
Abstract
The Analytical Information Markup Language (AnIML) is a standardization effort of ASTM (formerly American Society for Testing and Materials) Subcommittee E13.15 on Analytical Data. AnIML provides an XML-based format for analytical data. It is designed specifically for spectroscopy and chromatography data, but is suitable for use with many different analytical measurement techniques. AnIML consists of a generic core structure that permits the storage of arbitrary analytical data. These include multi-dimensional data, name-value pairs, and hierarchies. The concept of technique definitions permits the formal specification of constraints for usage of the core. This way, a definition can prescribe how the data for specific measurement techniques should be captured in the data file. To address changing requirements, AnIML supports an extension concept that allows vendors or end users to specify additional data that should be stored for a technique. These extensions can also be formally documented so that they do not break compatibility with existing software. This article presents an overview of AnIML and demonstrates how AnIML can be used to record data from everyday experimental workflows in a laboratoryenvironment. Issues related to the usage of AnIML in regulated environments are also discussed, including the use of digital signatures and audit trail functionality to ensure data integrity.
Introduction
Today, laboratory automation presents a number of challenges, not only in terms of equipment, workflow, and method design, but also in the proper documentation of the experiments we conduct. This issue receives growing attention, especially because of regulatory requirements from the Food and Drug Administration (FDA) and the Environmental Protection Agency (EPA), and also because of implementation of processes in compliance with Good Manufacturing and Good Laboratory Practices (GMP and GLP). These drivers impose a number of specialized requirements on how experiments must be documented. In addition, experiments in an automated laboratory environment are becoming more and more complex, involving the use of multiple analytical and experimental techniques. These techniques are often applied in combination or in sequence on the same sample. In many cases, an experiment also involves sample preparation, sub-sampling, and the use of derived or combined samples.
Currently, many standardized file formats for result data are readily available. Formats like SpectroML, 1 –3 ANDI, 4 –8 and JCAMP-DX 9 –12 are excellent choices for their application domains. But the use of such current formats becomes difficult when multiple techniques are used or if vendor-specific data need to be stored. 1
Consider the following experiment: a particular sample is acquired from a larger piece of material. Its amount is measured using an appropriate device (e.g., a balance). It is dissolved in a particular solvent using a certain ratio and is properly prepared for the analysis. After that, the prepared sample is processed using a separation technique (e.g., liquid chromatography) and analyzed using multiple attached detectors (e.g., a mass spectrometer and a UV/VIS diode array detector). Prior to the actual measurement, all the instruments have been calibrated according to manufacturers' protocols, and a blank sample has been analyzed. The devices have been purchased from multiple manufacturers and are running with a number of instrument-specific settings. A process such as this one is not particularly unusual, yet the proper electronic documentation of such an experiment is difficult. The Analytical Information Markup Language (AnIML) offers an XML (Extensible Markup Language)-based solution to this problem. It allows the documentation of a wide variety of laboratory workflows. The merits of using XML for the interchange and archiving of analytical data have been described previously. 1
When performing an analytical experiment, certain rules always apply. An operator typically applies an analytical technique to a technique-specific set of samples (Figure 1). It is necessary to provide a technique-specific set of instructions so that the technique can be applied properly.
