
Abstract
The paradigm of self-stabilization provides a mechanism to design efficient localized distributed algorithms that are proving to be essential for modern day large networks of sensors. We provide self-stabilizing algorithms (in the shared-variable ID-based model) for three graph optimization problems: a minimal total dominating set (where every node must be adjacent to a node in the set) and its generalizations, a maximal k-packing (a set of nodes where every pair of nodes are more than distance k apart), and a maximal strong matching (a collection of totally disjoint edges).
Introduction
Most of the essential fundamental services for mobile networked distributed systems (ad hoc, wireless or sensor) involve maintaining a global predicate over the entire network (defined by some invariance relation on the global state of the network) by using local knowledge at each of the participating nodes. With the advent of large scale sensor networks, where a very large number of sensor nodes with limited computing and communication capabilities are involved to achieve a larger global task, scalability in coordinating the nodes and implementing fault tolerance in the network now require fundamentally new approaches [1]. The participating sensor nodes can no longer keep track of even a small fraction of the knowledge about the global network due to limited storage. Similarly, the traditional approach to building fault tolerant distributed system is no longer economically viable. The traditional approach of fault masking is pessimistic in the sense that it assumes a worst case scenario and protects the system against such an eventuality. Validity is guaranteed in the presence of faulty processes, which necessitates restrictions on the number of faults and on the fault model. But fault masking is not free; it requires additional hardware or software, and it considerably increases the cost of the system. This additional cost is not an economic option, especially when most faults are transient in nature and a temporary unavailability of a system service is acceptable for a short period of time. We need a new paradigm of localized distributed algorithms, where a node takes simple actions based on local knowledge of only its immediate neighbors and yet the system achieves a global objective [1].
Self-stabilization is a relatively new paradigm for designing such localized distributed algorithms for networks; it is an optimistic way of looking at system fault tolerance and scalable coordination, because it provides a built-in safeguard against transient failures that might corrupt the data in a distributed system. The concept was introduced by Dijkstra in 1974 [2], and Lamport [3] showed its relevance to fault tolerance in distributed systems in 1983; a good survey of early self-stabilizing algorithms can be found in [4] and Herman's bibliography [5] also provides a fairly comprehensive listing of most papers in this field. The system is able to adjust when faults occur, but 100% fault tolerance is not warranted. The promise of self-stabilization, as opposed to fault masking, is to recover from failure in a reasonable amount of time and without intervention by any external agency. Since the faults are transient (eventual repair is assumed), it is no longer necessary to assume a bound on the number of failures. The participating nodes communicate only with their immediate neighbors and require minimal storage to keep the local knowledge and yet a desired global objective is achieved. Since no communication is needed beyond a node's immediate neighborhood, communication overhead scales well with increase or decrease in the network size.
Another fundamental idea of self-stabilizing algorithms is that the distributed system may be started from an arbitrary global state. After a finite amount of time the system reaches a correct global state, called a legitimate or stable state. An algorithm is self-stabilizing if
for any initial illegitimate state it reaches a legitimate state after a finite number of node moves, and for any legitimate state and for any move allowed by that state, the next state is a legitimate state.
A self-stabilizing system does not guarantee that the system is able to operate properly when a node continuously injects faults in the system (Byzantine fault) or when communication errors occur so frequently that the new legitimate state cannot be reached. While the system services are unavailable when the self-stabilizing system is in an illegitimate state, the repair of a self-stabilizing system is simple; once the offending equipment is removed or repaired the system provides its service after a reasonable time.
Graph theoretic optimization problems are useful for such dynamic networks; fault tolerant distributed protocols for such problems provide the key resources for designing such wireless, sensor and ad hoc networks and they offer new insight into the fundamental role of discrete distributed algorithms in developing these real life applications [6]. For example, a minimal spanning tree must be maintained to minimize latency and bandwidth requirements of multicast/broadcast messages or to implement echo-based distributed algorithms [7]; a minimal dominating set must be maintained to optimize the number and the locations of the resource centers in a network [8]; an (r,d) configuration must be maintained in a network where various resources must be allocated but all nodes have a fixed capacity r [9]. In some sense, the concept “graph problem” is not very restrictive as it can apply to any problem where there is some static global computation in the network. Our purpose in the present paper is to further explore the intrinsic algorithmic power of this paradigm to design protocols for maintaining global predicates in a network based on only local knowledge at nodes. We are interested in algorithms to implement global synchronization where the legitimacy specification in terms of local property. Specifically, we propose new self-stabilizing algorithms for generalizations of dominating sets, generalization of matching, and maximal k-packing and provide correctness proofs and complexity analyses.
