
Abstract
Security is a critical challenge for creating robust and reliable sensor networks. For example, routing attacks have the ability to disconnect a sensor network from its central base station. In this paper, we present a method for intrusion detection in wireless sensor networks. Our intrusion detection scheme uses a clustering algorithm to build a model of normal traffic behavior, and then uses this model of normal traffic to detect abnormal traffic patterns. A key advantage of our approach is that it is able to detect attacks that have not previously been seen. Moreover, our detection scheme is based on a set of traffic features that can potentially be applied to a wide range of routing attacks. In order to evaluate our intrusion detection scheme, we have extended a sensor network simulator to generate routing attacks in wireless sensor networks. We demonstrate that our intrusion detection scheme is able to achieve high detection accuracy with a low false positive rate for a variety of simulated routing attacks.
Introduction
The development of wireless sensor networks offers the promise of a flexible, low cost solution for monitoring critical infrastructure. For example, sensor networks have been proposed for applications such as traffic monitoring, building monitoring, and battlefield surveillance [1]. In any application involving critical infrastructure, there is the potential risk of malicious attacks on this infrastructure, either for financial gain or as a terrorist act. The sensor network has a critical role to play in detecting these attacks, and thus can become a target for attack in its own right. However, the problem of detecting attacks on sensor networks has not been addressed in the literature. In this paper, we investigate how to incorporate intrusion detection into wireless sensor networks, and present a method for detecting novel routing attacks on these networks.
A key attraction of sensor networks is their ease of installation and operation. However, security is one of the key challenges to creating a robust and reliable sensor network [2]. Currently, most research on security in sensor networks has focused on prevention techniques, such as secure routing protocols, cryptography, and authentication techniques [3]. These security mechanisms are usually the first line of defense. However, experience with the Internet has shown that flaws in these protocols are continuously being found and exploited by attackers [4]. Sensor network protocols are faced with additional challenges due to complexities such as a wireless access medium, unpredictable node movement, and unreliable node operation. These challenges create considerable potential to exploit weaknesses in the network. Consequently, we cannot rely on intrusion prevention techniques alone. In practice, Intrusion Detection Systems (IDSs) are needed to detect both known security exploits and even novel attacks that have yet to be experienced.
Intrusion detection is the problem of identifying misuse of computer systems and networks [5]. Most IDSs apply signature-based techniques. In general, signature-based techniques test for features of known network attacks. This raises the question of how to learn these features for known attacks, and how to detect new attacks. It is difficult to use supervised learning in this context, since labeled training data is expensive to produce. More importantly, it is difficult to detect new types of attacks whose signatures may differ from those in its signature set. This has motivated research into unsupervised learning techniques, which do not require labeled data and are able to detect previously “unseen” attacks.
Instead of learning the signature of attack traffic, unsupervised anomaly detection techniques focus on learning the signature of normal traffic. Unsupervised learning techniques do not require the data to be labeled, nor do they require the data to be purely of one type, i.e., normal or attack traffic. This is a significant benefit over the supervised learning approach.
This paper focuses on constructing an Intrusion Detection System for wireless sensor networks. We have made three main contributions in our work. First, we have explored the impact of network attacks on sensor networks. In particular, we have simulated several important categories of routing attacks on sensor networks. Second, we have developed an intrusion detection scheme that is suitable for use in wireless sensor networks. A major advantage of our intrusion detection scheme is that it is based on anomaly detection, rather than signature detection. This means that it is able to detect routing attacks that have not previously been seen. In addition, our intrusion detection scheme does not require communication between sensor nodes, which significantly reduces the power consumption in power-constrained sensor nodes. Finally, we demonstrate the effectiveness of our scheme on a variety of routing attacks in a simulated network. Our IDS was able to achieve high detection accuracy with a low false positive rate for each variety of attack that was simulated.
Sensor Networks
Sensor network technology is undergoing a rapid evolution. Early sensor networks involved simple transducers that convert a measured variable (e.g., temperature, sound, light) into a signal that can be transmitted to a central processing system for analysis [1]. These sensor networks were based on a star topology, with single-hop point-to-point links between the sensor and the central base station. The power requirements of single-hop links limited the range of the network, unless a significant power supply is available at each node.
These communication limitations have been addressed by the advent of multi-hop wireless networks,
based on routing protocols from ad hoc networks. In contrast to other types of networks, Akyildiz et
al. [6] note that this new generation of
wireless sensor networks has several special requirements that raise novel technical challenges.
Varying network size—the number of sensor nodes can vary over time as nodes move or lose
power. Power constraints—in many situations the sensor nodes have a limited power supply, which
makes communication much more expensive in comparison to local storage and computation. Geographic or data-centric routing—rather than relying on address-based routing, sensor
nodes place greater emphasis on geographic routing or content-based routing, where routing decisions
can be made on the basis of the contents of the message, and whether there is scope for local
aggregation of measurements.
These challenges have stimulated research into a new generation of routing protocols. In the remainder of this section, we introduce several important routing protocols that have been used or proposed in sensor networks. We also survey some of the security risks and attacks that are raised by these new routing protocols.
Routing Protocols
As stated above, the routing protocols in sensor networks have evolved from those developed for
ad hoc networks. Both networks can have a highly dynamic topology and lack any centralized control.