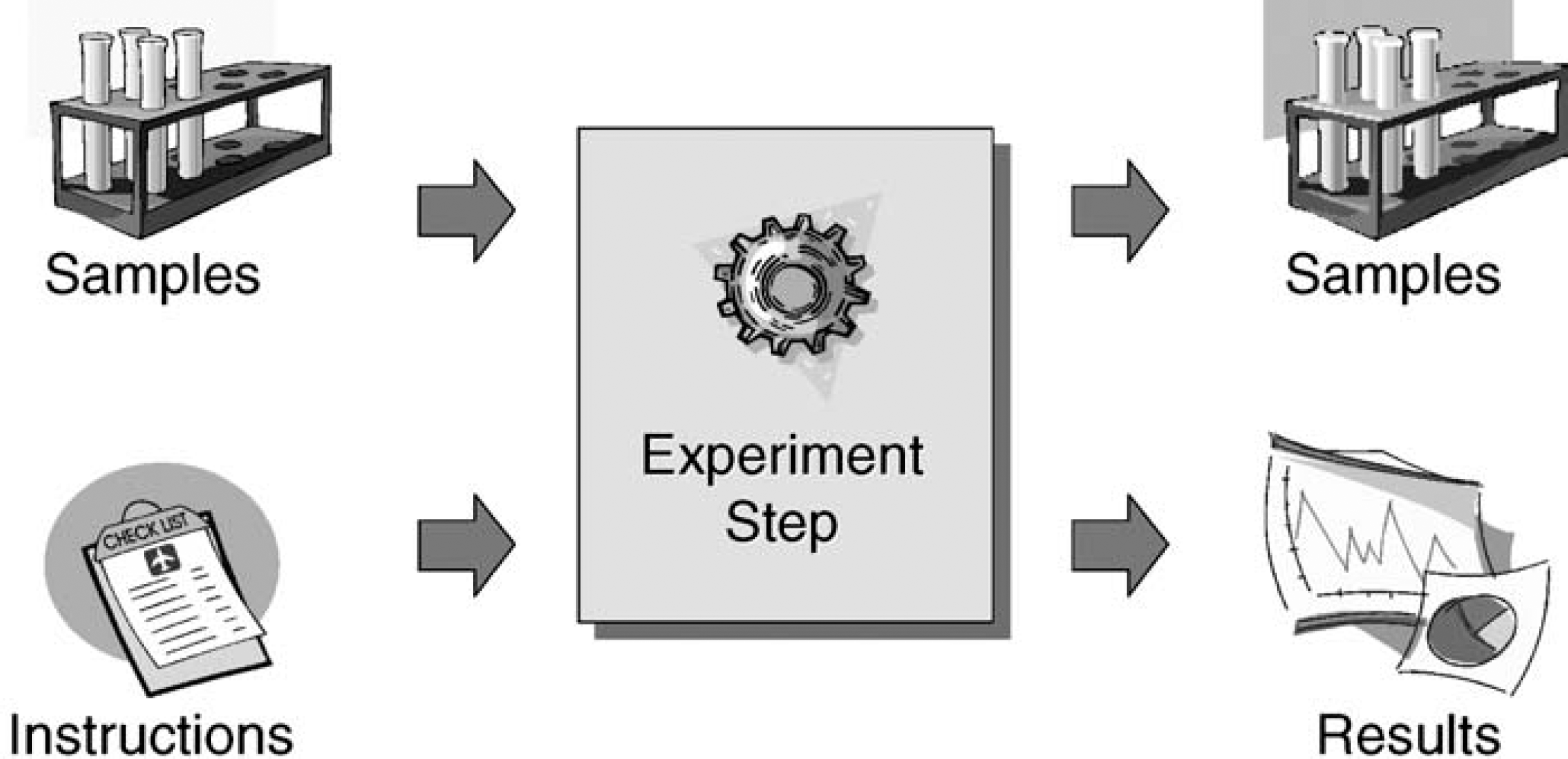
Data and material flow within an experiment step.
After the experiment is finished, the result data can be collected. Some techniques not only consume samples, but also produce new materials. These derived samples need to be collected and cataloged. It is obvious that both a material flow and a data flow need to be documented. We also notice that most of the data are technique-specific. AnIML provides a number of concepts to handle complex experiments like the one described above. It does this by dividing each experiment into a number of experiment steps. An experiment step is defined as the application of a technique to a technique-specific set of samples.
Data Model Overview
This section outlines the general ideas behind the AnIML data model. AnIML is divided into two major parts, the AnIML core and the AnIML technique layer.
The AnIML core constitutes an XML Schema 13 that provides very generic means to represent and organize arbitrary analytical data. Both multi-dimensional data and name-value pairs can be used to describe measurement data. Sample information and process information can also be expressed. Every AnIML document is governed by the core schema. Since the core is very generic, there are always multiple ways to represent a given analytical experiment. Such variability could make it difficult to implement generic software, because the software would have no idea what document structure to expect. The AnIML technique layer implements a metadata dictionary to solve this problem. It provides a technique definition schema that allows the creation of technique definition documents. These documents formally define how AnIML data documents (hereafter called simply AnIML documents) must be structured for a specific analytical technique. As these documents are machine-readable, an application can programmatically discover the structure of the AnIML document. This makes it possible to create software that can handle analytical techniques that were unknown at the time the application was developed.