Dominating sets with specific properties have been used in several routing proposals for mobile networks [10], or for server placement (see for example [11]). Natural generalizations of a dominating set S can be obtained by placing a lower bound on the number of neighbours that each node (or each node not in S) must have in S, or by insisting that each node outside S be sufficiently close to at least one node in S. That is, the set S must be sufficiently dense and the goal is to find a minimal such set. We provide a self-stabilizing algorithm for a family of these generalizations. This includes what is called a
We then provide a self-stabilizing algorithm for the generalization of a maximal independent set S where every two nodes in S must be sufficiently far apart. That is, the set must be locally sparse and the goal is to find a maximal such set. A special case of this algorithm occurs when one specifies that no two nodes in S can be within distance k of each other; such a set is called a k-
A different class of graph problems involves finding a maximal The protocols developed for various global predicates in a network are all localized in the sense that nodes need to know the states only of its immediate neighbors. Thus, the solutions are scalable for arbitrary number of nodes in the network and since the protocols are self-stabilizing, nodes can enter and leave the system as long as each node knows an upper-bound on the number of nodes in the network and the nodes are assigned unique IDs. The protocols show an unified way of utilizing ordered ID space of nodes to solve different graph optimization problems which can be used as building blocks for other related problems. Although the protocols have been described using the shared memory model, they can easily be implemented (by using the existing local mutual exclusion protocols at a lower layer of the networks) in a distributed system; in ad hoc or sensor networks where message exchange is essentially by broadcast, local mutual exclusion is already implemented by the very nature of transmission. The protocols are self-stabilizing and hence no system wide reset is necessary in presence of link and node failures and the protocols can tolerate an arbitrary number of such faults as long as the rate of failures is lower than the convergence time of the protocols.
Model, Notation, and Related Work
We restrict attention to bidirectional networks or symmetric graphs. We use the standard
For symmetry breaking we assume the nodes have
We assume the algorithm is executed by a
Several authors have considered self-stabilizing algorithms for graph problems. For example, matchings are studied in [14, 16], maximal independent sets in [20], and domination in [21–24]. A more comprehensive list of references to past related works can be found in those cited works.
Given a node i in a graph, we denote by N(i) its neighborhood, that is, the set of all nodes adjacent to i (its neighbors). The set
Minimal Total Domination
Algorithm
The algorithm has a similar flavor to the one for minimal domination given in [HnJS03]. In the proposed algorithm, each node i has two variables: a pointer p(i) (which may be null) and a boolean flag x(i). If p(i) = j then we say that i points to j. We will use i interchangeably to denote a node and its ID. At any given time, we will denote with D the current set of nodes i with x(i) = true.
Definition 2.1
For a node i, we define m(i) as its neighbor having the smallest ID.
Definition 2.2
We define a pointer expression q(i) for any node i as follows:

Note that the value q(i) can be computed by i using only local information.
Definition 2.3
We define the boolean condition y(i) for a node i to be true if and only if some neighbor of i points to it.
The algorithm consists of one rule shown in Algorithm 1. Thus, a node i is privileged if x(i) ≠ y(i) or p(i) ≠ q(i). If it executes, then it sets x(i) = y(i) and p(i) = q(i).
Algorithm 1 Minimal Total Dominating Set
Correctness and Convergence
Lemma 2.1
If Algorithm 1 stabilizes, then D is a minimal total dominating set.
Proof
First, we claim that D is a total dominating set. For suppose, that some node i is not totally dominated (that is, has no neighbor in D). Then N(i)∩D = Ø. Since the system is stable, p(i) = q(i) = m(i), and m(i) ∉D. But this implies y(m(i)) = true and x(m(i)) = false, and so node m(i) is privileged, a contradiction. Thus D is a total dominating set.
Next, we claim that D is minimal. For suppose there is some j ∈ D for which D – {j} is a total dominating set. Since j ∈ D, or x(j) = true, there is some node i ∈ N(j) for which p(i) = j. But since p(i) = q(i), node j must be the unique neighbor of i with membership in D. Thus the removal of j will leave i undominated, a contradiction.