This means that routes can be constantly changing, and the network must be self-organizing. However,
there are several important differences between ad hoc and sensor networks: the number of nodes in a sensor network can be much larger than in ad hoc networks; the traffic flows in sensor networks are from the sensors to a centralized base station (or vice
versa), rather than irregular one-to-one communication between nodes in ad hoc networks; sensor nodes can be exposed to hostile environments, and can have a higher likelihood of failure;
and many sensor network applications have more severe resource constraints, which makes communication
a more expensive task in contrast to computation.
Numerous routing protocols have been proposed to address these problems. AODV (Ad hoc On-demand Distance Vector) routing was initially designed for ad hoc networks, and supports the self-configuration required by sensor networks. LEACH (Low Energy Adaptive Clustering Hierarchy) [7] is a cluster-based protocol where sensors in the network use localized coordination and control to organize themselves into clusters. Sensor nodes in LEACH undergo a randomized rotation to be elected as the cluster head, which prevents power being drained from any single sensor node. INSENS (Intrusion-Tolerant Routing in Wireless Sensor Networks) [8] is designed to be a secure and intrusion tolerant routing protocol for wireless sensor networks. INSENS utilizes symmetric-key cryptography to limit flooding and act as an authentication tool.
In this paper we have focused on AODV, since it has been used in numerous studies involving sensor networks [9,10,11]. Note that the basic principles in our approach are not limited to use in AODV, and can be applied to a variety of sensor network routing protocols. Let us now examine the basic operation of AODV.
AODV is designed for dynamic self-starting networks [12]. Some of the key advantages of this protocol are that nodes store only those routes that are required, the need for broadcasting and duplication of messages is minimized, and it has low memory requirements. Moreover, it can quickly update routes in response to link failures, and is scalable to large numbers of nodes.
AODV only discovers routes when they are needed. Each node maintains a routing table. If the node needs to send a message to another destination node, it first checks if there is an entry for that destination in its routing table. If such an entry exists, it will specify the next hop on the route to the destination. Otherwise, the node needs to discover a route to the destination.
Route discovery starts when the source node broadcasts a Route Request message to each of its neighbors. If a neighbor knows a route to the destination, then it sends a Route Reply message to the source node. Otherwise, it forwards the original route request to its neighbours. For example, consider the network in Fig. 1(a). Node A wants to send a packet to the base station. It looks into its table and does not find an entry for the base station, so it has to discover the route. This property of discovering routes only when they are needed is what makes the algorithm “on demand.”

Example of AODV.
To locate the base station, node A constructs a Route Request packet and broadcasts it. Since only node C is in range with A, only node C receives the request. Node C will then search its own table for the route to the base station. When Node C fails to find the route in its table, it will broadcast the Route Request again. Node B, node I and node D are within range of C so they will look in their table for the route to the base station. This sequence will go on until the request reaches a node with the route to the base station or the base station itself. A Route Reply packet will then be sent back using the node from which the request came (Fig. 1(b)).
In order to avoid redundant broadcasts, the source node includes a Broadcast ID in its Route Request message. If an intermediate node receives a Route Request message containing a Source Node ID and a Broadcast ID that it has seen before, it can discard the message.
In order to avoid discovering routes that are out of date, each node has an associated Destination Sequence Number. When a node generates a Route Request, it includes the most recent Destination Sequence Number that it knows for that route. When the destination receives the request, it increments its Destination Sequence Number, and includes that number in its Route Reply message.
When an intermediate node receives a Route Reply Message for a particular destination, it checks the Destination Sequence Number in the message. If it is higher than the Destination Sequence Number associated with the route that is currently stored in the routing table of the intermediate node, then the route is updated and the message is forwarded to the source of the request.
Perrig et al. [2] highlight the security challenges for sensor networks. Like any network, trust, authentication, and privacy are important issues for sensor networks. However, traditional solutions such as public key cryptography and the associated key distribution protocols are not directly applicable to sensor networks, particularly due to the need to minimize communication overhead.
Most sensor network protocols assume a high degree of trust between nodes in order to eliminate the overhead of authentication. This creates the risk of attackers introducing malicious nodes to the network, or manipulating the operation of existing nodes. Consequently, there is the potential for a wide variety of attacks on sensor networks. This section provides a brief summary of the main types of attacks that pose a risk for sensor networks, based on the survey by Karlof and Wagner [13].
Denial of Service (DoS) Attacks. A DoS attack aims to flood the network with useless traffic. This has two effects on sensor networks. First, the attack traffic consumes network resources, and prevents legitimate traffic from reaching the base station. More importantly, it causes sleep deprivation of sensor nodes and wastes their energy. This can be combined with other attacks such as altering of the routing information in order to maximize its effect.
Spoofing and Altering of Routing Information. Spoofing refers to an attacker impersonating another node by falsifying the identity field in routing messages. In a simple but effective attack, a compromised node can disrupt the network through spoofing and altering of routing information. This can enable an attacker to create routing loops in the network, or to increase the length of routes. This in turn causes increased traffic congestion and deprives the network of resources.
