
Abstract
This study investigated to what extent advance planning during sentence production is affected by a concurrent cognitive load. In two picture–word interference experiments in which participants produced subject–verb–object sentences while ignoring auditory distractor words, we assessed advance planning at a phonological (lexeme) and at an abstract–lexical (lemma) level under visuospatial or verbal working memory (WM) load. At the phonological level, subject and object nouns were found to be activated before speech onset with concurrent visuospatial WM load, but only subject nouns were found to be activated with concurrent verbal WM load, indicating a reduced planning scope as a function of type of WM load (Experiment 1). By contrast, at the abstract–lexical level, subject and object nouns were found to be activated regardless of type of concurrent load (Experiment 2). In both experiments, sentence planning had a more detrimental effect on concurrent verbal WM task performance than on concurrent visuospatial WM task performance. Overall, our results suggest that advance planning at the phonological level is more affected by a concurrently performed verbal WM task than advance planning at the abstract–lexical level. Also, they indicate an overlap of resources allocated to phonological planning in speech production and verbal WM.
Humans are very talkative. On average, we produce about 16,000 words every day—contrary to Western folklore, men and women alike (Mehl, Vazire, Ramírez-Esparza, Slatcher, & Pennebaker, 2007). In daily life, we often talk while doing other things at the same time, such as memorizing the way to our destination that we just looked up on a map, or a telephone number that we just saw in an advertisement. In this article we address the question of whether and in which way these additional cognitive tasks affect the way speakers plan their utterances. More specifically, we investigated (a) whether the scope of advance sentence planning at different processing levels is affected by a concurrently performed working memory (WM) task and, if so, (b) whether it is affected in a differential way, depending on the nature of that concurrent task (verbal vs. visuospatial). The answer to these questions will inform us about both the degree of flexibility in speech planning at different processing levels and the kinds of resources recruited at these processing levels.
Processing levels in speech production
According to the received view, speech production involves three major levels: (a) conceptualization, during which a speaker generates a preverbal message, which, amongst other things, specifies what she or he wants to talk about, (b) formulation, during which the preverbal message is mapped onto an appropriate linguistic form, and (c) articulation, which is concerned with the generation and execution of an articulatory motor programme (e.g., Levelt, 1989). Moreover, formulation is assumed to comprise two sub-processes: grammatical encoding and phonological encoding, respectively. During grammatical encoding, abstract–lexical representations (sometimes referred to as lexical nodes, e.g., Dell, 1986, sometimes as lemmas, e.g., Levelt, 1989; Levelt, Roelofs, & Meyer, 1999), corresponding to concepts specified in the preverbal message, are retrieved, and their syntactic properties are used for generating a syntactic structure. During phonological encoding, the associated word forms and phonological segments are retrieved and are used for generating the phonological representation of the intended utterance.
In the present study, we explored how far ahead speakers plan at the phonological and abstract–lexical level. Before we turn to the experiments, we review previous studies that looked at advance planning, both with and without a concurrent cognitive load.
Advance planning at the abstract–lexical and phonological level
How far ahead do speakers typically plan at the abstract–lexical and phonological level during speech production? First insights came from the analysis of naturally occurring speech errors. In a seminal study, Garrett (1980) showed that different types of speech errors follow different constraints. In particular, he observed that word exchange errors (e.g., “although murder is a form of suicide” instead of “although suicide is a form of murder”) often involve elements from the same syntactic category and tend to span across different syntactic phrases. In contrast, sound exchange errors (e.g., “the little burst of beaden” instead of “the little beast of burden”) are not constrained by syntactic factors and tend to involve nearby elements within a syntactic phase. From this pattern, Garrett inferred that these two types of errors occur at different processing levels. In particular, he argued that word exchange errors (constrained by syntactic factors) occur during grammatical encoding and sound exchange errors (constrained by sentence surface distance) during phonological encoding. Moreover, the distance of the interacting elements in the surface structure of the sentence led him to conclude that the typical advance planning scope is notably narrower at the phonological than at the abstract–lexical level.
Much of the experimental evidence regarding the respective planning scopes obtained thereafter stems from studies using variants of the picture–word interference (PWI) task. In these tasks, participants name pictures while ignoring auditory or visual distractor words, whose relation to the target word is varied. Effects from phonologically and semantically related distractors (relative to unrelated distractors) are taken as indices of phonological and abstract–lexical activation, respectively (e.g., Damian & Martin, 1999; Glaser & Düngelhoff, 1984; Jescheniak & Schriefers, 2001; Jescheniak, Schriefers, & Hantsch, 2003; La Heij, 1988; Levelt et al., 1999; Schriefers, Meyer, & Levelt, 1990; but see Finkbeiner & Caramazza, 2006, for a different view). Typically, with a single-word target utterance, a distractor word semantic-categorically related to the target (e.g., “priest”, when the target depicts a monk) interferes with the naming response compared to an unrelated condition, whereas a phonologically related distractor word (e.g., “moth”) facilitates the naming response, indexing abstract–lexical and phonological retrieval, respectively. When more complex utterances, such as coordinated noun phrases (e.g., “the monk and the book”) or simple sentences (e.g., “the monk is next to the book”), are produced, semantic interference effects are obtained not only for nouns in the utterance-initial phrase, but also for nouns occurring in the utterance-final phrase, suggesting that abstract–lexical advance planning spans over larger units (Meyer, 1996; Wagner, Jescheniak, & Schriefers, 2010; see also Smith & Wheeldon, 2004, for corresponding evidence obtained with a different paradigm).
With respect to phonological effects, the empirical evidence is somewhat less consistent. While phonological effects for nouns at the beginning of an utterance are consistently found, this is not always the case for elements in non-initial positions. For example, with coordinated noun phrases and simple sentences, Meyer (1996) observed facilitation from distractors phonologically related to the first noun, but found no such effect from distractors phonologically related to the second noun. Instead, there was a trend towards interference. However, a number of PWI studies did show the existence of phonological effects also for nouns occurring later in an utterance (e.g., Costa & Caramazza, 2002; Miozzo & Caramazza, 1999; for verbs, this has been shown by Schnur, 2011; Schnur, Costa, & Caramazza, 2006). Moreover, with auditory distractors (which were used in the present study), these effects were inhibitory in nature, as was the trend in the study by Meyer (Jescheniak et al., 2003; Oppermann, Jescheniak, & Schriefers, 2010). Together, these studies suggest that phonological advance planning is not necessarily restricted to the initial phrase.
In sum, by now there is substantial evidence that abstract–lexical as well as phonological encoding extends beyond the initial phrase and may even span over a whole simple sentence. In the present study we addressed the question of whether the scope of advance sentence planning at the abstract–lexical and the phonological level is structurally fixed or is adaptive to general processing demands imposed on the cognitive system during sentence planning. To do so, we explored whether advance planning both at the phonological and at the abstract–lexical level varies as a function of specific kinds of concurrent WM load (visuospatial vs. verbal). Before turning to our experiments, we briefly review existing studies that have investigated the influence of WM load on sentence production.
Advance planning under concurrent working memory load
Working memory can be defined as “consisting of flexibly deployable, limited cognitive resources, namely activation, that support both the execution of various symbolic computations and the maintenance of intermediate products generated by these computations” (Shah & Miyake, 1996, p. 4). It is widely accepted that WM can be partitioned into a verbal and a nonverbal (e.g., visuospatial) component (e.g., Baddeley, 1986; Logie, 1986; Shah & Miyake, 1996). The finding that in particular verbal WM performance predicts participants’ performance on language comprehension tests has led to the assumption that it is an essential element of language comprehension (Baddeley, 2003; Daneman & Carpenter, 1980; Daneman & Merikle, 1996; Shah & Miyake, 1996), and probably production as well (Acheson & MacDonald, 2009).