Note. We say that node i invites node j if at some time t node i has no neighbor in D and then executes the rule, causing p(i) = m(i) = j. For a node to join D, it must either be pointed to from an initial erroneous state or be invited.
We now show our algorithm stabilizes. Observe that if D remains the same, then every node can execute at most once (to correct its pointer). So it suffices to show that D changes at most a finite number of times. We say a move is an in-move if it causes x(i) to become true.
Lemma 2.2
If during some time-interval there is no in-move by a node bigger than node i, then during this time-interval node i can make at most two in-moves.
Proof
The first in-move made by i may have been because a neighboring node happened to initially point to i. The second in-move made by i must be by invitation. So suppose i is invited by node j. Then i is the smallest node in j's neighborhood, since m(j) = i, and at the time of invitation, all other nodes in j's neighborhood are out of D. By our assumption, their membership status does not change, so j remains pointing to i throughout, and i remains in D for the remainder of the time-interval.
Theorem 2.1
Algorithm 1 always stabilizes, and finds a minimal total dominating set.
Proof
It suffices to show that every node makes only a finite number of in-moves. By Lemma 2.2, node n, which has the largest ID, makes at most two in-moves. During each of the three time-intervals between such moves, using Lemma 2.2 again, node n−1 makes at most two in-moves. It is easy to show this argument can be repeated, showing that each node can make only finitely many in-moves during the intervals in which larger nodes are inactive.
Exponential Running Time
We briefly sketch how the algorithm can make an exponential number of moves. Consider the subdivision of the complete graph and add a leaf-node incident to each node of large degree. Assume all the large-degree nodes have the largest IDs. Initially all flags are clear and all pointers null.
Number the large-degree nodes v1,&,vs in increasing ID. Let wij be the node of degree two adjacent to vi and vj, and
Fire uij (so it points to vi) and fire vi so it enters the set.
and immediately succeed with
Fire wij (so it points to null) and fire vi so it exits the set.
Finally tack onto the end of the sequence that
Minimal Extended Domination
We now show how to generalize the basic ideas of the previous section. We also show in the next section that the same ideas can be used to solve the opposite problem of maximal packing.
A dominating set is a set D in which, for all i, | N [i] ∩ D |≥ 1, and a total dominating set satisfies | N(i) ∩ D |≥ 1. We seek a common generalization.
Definition 3.1
Assume that for each node i, the set

For the algorithm, we provide each node with a bag of pointers, denoted P(i), whose cardinality is bounded by t(i). (We allow P(i) to contain i.) Each node also has a boolean flag x(i). As before, x(i) should be true if and only if some node points to i, and also as before, D will denote the set of nodes with true flags at any point in time.
At a given time, assume
Definition 3.2
We define a set of pointers Q(i) as follows.

As before, we define the boolean condition y(i) to be true if and only if some neighbor of i points to it. The algorithm consists of one rule shown in Algorithm 2. Thus, a node i is privileged if x(i) ≠ y(i) or P(i) ≠ Q(i). If it executes, then it sets x(i) = y(i) and P(i) = Q(i).
Remark 1
It is easy to see that Algorithm 2 reduces to Algorithm 1 when
Algorithm 2 Minimal Extended Dominating Set
Lemma 3.1
If Algorithm 2 stabilizes, then D is a minimal set satisfying (1).
Proof
Assume Algorithm 2 stabilizes, and suppose that for some i,
Again, we say that node i
Theorem 3.1
Algorithm 2 always stabilizes, and finds a minimal extended dominating set.
Proof
In light of Lemma 3.1 we need only show stabilization. As before, observe that if D remains the same, then every node can make at most one move (to correct its pointers). So it suffices to show that D changes at most a finite number of times. In particular, it suffices to show that if during some time interval, x(k) remains unchanged for all nodes k > i, then during this interval node i can make at most two in-moves.
If i is never invited during this interval, then once i leaves D, it cannot rejoin. So suppose that during this interval i is invited by node j, allowing i to make an in-move. Once i enters D it must remain there if j continues pointing at it. And this is ensured, provided
Applications
Signed Domination. With this extension, one can, for example, find a minimal weak dominating set: here every node must be dominated by a node with degree at most its own. (For more details, see [25].) We also observe that Algorithm 2 gives one a self-stabilizing algorithm for finding a minimal

Packings. The generalized domination algorithm above solves the problem of a maximal packing. Another way of defining a packing is to say that it is a set such that in any closed neighborhood there is at most one node of the set. The set that is constructed is the set of nodes not in the packing. The requirement is that for every closed neighborhood of cardinality N, at least N−1 nodes must be outside the packing. Further, it is easy to see that the packing is maximal iff the complement is minimal with respect to that property.