Since the structure of an AnIML document can be formally described by applying the technique layer, it is possible to perform automated validation on AnIML data files. A validator program can be used to ensure that all the pieces of data required by a technique definition (and its extensions) are present in the file and bear the correct measurement unit and data type. Nevertheless, use of the technique layer is not required. An AnIML document that does not refer to a technique definition can be perfectly valid in itself. Using techniques only provides additional functionality and improves the interchangeability of AnIML documents.
AnIML Core—composing AnIML Data Files
The AnIML core provides means to represent arbitrary analytical data. In addition, it can represent process information that documents how the analytical data have been collected. Audit trail functionality and digital signatures are provided to ensure security and regulatory compliance. The core is defined by an XML Schema, the AnIML core schema, which governs every valid AnIML document. This schema should provide sufficient expressive power to represent arbitrary analytical data and should therefore not be modified or extended.
As depicted in Figure 2, an AnIML document is composed of the following four sections:
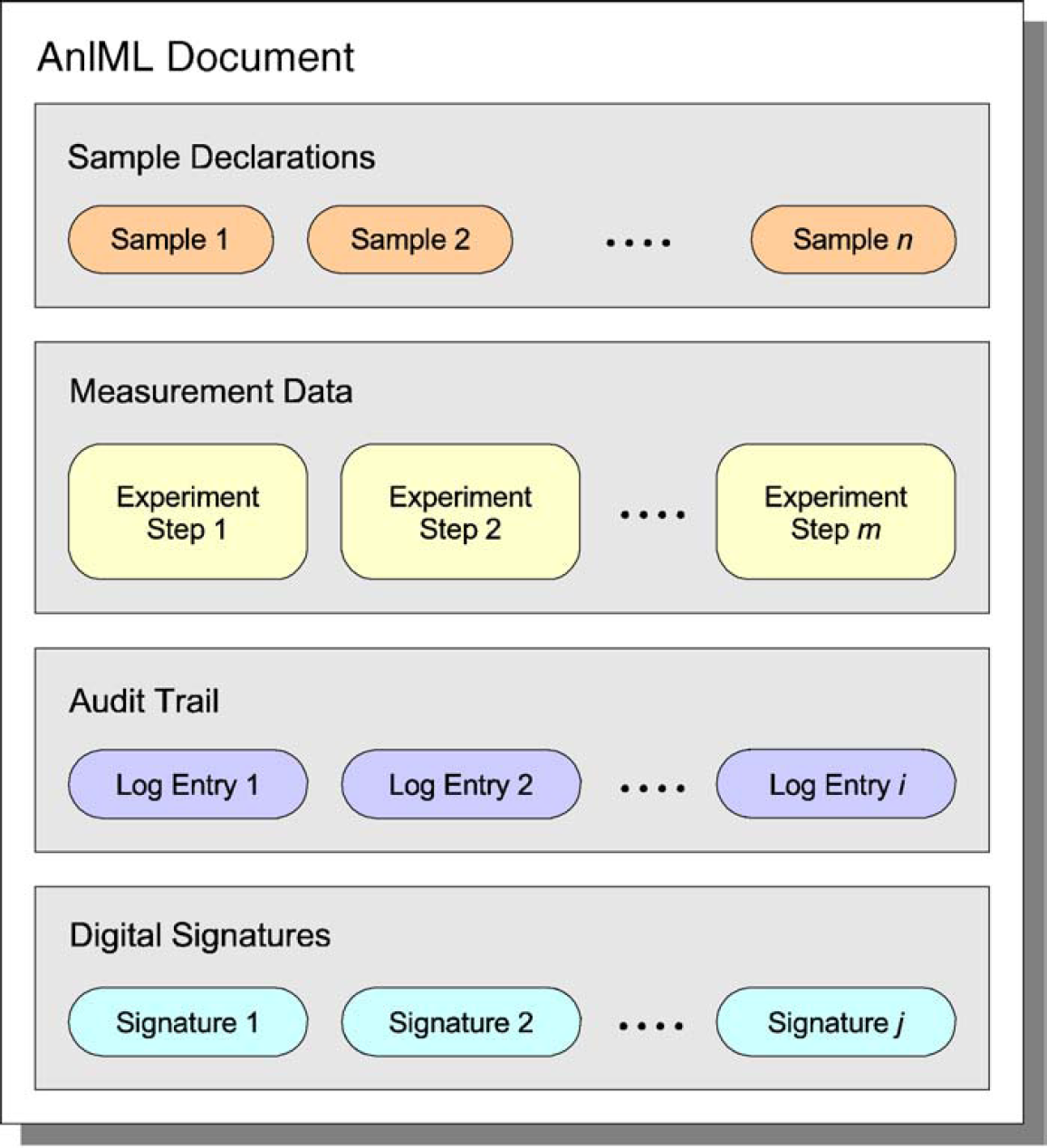
Structure of an AnIML document.