When two tasks that require capacity are concurrently performed, typically performance decrements are obtained in one or both tasks; this dual-task interference increases with task similarity (e.g., Allport, Antonis, & Reynolds, 1972; Jarrold, Tam, Baddeley, & Harvey, 2011; Navon & Miller, 1987, 2002; Park, Kim, & Chun, 2007; Paucke, Oppermann, Koch, & Jescheniak, 2015; Shah & Miyake, 1996; Wickens, 2008). In the case of the present study, the verbal WM task can be assumed to be more similar to the sentence production task compared to the visuospatial WM task. Therefore, a verbal load should have a greater effect on speech production, either in terms of naming latencies and/or error rates or in terms of the advance planning scope, or both.
To date, only a few studies investigated how WM load interacts with sentence planning. In a recent study by Boiteau, Malone, Peters, and Almor (2014), participants were engaged in a dialogue situation while concurrently tracking a moving target on a computer screen. The authors found that both comprehending and producing utterances interfered with the tracking task. From time course analyses the authors concluded that in particular planning and monitoring during speech production had the most detrimental effect on the tracking task, suggesting that these processes require attentional resources also used for the non-linguistic visuomotor task. This finding shows tight links between WM and speech planning, but does not provide any hints of how a concurrent WM load affects speech planning or, more specifically, advance planning at a particular representational level during speech production.
In another study, Slevc (2011) investigated in which way a concurrent WM load modulates effects of accessibility and given–new structuring (i.e., the tendency to place highly accessible/given information first in an utterance) in speech planning. The author observed that a concurrent verbal WM load reduced the accessibility effect. Moreover, given–new ordering was more strongly impaired by a verbal than a visuospatial WM load. This shows that WM load affects structure building during grammatical encoding and suggests that a verbal WM load is more detrimental than a visuospatial WM load. However, this study was mainly concerned with WM effects on structure building and does not directly speak to the question of advance planning at either the abstract–lexical or phonological level in terms of retrieval of lexical representations.
A PWI study by Wagner et al. (2010) investigated whether a concurrent verbal WM task (memorizing digits or adjectives) would affect advance planning at the abstract–lexical level. Participants described two-object displays (e.g., “the monk is next to the book”) while ignoring auditory distractor words either semantically related to the subject or object noun, or unrelated to both. The authors observed semantic interference in both cases, regardless of whether participants were engaged in a concurrent verbal WM task or not, suggesting that verbal WM load did not reduce the scope of advance planning at the abstract–lexical level. Still, WM load had an effect on speech production in that it led to longer naming latencies. Thus, this study gives some first evidence that the scope of advance planning at the abstract–lexical level might be relatively immune to influences from verbal WM.
In another recent study, Martin, Yan, and Schnur (2014) asked participants to describe multi-object displays while holding different types of information in WM. The visual input was varied such that sentences beginning with a complex noun phrase (e.g., “the drum and the package are below the squirrel”) could be contrasted with sentences beginning with a simple noun phrase (e.g., “the drum is above the package and the squirrel”). In the absence of a concurrent WM load, naming latencies were longer for the complex–simple structure than for the simple–complex structure, which was interpreted as a phrasal scope of lexical advance planning. Adding a visuospatial, phonological, or semantic WM task did not affect this pattern, suggesting that this phrasal scope is not subject to interference from a concurrent WM load.
In terms of the flexibility of the phonological advance planning scope, a study by Oppermann et al. (2010) provides some initial hints that the planning scope on this level might be adapted as a function of task demands. The authors found that the scope of phonological advance planning was affected when participants used different syntactic formats from trial to trial, depending on a lead-in fragment preceding the picture to be responded to. The lead-in fragment “Man sah wie …” [one saw how…] required participants to continue the sentence with an SOV (where S = subject, O = object, V = verb) utterance in order to yield a grammatically correct sentence in German (e.g., “[der Mönch]subj[das Buch]obj[las]verb” [the monk the book read]). In this case, both the subject and the object noun were found to be phonologically activated prior to speech onset. The lead-in fragment “Vorhin … ” [earlier…], by contrast, required participants to continue the sentence using a VSO structure (e.g., “[las]verb[der Mönch]subj[das Buch]obj” [read the monk the book]). In this case, only the subject noun was found to be phonologically activated prior to speech onset. Importantly, in the reference experiment, in which participants always produced SVO sentences (“Der Mönch las das Buch” [the monk read the book]) and in which the object noun also occurred in utterance-final position (as in the VSO format), the object noun was found to be phonologically activated prior to speech onset. A possible reason for the planning scope reduction for the VSO format is that in German the VSO format is relatively rare (Dryer, 2008). Thus, this format could have required more processing capacity, which, in turn, might have led to a smaller advance planning scope. Alternatively, it could also be that the need for generating syntactic frames anew on each trial (rather than reusing an established one) along with the non-dominant syntactic format might have led to a more demanding processing situation, which then has reduced the planning scope. Regardless of which account offered by the authors is correct, both assume that advance planning at the phonological level is reduced as task demands increase. This latter study was the starting point of the present study.
Overview of the experiments
We present two experiments that addressed the question of under which particular circumstances a reduction of the scope of advance planning occurs. Specifically, in Experiment 1, we looked at whether a non-verbal (i.e., visuospatial) load already suffices to detect flexibility in the phonological planning process or whether it takes a specific verbal load. In Experiment 2, we focused on planning processes at the abstract–lexical level. By systematically crossing different types of WM load and different processing levels in speech production—which has not been done in any of the previous studies—we aim to contribute to a deeper understanding of the relationship between WM and spoken language. The two experiments used the same paradigm, and they were constructed such that their results can be directly compared to each other.
The two experiments used a PWI paradigm in which participants produced SVO sentences while ignoring auditory distractor words. Naming latency differences between related and unrelated distractor conditions allowed us to assess whether subject and object nouns were activated at the phonological or abstract–lexical level, respectively, prior to speech onset. To examine effects of cognitive load, we additionally manipulated what kind of concurrent WM task speakers performed (visuospatial or verbal).
The sentence production task itself was adopted from an earlier study by Oppermann et al. (2010). Target sentences were descriptions of simple action scenes (e.g., “the monk read the book”). Initially, participants were familiarized with pictures showing the complete scenes, but in the main experiment they saw the agent of the scene (encoded as the sentence subject) only and produced the corresponding sentence in past tense. For the specific issue at hand here, this procedural detail is important, because it rules out that any observed activation of an abstract–lexical or phonological representation of the sentence object resulted from the mere visual processing of a picture (showing that object) rather than advance planning of that particular word (see, for example, Morsella & Miozzo, 2002; Oppermann, Jescheniak, & Schriefers, 2008). We return to this issue in the General Discussion.
Experiment 1 investigated the influence of a concurrent cognitive load on advance planning at the phonological level. To examine whether different load modalities affect phonological advance planning differently, two concurrent WM load conditions were tested between groups of participants (visuospatial vs. verbal, respectively). Experiment 2 was parallel to Experiment 1, except that the abstract–lexical planning scope was examined. We reasoned that if a particular (phonological or semantic) distractor effect would be obtained in one load condition but not the other, this would indicate that the scope of advance planning at the respective processing level had been narrowed down as a function of that specific (visuospatial or verbal) load.
Apart from the possible effects of WM load on the scope of advance planning, we expected a performance decline in the WM task when it was performed concurrently with the sentence production task compared to a single-task situation, and we expected this decline to be larger in the more similar dual-task situation (verbal WM with sentence production) than in the less similar dual-task situation (visuospatial WM with sentence production). Moreover, performance in the sentence production task should be worse in the more similar dual-task situation—that is, regardless of effects on the planning scope. Thus, we predicted longer naming latencies and/or more errors in the sentence production task under verbal WM load than under the visuospatial WM load.