One can generalize packing to allow denser sets. We define a {k}-packing as a set S of nodes such that in every closed neighborhood there are at most k members of S. So a normal packing is a {1}-packing. Such a packing is maximal if no node can be added to it. By the same argument as above, the extended domination algorithm solves this problem.
Weighted Extended Domination. The techniques used above can be extended further. Consider the problem of
One way to handle this is simply to think of a node i as having b(i) flags that operate independently and have unique IDs. However, for efficiency, instead of a flag x(i) a node could have a value X(i) restricted to the allowed range. The bag of pointers is replaced by an array of counters, one for each neighbor. The weight that i places in that register is how much weight it needs from that neighbor. The rule for X(i) for consistency is that it is the minimum of the weight-needs of its neighbors. We omit the details which are similar.
Maximal k-Packings
We now consider the problem of finding a set such that every pair of nodes are far apart. Recall that a k-packing is a set such that every pair of nodes are strictly more than k apart. We present next an algorthm for finding a maximal k-packing. This also provides a minimal set such that every node is within distance k of the set (called distance k-domination in the literature). Distributive algorithms for this problem were given by Kutten and Peleg [26].
Algorithm
In the algorithm, each node i has a vector Ri (for ruler) of length k (indexed 0,&, k−1) whose entries are IDs or null. First, We define the set D of
Definition 4.1
D is the set of all nodes i such that Ri contains only the value i (written Ri ≡ i). The intended meaning of the entry Ri[d] is that it gives the smallest ID of a despot within distance d of the node.
The algorithm consists of three rules as shown in Algorithm 3. The idea is that a node becomes a despot if (as far as the node can tell) there is no other despot within distance k, and retire if (as far as the node can tell) there is a despot with a smaller ID within distance k. Otherwise the node updates its ruler-vector to have the desired meaning.
Algorithm 3 Maximal Packing
Correctness and Convergence
Lemma 4.1
If Algorithm 3 stabilizes, then for each node i the value Ri[d] does indeed give the smallest ID of a despot within distance d from i
Proof
Proof by induction on d. True for d = 0: if i is a despot then Ri[0] = i and otherwise Ri[0] = null (any other possibility and the node would be privileged for Rule Upd). So assume true for indices less than d.
Assume i is not a despot. By Rule Upd, the value of Ri[d] is equal to the minimum of Rj[d − 1] for some neighbor j. By the induction hypothesis, Rj[d − 1] is the smallest despot within distance d − 1 of j. In particular, Ri[d] is a despot within distance d. But suppose z is the smallest despot within distance d. Then z < Ri[d]. But then if u is the neighbor of i on a shortest i — z path, it holds that Ru[d − 1] ≤ z, a contradiction.
A similar argument holds if i is a despot, except that then if Ri[d] (which equals i) is not the smallest despot within distance d, them Rj[d − 1] < i for some neighbor j, and so i is privileged for Rule Ret, a contradiction.
It follows that:
Lemma 4.2
If Algorithm 3 stabilizes, then D is a maximal k-packing
Proof
Suppose two despots i < j are within distance k of each other. Let u be the first node on a shortest path from j to i (possibly u = i). Then by the above lemma, Ru[k − 1] ≤ i; but then j is privileged for Rule Ret, a contradiction. So D is a k-packing.
On the other hand, suppose that i can be added to D and it remain a k-packing. Then i is distance more than k from every despot. So every neighbor of i is distance at least k from every despot, and by the above lemma has the all-null vector. But this means that i is privileged for Rule Add, a contradiction.
Lemma 4.3
If the set D does not change over some time-interval, then there can be at most a finite number of moves
Proof
By assumption, during this time-interval neither Rule Add nor Rule Ret is ever executed. Thus, while Ri might be corrupt due to erroneous initialization, after one pseudoround Ri[0] has stabilized for all nodes.
After another pseudoround, Ri[1] has stabilized for all nodes. For, if node i executes Rule Upd, then Ri[1] is the minimum of Rj[0] over all its neighbors, and these values have stabilized. Similarly, after another pseudoround, Ri[2] has stabilized. After k pseudorounds, there can be no further move.