Sample Information
Process Information and Measurement Data
Audit Trail
Digital Signatures.
To facilitate the re-use of samples, every sample that is used inside an AnIML file must be declared in the Sample Information section. Each sample declaration carries a unique identifier that is used to reference a sample from other parts of the document. The Process Information and Measurement Data section describes how the samples defined above have been processed. It describes which techniques have been applied to a sample and the results that were gleaned using one or more experiment steps.
Modifications to an AnIML document can be tracked in the Audit Trail section. The location, date/time, and type of every change made can be logged. Information such as the user making the change and a description of changes made can also be stored here. To detect tampering with AnIML documents, digital signatures can be used. Stored in the Digital Signatures section, a signature can govern one or multiple parts of a document and prove the identity of a user having created, approved, or modified a document. Audit trail entries can also carry digital signatures. These signatures use the Worldwide Web Consortium's (W3C) XML DSIG standard. 14
Sample Information
Each sample that is used in an AnIML document is declared in the Sample Information section. It can then be referenced from other parts of the document. This approach has been chosen to allow multiple experiments on the same sample without having to store the sample data multiple times.
A sample receives a unique identifier (ID) and (optionally) a barcoded value that may be different from the identifier. Additionally, it is noted if a sample has been derived from a different existing sample. This is useful for documenting sample preparation steps, separation techniques, or sub-sampling. The sample ID is later used to reference a given sample. It is possible to store arbitrary additional attributes with a sample's information. These attributes can be grouped into categories, which may be hierarchically nested. To store these attributes physically, the notion of Parameters and Parameter Categories is used.
A Parameter is a data object that assigns a value of a specific data type to a name. It can have a measurement unit. As shown in Figure 3, parameters can be grouped into parameter categories, which in turn can recursively contain other categories, allowing the construction of a tree-like attribute hierarchy. Parameters support most of the standard data types (string, Boolean, numeric, …) for value representation. For specific purposes, special types like Image (PNG or SVG) or XML are available. The sample information that needs to be kept varies with each analytical technique. For this reason, a technique definition can prescribe which attributes need to be stored for each sample that is used with a given technique.

Parameters and parameter categories.
Process Information and Measurement Data
This section of an AnIML document assembles a number of different building blocks to describe precisely the laboratory experiments conducted. It can contain an arbitrary number of experiment step definitions. Each experiment step describes an experiment—the application of a technique to a sample. Each experiment step describes the material and the data flow, as well as how a technique was applied (method parameters). The actual result data are stored in pages that are contained within the experiment step element. Pages can store both multi-dimensional data (plots, spectra) and hierarchically nested and categorized name-value pairs.
Experiment Steps
An experiment step represents the application of a technique applied to a technique-specific set of samples. As such, it can be regarded as the instantiation of a technique definition. When an analytical experiment is performed, multiple samples may be involved. Each sample may have a different function within the experiment. For example, there may be a calibration sample, a blank sample, and an actual run sample. To express accurately these meanings of a sample, the notion of sample roles is used. These roles depend on the analytical process and are thus technique-specific. Additionally, a technique may not only consume, but also produce samples. This is usually the case for sample preparation techniques. But, this concept can also be used for sample inheritance when an actual sample may not be physically isolated, for example the sub-sample from a chromatographic peak that gives rise to a mass spectrum in a GC-MS experiment.