Experiment 1: Phonological advance planning under visuospatial and verbal working memory load
Experiment 1 tested whether a concurrent visuospatial or verbal WM load influences the scope of advance planning at the phonological level. Previous research using a very similar sentence production task has shown that in the absence of a concurrent load, both the initial and the final noun of a simple SVO sentence were activated on the phonological level prior to speech onset (Oppermann et al., 2010, Experiment 1). We tested whether a domain-general load (i.e., a concurrent visuospatial WM task) and/or a domain-specific load (i.e., a concurrent verbal WM task) reduce the phonological planning scope when participants produce simple SVO sentences (e.g., “the monk read the book”). If neither of these tasks affects the phonological advance planning scope, and both nouns are phonologically activated prior to speech onset, we should observe facilitation effects from subject-related distractors and interference effects from object-related distractors. By contrast, if one—or both—WM load conditions reduce the planning scope, no object-related distractor effect should be found in the presence of that specific load.
Method
Participants
We tested 80 native speakers of German (65 female; mean age = 23.3 years, SD = 3.8, range: 18–44). In the experiments reported below, participants were paid €8 (approximately US $8.50) or received course credit. None of them had any known hearing deficit, and they had normal or corrected-to-normal vision. Participants with fewer than 8 out of possible 20 valid data points in any experimental condition were replaced (one participant in Experiment 1); this criterion was also applied in Experiment 2. Each participant took part in only one of the experiments reported here.
WM capacity scores of the participant groups tested under the different load conditions in Experiments 1 and 2.

Note: WM = working memory; WMS = Wechsler Memory Scale.
Materials
For the sentence production task, we used 20 line drawings of subject–verb–object scenes, which could be described with a simple SVO sentence (e.g., “Der Mönch liest das Buch” [the monk reads the book]). The materials were partly overlapping with those used in Oppermann et al. (2010). Each picture was sized to fill an imaginary square of about 15 × 15 cm. The complete picture was presented during familiarization with the materials. During the test phase, however, only the agent was displayed (see above, for the reasons to choose this procedure). For each subject and object noun, a phonotactically legal pseudo-word was created, which shared the initial consonant or consonant cluster and the adjacent vowel with the noun it was related to, and had the same number of syllables and syllabic structure (e.g., “mölk” for Mönch [monk] and “buf” for Buch [book]). Unrelated control conditions were created by reassigning the distractors to different subjects (for the subject-related distractors) or objects (for the object-related distractors), respectively; see Appendix A for a complete list of the materials. The auditory distractors were spoken by a female native speaker of German and varied in duration from 529 ms to 968 ms with an average of 731 ms (SD = 122 ms). They were digitized at a sampling rate of 48 kHz for presentation during the experiment. An additional set of five scenes with corresponding distractors was created for use in practice and warm-up trials.
As a visuospatial WM task we used a dot-in-matrix task (Ichikawa, 1981, 1983) and as a verbal WM task a digit string task (e.g., Slevc, 2011; Wagner et al., 2010). A pre-test (N = 12) showed that the two tasks (in a single-task situation) were of comparable difficulty with four dots and five digits (5.3% and 5.4% errors for the visuospatial and the verbal task, respectively, p > .474). The materials for the visuospatial WM task consisted of a 5 × 5 matrix about 15 × 15 cm in size, with four dots presented at random positions within the matrix. The only constraint was that not more than one dot would appear within the same row or column. We generated 80 different patterns. For half of these materials, incorrect probes were created by moving one dot by one field. For the other half, correct probes were used. The materials for the verbal WM task consisted of 80 random five-digit strings. For half of these materials, incorrect probes were created either by replacing a single digit or by switching the position of two digits. For the other half, correct probes were used. For each WM task, five additional practice items were created.
Design
The experimental design included the completely crossed variables load (visuospatial vs. verbal), noun phrase (subject vs. object), relatedness (phonologically related vs. unrelated), and stimulus onset asynchrony (SOA; 150 ms vs. 300 ms). All variables, with the exception of load, were tested within participants and within items; load was tested within items but between participants. Each of the 20 items was presented in each of the resulting eight conditions once, yielding a total of 160 experimental trials per participant. SOA was blocked, and the sequence of SOA blocks was counterbalanced across participants. The sequence of distractor conditions per item within SOA blocks was counterbalanced using a sequentially balanced Latin square procedure. For the experimental blocks, trials were pseudo-randomized according to the following criteria: (a) Repetitions of a picture were separated by at least eight intervening trials, (b) repetitions of a particular distractor word were separated by at least three intervening trials, (c) no more than three trials with the same distractor condition were presented in direct succession, and (d) no more than three trials with subject nouns from the same gender class were presented in direct succession (to avoid that too many subsequent utterances would start with the same determiner).
Apparatus
The visual stimuli were presented on a 19-inch EIZO S1910 computer screen as black line drawings on a light grey background (RGB 244 244 244). Viewing distance was about 60 cm. The presentation of the visual and auditory stimuli and the online collection of the data were controlled by the NESU program (1998, Max Planck Institute for Psycholinguistics, Nijmegen). Auditory distractors were presented with Sennheiser HD 280 headphones at a comfortable volume. Speech onset latencies were measured to the closest millisecond with a Sennheiser ME 64 microphone via a voice-key connected to the computer. Speech errors, dysfluencies, and technical errors were coded online by the experimenter. Responses to the WM task were recorded with a button box connected to the computer.
Procedure
Each participant was tested individually. The participant was seated in a dimly lit room and was separated from the experimenter by a partition wall during the experimental task. First, participants completed the WMS–R subtests Digit Span Backwards and Block Span Backwards (Härting et al., 2000) presented by the experimenter. Then, participants were instructed that their task would be to describe pictures of simple (agent–action–patient) scenes as fast and as accurately as possible. They were familiarized with the pictures and the corresponding present tense SVO sentences (e.g., “Der Mönch liest das Buch” [the monk reads the book]) in a printed booklet. Participants were instructed to only use these sentences in the experiment. In a next step, the agents of the scenes (to be encoded as sentence subjects) were presented individually on the computer screen one after the other, and participants were asked to describe as fast and as accurately as possible what this entity had done in the picture that they had seen earlier by producing the respective past tense SVO sentence (e.g., “Der Mönch las das Buch” [the monk read the book]). If participants responded other than expected, they were corrected by the experimenter right away. Practice was continued without immediate feedback until participants had produced each target sentence eight times. We decided to use this rather long practice phase because we wanted to ensure that participants could later produce the target sentences fluently and without excessive errors, even in a situation where only the agent was displayed, the corresponding sentence was retrieved from episodic memory, and a concurrent WM task was added.
Next, the auditory distractors were introduced in a practice block consisting of 15 trials with practice items. Then the respective WM task (visuospatial or verbal, depending on load condition) was introduced as a single task in another practice block consisting of 15 trials. Participants were instructed to memorize the visually presented stimulus, the memory set (position of the four dots or the order of five digits), and then to press the left button if a subsequently presented stimulus, the probe, was identical, or the right button if it was different. This practice phase was followed by an experimental block consisting of 80 trials, which served for assessing the participant's WM performance in a single-task situation. One such trial was structured as follows. First, a fixation cross appeared at the centre of the computer screen for 800 ms. Then, the memory set was presented for 750 ms. Following a blank screen for 1500 ms, the memory probe, marked by a question mark below it, appeared for 2000 ms, and the participant's responses were recorded until probe offset. At 700 ms after the probe had disappeared, the next trial was initiated.