Selective Forwarding. Selective forwarding occurs when a compromised node drops a packet that is bound for a particular destination. In this way, an attacker can selectively filter traffic from a particular part of the network. Other possible variations of selective forwarding can involve dropping all packets or randomly dropping packets. Although random dropping is less disruptive, it can also be much harder to reliably detect and trace.
Sinkhole Attacks. The main purpose of the sinkhole attack is to lure all traffic from nodes in a region to a compromised node. This is achieved by forging or altering of the route packet information to make a compromised node look very attractive to the routing algorithm, causing neighboring nodes to assume that the compromised node is the best path to their destinations. Sinkhole attacks can also act as a platform for launching other attacks. An example would be to combine it with a selective forwarding attack. Since all the traffic basically flows through the compromised node, a selective forwarding attack would thus become more effective and easier to achieve.
Sybil Attacks. In Sybil attacks [14], a malicious node pretends to be a number of different nodes in the network. The malicious node can acquire identities either by fabricating new ones or by learning the identity of other nodes. To attack a network, the malicious node can use the impersonated identity to communicate with legitimate nodes directly, or by indirect communication where the malicious node advertises that it has a path to the impersonated node.
Wormholes. In a wormhole attack, a malicious node tunnels messages between two different parts of the network via a high speed link. This can make distant nodes appear “closer” in the network, which can be useful as part of a Sybil attack. Moreover, if the attacker is appropriately positioned, it can disrupt the entire network by diverting traffic from the base station.
Summary. Many different types of protocols are available for sensor network applications, some focus on energy saving, and some on resource awareness, or in-built security mechanisms. However, there is no perfect protocol which has yet proven to be robust against all attacks. Sensor network attacks come in various forms. They can be combined to create more complex forms of attacks by flooding, packet dropping, or manipulating nodes in the network. It is an open question as to how we can efficiently detect these types of attacks in sensor networks. In the rest of this paper, we focus on the problem of detecting routing attacks on sensor networks.
Problem Definition
Our aim is to develop an intrusion detection system that can detect routing attacks in sensor networks. We are given a wireless sensor network, which comprises a set of sensor nodes S = {s1, …, s n }, and a base station B. The sensor nodes and the base station use a suitable routing protocol so that sensors can route messages to the base station and vice versa. Each node s ∈ S monitors the routing messages that it receives in order to detect routing attacks in the network. The routing attack is caused by the activities of a compromised node denoted s a ∈ S. The problem is for each node s ∈ S to identify when an attack is occurring in S. Due to the cost of communication between nodes in sensor networks, we assume that each node acts independently when trying to detect an attack.
At every time interval Δ i , each sensor node constructs a feature vector c i , which summarizes the routing information that has been seen by that node. The feature vector c i comprises a fixed number of attributes {x j , j = 1 … d}. There are two challenges for intrusion detection in this context. First, we require an effective anomaly detection scheme for detecting abnormal routing conditions in the network. Second, we require a suitable set of attributes x that can summarize the relevant information about the routing conditions in the network. These attributes must be both efficient to collect, and generally applicable to a wide range of different routing protocols.
Anomaly Detection for Sensor Network Attacks
Our approach is to have all nodes in the sensor network individually equipped with an IDS. The main requirement of the system is that every IDS should function independently and be able to detect signs of intrusion locally by observing all the data it received without collaboration between its neighbors. Each IDS could rely solely on information extracted from the node's routing table and traffic packets through the node. Querying of information from other sensor nodes is not possible as neighboring nodes could not be trusted and this would incur a significant cost in terms of power resources.
We assume that each node has sufficient power and resources to perform the computation required for intrusion detection. This may not be applicable to all sensor network applications. However, our approach does not require expensive communication between nodes. Since each node operates independently when trying to detect occurrences of attacks from its neighbors, we describe the operation of our intrusion detection scheme from the perspective of a single node, which we refer to as the monitoring node. In practice, all nodes can potentially be monitoring nodes in the network for the purposes of intrusion detection.
We assume it is possible to physically compromise sensor nodes in the network, or to introduce compromised nodes. An example would be a node being captured and reconfigured to be under the control of an attacker, converting the sensor node to a malicious node. The malicious node would then be used as a launching pad for attackers to mount an attack.
As sensor networks use wireless communication, we assume that the radio links are insecure and the attackers are able to bypass intrusion prevention techniques. Thus, malicious nodes may be able to eavesdrop on network traffic in order to acquire network information for launching attacks.
In the rest of this section, we describe our intrusion detection technique in detail. Our first challenge is to define a set of traffic features that can be used to detect a wide variety of attacks for a range of different routing protocols. Our second challenge is to develop a suitable anomaly detection technique for detecting attacks without the need for prior knowledge of the signatures of these attacks.
Feature Selection
Our first task is to identify suitable traffic features that are useful for detecting routing anomalies, while attempting to have as few features as possible. This is because more features means more computation time and resources are needed by the nodes in the sensor network. Another important requirement is that the features selected should be applicable to a variety of routing protocols.
We have identified a set of 12 features that need to be extracted from the network traffic that is seen by the monitoring node. These features can be classified as non-traffic related and traffic related. Non-traffic related features represent the routing conditions of the sensor node, while traffic related features describe the conditions of the traffic flow through the node. These features are listed in Table 1, along with a summary of the distribution of values that were measured for each feature under normal traffic conditions in our network simulation. A detailed description of this simulation is given in Section 5.2.