As pointed out above, samples are declared in the samples section of the AnIML document. Thus, the experiment step only contains references to these sample declarations. Along with this reference, the role of the sample is stored. Accordingly, a sample may be involved in multiple experiments and may play a different sample role in each of them. It is important to note that an experiment step definition should use as few samples as possible. Typically, only one sample is analyzed by a technique at a time. Other samples involved usually play ancillary roles, e.g., calibration or blank samples. These are also referenced by the experiment step. If an instrument is loaded with multiple samples simultaneously, multiple experiment steps would be used.
The AnIML core schema provides elements to store some administrative information directly within an experiment step. This includes the date and time when the experiment was performed and information about the user who performed it. Additional data about how the experiment is performed, i.e., method properties, can be stored as categorized parameters, similarly to the mechanism presented in Figure 3. However, this does not include measured result data; experiment step parameters only contain process description data. Although there may be some common information stored here, these data are typically technique-specific. The actual result data are stored in pages, multiples of which can be stored inside an experiment step. The concept of a page is covered in the following section.
Pages
A page serves as a container for result data. It may contain a multidimensional data set (plot, chart) as well as hierarchically nested name-value pairs (Figure 4). Multi-dimensional data are represented using a set of vector elements, one per dimension. Name-value pairs are stored using parameter elements that can be grouped and nested using multiple instances of the parameter category element. Again, the same parameter mechanism described earlier is used.
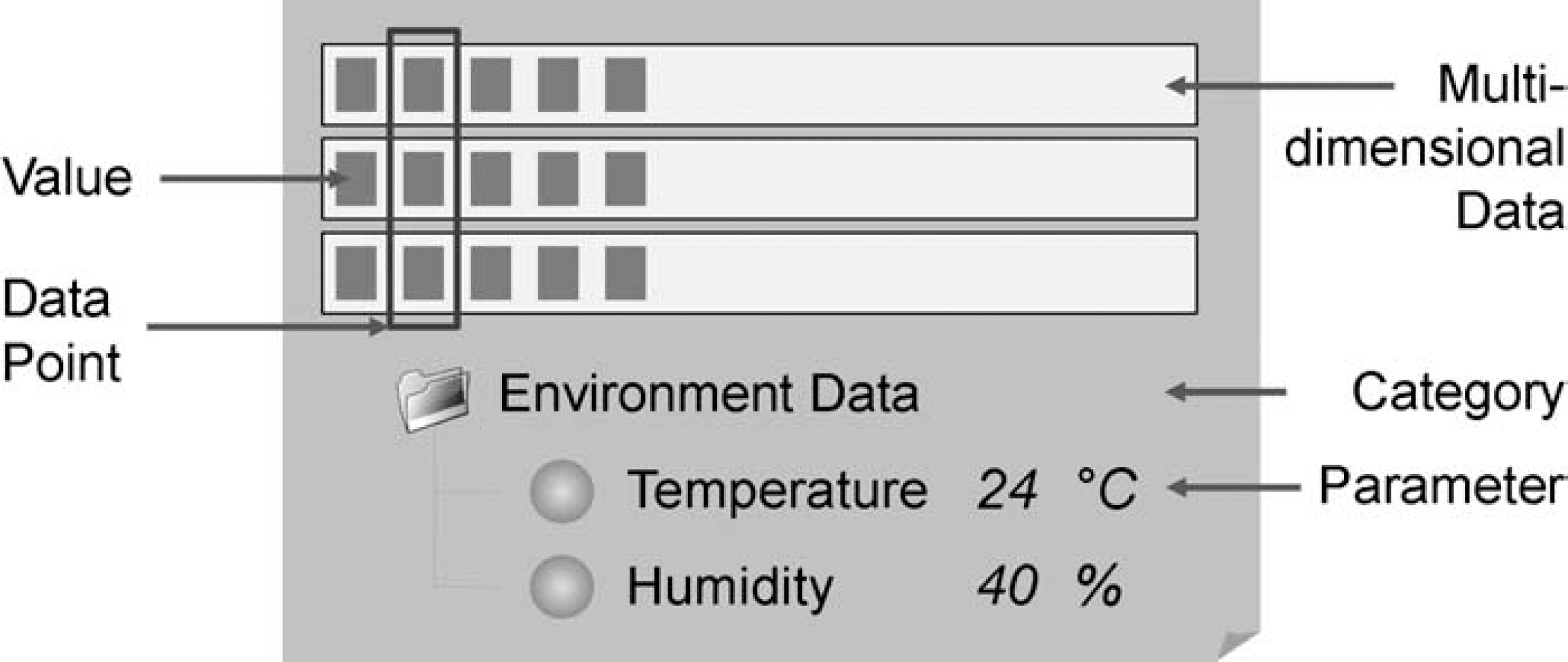
Structure of a page.