Finally, the dual task was introduced. Participants were told that now the memory task just practised and the picture description task practised earlier would be combined. They were instructed to first memorize the positions of the dot pattern or the digit string, respectively, then to describe the upcoming picture while ignoring the auditory distractor words, and finally to compare the memory probe with the previously presented stimulus by giving a push-button response. Participants were instructed to produce the sentences as quickly and as accurately as possible and to perform the memory task as accurately as possible.
One such experimental trial was structured as follows. First, a fixation cross appeared at the centre of the computer screen for 800 ms. Then, the memory set (dot-in-matrix pattern or digit string) was presented for 750 ms; this time period was chosen because it is too short to verbally encode the kind of visuospatial stimulus we used (Shah & Miyake, 1996). Following a blank screen for 150 ms, the picture of an agent was displayed for 1000 ms. Auditory distractors started at an SOA of either 150 ms or 300 ms, depending on the SOA block. Participants had 3000 ms to produce the target sentence. After this interval, the memory probe appeared for 2000 ms, and participants responded by giving a push-button response. After another 700 ms, the next trial started. Each experimental session lasted approximately 75 minutes.
Analyses
Observations from the sentence production task were discarded from the naming latency analyses whenever (a) a picture had been responded to other than expected; (b) a speech-unrelated sound preceded the target utterance, triggering the voice-key; (c) a dysfluency occurred or an utterance was corrected; (d) a speech onset latency exceeded 3000 ms or there was a perceptible pause within the utterance; or (e) the voice-key was not triggered due to technical errors. All of these cases, with the exception of (d) and (e), were included in the error analyses. Observations deviating from a participant's and an item's mean by more than two standard deviations (computed separately by primed element, relatedness, and SOA) were considered as outliers and were also discarded from the naming latency analyses without coding an error.
Statistical analyses were computed separately by noun phrase (subject vs. object) with mixed-effects models using the lme4 package (Version 1.1.6, Bates, Maechler, Bolker, & Walker, 2015) in R (Version 3.2.2; R Core Team, 2015). The factors load (visuospatial vs. verbal), relatedness (phonologically related vs. unrelated), and SOA (150 ms vs. 300 ms) were sum-coded and included as fixed effects in the models. Participants and items were included as random effects (Baayen, Davidson, & Bates, 2008). We always started the analyses with a maximal random-effects structure—that is, models including random intercepts and random slopes (for all fixed effects and their interactions) for both participants and items (Barr, Levy, Scheepers, & Tily, 2013). Only if the model with the maximal random-effects structure did not converge did we simplify it by the stepwise removal of the higher order terms (first the three-way interaction of load, relatedness, and SOA and then, if needed, individual two-way interactions or main effects).
Naming latencies were log-transformed to normalize their distribution. Visual inspection of residual plots did not reveal substantial deviations from homoscedasticity or normality of the transformed data. For the analyses of naming latencies, we interpreted fixed effects as significant if their absolute t value exceeded the value of 2 (Baayen, 2008; Baayen et al., 2008). Error rates were analysed using mixed logit regression (Jaeger, 2008). For the analyses of error rates, Wald's-z scores and associated p values are reported. We report only significant predictors or interactions thereof. For this and the next experiment, a complete documentation of all predictors and their interactions as well as the final random-effects structures of the models can be found in the Supplemental Material.
For the analyses of performance in the respective WM tasks, error rates were analysed using mixed logit regression, including the between-participants factor load modality (visuospatial vs. verbal) and the within-participant factor task situation (single vs. dual task) in the analysis.
Results and discussion
For this as well as the following experiment, we report performance data from the WM tasks (% errors) and performance data from the sentence production task (mean naming latencies and % errors), in that order.
WM performance
Error rates were higher in the dual-task situation than in the single-task situation; for the main effect of task situation, β = 0.635, SE = 0.033, z = 18.95, p < .001; and higher in the verbal task than in the visuospatial task; for the main effect of load modality, β = −0.162, SE = 0.054, z = −3.00, p < .01. However, load modality and task situation interacted, β = −0.118, SE = 0.032, z = −3.66, p < .001. The increase of error rates from single- to dual-task situation was more pronounced for the verbal task (from 8.4% to 27.5%) than for the visuospatial task (from 7.7% to 18.3%), even though the increase of error rates was significant in both tasks; for the visuospatial task, β = 0.506, SE = 0.047, z = 10.80, p < .001; for the verbal task, β = −0.761, SE = 0.048, z = 15.89, p < .001. Notably, single-task performance was comparable across modalities (p > .630).
Sentence production performance
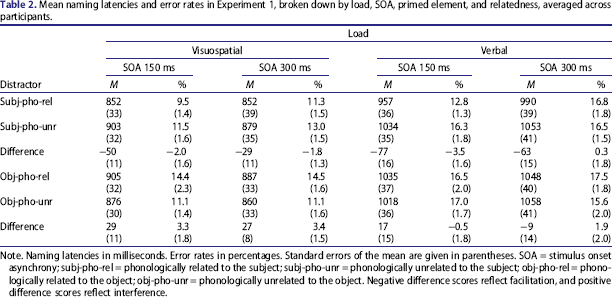
A total of 14.1% of the observations (3.0%, 6.6%, 4.5%, 1.1%, and 2.3% for Cases a–e described in the Method section, respectively) were identified as erroneous and 0.9% as outliers. These data points were removed from the analyses. Table 2 displays mean naming latencies and error rates broken down by load, primed element, SOA, and relatedness, and Figure 1 shows the distractor effects.
Distractor effects on naming latencies and error rates, averaged across participants and broken down by load (visuospatial vs. verbal), primed element (subject vs. object), relatedness (phonologically related, rel, vs. unrelated, unr), and stimulus onset asynchrony (SOA; 150 ms vs. 300 ms) from Experiment 1. Error bars indicate standard errors across participants. Mean naming latencies and error rates in Experiment 1, broken down by load, SOA, primed element, and relatedness, averaged across participants. Note. Naming latencies in milliseconds. Error rates in percentages. Standard errors of the mean are given in parentheses. SOA = stimulus onset asynchrony; subj-pho-rel = phonologically related to the subject; subj-pho-unr = phonologically unrelated to the subject; obj-pho-rel = phonologically related to the object; obj-pho-unr = phonologically unrelated to the object. Negative difference scores reflect facilitation, and positive difference scores reflect interference.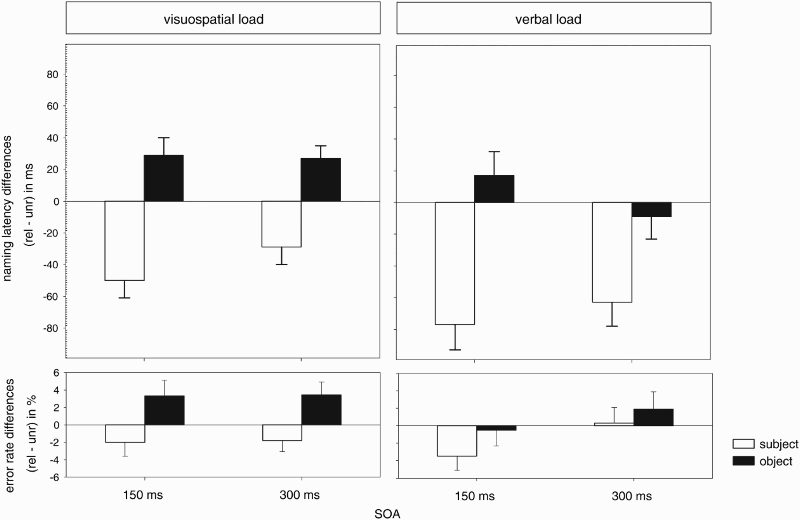
Effects from subject-related distractors
In the analysis of naming latencies, there was a main effect of load, indicating longer naming latencies under a concurrent verbal WM load than under a concurrent visuospatial WM load, β = −0.071, SE = 0.024, t = −2.91. Naming latencies were shorter with subject-related distractors than with unrelated distractors; for the main effect of relatedness, β = −0.030, SE = 0.005, t = −5.58. This effect did not differ across load conditions; for the interaction of load and relatedness, t = 1.55. The facilitation effect differed in size across SOA; for the interaction of relatedness and SOA, β = −0.007, SE = 0.003, t = −2.25. However, it was reliable at both SOAs (SOA 150 ms, t = −5.51; SOA 300 ms, t = −4.51).
