
Abstract
Reward is thought to enhance episodic memory formation via dopaminergic consolidation. Bunzeck, Dayan, Dolan, and Duzel [(2010). A common mechanism for adaptive scaling of reward and novelty. Human Brain Mapping, 31, 1380–1394] provided functional magnetic resonance imaging (fMRI) and behavioural evidence that reward and episodic memory systems are sensitive to the contextual value of a reward—whether it is relatively higher or lower—as opposed to absolute value or prediction error. We carried out a direct replication of their behavioural study and did not replicate their finding that memory performance associated with reward follows this pattern of adaptive scaling. An effect of reward outcome was in the opposite direction to that in the original study, with lower reward outcomes leading to better memory than higher outcomes. There was a marginal effect of reward context, suggesting that expected value affected memory performance. We discuss the robustness of the reward memory relationship to variations in reward context, and whether other reward-related factors have a more reliable influence on episodic memory.
Memory is limited by constraints such as output interference, temporal discrimination, source confusion, and sensitivity to context (Schacter, 1999). It is therefore adaptive to selectively encode and retrieve events in order to remember items that will support achieving goals (Castel, 2007). A critical question for memory research is to determine which factors lead us to remember certain events and forget others.
The status of reward (versus no reward) as one factor in promoting memory in both incidental and motivated learning has been established across a number of studies (Adcock, Thangavel, Whitfield-Gabrieli, Knutson, & Gabrieli, 2006; Murayama & Kitagami, 2014; Wittmann, Dolan, & Düzel, 2011; Wittmann et al., 2005). However, the degree to which small variations in reward can influence memory is still unclear. That is, to what extent are more rewarding events more memorable than less rewarding events?
Non-human primate neurophysiology suggests that the reward system is responsive to variations in the magnitude of reward (Schultz, 1998; Tobler, Fiorillo, & Schultz, 2005). For instance, dopaminergic neurons in the midbrain appear to respond to prediction error, so that if a smaller than expected reward is given, the neurons respond below their baseline firing rate, and if a larger than expected reward is given, the neurons respond above their baseline (Schultz, 1998). In this way, neurons respond to changes in reward magnitude relative to some global expected value (Schultz, 1998). An alternative form of adaptation, referred to as adaptive scaling, was suggested by Tobler et al. (2005), where the increases and decreases in activity above and below baseline activity remain constant regardless of the magnitude of the increase or decrease in reward (equivalent to the sign of the prediction error).
Bunzeck, Dayan, Dolan, and Duzel (2010; henceforth Bunzeck et al.) extended these findings to human reward processing. Using functional magnetic resonance imaging (fMRI) they first provided evidence that the reward circuitry in the brain, specifically the nucleus accumbens, orbitofrontal cortex (mOFC), and medial prefrontal cortex (mPFC), show adaptive scaling of reward. Second, in a behavioural experiment Bunzeck et al. linked adaptive scaling of reward to enhanced memory encoding. Before discussing the significance of these findings, we briefly summarize the adaptive reward coding task and the findings from their initial fMRI study.
Bunzeck et al. conducted a version of the task used for adaptive reward coding in nonhuman primates (Tobler et al., 2005). On each trial, a reward cue (a coloured square) was presented (see Figure 1). The colour of the cue informed the participant which two reward values could follow. One cue predicted a high (£1) or medium (£0.50) reward value; one a medium or low (£0.15) value; and one a high value or a low value. The reward values associated with each cue were presented with equal probability. Participants then responded by indicating whether the reward was the higher or lower option associated with the cue.
Experimental task. Each of the three reward cues (coloured squares) indicated two possible reward values that would occur with equal probability. After the reward value was presented, participants were required to indicate whether they saw the higher or the lower reward value. A picture of a scene was then presented, which participants were required to classify as indoor or outdoor in order to receive the reward. Adapted from Bunzeck et al. (2010). To view this figure in colour, please visit the online version of this Journal.
Bunzeck et al. fit three predictors to the blood-oxygen-level-dependent (BOLD) data to explain activity in the midbrain during reward processing. The three panels in Figure 2 illustrate the qualitative patterns of possible haemodynamic BOLD responses to reward for each of the three predictors. The first predictor, “adaptive scaling”, expresses each reward value in terms of the cue context and encodes the reward value as either the higher or the lower of the two possible reward values, disregarding the actual reward value (Panel A). In this way, neural activity associated with a high reward outcome is predicted to remain constant across actual differences in reward value. The second predictor, illustrated in Panel B, refers to the actual value of the outcome, independently of the context in which the reward occurs (“absolute coding”). Panel C demonstrates reward encoding in terms of “linear prediction error”. This takes into account both the reward value and the reward cue context. Each reward outcome is processed in terms of the difference between the expected value for a given reward cue and the actual value of the reward received. The best fitting model was found to be “adaptive scaling” of reward, meaning that the reward outcomes are processed relative to the reward context as a binary outcome—the higher or the lower reward value. This approach suggests that the reward system is not responding to reward value, as captured by the predictors “absolute coding” or “linear prediction error”.