The multi-dimensional data within a page basically can represent a plot with an arbitrary number of dimensions (axes). AnIML provides a number of configuration options to customize the visualization of this plot:
dependent and independent axes
linear or logarithmic scaling
sparse or continuous sampling
data type
visibility
SI unit.
This information provides hints to the processing application about the meaning of the data, rather than exactly describing how a viewer should display it. This is intentional. The purpose of this mechanism is to capture the result data accurately while leaving the actual rendering to an application.
If a single page does not provide sufficient expressive power, additional pages (sub-pages) can be nested inside a page. Sub-pages can be attached to a specific data point or data range in the plot. Additionally, multiple experiment steps may be attached to a page. This makes is possible to describe analytical processes that make use of multiple techniques.
Using this mechanism, the example experiment described at the outset can be represented quite naturally as shown in Figure 5.
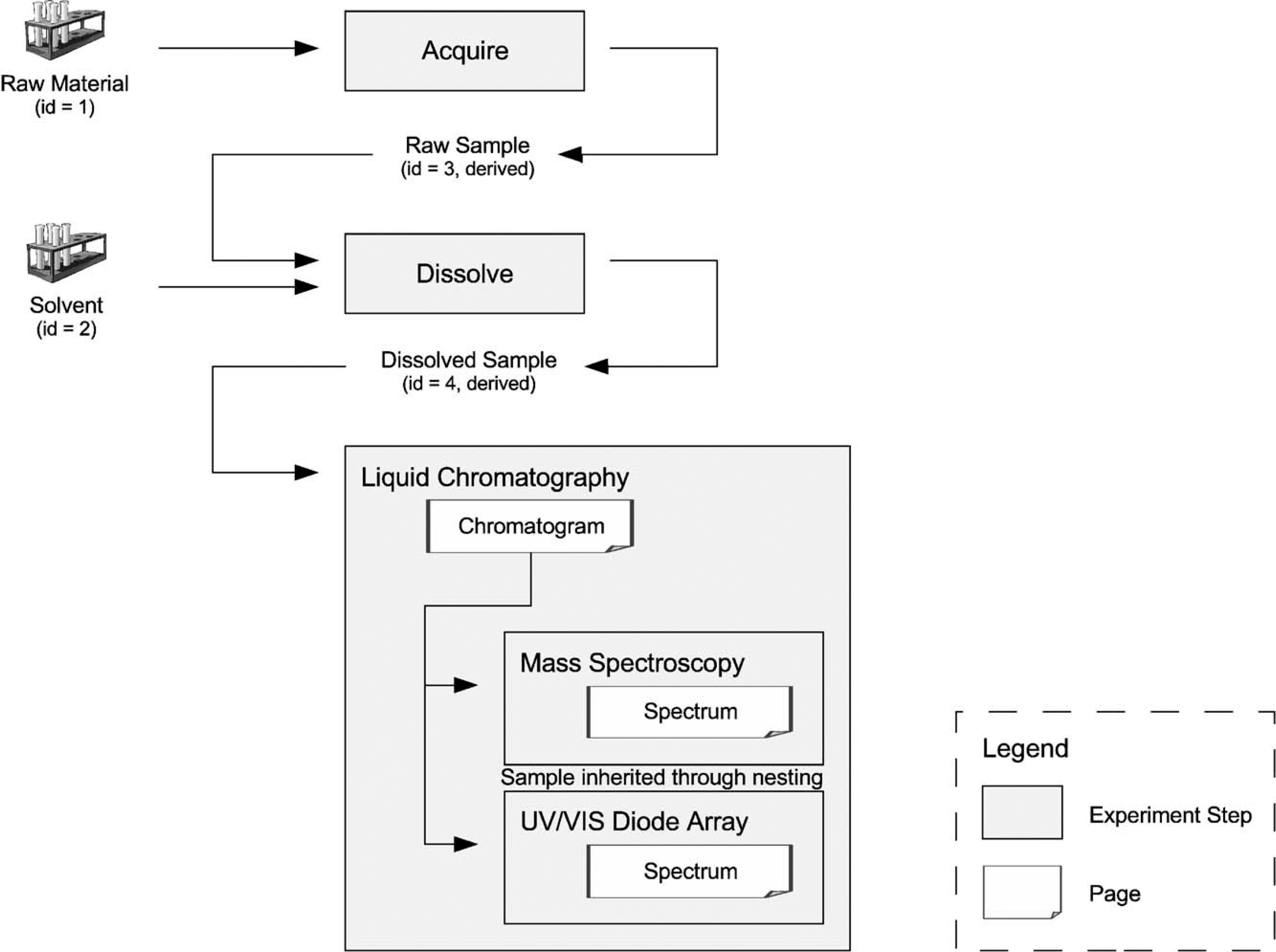
Using multiple and nested experiment steps.
Audit Trail
The audit trail section of an AnIML document serves as a container for log entries that describe modifications made to the document. Such an audit trail is often required in regulated environments. AnIML provides a mechanism for applications to store such a change history and to secure it using digital signatures.
Each audit trail entry provides fields for answers to these four typical questions:
AnIML supports a pointer mechanism to reference particular parts of the document. This is used to delineate which parts of the document are covered by an audit trail entry.
Digital Signatures
As with any file format, AnIML is not in a position to prevent unauthorized changes to data files. This task needs to be fulfilled by the storage repository together with the applications that create the file. Nevertheless, AnIML can help detect document modifications because AnIML documents can be electronically signed using digital signatures. When creating a signature, the user can choose which parts of a given document should be covered. It is also possible to sign the entire document. Additionally, an AnIML document can bear an unlimited number of signatures, with a different coverage scope each. With each signature, AnIML stores the user who created it, the time when the signature was made, and the business meaning of the signature (created, approved, …). Since AnIML uses the World Wide Web Consortium's XML DSIG specification, 14 AnIML can make use of existing software, certificates, and smart cards, as desired. It can also integrate with an organization's public key infrastructure (PKI).