Error rates were higher under verbal WM load than under visuospatial load; for the main effect of WM load, β = −0.207, SE = 0.079, z = −2.61, p < .01. There was a trend towards lower error rates with subject-related distractors than with unrelated distractors; for the effect of relatedness, β = −0.085, SE = 0.046, z = −1.86, p = .063. Error rates were higher at SOA 150 ms; for the main effect of SOA, β = −0.085, SE = 0.038, z = −2.25, p < .05. None of the interactions reached significance (all ps > .2110.
Effects from object-related distractors
Naming latencies were longer under verbal WM load than under visuospatial load; for the main effect of load, β = −0.078, SE = 0.024, t = −3.21. Object-related distractors interfered with the naming response compared to unrelated distractors; for the main effect of relatedness, β = 0.008, SE = 0.004, t = 2.08. Crucially, there was an interaction of relatedness and load, β = 0.006, SE = 0.003, t = 2.01. Splitting the analysis by load condition (i.e., visuospatial vs. verbal) revealed that the relatedness effect was significant under visuospatial WM load, β = 0.014, SE = 0.004, t = 3.05, but not under verbal WM load, β = 0.002, SE = 0.005, t = 0.47.
Error rates were higher under verbal WM load; for the main effect of load, β = −0.186, SE = 0.008, z = −2.25, p < .05. There was a trend towards higher error rates with object-related than with unrelated distractors; for the effect of relatedness, β = 0.009, SE = −0.005, z = 1.86, p = .063. There was a trend towards an interaction of load and relatedness, β = 0.007, SE = 0.004, z = 1.92, p = .055. Splitting the analyses by load revealed that relatedness was significant for the visuospatial load condition, β = 0.156, SE = 0.073, z = 2.13, p < .05, but not for the verbal load condition, β = 0.028, SE = 0.058, z = 0.48, p = .631, coinciding with the pattern observed for naming latencies. None of the other effects reached significance (all ps > .453).
To summarize, there were clear effects of the sentence production task on WM task performance and vice versa. The concurrent sentence production task had a detrimental effect on WM task performance (when compared to single-task WM performance), and the performance decrement was larger for the verbal WM task than for the visuospatial WM task. The same was true in the other direction. The verbal WM task led to slower naming latencies and more naming errors than the visuospatial WM task. Thus, in line with our predictions, the more similar dual-task situation resulted in a stronger performance decline in both tasks than the less similar dual-task situation.
The central finding from Experiment 1 is, however, that there was interference from object-related distractors with visuospatial WM load but not with verbal WM load, suggesting that the concurrently performed verbal WM task effectively reduced the scope of advance planning at the phonological level. Notably, the polarity of this effect is different from the one observed with subject-related distractors. Such a polarity shift of phonological distractor effects as a function of the serial position of the primed element (facilitation for elements occurring early in an utterance and interference for elements occurring late in an utterance) has been reported earlier (Jescheniak et al., 2003; Oppermann et al., 2010) and can be accounted for by a simple model of phonological encoding (Jescheniak et al., 2003; see also Dell, 1986; Meyer, 1996). The model assumes that before articulation is initiated, there is a graded pattern of activation for the phonological forms of the successive words in the planned utterance. The subsequent words differ with respect to their activation level, decreasing from left to right, such that activation strength codes the linear position of an element in the utterance. Elements outside the scope of phonological advance planning have an activation of zero. Further, the model assumes that any distortion of this graded activation pattern—and thus of the linear position coding—leads to problems during phonological encoding, because the original sequence of elements needs to be re-established. Relative to an unrelated control condition, phonologically related distractors that enhance the activation of non-initial elements might effectively distort the graded activation pattern such that the primed element moves to a wrong (i.e., too early) position. Re-establishing the correct serial order of the elements takes time, thus slowing down responses. By contrast, phonologically related distractors that enhance the activation of an utterance-initial element do not distort the graded activation pattern. On the contrary, such distractors should be beneficial as they effectively facilitate the processing of an initial element, which should speed up responses.
Before the conclusion that the concurrently performed verbal WM task effectively reduced the scope of advance planning at the phonological level may be accepted, however, two caveats need to be addressed. First, given that naming latencies under verbal load were about 160 ms longer than under visuospatial load, one might object that the SOAs we used were too short to detect any object-related effect under verbal load. We addressed this concern in a control experiment (N = 40), which was identical to the verbal load condition of Experiment 1, with the only difference that SOAs 150 ms and 300 ms were replaced with SOAs 300 ms and 450 ms to account for the between-load latency shift. In this control experiment, we obtained comparable results to those in Experiment 1: Participants performed comparably in terms of naming latencies and error rates (1343 ms and 13.5%, respectively; unrelated conditions only). In the analysis of naming latencies, we again observed phonological facilitation for subject-related distractors, β = −0.021, SE = 0.005, t = −4.25, but no effect from object-related distractors, β = −0.007, SE = 0.005, t = 1.52. Again, this pattern did not differ across SOAs; for interactions with SOA (all |t|s < 0.53). In the analysis of error rates, there were no significant effects (all ps > .112). This control experiment, thus, lends additional support to the notion that the scope of phonological advance planning was effectively narrowed down in the presence of a concurrent verbal WM task.
Second, it is possible that the concurrent verbal WM task did not reduce specifically the phonological advance planning scope, but led to a more general reduction of advance planning, including the preceding abstract–lexical processing level as well. Although the results of Wagner et al. (2010) do not speak in favour of this possibility (because in that study a concurrent verbal WM task did not reduce the scope of abstract–lexical advance planning), one needs to recognize that the procedure used by Wagner et al. differs in important details from the one used here. Wagner et al. only varied verbal load, which does not allow an evaluation of effects of different kinds of load (verbal vs. visuospatial) directly. More important, Wagner et al. presented the critical elements (agent [subject] and patient [object]) of the sentence as pictures on the screen whereas we presented the agent [subject] only while the patient [object] had to be retrieved from memory. As described in the introduction, the visual presentation of the patient [object] could have enhanced the activation of its lexical representations (e.g., Morsella & Miozzo, 2002; Oppermann et al., 2008). Thus, we have to ask whether the scope of abstract–lexical planning is affected as well by the load manipulation using the same task and load conditions as in Experiment 1. This was investigated in Experiment 2.
Experiment 2: Abstract–Lexical advance planning under visuospatial or verbal load
Experiment 2 tested whether a concurrent visuospatial or verbal WM load influences the scope of advance planning at the abstract–lexical level. It was identical to Experiment 1, with the following exceptions. First, the phonologically (un)related pseudo-word distractors were replaced by semantically (un)-related word distractors. Second, the item set was adapted because for some subject or object nouns no suitable semantically related distractors were available. Third, SOAs 150 ms and 300 ms were replaced by SOAs 0 ms and 150 ms because semantic distractor effects often precede phonological distractor effects (Damian & Martin, 1999; Meyer, 1996; Schriefers et al., 1990). If the disappearance of the object-related distractor effect under verbal WM load as observed in Experiment 1 reflects a specific reduction of the scope of advance phonological planning, then an object-related distractor effect (i.e., interference) should still be present under verbal WM load in Experiment 2. If, by contrast, it reflects a more general reduction of advance planning, the effect should be absent under verbal WM load in Experiment 2 as well.