One of three possible reward cues (coloured squares) indicated which of two possible reward values would follow with equal probability. Panels A to C illustrate the predicted blood-oxygen-level-dependent (BOLD) responses to activity at outcome of reward based on three models of reward processing: adaptive scaling (A); absolute encoding (B); and linear prediction error (C). Adapted from Bunzeck et al. (2010). To view this figure in colour, please visit the online version of this Journal.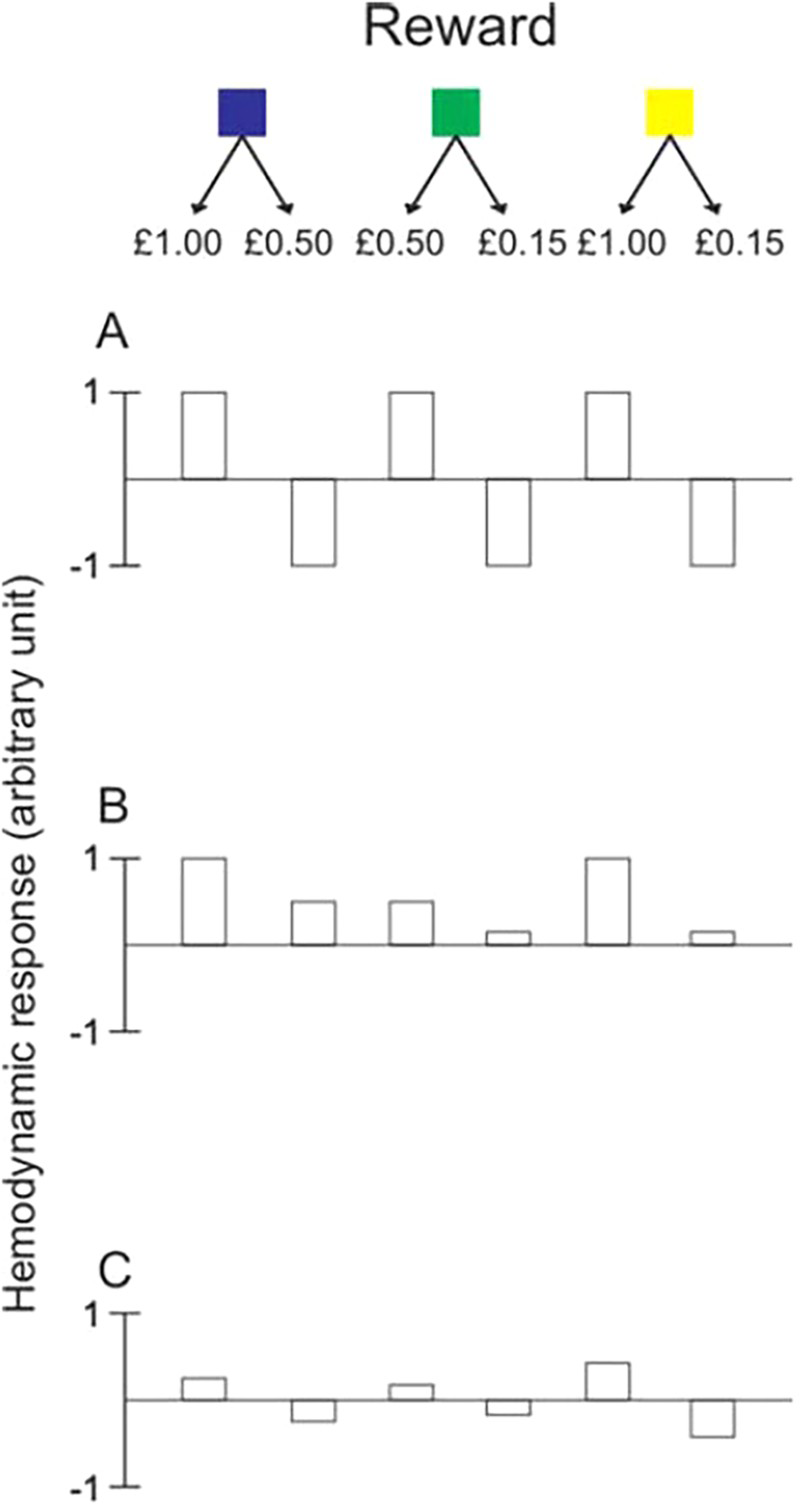
The neuroscience of reward processing has guided research on the relationship between reward and memory (Shohamy & Adcock, 2010; Wittmann et al., 2011). A critical question in the reward–memory literature concerns the sensitivity of memory encoding to changes in reward-related properties. In their behavioural study, Bunzeck and colleagues directly linked adaptive coding of reward to memory encoding. The paradigm used in their fMRI study was extended to include a memory component. Each trial of the reward-processing task was followed by the presentation of a photograph depicting a scene, and participants responded by saying whether the scene was “indoors” or “outdoors”. The picture was presented the next day in an incidental memory test.