Features for intrusion detection, showing the mean and standard deviation that was measured for
each feature from the network traffic simulation under normal traffic conditions (see Section 5.2 for details)

Features for intrusion detection, showing the mean and standard deviation that was measured for each feature from the network traffic simulation under normal traffic conditions (see Section 5.2 for details)
The first 9 features listed are traffic related and are primarily selected for detecting denial-of-service attacks, and attacks that manipulate the routing protocol. Feature 1 is used to detect unusual levels of data traffic, which may indicate a denial-of-service attack based on a data traffic flood. Features 2, 3, and 4 may be used to detect sinkhole attacks, since a sinkhole can generate artificial routes that may affect the need of other nodes to request routes. Similarly, features 5, 6, and 7 can be affected by the manipulation of the routing protocol in sinkhole attacks. Features 8 and 9 measure the level of route errors seen on the network, which directly relates to the operation of periodic route error attacks. While we expect there to be some degree of correlation between some pairs of features, our tests have shown that different types of attacks can cause subtle differences in the behaviour of related features.
The next 3 features are designed to monitor changes of the path to the base station. Feature number 10 is the most interesting among the 3 features. For sinkhole attacks in AODV, the attacker lures traffic by sending false routing packets that consist of a maximum Destination Sequence Number and minimal hop count. While it is not possible to detect the authenticity of the routing packet, we are able deduce that there is an occurrence of an attack if there is a sudden increase in the number of times the path to the base station changes compared to normal traffic conditions.
The problem of anomaly detection for network intrusion detection can be defined using the model in [15] as follows. Our aim is to detect suspicious traffic in the network that we are trying to protect. For example, when a sample of traffic is collected from our network, we need to decide whether that traffic sample is normal or abnormal. In order to make that decision, we represent each sample by a set of d features, e.g., the features in Table 1. These features are encoded so that each sample is mapped onto a point c in a feature space 葵 d , i.e., c ∈ 葵 d . We then analyze the surrounding region of the feature space for the point corresponding to that sample. If the point c lies in a sparse region of space where few other samples have been seen, then we label c as abnormal or anomalous. Any abnormal traffic is considered to be an attack. Conversely, if c lies in a dense region of space where we have seen many other traffic samples, then we label c as normal.
The process of anomaly detection comprises two phases: training and
testing. The training phase involves modeling the distribution of a given set of
training points, i.e., characterizing a set of given network traffic samples. Note that this
training data may contain both normal and abnormal data. For example, we cannot guarantee that a
traffic trace from a monitored network contains no attack traffic. Consequently, in order to build a
model that discriminates between normal and abnormal data points, we need to make the following
standard assumptions [16]: We need to assume that attack traffic occurs far less frequently than normal traffic. As a guide
we need to assume that less than y % of the data consists of abnormal
traffic samples. This assumption is used to differentiate between normal and attack traffic. We assume that attack traffic samples are statistically different from normal connections.
The second phase of anomaly detection, the testing phase, analyses new network traffic samples based upon the information gathered in the training phase. New traffic samples are mapped to the feature space and are labeled as abnormal or normal based upon the model developed in the training phase.
Due to the fact that we have assumed attacks occur far less frequently than normal traffic and that they are statistically different from the normal traffic samples, attacks will appear as outliers in the feature space. This means we can detect the attacks by analyzing and identifying anomalies in the data set. This is known as the process of anomaly detection for network intrusion.
The problem of anomaly detection for network intrusion has been an active area of research. Our approach is based on a fixed-width clustering algorithm, which is used to model the distribution of training points. This clustering algorithm has been shown to be highly effective for anomaly detection in IP networks [15,17].
Fixed-width clustering builds a set of clusters, such that each cluster has a fixed radius in the feature space. In the training phase of the fixed-width clustering technique, a threshold w is chosen as the maximum radius of a cluster. The first data point forms the centroid of a new cluster. If the distance of each successive point to its closest cluster is less than w, then the point is assigned to the cluster, and the centroid of the cluster is recalculated. Otherwise, the new point forms the centroid of a new cluster. At the end of training, the clusters that contain less than a threshold Τ % of the total set of points are labeled as anomalous. All other clusters are labeled as normal. The testing phase operates by calculating the distance between a new point c and each cluster centroid. If the distance from the test point c to the centroid of its nearest cluster is less than w, then the new point c is given the label of the nearest cluster, i.e., normal or anomalous. If the distance from c to the nearest cluster is greater than w, then c lies in a sparse region of the feature space, and is labeled as anomalous.
The algorithm for fixed-width clustering appears in Algorithm 1. We are given a set of network traffic samples C Tr for training, where each sample c i in this set is represented by a d-dimensional vector of attributes. We then proceed through the following stages of (1) normalization, (2) cluster formation, and (3) cluster labeling.
Normalization. There is considerable variation in the range of each
attribute—in some cases many orders of magnitude. Hence, when calculating the distance
between points, attributes with larger values will dominate those attributes with smaller values.