Method
Participants
We tested 80 native speakers of German (67 female, mean age = 24.2 years, SD = 3.5, range: 18–32). Again, half of them were tested in the visuospatial WM condition, and half of them in the verbal WM condition. Assignment to the WM condition was alternated during testing. Participants performing the concurrent visuospatial WM task did not differ from participants performing the concurrent verbal WM task in their performance on the backward block span task, F(1, 78) = 1.88, p = .175, or the backward digit span task, F(1, 78) = 2.98, p = .089 (for specific scores, see Table 1).
Materials, design, apparatus, procedure, and analyses
These were the same as those in Experiment 1, with the following differences: In the sentence production task, a semantically related real-word distractor was selected for each subject and object noun (e.g., “Priester” [priest] for Mönch [monk] and “Zeitung” [newspaper] for Buch [book]). Eight target sentences used in Experiment 1 were replaced because no suitable semantically related distractor words were available. Unrelated control conditions were again created by reassigning the distractors to different subjects (for the subject-related distractors) or objects (for the object-related distractors); see Appendix B for a full list of the materials. To avoid any contamination of the expected distractor effects due to grammatical gender congruency (e.g., Schriefers, 1993), we made sure—on the level of individual items—that for each critical subject or object noun the contrast between related and unrelated distractors involved two words either gender-congruent or gender-incongruent to that critical noun. The auditory distractors varied in duration from 463 ms to 979 ms with an average of 681 ms (SD = 123 ms).
The experimental design included the completely crossed variables load (visuospatial vs. verbal), primed element (subject vs. object), relatedness (semantically related vs. unrelated), and SOA (0 ms vs. 150 ms). All variables, except for the between-participant factor load, were tested within participants and within items.
Results and discussion
WM performance
Again, error rates were higher in the dual-task situation than in the single-task situation; for the main effect of task situation, β = 0.582, SE = 0.032, z = 18.08, p < .001; and higher in the verbal task than in the visuospatial task; for the main effect of load modality, β = −0.197, SE = 0.052, z = −3.76, p < .001. Load modality and task situation interacted, β = −0.072, SE = 0.031, z = −2.30, p = .021, reflecting the fact that the increase of error rates from the single- to the dual-task situation was higher for the verbal task (from 11.4% to 31.0%) than for the visuospatial task (from 9.2% to 21.3%), even though the increase of error rates was significant in both tasks; for the visuospatial task, β = 0.495, SE = 0.037, z = 13.48, p < .001; for the verbal task, β = 0.665, SE = 0.052, z = 12.90, p < .001. As in Experiment 1, single-task performance was comparable across load modalities (p = .092).
Sentence production performance
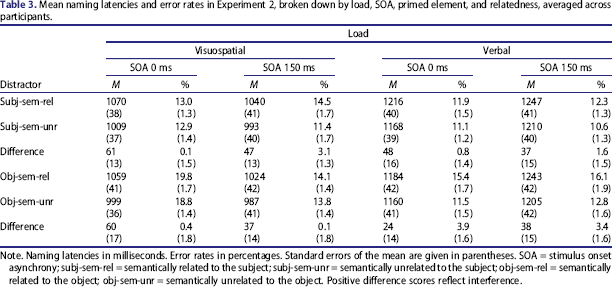
The raw data were treated as in Experiment 1, leading to the removal of 12.9% erroneous responses (2.2%, 5.6%, 5.1%, 2.3%, and 2.2% for Cases a–e described in the Method section of Experiment 1, respectively) and 1.1% outliers. Table 3 displays mean naming latencies and error rates broken down by load condition, primed element, SOA, and relatedness, and Figure 2 shows the distractor effects.
Distractor effects on naming latencies and error rates, averaged across participants and broken down by load (visuospatial vs. verbal), primed element (subject vs. object), relatedness (semantically related, rel, vs. unrelated, unr), and stimulus onset asynchrony (SOA; 0 ms vs. 150 ms) from Experiment 2. Error bars indicate standard errors across participants. Mean naming latencies and error rates in Experiment 2, broken down by load, SOA, primed element, and relatedness, averaged across participants. Note. Naming latencies in milliseconds. Error rates in percentages. Standard errors of the mean are given in parentheses. SOA = stimulus onset asynchrony; subj-sem-rel = semantically related to the subject; subj-sem-unr = semantically unrelated to the subject; obj-sem-rel = semantically related to the object; obj-sem-unr = semantically unrelated to the object. Positive difference scores reflect interference.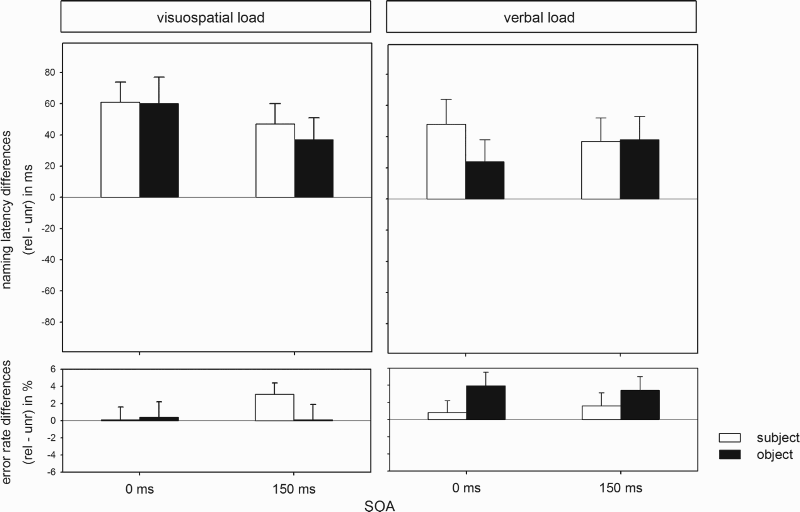
Effects from subject-related distractors
Naming latencies were higher under verbal WM load than under visuospatial WM load; for the main effect of load, β = −0.083, SE = 0.024, t = −3.48. Related distractors slowed down naming latencies compared to unrelated distractors; for the main effect of relatedness, β = 0.022, SE = 0.008, t = 2.76. This effect did not differ across load conditions; for the interaction of load and relatedness, t = 0.85. Load and SOA interacted, β = 0.015, SE = 0.005, t = 2.88. Splitting the analyses by SOA revealed that the effect of load (i.e., slower naming latencies under verbal than under visuospatial load) was present at both SOAs but smaller at SOA 0 ms, β = −0.068, SE = 0.024, t = −2.87, than at SOA 150 ms, β = −0.099, SE = 0.025, t = −3.95. None of the other effects were significant (all |t|s < 0.95), and there were no significant effects in the analysis of error rates (all ps > .176).
Effects from object-related distractors
Naming latencies were longer under verbal WM load than under visuospatial WM load; for the main effect of load, β = −0.084, SE = 0.024, t = −3.41. Again, load and SOA interacted, β = 0.016, SE = 0.005, t = 2.99. The effect of load (i.e., slower naming latencies under verbal than under visuospatial load) was smaller at SOA 0 ms, β = −0.068, SE = 0.025, t = −2.75, than at SOA 150 ms, β = −0.099, SE = 0.025, t = −3.90.