Each picture was effectively associated with a reward value. Average recognition memory corrected hit rates were calculated for each of the reward values, in the three reward contexts. Figure 3 shows that recognition memory was better for the higher outcomes than for the lower outcomes across each context. This was independent of absolute reward value. The critical evidence for this is the comparison of memory performance for the medium reward value (£0.50) when it occurred as the higher and as the lower outcome. The recognition memory rates for pictures associated with £0.50 presented as a higher outcome were significantly better than those for £0.50 as the lower outcome. This study has been cited as evidence that memory performance is adaptively scaled in line with the contextual reward values in the environment (Wittmann et al., 2011), and that a common mechanism controls the midbrain response to reward and its effects on memory.
Results from Experiment 2 in Bunzeck et al. (2010), reproduced with permission.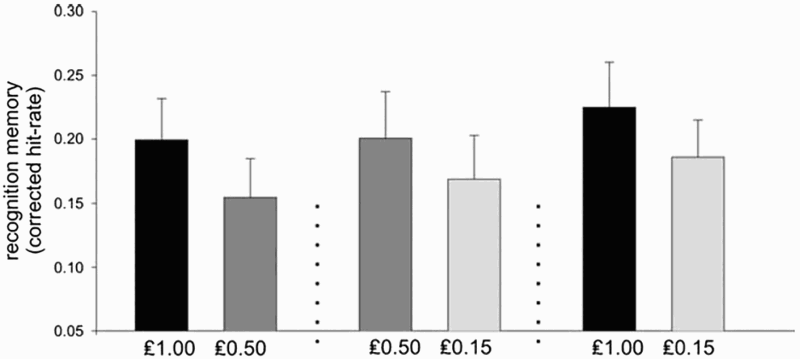
The results of Bunzeck et al. demonstrate that under incidental learning conditions the reward–memory relationship is sensitive to small changes in reward magnitude, relative to a context-specific expected value. However, other incidental learning studies that have varied reward magnitude have not seen differences in memory performance across variations in reward value (Wittmann et al., 2011). In an incidental memory paradigm, Wittmann et al. (2011) found a non-linear effect of reward on memory performance, with only significant differences in memory performance for rewards versus no rewards, and no further effect of varying amounts of positive reward. One explanation for this finding is that the reward system may not have sufficient fidelity to differentially respond to similar reward values. However, this explanation would be at odds with evidence from the primate and human literature (Bunzeck et al., 2010; Diederen, Spencer, Vestergaard, Fletcher, & Schultz, 2016; Park et al., 2012; Tobler et al., 2005).
Wittmann et al. (2011) suggested that their lack of an effect compared to the finding from Bunzeck et al. could be due to differences in experimental procedures. In the Wittmann et al. study, participants received a single reward cue for each trial and then positive or negative feedback if the reward was earned or not. In contrast, Bunzeck et al. focused on the reward activity at reward outcome. After a cue and reward outcome were presented, participants were required to judge whether or not the reward value was the higher or lower outcome associated with the cue they had just seen. Arguably, this requirement may have served to sharpen the neural representation of the rewards as the higher or lower outcome, and to ensure that rewards were processed as values within a context.
Alternatively, effects of reward magnitude on memory may also be influenced by reward salience, as opposed to valence. Madan and Spetch (2012) have shown a non-linear relationship between reward value and memory in incidental learning such that words associated with the highest and the lowest reward values are better remembered than those linked to intermediate reward levels. The authors propose that this finding may be driven by an interaction between reward value and reward salience. There is neural evidence supporting this distinction in reward processing, and the ventral striatum responds to both these dimensions (Cooper & Knutson, 2008; Jensen et al., 2007; Litt, Plassmann, Shiv, & Rangel, 2011), such that there is a stronger neural response linked to the most positive and most negative reward values (Cooper & Knutson, 2008). More generally, this is consistent with a prediction error account of reward processing: A partially signed prediction error model treats appetitive and aversive events equivalently and is effectively responding to the presence of an unpredicted significant event, and not to whether the event is better or worse than expected (Jensen et al., 2007). Using fMRI, Jensen et al. (2007) demonstrated that activity in the ventral striatum was correlated with a partially signed prediction error coding the salience, as opposed to value, of a reward outcome.