Therefore to ensure that all features have the same influence when calculating distance between
traffic samples, we must normalize each attribute before mapping into the feature space. This is
accomplished by normalizing each continuous attribute
x
j
in terms of the number of standard deviations from
the mean of the attribute as follows: 
Cluster Formation. After normalization, we measure the distance of each traffic sample c i in the training set C Tr to the centroid of each cluster that has been generated so far in the cluster set Φ. If the distance to the closest cluster Φ is less than the threshold w, then the centroid of the closest cluster is updated, and the total number of points in the cluster is incremented.
Note that the only information that needs to be stored for each cluster is a count of the total number of points belonging to that cluster and the mean of the cluster. Furthermore, only one pass is required through the traffic samples, and traffic samples do not need to be stored. This has the important benefit that it minimizes the computational load on sensor nodes when they perform anomaly detection. During the clustering process, we need to calculate the distance between a point and the centroid of each cluster. We have used the Euclidean distance metric in our application.

Fixed-width clustering.
Cluster Labelling. The assumption that the attack to normal traffic ratio is extremely small is used as a classification criterion in this algorithm. Furthermore, as per the second assumption, anomalous data-points are statistically different to normal data-points and hence are likely to belong to different clusters.
Based on these initial assumptions we define the following as the classification criterion. If a cluster contains more than the classification threshold fraction Τ of the total points in the data set, it is labeled as a normal cluster, else it is labeled as anomalous.
Testing Phase. In the testing or real-time phase, each new traffic sample is compared to the cluster set Φ to determine whether it is anomalous. The distance from the traffic sample to each of the clusters is calculated. If the distance to the nearest cluster is less than the cluster width parameter w, then the traffic sample shares the label (normal or anomalous) of its nearest cluster. Otherwise, the data-point is labeled as anomalous.
One of the limitations of clustering is the fixed threshold distance for a data point to be considered in a cluster during the learning phase, as illustrated in Fig. 2(a). This may lead to an anomaly data point to be considered as part of a normal cluster. The problem can be resolved by having a different threshold distance for each cluster, as shown in Fig. 2(b). After the learning phase, the threshold distance of each cluster can be optimized by changing it to be the same as the furthest point in each cluster. This will minimize the area of normal data clusters, and anomalies are less likely to fail into them during the testing phase.

Anomaly detection using clusters.
In order to evaluate the effectiveness of our intrusion detection system, we have simulated a range of attacks on sensor networks. The goal of our evaluation is to test the detection accuracy of our system under normal and attack conditions. Our simulation is based on a sensor network simulation library from the Naval Research Laboratory [18] . This simulation uses the NS-2 simulator to implement a sensor network that uses the AODV routing protocol. We have extended the simulation package to implement three types of attacks: periodic route error attacks, active sinkhole attacks, and passive sinkhole attacks. In this section, we first describe these attacks in detail; we then describe the implementation of our simulation; finally, we present the results of our evaluation.
Simulated Attacks
We now present the three attack types that we have simulated. Each attack is implemented for the AODV protocol, which is the basis of the simulation package we have used.
Periodic Route Error Attack. The periodic route error attack is a form of DoS. A sensor node is initially physically compromised by the attacker. Next, the compromised node will proceed to broadcast Route Error Messages to neighbouring nodes. These error messages inform the neighboring nodes that the route to the base station is down (Fig. 3(a)). Nodes that utilized this route will lose their path to the base station (Fig. 3(b)) and would have to repeat the process of searching for a route to the base station. This causes the affected portion of network to be congested with packets, and also causes sleep deprivation of the affected sensor nodes.
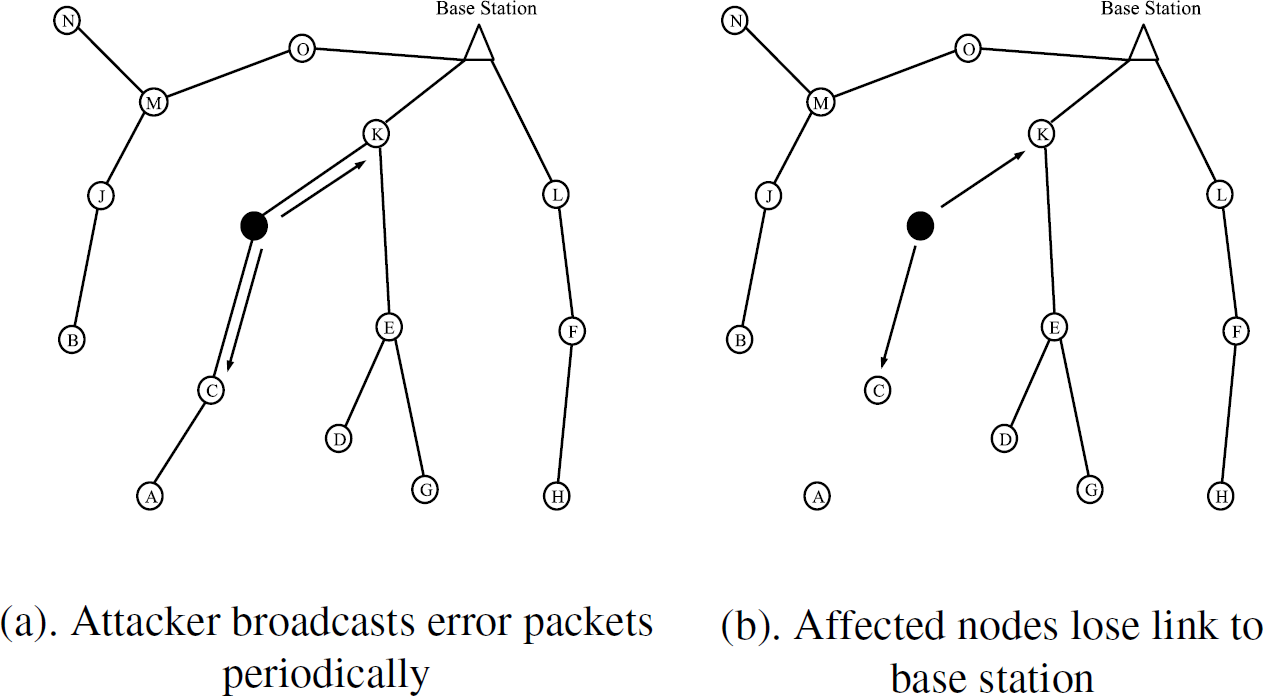
Example of a periodic route error attack.
