnotes
Author Disclosure Statement
DAB was compensated by L'Oréal for the time spent in the preparation and review of this article; all other authors are fully paid employees of the L'Oréal company.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.