The work from Bunzeck et al. has contributed to our understanding of the relationship between reward and memory and is often cited as evidence of striatal contributions to declarative memory (Scimeca & Badre, 2012; Shohamy & Adcock, 2010). To our knowledge, the Bunzeck et al. study remains the only study in incidental learning to examine the effects of reward magnitude both in terms of neural correlates and in terms of behavioural effects. To some extent these issues have been examined in more depth in the motivated learning literature. There is a strong body of evidence in motivated learning demonstrating that people are able to prioritize high-value over low-value items in memory. These effects have been shown using a variety of memory tests including free and serial recall, and recognition memory (Adcock et al., 2006; Eysenck & Eysenck, 1982; Harley, 1965; Loftus & Wickens, 1970; Madan, Caplan, Lau, & Fujiwara, 2012; Spaniol, Schain, & Bowen, 2013; Wolosin, Zeithamova, & Preston, 2012). Furthermore, these findings extend to value-based learning where points are used instead of monetary incentives (Ariel & Castel, 2014; Castel, 2007; Castel, Benjamin, Craik, & Watkins, 2002; Castel, Murayama, Friedman, McGillivray, & Link, 2013; Friedman & Castel, 2011; Soderstrom & McCabe, 2011). Taken together these findings suggest that people are acting to maximize reward and are able to allocate cognitive resources during learning so that higher value items are better encoded than lower value items. The role of value in memory has important implications for educational research (Howard-Jones, Demetriou, Bogacz, Yoo, & Leonards, 2011). This is supported by recent findings from fMRI studies showing differences in activity in the fronto-temporal network, associated with semantic processing, during processing of high- and low-value words (Cohen, Rissman, Suthana, Castel, & Knowlton, 2014, 2016).
As the above evidence suggests, under different reward conditions there may be different motivational processes underpinning the relationship between reward and memory. Nevertheless, the findings from Bunzeck et al. along with the suggestion that there may be a direct mapping between reward processing and memory performance are often cited in the motivated learning literature (Spaniol et al., 2013). The work by Bunzeck et al. has been used as a building block in our theoretical understanding of the relationship between reward and episodic memory, and behavioural research has been conducted and interpreted in line with their findings (Murayama & Kitagami, 2014; Spaniol et al., 2013; Wittmann et al., 2011). Episodic memory is a critical system for learning and decision making; one's current actions and choices are dependent upon one's past (Lengyel & Dayan, 2007; Nairne, 2005, 2014; Shohamy & Adcock, 2010). For example, recent work in the decision-experience literature has illustrated that people are biased towards remembering extreme outcomes (Ludvig, Madan, & Spetch, 2015; Madan, Ludvig, & Spetch, 2014), and that these memory biases are correlated with risky choices. In another study, Ludvig et al. (2015) showed that priming memories for recent wins leads to risk seeking, but that priming losses does not lead to risk aversion. It is therefore important to establish the degree to which the relationship between reward and memory is monotonic.
Initially we were interested in exploring the potential role of adaptive scaling in motivated learning. In an unpublished experiment we began with a direct comparison of adaptive scaling in motivated learning and incidental learning using the Bunzeck et al. paradigm (see Supplemental Online Material Figure S1). We failed to find any reward-related effects on memory, in either incidental or motivated learning. This difference in findings could have been attributed to several procedural factors, and we were therefore motivated to conduct a direct replication of the behavioural study of Bunzeck et al.
Experimental Study
Method
The experimental procedure followed that described by Bunzeck et al. (2010, p. 1382) and is illustrated in Figure 1. The experiment was run as four blocks of 72 trials. Each trial consisted of a reward classification and a picture classification task. In the reward task, a cue (coloured square) was presented for 500 ms. The colour of the cue informed the participant which two reward values could follow. One cue predicted a high (£1) or medium (£0.50) reward, one a medium or low (£0.15) reward, and one a high or low reward.
The mapping between reward colour cues and values was counterbalanced across participants. After the cue, a fixation cross appeared for 2750 ms. This was followed by the reward values for 1000 ms. Participants used the left/right arrow keys to indicate whether the reward was the higher or lower option associated with the cue. A photograph was then presented for a further 1000 ms, after which the fixation cross appeared for 1875 ms. During this time participants had to indicate, using the right/left arrow keys, whether the photograph depicted an indoor or outdoor scene. In order to maximize stimulus reward associations, the timings between the cue, the reward, and the picture were fixed.
Participants were asked to respond as quickly and as accurately as possible.
Participants earned rewards on the trials where they correctly classified the reward and the picture. They were told that they would be paid 10% of all their earnings, where the maximum possible earnings was £16. Participants were told they would complete a similar computer-based task the following day, but that they would not earn further rewards or payment during this task. One day later subjects performed a recognition memory test. The 288 previously seen pictures (48 per reward condition) and 48 new distractor pictures were presented at the centre of the screen in a random order. The recognition test followed the “remember/know” procedure of Tulving (1985). Using the left/right arrow keys, participants had to make an old/new judgment. After “new” judgments, participants were asked to rate how confident they were about this decision by deciding whether the picture was “certainly new” or “guess”. After “old” decisions, subjects were asked to indicate whether they were able to recollect something specific about seeing the picture during the study phase “remember”, or whether they simply felt the picture was “familiar” or they were guessing that the picture was old (“guess”). Participants had 4 s to make each of the two judgments, and there was a break of 15 s after every 84 pictures. The images used in this study were the same as those used in the original.
Participants
We had a target sample size of 40 participants (age range = 18–32 years, mean = 21.3 years, SD = 3.23; 12 males and 28 females). The original paper did not provide standard errors, and so we were unable to perform an accurate effect size and power calculation. In order to determine our sample size, we used the heuristic that a sample size 2.5 times greater than the original will allow us to detect a true effect with a power of approximately 80% (Simonsohn, 2015).