This type of attack is only effective if the route to the base station is through the attack node. If none of the nodes in the network has a route through the attack node, the broadcasting of a route error will have no effect on the network. A Periodic Route Error Attack is best used with a sinkhole attack where traffic is drawn towards the attack node.
Active Sinkhole Attack. The active sinkhole attack aims to lure traffic to the attacker. An attacker first takes over a sensor node. Next, it sends a Route Request message for a route to the base station regardless of whether a path already exists. This is immediately followed by sending of a Route Reply Message, which contains the maximum Destination Sequence Number and minimum hop count (Fig. 4(a)). Neighboring nodes which receive the initial route request will reply to the compromised node if a route to the base station exists in their routing table, or else will forward the request message. However, these neighboring nodes would then receive the Route Reply Message from the compromised node, which will cause them to update their routing table with the compromised node as the best path to the base station (Fig. 4(b)). This effectively creates a black hole and shuts down this area of the network, since all packets bound for the base station are forwarded to the compromised node instead.

Example of a sinkhole attack.
This attack is devastating to the network because it does not need any node to generate a request. Even if there is no other traffic in the network, the attack node can still generate a request and reply itself.
Passive Sinkhole Attack. The passive sinkhole attack is similar to the active sinkhole attack. The only difference is that instead of broadcasting a Route Request message, the compromised node starts the attack by replying to a genuine Route Request message from a sensor node in the network with a Route Reply message. The reply message from the attacker contains the maximum Destination Sequence Number and a minimum hop count. This attack has the advantage that the probability of detection is reduced as the frequency of the attack is randomized.
However, this attack is not as effective as the active sinkhole attack as it has to wait for a Route Request to arrive before it replies. If the nodes in the area have no measurements to transmit, the attack node will not receive any Route Request.
Our simulation was based on the sensor network package from the Naval Research Laboratories, running on the NS-2 simulator platform (version 2.27). Our simulation scenarios used 25 sensor nodes, one base station and one phenomenon node. The phenomenon node represents a moving object, which is being tracked by the mobile sensor nodes. The sensor nodes use the Constant Bit Rate transport protocol, and use AODV as the routing protocol. The movement of all nodes except the base station was randomly generated over a 500m × 500m field, with a maximum speed of 55 m/s and an average pause of 0.01s. Each simulation was over a time period of 10,000 simulation seconds.
We have relied on a random node movement to generate routing activity under normal operating conditions. The continuous routing activity in our simulation reflects the potentially dynamic nature of real-life wireless sensor networks. In practice, routing activity can also be the result of a number of different factors, such as changes in the radio environment caused by the movement of vehicles, or changes in the routing topology caused by the failure of sensor nodes. Note that many sensor network applications involve the use of static sensor nodes. In that case, we would expect the routing topology to be much more stable in comparison to the case of mobile nodes, and thus involve far less routing activity. In such an environment, the routing activity caused by routing attacks is likely to be much more noticeable than in the case of dynamic nodes, and thus easier to detect using anomaly detection techniques. Consequently, we consider that our simulation using randomly moving sensor nodes is a more challenging test for our anomaly-based IDS.
We implemented four simulation scenarios: normal traffic, periodic route error attacks, active sinkhole attacks, and passive sinkhole attacks. We repeated five simulation runs of each traffic scenario, giving a total of five normal traces and 15 attack traces for evaluating our intrusion detection scheme. Each simulation run generates two trace files—one containing all the network traffic generated, and the other containing the status of routing tables throughout the simulation. Each trace is approximately 1 Gbyte in size, and is used to extract the 12 features used by each sensor node.
We use a single monitoring node in our simulation, and analyze the detection accuracy of the IDS in this node. In each simulation run, the monitoring node is chosen to be the closest node to the attacking node. In order to ensure consistency of our simulation results, we ensure that the monitoring node remains within transmission range of the attacking node. This guarantees that the traces from our monitoring node always contain attack traffic when an attack occurs.
We used one set of normal traffic to train our anomaly detection model during its training phase. We then used a second set of normal traffic to test the false positive rate of our IDS, i.e., the frequency with which it reports an attack when there is no attack.