Load and relatedness did not interact (t = 1.27), which suggests that the amount to which object-related distractors interfered with the naming response did not differ across load modalities. However, surprisingly, relatedness as a main effect was not significant either, β = 0.016, SE = 0.009, t = 1.74.
In the analysis of error rates, there was an interaction of load and relatedness, β = −0.076, SE = 0.037, z = −2.04, p = .041. Splitting the analysis by load modality, the effect of relatedness was not significant for visuospatial load (p = .985), but for verbal load, β = 0.196, SE = 0.089, z = 2.21, p = .027. More errors were made with object-related than with unrelated distractors under verbal load. None of the other effects were significant (all ps > .121).
As in Experiment 1, there were clear effects of the sentence production task on WM task performance and vice versa. The sentence production task had a detrimental effect on WM task performance (when compared to single-task WM performance), and the performance decrement was larger for the verbal WM task than for the visuospatial WM task. The same was true in the other direction: The verbal WM task led to slower naming latencies than the visuospatial WM task. Thus, in line with our predictions, the more similar dual-task situation again resulted in a stronger performance decline in both tasks than the less similar dual-task situation.
In terms of the distractor effects, we observed no interaction of load and relatedness. Surprisingly, the interference effect from distractors semantically related to the object was not significant either, which is unexpected for the following reasons. First, a corresponding semantic interference effect for nouns in utterance-initial as well as utterance-final phrases was obtained in a closely related study by Wagner et al. (2010, Experiments 3a and 3b) under conditions of verbal load. Second, the demonstration of a phonological effect in Experiment 1 of the present study (under visuospatial load) logically implies that—in principle—semantic effects should be observable as well, at least under visuospatial load (given that all models of lexical retrieval assume semantic access to precede phonological access).
In light of these considerations, we further explored the effect from semantically object-related distractors under visuospatial and verbal load by taking the following actions. First, we calculated DFBeta values on the item level using the R package influence. ME (Nieuwenhuis, te Grotenhuis, & Pelzer, 2012). DFBetas are an objective measure for determining cases that have an unusually high impact on the parameter estimates. Using a cut-off value of 2/
Finally, we also analysed effects from subject-related and object-related distractors jointly, without excluding any items. In this analysis, too, the main effect of distractor relatedness was significant, β = 0.019, SE = 0.005, t = 3.66, while none of the interactions including the factors load, noun phrase and relatedness were (all |t|s < 1.31).
In all, these additional analyses clearly show an interference effect from distractors semantically related to the object when measures to eliminate conspicuous items or measures to enhance the statistical power are taken. Most importantly, there was no interaction of load modality and this relatedness effect in any of these analyses.
Overall, our findings thus suggest that regardless of type of WM load, both subject and object nouns were activated at the abstract–lexical level prior to speech onset. This is in clear contrast to what we observed in Experiment 1. In that experiment, object-related (phonological) distractor effects were only observed with visuospatial WM load. Together, this means that what we observed in Experiment 1 (absence of an object-related distractor effect with verbal WM load) reflects a specific reduction of the scope of advance phonological planning and not a more general reduction of advance planning.
General Discussion
In two sentence production experiments, we investigated the influence of different types of cognitive load on phonological (Experiment 1) and abstract–lexical advance planning (Experiment 2). In Experiment 1, participants produced SVO sentences while ignoring auditory distractors phonologically related or unrelated to the subject or object noun. Additionally, they performed either a concurrent visuospatial or verbal WM task. Under visuospatial load, we observed a subject-related facilitation effect and an object-related interference effect, indicating that at the phonological level, the entire sentence was planned prior to speech onset. By contrast, under a concurrent verbal load, the object-related interference effect was absent, indicating that the verbal load had effectively reduced the phonological planning scope. Experiment 2 investigated the influence of a concurrent visuospatial and verbal WM task during abstract–lexical advance planning using auditory distractors semantically related or unrelated to the subject or object noun. This time, subject- and object-related interference effects were obtained regardless of the kind of load, indicating that the abstract–lexical planning scope was not reduced by either load.
In sum, then, while the abstract–lexical planning scope up to the utterance-final noun also held under verbal load, this was not the case for the phonological planning scope. This suggests that in planning an utterance, the production system can maintain an abstract–lexical advance planning scope beyond the initial noun phrase despite a highly demanding concurrent task—regardless of whether it contains visuospatial or verbal information—whereas the phonological advance planning scope is adapted in response to the current specific task demands. This supports the assumption that verbal WM and phonological planning require the same processing resources.
What could be the cause of this interaction? Verbal WM tasks like the one used in the current study (i.e., with verbal, but semantically relatively void stimuli) are mostly attributed to phonological processing—that is, maintaining and rehearsing phonological codes and their serial order (e.g., Baddeley, 1986, 2003, 2012; Baddeley & Logie, 1999). Similarly, phonological advance planning in the sentence production task includes establishing and maintaining a serial order of phonological codes (e.g., Dell, 1986; Jescheniak et al., 2003). Thus, both tasks draw on processes operating at the same—phonological—level of representation, and processing demands on that level should increase when the two tasks are performed concurrently. Evidence supporting the view comes from the observation that performance in the verbal WM task was impeded more by the concurrent sentence production task than was performance in the visuospatial WM task.
We assume that the reduced phonological advance planning scope under verbal load reflects an adaption of the language production system to the increased processing demand on the phonological level. This follows quite naturally from the view that the serial order of multiple word forms within the planning scope is established by a graded activation pattern (e.g., Dell, 1986; Jescheniak et al., 2003). Under the assumption that there is some upper limit to the activation of the first element, it follows that the activation gradient (i.e., the difference in activation between adjacent elements) would become less pronounced the larger the advance planning scope is. This would in turn make the ordering of elements more susceptible to error. A reduction of the phonological advance planning scope under verbal load might therefore reflect a need to compensate for the increased processing demand introduced by the verbal WM task.
From a methodological point of view, one might object that (a) the task we used is fairly different from normal production because it requires the retrieval of information from long-term (episodic) memory (in this case the memory trace of visual scenes or corresponding sentences or both), and that (b) exactly this component might be responsible for the pattern of results we obtained. However, one should keep in mind that speaking always requires long-term memory retrieval (i.e., retrieval of lexical information from that part of memory we call the mental lexicon). This is also true when using more conventional multi-object displays in sentence production experiments. In this case, names of depicted objects, actions, or spatial relations need to be retrieved from long-term memory. However, for the issue at hand here, this procedure is disadvantageous, because of evidence suggesting that elements in a complex visual display may activate their phonological code independent of the intention to name them (Morsella & Miozzo, 2002). This is in particular true when the objects are in some way related (Oppermann et al., 2013; Oppermann et al., 2008, 2010) or particularly easy to process (Mädebach, Jescheniak, Oppermann, & Schriefers, 2011). Long-term memory retrieval is evidently also involved in spontaneous speech in the absence of pictorial input. In this case, words need to be retrieved from long-term memory based on conceptual information that is part of the speaker's preverbal message. Hence, rather than asking whether memory retrieval as such was responsible for the pattern of results we observed, one needs to ask whether our task involved some specific kind of memory retrieval not present when sentence production is triggered by multi-object displays or the preverbal message.