A total of 48 participants were tested. Eight participants’ data were removed from the analysis for the following reasons: One person did not attend the second session, three participants’ testing sessions were incomplete due to technical issues with the network, and four participants did not respond accurately to the reward task—either by pressing incorrect response keys or by not engaging with the task. These four participants scored below the exclusion criteria (85%) specified in our pre-registration document (https://osf.io/xsrhj).
Results
The recognition memory analysis was conducted in line with the analysis in the Bunzeck et al. paper and is based on a model of recognition memory that assumes that recollection and familiarity are distinct processes (Yonelinas & Jacoby, 1995). Recollection requires recall of contextual aspects of encoding of the stimulus, whereas familiarity refers to an assessment of stimulus recency, without any contextual details of recollection (Libby, Yonelinas, Ranganath, & Ragland, 2013). Participants must classify their responses to “old” items as either “remember” responses, where they can identify contextual detail about the encoding of the stimulus (e.g., whether it occurred early in the experiment), or as “know” responses, where they are sure that the item was presented but cannot recall any additional information. According to a model of recognition memory (Yonelinas & Jacoby, 1995), the “remember” and “know” responses are thought to map onto the psychological dimensions of recollection and familiarity. False-alarm rates are calculated for both “remember” and “know” responses. A recollection score (RCorr) is calculated by taking the proportion of correct “remember” responses and subtracting false alarms (where a “remember” response was made to a new item). The proportion of “know” responses corrected for “know” false alarms (KCorr), is then used to calculate a familiarity estimate, known as FCorr. The familiarity estimate is equal to KCorr divided by 1 – RCorr. By adding the RCorr and FCorr estimates together an overall corrected hit rate for recognition memory was obtained in the same manner as in Bunzeck et al.
During encoding, participants responded quickly and accurately to the reward task (see Appendix Table A1 for a summary of the reaction time data). In the supplemental materials of the Bunzeck et al. paper the authors report that they conducted a 3 × 2 analysis of variance (ANOVA) on reward-related reaction times (RTs) with the factors reward context (high–medium; medium–low; high–low) and reward outcome (higher or lower). They reported significant effects of reward context and reward outcome on reaction time as well as an interaction between reward context and outcome. To summarize their results, reaction times were fastest for the high–low reward context, and there was no difference in RTs between the high–medium and medium–low contexts. Bunzeck et al. also found faster RTs for the higher of two reward outcomes.
We replicated this analysis on our RTs for the reward classification task and did not find any significant main effects or interactions (see Appendix Table A2). Although no effects in our RT analysis were significant, they do appear to follow the same numerical pattern of faster RTs for higher outcomes. Participants in our study had lower RTs across the board than those in the original study, but as the d′ values show in Table A1, there was no cost to accuracy. Accordingly, our participants appear to have been engaged with the task. In line with the original study, we also conducted a 3 × 2 ANOVA on picture RTs and did not find any main effects or interactions (see Appendix Table A3). This is consistent with the original findings.
Figure 4 shows recognition memory performance: The corrected hit rates for each of the conditions were lower than those in the original study. Recognition memory was higher for the lower of the two outcomes in each reward context. Recognition and familiarity rates, reward context (high, medium, and low), and relative reward outcome (higher or lower) were entered into a 3 × 2 × 2 ANOVA, which found a main effect of recognition memory type, F(1, 39) = 18.05, p <. 001, Recognition memory performance one day after encoding. Recognition rates are measured as corrected recognition rates plus corrected familiarity rates. Error bars show within-subject error bars calculated using the method in Morey (2008)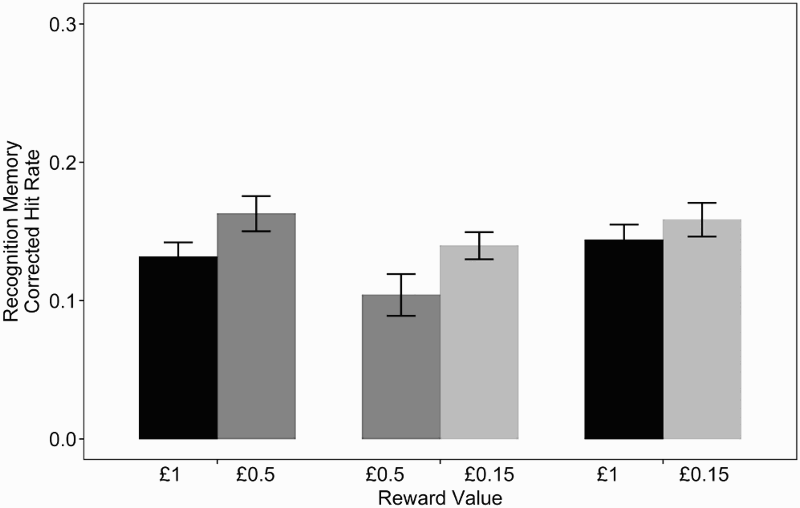
Although it did not appear to offer additional information over the main effect in the ANOVA, in order to fully replicate the original analysis we also conducted a post hoc t test comparing the lower and the higher reward outcomes (collapsing across context). We found that memory performance was significantly more accurate for lower outcomes (M = .15, SEM = .01) than for higher outcomes (M = .13, SEM = .01), t(39) = 3.08, p = .004,
Our results for recognition performance across reward cue and outcome do not match the findings from the original paper. Our results indicate that lower outcomes lead to better memory performance than higher outcomes. This pattern is the opposite of the findings in the original study, where memory performance was better for the higher of the two reward outcomes.