We then used the attack traffic traces to measure the frequency with which the IDS in the monitoring node correctly detects the attack. We refer to this as the detection rate.
Simulation Results
Before we analyze the detection accuracy of our IDS, let us first consider the statistical profile the network traffic in our simulation under normal and attack conditions. As a baseline, we have summarized in Table 1 the statistical profile of each feature as measured under normal traffic conditions. Note that under normal traffic conditions there is a continuous level of routing activity, which is a result of the random movement of sensor nodes in the simulation.
We then compared the traffic profiles for each of the three simulated attack scenarios against the baseline of the normal traffic simulation. In the case of both the passive sinkhole and the periodic route error attacks, we found that for each feature there was an overlap in the measured distributions of values for the normal and attack traffic scenarios at two standard deviations or less from the mean. This indicates that no feature on its own can accurately discriminate either of these attacks from normal traffic conditions. In contrast, we found that in the case of the active sinkhole attack, there were two features whose measured distributions did not overlap at two standard deviations from the mean, namely, Feature 7 (Number of Route Request Replies Sent) and Feature 10 (Number of Updates on the Route to Base Station). This indicates that it should be reasonably easy for an anomaly detection system to discriminate this attack from normal traffic conditions with a high degree of accuracy.
Let us now consider the detection accuracy of our IDS. The results of our evaluation of our IDS are shown in Fig. 5. This figure shows the Receiver Operating Characteristic (ROC) curve for our IDS. The vertical axis shows the detection rate, while the horizontal axis shows the false positive rate. A perfect IDS would have 100% detection rate with a 0% false positive rate.

Receiver Operating Characteristic of the IDS for each type of attack.
For each attack type, we repeatedly tested the accuracy of our IDS using different values of the cluster width parameter w from Algorithm 1. Each setting of this parameter resulted in a different version of our IDS, which corresponds to a single point on the ROC graph. Figure 5 contains three ROC curves, corresponding to the accuracy of our approach for each attack type.
An important issue for the use of this anomaly detection approach in practice is how to set the cluster width parameter w. As can be seen from Fig. 5, a reasonable trade-off between the detection rate and false positive rate is achieved at a false positive rate of approximately 5% on normal traffic. By using a maximum target false positive rate, an appropriate value for the cluster width parameter w can be chosen in practice by decreasing w on normal traffic until the target false positive rate is reached. Potentially, the optimum choice of w may vary depending on the size and topology of the sensor network. We expect that the distance normalization scheme should lessen the effect of topology changes. An issue for further research is to test the sensitivity of the choice of w for different network scenarios.
We can characterize the performance of our approach using two measures based on the ROC curves in Fig. 5. The first measure is the detection rate for a false positive rate of 5%. The second measure is the area under the ROC curve. The area under the ROC curve for a perfect IDS would be 100%, whereas the curve for an IDS that picks at random would be a diagonal line, where the area under this curve would be 50%. We summarise the performance of our system on each attack type in Table 2.
Summary of results by attack type

For each type of attack, Table 2 summarizes how it is implemented, the potential impact of the attack, and the detection rate of our scheme for a 5% false positive rate. We also include the main features that helped discriminate each attack from normal traffic, based on an inspection of the features in the attack traffic that contributed most to the distance calculation.
In the case of the periodic route error attack, we achieved a 95% detection rate for a 5% false positive rate. In practice, this type of attack only has a high impact on the network if many of the routes to the base station pass through the attacking node.
In the case of the passive sinkhole attack, the detection rate was 70% for a 5% false positive rate. This attack can only take effect when a normal Route Request reaches the attacker. This lowers its impact, and also makes the attack harder to detect.
In the case of the active sinkhole attack, we achieved a 100% detection rate for a 5% false positive rate. This is an important result, because this is the most disruptive of all the attacks. It can occur anytime, and does not depend on the location of the attacker.
These results confirmed our expectations of the difficulty of anomaly detection for each type of attack. Recall from our discussion at the start of this section that in the cases of the periodic route error attack and the active sinkhole attack, there was substantial overlap between the measured statistical profiles of each feature in the normal and attack traffic cases. In contrast, in the case of the active sinkhole attack there were two features with very different statistical profiles for the normal and attack traffic cases. As expected, our anomaly detection system achieved extremely high accuracy on the active sinkhole attack. In the case of the other two attack types, our anomaly detection scheme achieved a high degree of accuracy, despite the substantial overlap in the feature profiles in comparison to normal traffic.
It is important to note that for each type of attack, a different set of features dominated the distance calculation for the attack traffic. Given that our detection scheme is only trained on normal traffic, this demonstrates the effectiveness of our approach for detecting new types of attacks. Our scheme also proved to be most effective for the attack that has the greatest impact on the sensor network, i.e., active sinkhole attacks.
Intrusion detection for sensor networks is an emerging field of research. Doumit and Agrawal [19] have used hidden Markov models to detect abnormal transitions in measurements from sensor networks. While their approach can detect attacks on individual sensor nodes, it does not address the problem of how to detect attacks on the sensor network infrastructure.