Now we define an
Lemma 4.4
If the set
Proof
After one pseudoround, there obviously cannot be another reversal of Rv[0] for any v. Similarly, after another pseudoround, there cannot be another reversal of Rv[1]. For, if Rw[0] < i for some w ∈ N(i), then Rv[1] is fixed to the smallest value of Rv[0] (as these values never reverse). On the other hand, if Rw[0] is null or at least i for every neighbor, then Rw[1] can never become a value less than i.
Similarly, after k pseudorounds, there can be no further i-reversal.
Theorem 4.1
Algorithm 3 always stabilizes, and finds a maximal k-packing.
Proof
In light of Lemma 4.2 we need only show stabilization. We argue that a node can enter D at most a finite number of times. The proof is by induction on i.
We first observe that between consecutive entrances of a node i, there must be an i-reversal. For, when i executes Rule Add, all of its neighbors must have all-null arrays. In order for it to execute Rule Ret, some neighbor of i must have Rj[k − 1] smaller than i. That is, there must have been an i-reversal.
For the smallest node i = 1, there can be no 1-reversal. Hence it can enter at most once. For a general node i, between changes in Di< there is a bounded number of i-reversals, and hence a bounded number of entrances by i. This shows that D can change at most a finite number of times.
Putting this together with Lemma 4.3, it follows that the algorithm always terminates.
Strong Matching
In our proposed algorithm, each node i maintains only a pointer P(i): the value of P(i) is either a neighbor of i, or one of two special values:
The key is to use the total ordering of the nodes to provide an ordering (sometimes called the lexicographic ordering) on the set of edges (or more precisely on the set of pairs of nodes).
Definition 5.1
If e and f are pairs of nodes, then
For a node i, we define A(i) to be the smallest matched edge incident with one of its neighbors (as shown by their pointers).
Definition 5.2
For any node i, we define a special edge as

if it exists. (The edges are compared using the ordering ⪯ given above.)
We further define B(i) as the minimum available neighbor of node i.
Definition 5.3
For any node i, we define a special neighbor as
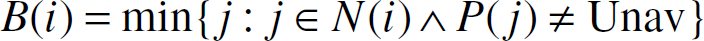
if it exists.

An example graph for illustration.
For example, consider the graph shown in Fig. 1 (where the values inside the nodes give the nodes' IDs and the values outside the value of P). For the node 2, A(2) = {1,4} and B(2) = 4.
Definition 5.4
We define the value Q(i) for a node i as follows:

We say that a node i is
Note that the value Q(i) can be computed by the node i (i.e., it uses only local information).
The self-stabilizing algorithm for maximal strong matching consists of one rule as shown in Algorithm 4. Thus, a node is
Algorithm 4 Maximal Strong Matching
Lemma 5.1
If Algorithm 4 stabilizes, then for any node i, if P(i) = j then P(j) = i.
Proof
We claim that if P(j) = Unav or P(j) < i, then i is privileged. For, if P(j) = Unav then B(i) ≠ j so that P(i) ≠ Q(i); while if P(j) < i then since
Further, we claim that if P(j) = Open or P(j) > i, then j is privileged. For, since B(j) ≤ i, it follows that Q(i) = Unav or Q(j) ≤ i.
We define a special set of edges as follows.
Definition 5.5

Lemma 5.2
If Algorithm 4 stabilizes, then the set
Proof
By the above lemma, the set
Suppose adjacent nodes i and j are both in the matching, but the edge between them is not part of the matching. That is, edges e = {i, P(i)} and f = {j, P(j)} are disjoint. Without loss of generality,
Finally, suppose an edge e = {i, j} can be added to
Termination
In this section we show that Algorithm 4 terminates in a finite number of moves when it starts from an arbitrary initial state.
Definition 5.6
Let X be a totally ordered set. Consider a sequence
Lemma 5.3
If X is finite, then a downward sequence
Proof
We prove by induction on |X|. Consider the minimum element of X; call it 0. It might be in or out of S(1). But once added, it cannot be deleted. So define
Definition 5.7
For any node k, we define the set of edges

Note that Sk exists for a node k only when P(k)∉ {Open, Unav}
Lemma 5.4
Let k be a node, and consider a period when no node less than node k executes.
Then Sk can change only a finite number of times during that period. If node k is at some stage consistent and available, and later declares itself unavailable, then in-between there was an addition to Sk.