Given our marginal effect of reward context, we ran post hoc Bonferroni-corrected t tests using adjusted alpha levels of .017 across the three different reward contexts: high–medium (£1 and £0.50; M = .14, SEM = 0.02), medium–low reward context (£0.50 and £0.15; M = .12, SEM = .02) and high–low reward context (£1 and £0.15; M = .15, SEM = .1). Memory performance did not significantly differ across any of the pairs of reward contexts: high–medium reward context compared to the medium–low, t(79) = 2.07, p = .04,
In line with the original analysis, we ran a t test comparing the memory performance for pictures paired with the £0.50 value when it occurs as the lower reward outcome with that when it occurs at the higher reward outcome. We found a significant difference for memory performance associated with the value under the two different reward contexts, with memory being better when £0.50 is presented as the lower (M = .16, SEM = .01) outcome than as the higher (M = .10, SEM = .02) outcome, t(39) = 2.71, p = .010,
By replicating the analysis conducted by Bunzeck et al. we have found effects of adaptive scaling on memory but in the opposite direction to those observed in the original study. Given these conflicting findings, it is important to estimate a graded measure of the strength of evidence in favour or against the adaptive scaling hypothesis. A critical question is what the strength of this evidence is when the data from both studies are combined. Bayes factors are well suited to quantify strength of evidence as they allow the researcher to state evidence in favour of both the null and the alternative hypothesis (Dienes, 2011; Rouder, Speckman, Sun, Morey, & Iverson, 2009; Wagenmakers, 2007). This evidence is expressed in terms of the probability of a hypothesis conditional upon the observed data, and the evidence is not affected by sample size. Although the strength of evidence for either hypothesis may increase with sample size, this increase is not biased in favour of either hypothesis. Finally, for small sample sizes, where it is hard to differentiate between approximate and exact invariance, Bayesian statistics allow us to gain evidence for a null effect. This is particularly important here where we are dealing with small effects and relatively small sample sizes. For these reasons, analysing both the original data and our data from the replication study allows us to directly compare the evidence for adaptive scaling across experiments.
We collapsed across memory type and ran a Bayes factor ANOVA on the data. We used the Bayes Factor Package in R to compute Bayes factors (Morey & Rouder, 2015). This analysis compares a set of more complex models against a null model that only has a subject-specific intercept. For the purpose of comparing this analysis to the original, we focused on the models with reward cue and reward outcome as the main predictors. If a model containing either reward context or outcome helps account for variance in the dependent variable then these models will perform better than the null model. The Bayes factors obtained from this analysis quantify the strength of evidence in favour of each model and inform us how much of prior beliefs should shift in response to the data obtained.
According to Jeffreys (1961) we can interpret odds greater than 3 as some evidence, odds greater than 10 as strong evidence, and odds greater than 30 as very strong evidence for a particular hypothesis compared to an alternative (Wagenmakers, 2007). The subscript of the Bayes factor (“10” or “01”) indicates the direction of the model comparison: in favour of the alternative of the null, respectively.
We used the default settings for the priors in the Bayes Factor Package for R (Morey & Rouder, 2015). The scale of the effect size (rscale) was set to .707, which is the “medium” prior. It should be noted that our results do not change if the narrower or the wider prior is used. For a discussion on priors see Rouder, Morey, Verhagen, Province and Wagenmakers (2016).
There was ambiguous evidence regarding an effect of context (BF01 = 1.14). There was some evidence in favour of an effect of outcome (BF10 = 4.57), albeit in the opposite direction to the original result. The critical comparison that provided evidence for adaptive scaling in the original paper was between the £0.50 reward value when it appears as the higher or lower outcome. Using a Bayesian t test we found some evidence that the recognition memory rates for the £0.50 in the high reward context was greater than recognition memory for the £0.50 in the medium reward context (BF10 = 4.13). Again, this effect is in the opposite direction to the original effect.
The authors of the original study shared their data with us, allowing us to analyse their data using Bayes factors for comparison. According to this analysis of the original data there was some evidence against an effect of reward context on memory (BF01 = 3.12) and some evidence in favour of an effect of outcome (BF10 = 3.57). Again, we conducted a Bayes factor t test on the critical comparison in the Bunzeck et al. study: the difference between memory performance for £0.50 reward outcome in a high-medium and in a medium-low reward context. We found inconclusive evidence in favour of the £0.50, as a higher outcome, leading to better memory performance than the £0.50 as a lower outcome (BF10 = 2.21).