The most relevant body of work is in the area of ad hoc networks. Brutch and Ko [20] and Mishra et al. [21] highlight the challenges for intrusion detection in ad hoc networks, and propose the use of anomaly detection, but do not provide a detailed solution or implementation for the problem. However, a number of papers have presented intrusion detection schemes for ad hoc networks. We now summarize these schemes.
One approach is to make use of prior knowledge to guide the IDS. Anjum et al. [22] investigate the effectiveness of signature-based detection of attack traffic. Their focus is on how changes in the number of IDS-capable nodes affects the accuracy of detecting attacks. They do not consider the problem of detecting previously unseen attacks. Tseng et al. [23] propose a specification-based IDS, which makes use of a specification of how the underlying ad hoc routing protocol should behave. However, their approach requires detailed state information to be kept for each flow by the IDS, and no evaluation is given for their approach.
Some researchers have focused on the problem of how to achieve cooperation between IDSs that operate on different nodes. Albers et al. [24] propose an architecture for a cooperative IDS in ad hoc networks, but provides no details about implementation or evaluation. Kachirski and Guha [25] investigate the use of mobile agents in an ad hoc network. Their focus is on how nodes should be grouped for cooperation so as to increase the overall coverage of the network.
Several papers have considered the use of anomaly detection in ad hoc networks. Zhang et al. [26] have developed a queuing model to detect packet dropping in ad hoc networks. Each node compares the predicted and measured packet loss for each of its neighboring nodes. Their approach is focused on a single type of attack, and their evaluation is limited to a single node with a single flow.
Deng, Zeng, and Agrawal [27] have developed an anomaly detection scheme for ad hoc networks, based on one-class support vector machines. They demonstrate how their scheme can be used to detect black hole routing attacks in ad hoc networks. They use a form of information sharing between nodes in order to detect the attack, whereas our scheme does not require any form of information sharing. This is important, since communication is an expensive operation in sensor networks.
Huang et al. [28] have also applied anomaly detection techniques for intrusion detection in ad hoc networks. They have developed an anomaly detection technique called cross-feature analysis, which learns correlations of features that appear in normal traffic. Their technique is able to detect black hole attacks and packet dropping attacks in simulated ad hoc networks. While this is a promising technique, a potential drawback of cross-feature analysis is that the detection model can contain a large number of rules, based on different combinations of feature values. In the context of sensor networks, the size of the detection model may become a problem in terms of its memory requirements, and the computation time required to test the model on incoming traffic.
Future Work
Our approach highlights several promising challenges for future research. As new routing protocols are proposed for sensor networks, it is important to identify possible vulnerabilities and attacks for these protocols, and to investigate the effectiveness of our approach on these protocols. In this paper, we have considered the essential first step of demonstrating that nodes in isolation can infer evidence of an attack. Currently, our detection scheme is designed to run on the sensor nodes, due to the goals of minimizing energy-expensive communication operations, and the difficulties of managing trust between nodes. However, there are several possible extensions to our approach that could be considered as future research.
One promising direction for future research is whether sensor nodes can improve their intrusion detection accuracy by sharing evidence in a limited manner. For example, Leckie and Kotagiri [29] have developed an approach that can minimize both the delay and communication overhead required to detect network intrusions in a distributed intrusion detection system. We consider that this scheme could form the basis for collaborative detection in bandwidth-limited environments such as wireless sensor networks. Another alternative approach is to investigate how attacks can be detected from the perspective of the base station. This could be particularly useful if there is more than one base station, since the base stations are likely to have better communication infrastructure for sharing information. Finally, once an attack has been detected, it is important to establish suitable responses to the attack. These responses need to be able to mitigate the effect of the attack, while not becoming vulnerable to attacks themselves.
There is also scope for further work in terms of validating our approach on the different types of attacks. In this paper we have simulated situations where an attack is either present or absent. In practice, the onset of an attack may appear gradually, so that the attacker does not cause an abrupt change in the network, or the attack may be intermittent. We have also concentrated on simulations involving sensor networks of moderate size, in terms of the number of nodes in the network. An important issue for further research is thec development of a simulation platform that can support a wider variety of attacks on larger scale networks. In addition, it is important to move beyond simulations and validate these techniques on deployed sensor network hardware.
Conclusion
A critical issue for security in wireless sensor networks is how to detect attacks on the network in an accurate and computationally efficient manner. In this paper, we have made three important contributions to this problem. First, we have presented an intrusion detection scheme for sensor networks, which uses anomaly detection so that it can detect previously unseen attacks. Second, we have identified a general set of features that can be used to characterize the routing behavior in a network for intrusion detection, and are potentially applicable to a wide range of routing protocols. Third, we have extended a sensor network simulator so that we can simulate three important types of routing attacks in sensor networks, and demonstrated the effectiveness of our detection scheme on these attacks. In particular, we found that our detection scheme was highly effective at detecting active sinkhole attacks, which are an extremely disruptive form of attack. An important advantage of our detection approach is that it requires no communication between sensor nodes, which is a significant factor in minimizing the energy required in power-constrained sensor networks. Given the growing importance of sensor network applications, our intrusion detection scheme provides a valuable tool for developing robust and secure sensor networks in the future.
Footnotes
Acknowledgements
We thank the Naval Research Laboratory for making available their sensor network simulator.