One such difference is that in our task, participants—following familiarization and training—could have retrieved the target sentences as complete chunks, without any need to assemble them from individual words. However, this possibility was addressed in a control experiment (N = 32) and dismissed. In this experiment, participants went through the same familiarization and training procedure as that in the main experiments (i.e., they learned to describe the whole scene), but were then instructed to name only the inflected verb (e.g., “las” [read]) in the experimental trials. A chunking account would predict that in this situation, in which neither the subject nor the object needs to be lexically encoded in order to prepare the utterance, the interference effect from object-related distractors should still persist. Contrary to this prediction, there was no trace of such an effect. Participants were faster and made fewer errors (mean naming latencies: 873 ms; mean error rates: 6.4%; unrelated conditions only) than in the sentence production experiment, but there was neither an effect of object-relatedness (t = −0.18), nor an interaction of SOA and relatedness (t = −1.51). 2 To further strengthen this argument, we conducted a cross-experimental analysis between this control study and Experiment 2, including the predictor utterance format (SVO vs. bare verb) as a fixed effect. This analysis yielded a significant interaction of utterance format and object-relatedness, β = 0.008, SE = 0.004, t = 2.02. Thus, when the object was not part of the planned target utterance, it was not activated at the abstract–lexical level anymore, as opposed to a situation requesting the production of the object. In conclusion, our task does entail a memory component, as does speaking in other contexts as well. However, there is no evidence that our task introduced a specific kind of memory retrieval not present in other contexts that should be considered the genuine source of our effects.
Phonological advance planning and WM load
The finding that the phonological advance planning scope is reduced by a verbal, but not a visuospatial, load extends existing research on the flexibility of phonological advance planning. The study by Oppermann et al. (2010) provided first support for a flexible phonological planning scope by showing a reduced planning scope when a rare and varying utterance format was used. While this was interpreted to reflect an adaptation to immediate task demands, the current experiments demonstrate that this adaptation occurs particularly in situations in which those task demands draw on specific processing resources utilized for phonological advance planning.
Crucially, we do not intend to claim that under a concurrent verbal WM load, the phonological advance planning scope was necessarily restricted to earlier elements of an utterance at all times. First, it is possible that participants differ in their adaptation, and some participants might have still planned ahead up to the utterance-final element despite a concurrent verbal WM load while others did not. For example, participants performing a concurrent verbal WM task in Experiment 1 displayed a much higher variability in terms of naming latencies, error rates, and phonological distractor effects than did the participant sample performing a concurrent visuospatial WM load. Because the pre-experimentally collected WM scores (backward digit span and backward block span) for the two participant groups tested in the visuospatial versus verbal WM load conditions were comparable, it seems unlikely that this was due to general differences between the participant groups. Nonetheless, participants possibly employed different strategies to master the dual-task demands, and some participants may have exhibited a greater tendency (and ability) to still plan ahead despite a concurrent verbal WM load than others.
Second, it is also possible that the amount to which the object was still included in the phonological planning scope varied from trial to trial (see Konopka & Meyer, 2014, for evidence concerning intraindividual variability of syntactic planning processes in sentence production). That is, imposing a concurrent verbal WM load might not have resulted in a compulsory reduction of the phonological planning scope, but in a reduction of the relative amount of trials in which the participant's phonological planning scope included the object (reduced to a degree that was no longer reliably detectable in the analyses). The present study was not designed to assess these possibilities, and future research should aim at disentangling them. What it does suggest, however, is that a concurrent non-verbal task does not affect the scope of phonological advance planning, whereas a concurrent verbal task does. In other words, advance planning at the phonological level seems to be more susceptible to a concurrent verbal WM load than to a concurrent non-verbal (visuospatial) WM load.
Abstract–lexical advance planning and WM load
In terms of the abstract–lexical advance planning scope, our results replicate and extend those reported by Wagner et al. (2010). That is, we obtained comparable results despite having participants describe a more integrated scene, rather than two conceptually independent objects, and omitting the critical (late) element of the sentence from the display to rule out any automatic lexical activation of the object's name. However, there are two possible caveats with respect to this evidently stable planning scope. First, one could argue that by presenting only the object that is encoded as the subject of the to-be-produced utterance, speakers retrieved the entire utterance as one chunk from memory, thus inevitably activating the object noun at the abstract–lexical level. However, we addressed this issue in a control experiment (see above) and found no evidence that the entire sentence was encoded as a chunk on the abstract–lexical level, which gives further support to the notion that the semantic interference effects in Experiment 2 can be taken as an index of advance planning at the abstract–lexical level.
A second possible criticism is that the verbal WM task we administered might have been too phonological in nature, thus only causing an overlap of phonological, but not lexico-semantic processing resources and thus leaving the abstract–lexical planning scope unaffected. Studies from patients with brain lesions (e.g., Martin & He, 2004; Martin & Romani, 1994; Martin, Shelton, & Yaffee, 1994) as well as experimental and imaging studies (e.g., Crosson et al., 1999; Shivde & Anderson, 2011) have put forward the idea that verbal WM can indeed be further subdivided into a phonological and a semantic subsystem. Therefore, it is feasible that the planning scope at the abstract–lexical level might be modulated if a different, more semantic verbal WM load is introduced. However, Martin et al. (2014) did not find an influence of a concurrent WM task, which mainly drew on semantic features of the memoranda (i.e., deciding whether a presented probe, e.g., “banana”, was part of the same category as one member of a previously presented word list, e.g., “donkey” and “cherry”). Future research will need to further dissociate the influence of a concurrent, primarily semantic WM task on this planning scope.
Conclusion
The central finding of the current study is that the two representational levels (abstract–lexical vs. phonological) are affected differently by a verbal WM load. This is not a trivial observation. For example, in the field of language comprehension, the influence of verbal WM is treated largely in terms of reading and comprehension proficiency, and no specific assumptions exist as to whether different stages involved in sentence comprehension are affected differently (perhaps because of the implicit assumption that all stages are affected alike; e.g., Caplan & Waters, 1999; Daneman & Carpenter, 1980; Daneman & Merikle, 1996; Fedorenko, Gibson, & Rohde, 2006, 2007). Therefore, our finding that in sentence production, phonological advance planning is susceptible to interference from parallel verbal WM processes whereas abstract–lexical advance planning is not (or at least to a lesser degree) calls for a more fine-grained view on how language processing and verbal WM interact, at least for the domain of speech production.
In the introduction, we have mentioned that the distributional properties of naturally occurring word and exchange errors led to the idea that the scope of advance planning during phonological encoding is notably smaller than the scope of advance planning during grammatical encoding (Garrett, 1975, 1980). Previous experimental studies (Oppermann et al., 2010; Schnur, 2011; Schnur et al., 2006) exploring online sentence production, however, showed that the scope of phonological advance planning may well extend beyond a single noun phrase and may even match the scope of abstract–lexical advance planning. Possibly, this discrepancy between speech error and online data can be ascribed to the circumstances under which speech errors occur. Other than in laboratory settings in which sentence production is studied while carefully controlling any potentially contaminating influences, in everyday life humans are often engaged in other activities while speaking, and some of these concurrent activities might have a more detrimental influence on phonological advance planning as opposed to abstract–lexical planning. This is in line with the conclusions drawn from the present experiments, namely that phonological advance planning is more susceptible to interference from concurrent verbal WM contents than abstract–lexical advance planning.
Footnotes
1
We do not report these analyses based on the other random effect of the models (i.e., participants) because it turned out that applying the same procedure resulted in serious issues of model convergence. That is, running these analyses by participants required an extremely simplified random effects structure for all of the models to converge, which is in conflict with established approaches in linear mixed-effects modelling (Barr et al., 2013), and does not allow a direct comparison with the full models reported here.
2
In the analysis of subject-related distractors, the main effect of relatedness was not significant either, t = 0.55, and neither was the interaction of relatedness and SOA, β = −0.008, SE = 0.004, t = −1.85.
Acknowledgement
We thank Nicole Hudl, Laura Babeliowsky, and Marie Kaiser for their assistance in data collection.