Each item that is to be covered by a signature receives a unique identifier. The actual signature is then created by referencing all signable items, calculating the message digest checksum over the signature scope, and encrypting it with the user's private key. The use of digital signatures with varying scope proves to be useful in practice. It allows each operator to sign for the part of the experiment conducted by him/her. It also permits the signing of raw data directly in the instrument software, preventing undetected modification further down the line.
The AnIML Technique Layer
The purpose of the AnIML technique layer is to provide formal constraints on the usage of the AnIML core for particular experimental techniques. In a technique definition document, an author can declare the structure of an AnIML document. It describes the hierarchical nesting of data, its dimensionality, units, data types, among others. It also states which kind of sample information is required for a particular technique. Technique definitions should be created and maintained by experts in their specific fields. These definitions could be collected in a central repository. This way, any interested party could create and work with documents pertaining to a given technique. To use a technique definition, it is referenced from the proper section of an AnIML document. For more complex experiments, it is possible to combine multiple techniques and thus to create an AnIML file that accurately describes the experimental procedures and the resulting measurement data. To do that, the AnIML core supports multiple technique references per document, one per experiment step.
Sample Roles and Parameters
As we have already explored, an experiment step can both consume and produce samples. Each sample plays a specific sample role and needs certain attributes (parameters) to describe it further. All this information highly depends on the analytical technique that is used. It is technique-specific. Therefore, a technique definition declares all sample roles as well as the associated parameters and parameter categories that an experiment step for this technique must contain.