Finally, we conducted the same Bayes factor analyses on the combined data from the original study and the replication (Rouder, Morey, & Province, 2013; Rouder, Morey, Speckman, & Province, 2012), so there were a total of 56 participants. This combined analysis demonstrated that there was some evidence in favour of an effect of reward context (BF10 = 4.25) and inconclusive evidence regarding the role of reward outcome with similar recognition memory rates for higher and lower outcomes (BF10 = 1.25). Lastly, we conducted a Bayes t test on the critical comparison for the combined data set (BF10 = 0.52), which indicated inconclusive evidence regarding the critical comparison of the £0.50 across the two conditions.
General Discussion
Our results do not provide evidence for the sensitivity of memory to adaptive scaling of reward values as described by Bunzeck et al. Instead we find some evidence in our data for an effect of lower reward outcomes enhancing memory performance and a marginal effect of reward context and therefore expected value on memory. The effect sizes are relatively small, as is the strength of evidence in the data as assessed with Bayes factors. Before reaching any conclusions regarding the differences between our findings and the original, it is necessary to determine whether there were any ways in which the methods employed in our replication differed from the original.
Our replication was pre-registered, and the registration form is available on the Open Science Framework (https://osf.io/xsrhj). Furthermore, we corresponded with the original authors to obtain details regarding their methods and analysis of their data. This replication aimed to follow the experimental procedure set out by Bunzeck et al. as closely as possible, and we are unaware of any ways in which our procedure differed from the original. We used the original stimuli from the Bunzeck et al. paper and all of the timings followed those in the original study. We tested a similar cohort of subjects, we kept the age range of participants the same as those in the original study, and our participants had a similar (although slightly lower) average age. Compared to the original, we did have a significantly higher proportion of females to males in our sample, but there are no known gender effects in the reward–memory relationship. In line with the guidelines suggested by Simonsohn (2015), we tested a sample size 2.5 times larger than the original to obtain an expected power of approximately 80% power in our replication.
In addition to the failure to replicate the memory enhancement for contextually higher rewards, there are two further ways in which our data do not “match” that of the original. Firstly, the recognition rates in our study were lower than in the original study, which is surprising given that the images used and the instructions for the recognition test were identical. Secondly, we did not see any significant effects of reward on reaction time in the reward classification task in the learning phase. Numerically, participants in our study had lower RTs across the board than in the original study; however, the accuracy was overall very similar in the two studies (see Supplemental Material Table S1). Although there is some evidence that rewards may influence response vigour (Niv, Daw, Joel, & Dayan, 2007), we are not aware of any a priori, theoretical reason why a behavioural effect of reward on memory would be contingent upon differences in reward-related RTs. Accordingly, although previous studies in the reward memory literature have found faster reaction times for high than for low rewards (Adcock et al., 2006; Wittmann et al., 2005), there is no reason to expect that the magnitude of the reward effect on memory depends on the magnitude of the reward effect on RT. In addition, any overall differences in RT may be attributed to differences in the lab settings, equipment used, the participant pool, or a combination of these factors. We therefore do not think that our failure to replicate this finding, or our faster average RT, can explain our lack of evidence for adaptive scaling effects on memory.
Our calculation of the strength of evidence in the original study, combined with our effect size estimates, indicates that the effects of adaptive coding of reward on memory are relatively small. Therefore, our failure to replicate this finding could be due simply to the small and fragile nature of the effect: Some studies (especially when the sample size is small) will fall on the “right” side of p = .05, and other studies will not. Indeed, computing a more graded metric of evidence in favour of adaptive scaling in the form of Bayes factors, it is clear that there is some positive evidence in favour of an effect, albeit in opposite directions, of relative reward outcome (lower vs. higher) in the original study and in our study. Therefore, when we combine the data from both studies, the evidence is ambiguous (Bayes factor close to 1). For the more the critical comparison of the medium reward (£0.50) in two different contexts (one in which the medium reward is relatively low and one in which it is relatively high) a Bayes factor analysis suggests that the original evidence for an effect was weak (Bayes factor around 2). In our study, the evidence is stronger (Bayes factor around 4), but again in the opposite direction.
Across studies in the reward–memory literature there is substantial variability in the reward–memory effect, including factors such as the exact manner in which reward cues and outcomes are presented, paired with stimuli, and the expectancy of participants (incidental or motivated learning). Given that we are often dealing with small effect sizes, it is important that there exists a true record of attempts to look at the conditions under which different reward–memory related effects occur. This will help establish the size of the effect and in this case the necessary and sufficient conditions under which adaptive scaling of reward influences memory encoding. It is possible that others have failed to observe such effects, especially as reward-related effects are relatively small, and one goal of this paper is to ensure we do not contribute to the “file drawer problem”.