If k is available throughout the period, and v is some neighbor of k that is at some stage consistent and available, and later declares itself unavailable, then in-between there was an addition to Sk
Proof
Suppose at some stage P(i) becomes j, with i > k > j. Since the nodes less than k are stable, it follows that B(i) = j throughout. So for i to change again, it must happen that A(i) changes to a value smaller than {i, j}. That is, if at some stage {i, j} is added to Sk, then before it is deleted some smaller edge must be added to Sk. (Note that if at the start P(i) = j' with j' < k, then we assume the change in Sk occurs in two steps: add {i, j} and then delete {i, j}.) Thus, the sequence of Sk is a downward sequence. By Lemma 5.3, Sk can change only a finite number of times. When node k declares itself unavailable, a better edge must have been created in its neighborhood since node k was last consistent. Hence there was an addition to Sk. At the moment v declares itself unavailable, it must see an edge smaller than {v, k}, which did not exist when it was consistent. Hence there must have been an addition to Sk.
Lemma 5.5
Let k be a node, and consider a period when no node less than k executes. Then node k moves a finite number of times.
Proof
There cannot be an infinite cycle of node k doing just the following types of moves: Unav to
Theorem 5.1
Starting from an arbitrary initial state, the algorithm terminates in finite time.
Proof
We use induction and Lemma 5.5; it follows that nodes {1,&,k} can be privileged (or make a move) only a finite number of times. Hence the algorithm terminates.
We note that in our application, the downward sequences have the additional property that if i is deleted because of j's addition, then i cannot be re-added until j is deleted. It can readily be shown that such sequences have length O(|X|2). However, this provides no improvement in the bound on the running time of the overall algorithm—which is O(nn) since no state can repeat.
Algorithm 4 does indeed have exponential running time. Consider the following example. Take any graph G and add three new nodes x3, x2, x1 such that x3 is adjacent to all nodes, while x1 and x2 are adjacent only to each other and to x3, and such that these three nodes have the smallest IDs and x3 > x2 > x1. Call the resulting graph G'.
Assume all nodes start as Unav. Then assume the demon proceeds as follows:
fire G until it stabilizes; fire x1 (so goes to Open) and then x3 (so points to x1); fire all nodes in G (so go to Unav); fire x2 (so points to x1) and then x3 (so goes to Unav); fire G until it stabilizes.
If M(G) denotes the maximum number of steps on graph G assuming all nodes start as unavailable, then it follows that M(G') ≥ 2M(G) + 4. By repeating this construction, it follows that running time can be at least 2n/3.
In this paper, we have proposed several self-stabilizing distributed algorithms for total domination, maximal k-packing and strong matching in large networks. We have assumed an ID based network to prove the correctness and the convergence of the algorithms. The underlying concepts are shown to be general and they are useful in symmetry breaking which is ever so important in designing distributed algorithms to achieve global objectives based on local knowledge. We did not address the issues of implementation of message exchanges in the network; this will be needed to be done before the protocols can be useful in real life networks; one possible implementation mechanism can be found in [27]. Also, we have considered only worst case performance analysis of the protocols; experimental investigations of average run-time behavior will be interesting and useful. We expect the inherent algorithmic power of the self-stabilization paradigm to achieve global objectives based on localized computations will be useful in designing algorithms for similar applications in ad hoc and sensor networks.
It is to be noted that in designing self-stabilizing algorithm, we need to define some kind of an invariant at each node that depends on the states of the neighboring nodes (since only the states of the immediate neighbor nodes are available to any node). Most of the self-stabilizing protocols for various graph theoretic problems follow this approach. On the other hand, there are problems for which designing a distributed algorithm becomes easier and more intuitive if distance-two knowledge was available at each node (this does not necessarily mean that the distributed protocol cannot be designed without distance-two knowledge). Authors in [28] have proposed a very elegant self-stabilizing protocol to collect distance-two knowledge at each node (invariant at each node still depends on strictly local knowledge). The underlying principle of the approach is to utilize some embedded lock mechanism to make sure the correct values of variables in distance-2 neighborhood are up to date before each node makes a move (which explicitly depends only on distance-one information). It has also been shown in [28] that any self-stabilizing algorithm that is designed using distance-2 knowledge can be simulated by their protocol to run on distance-1 knowledge at nodes with a slowdown factor of O(n2). It'd be interesting to if it is possible to design polynomial time self-stabilizing algorithms for the problems studied in this paper using the new approach.