Page Structure
The structure of the result data as well as the process information is also technique-specific. For this reason, it is also only natural to describe this formally within the technique definition document. This includes a list of all pages that need to be in the file, each with specific instructions about the dimensions of a plot (name, data type, unit, and other metadata). It also defines all needed parameters with their name, data type, and unit, as well as the parameter category hierarchies. References to formal parameter definitions (such as those from consensus standards documentation) can be included to ensure precise meaning of the terminology employed. Each entry can be stated as optional or required, allowing added flexibility. Basically, a technique definition can be regarded as a blueprint that can be followed to construct valid experiment steps for a particular experimental technique. This blueprint can also be consulted when trying to decide if a given document is valid and complete. The technique definition can help determine if all required data from the experiment have been acquired and documented.
Extensions
In real-life situations, it is often necessary to make vendor-or user-specific extensions to a technique definition. This may be the case if a vendor releases an instrument that can measure additional parameters or requires specific settings. Other additions may be required on organizational or regulatory levels. Typically, such proprietary modifications adversely impact the interoperability with other applications. To prevent this, we developed a method to describe these modifications formally using technique extensions. A technique extension is also an XML document. It contains information about fields added by a user, supplier, or third party. Such extensions can be applied to an AnIML document—together with a technique definition. The declarations made in the technique extension(s) are superimposed on the technique definition. The resulting construct can then be used to deduce the structure of an AnIML document. Syntactically, technique definitions and technique extensions are virtually identical. They use the same XML Schema.
Standards Development Process
AnIML is a result of the work of the ASTM E13.15 subcommittee on analytical data. It is planned to create the AnIML standard in three distinct steps. First, the AnIML core and AnIML technique layer, i.e., the respective XML Schemas and corresponding usage documentation, will be documented in ASTM standards. This allows interested parties to implement the functionality of the standard in software applications.
ASTM is also planning to create ASTM standard technique definitions for a number of analytical techniques. This will happen in two phases:
Phase 1: Chromatography, Mid-Infrared Spectroscopy, Mass Spectrometry, Nuclear Magnetic Resonance Spectroscopy, UV/Visible Spectrophotometry, and Ion Mobility Spectrometry
Phase 2: Electron Paramagnetic Spectroscopy (Electron Spin Resonance Spectroscopy), Near-Infrared Spectroscopy, Crystallography, Chemometrics
The techniques chosen for Phase 1 all have agreed upon ontologies, documented data dictionaries, and existing standardized file formats for their result data. 1 –12 Domain expertise for many of these techniques exists within the other subcommittees of ASTM E-13 and within the IUPAC Subcommittee on Electronic Data Standards. However, we are seeking collaborations with other groups of domain experts to augment this list. Instrument vendors and end users are free to implement additional technique definitions as required.
At the time of this writing, details of the AnIML specification are still under development and subject to change. Detailed information on the current development and standardization status may be obtained from the AnIML web site. 15 Interested parties are encouraged to join ASTM E13.15 and assist with the further development of AnIML. 16
Summary
One of the main strengths of AnIML is its ability to store data from many different techniques—not only existing ones, but also future developments. The usage of a metadata-dictionary approach for technique definitions together with a generic core provides a solid foundation for this.
Because the core is generic, all data files practically follow the same format. It is therefore possible to develop generic software components that can handle data from arbitrary analytical techniques. The formal documentation of the document structure allows an application to discover automatically the semantics of the measurement data. Generic AnIML parsers and a generic viewer have already been demonstrated. Another benefit of the formal documentation is that automated validation of documents becomes a possibility. With appropriate extensions, even user-specific standard operating procedures (SOPs) can be enforced. Through the extension mechanism, vendors and users can add fields to a technique definition without sacrificing compatibility with existing software. Since the amendments are formally described, the software can either choose to work with the additional data or simply ignore it and hide it from the user. The use of audit trails and digital signatures, together with strong validation features, makes AnIML a viable file format for applications in regulated environments.
Acknowledgments
We would like to acknowledge the members of the ASTM E13.15 subcommittee for their many contributions to the development of the AnIML concept. Tony Davies and Maren Fiege from Waters Corporation (formerly Creon Lab Control)and others from the IUPAC Subcommittee on Electronic Data Standards have made major contributions in particular to the AnIML Technique Definitions. We also thank Peter Linstrom from NIST, Mark Bean from GlaxoSmithKline, and David Martinsen from the American Chemical Society for their helpful discussions and ideas.