Our failure to replicate could in part be due to mediating factors in the reward–memory relationship. In this case, a potential role of performance-related anxiety has been suggested to us by the original authors (Dayan & Bunzeck, personal communication, February 18, 2014). Previous research indicates that the reward–memory relationship is in some instances mediated by performance anxiety, in particular where reward is dependent on the to-be-remembered items (Callan & Schweighofer, 2008; Murty, LaBar, Hamilton, & Adcock, 2011). These findings are more relevant to the motivated learning literature, where a participant's memory performance determines their earnings. In the current study, during the encoding phase participants are unaware of the memory component to the task. In addition, participants were very accurate in performing the adaptive scaling task. Having said this, any element of performance-related reward could have induced anxiety and therefore may be worth controlling for in future reward-related memory studies. If this is the case, it remains unclear as to why this did not influence findings in the original study. Furthermore, there is the possibility that other individual difference factors such as personality or genetics could contribute to the variability in results (Krebs, Schott, & Düzel, 2009; Wittmann, Tan, Lisman, Dolan, & Düzel, 2013). However, at this stage there is no evidence to suggest that these factors mediate the reward–memory relationship (Wittmann et al., 2013).
It is important not to over-emphasize the potential contribution of hidden or unknown moderators. Beyond those possible moderators mentioned above there are also many others, for example the chance that experimenter-specific effects affected either our study or the original. However, if such incidental features of the experimental settings could be responsible for completely flipping the pattern of results, then the incidental effects are clearly stronger than the underlying effect of interest. If that were the case, it would suggest that the paradigm used here (and in other studies) is not suited to assess the robust operating characteristics of the systems that link reward to memory. Another alternative, of course, is that the difference in results between the studies is attributable solely to sampling variability.
Not only did we fail to replicate the original findings, we actually found some evidence of an effect in the opposite direction. Interestingly, there is previous evidence in the reward–memory and decision-making literature that negative outcomes can promote memory performance (Madan et al., 2014; Murty, Labar, & Adcock, 2012). Aside from their role in positive motivation, dopamine neurons are also thought to indicate non-rewarding but salient events and even aversive events (Bromberg-Martin, Matsumoto, & Hikosaka, 2010). Murty et al. (2012) found that mean recognition rates were significantly greater for pictures paired with the threat of punishment. It is possible that in our replication the lower of the two outcomes was seen as an adverse outcome and was processed as a punishment, thus leading to better memory performance. Incidentally, Murty et al. (2012) note that the overall recognition rates in their study were lower than in their work on reward and motivated learning (see also Adcock et al., 2006). Considering the present experiment in isolation, these punishment type effects may also explain our lower recognition rates in this replication.
Furthermore, it has been shown that across a range of positive reward values, the most positive and the most negative values lead to better memory performance (Madan & Spetch, 2012). Madan and Spetch (2012) propose that a model containing both reward value and reward saliency best explains memory performance. Moreover, it has been suggested that the divergent effects of reward value on memory across the literature can be explained by interactions with the salience, arousal, and priority processing of stimuli (Clewett & Mather, 2014). The data from this experiment cannot easily be explained by a theory of reward salience. If reward saliency referred to the outcomes in each reward context, we would not predict a difference in memory performance linked to the higher and lower reward outcomes. In contrast, if the term is applied across all values in the experiment it would be expected that the mid-range £0.50 reward value would be less salient and would consistently lead to lower memory performance. In contrast, our data do show some (albeit weak) evidence of contextual effects of reward on memory processing, with lower reward outcomes leading to enhanced memory performance. However, this may be an artefact of the current experimental design, which was not intended to test the influence of reward salience on memory.
There is existing evidence that suggests that reward outcome is a critical factor in the reward–memory relationship (Mason, Ludwig, & Farrell, 2016). Mather and Schoeke (2011) examined the effects of reward anticipation and outcome on incidental memory encoding. They found there was a substantial effect (
Although there is substantial evidence of adaptive scaling of reward in the brain (Bunzeck et al., 2010; Diederen et al., 2016; Park et al., 2012; Tobler et al., 2005), the evidence regarding a direct mapping of reward processing patterns in the brain and memory is far from conclusive. It is important that theories relating to dopaminergic consolidation go beyond looking for a direct relationship between dopamine activation in the brain and memory performance. For example, in a series of studies in motivated learning (Mason, Ludwig, & Farrell, 2016), we have found no relationship between reward uncertainty, as encoded by tonic firing rates of dopamine neurons (Fiorillo, Tobler, & Schultz, 2003; Preuschoff, Bossaerts, & Quartz, 2006), and memory. It thus appears that other reward-related factors, such as reward outcome, determine memory processing above and beyond those mapping specific neural firing patterns.
Disclosure Statement
No potential conflict of interest was reported by the authors.
Funding
This work was supported by the United Kingdom Engineering and Physical Sciences Research Council [grant number EP/I032622/1].
Footnotes
Acknowledgements
The authors would like to thank Sarah Bunce for her help with data collection, and Nico Bunzeck and Peter Dayan for providing us with their original data.