
Abstract
User-generated content provides many opportunities for managers and researchers, but insights are hindered by a lack of consensus on how to extract brand-relevant valence and volume. Marketing studies use different sentiment extraction tools (SETs) based on social media volume, top-down language dictionaries and bottom-up machine learning approaches. This paper compares the explanatory and forecasting power of these methods over several years for daily customer mindset metrics obtained from survey data. For 48 brands in diverse industries, vector autoregressive models show that volume metrics explain the most for brand awareness and purchase intent, while bottom-up SETs excel at explaining brand impression, satisfaction and recommendation. Systematic differences yield contingent advice: the most nuanced version of bottom-up SETs (SVM with Neutral) performs best for the search goods for all consumer mind-set metrics but Purchase Intent for which Volume metrics work best. For experienced goods, Volume outperforms SVM with neutral. As processing time and costs increase when moving from volume to top-down to bottom-up sentiment extraction tools, these conditional findings can help managers decide when more detailed analytics are worth the investment.
Keywords
“In a world where consumer texts grow more numerous each day, automated text analysis, if done correctly, can yield valuable insights about consumer attitudes” Humphreys and Wang (2017)
From banks to potato chips, from large (e.g., J.P. Morgan) to small (e.g., Kettle) brands, the growth in the amount of available online user-generated content (UCG) provides managers with rich data opportunities to gauge (prospective) customers’ feelings. The Markets and Markets (2017) report shows that more than 75% of companies employ social media analytics by collecting and using the volume and valence of UGC to monitor brand health. To do so, most companies either purchase processed social media data from external providers (e.g., Social Bakers) or use off-the-shelf software solutions such as Linguistic Inquiry and Word Count; (LIWC). To date, most academic studies either solely rely on volume metrics (or pre-SET metrics) 1 (Srinivasan, Rutz, & Pauwels, 2015) or choose a single sentiment extraction tool (SET), such as dictionary-based analysis (Kupfer, Pähler vor der Holte, Kübler, & Hennig-Thurau, 2018; Rooderkerk & Pauwels, 2016) or machine learning-based techniques (Büschken & Allenby, 2016; Homburg, Ehm, & Artz, 2015). As pointed out by Balducci and Marinova (2018), few studies have provided a detailed explanation for their choice of a specific SET. The absence of a comparison is unfortunate for researchers and marketing practitioners because it hinders the ability to draw empirical generalizations and develop a consistent body of knowledge.
We thank the anonymous reviewer for this term
Does the choice of SET matter? Yes, for two reasons: UCG is often ambiguous and SETs substantially differ in their underlying approach to classifying sentiments in positive, negative or neutral categories. Pre-SETs only track classic volume-based metrics, such as the number of likes, comments or shares – with the assumption that more of such “engagement” is better for the brand. Top-down approaches as described by Humphreys and Wang (2017) use linguistic dictionary-based software solutions, such as LIWC, which rely on word lists that count the number of pre-classified words that belong to different categories (positive or negative emotions). Bottom-up approaches rely on machine learning and artificial intelligence in combination with training data to infer the probability that certain words or word combinations indicate a positive or negative sentiment.
Examples abound on ambiguous UGC, such as “@Delta Losing my bag is a great way to keep me as a customer,” which got much “engagement.” Human coders correctly deduce that the post conveys negative sentiment. However, a volume-based pre-SETs would reflect a simple count of, e.g. likes, comments and shares, and a simple top-down dictionary-based SETs would classify it as positive sentiment, given the higher frequency of positive words (
These approaches come with certain benefits and costs and present a varying level of complexity for managers. Classic volume-based pre-SET metrics such as likes, comments and shares are easy to collect, relatively easy to implement into existing dashboards and fast to process. For example, once a manager has access to their brand Facebook account, the time and effort to collect such metrics is minimal. Thus, we posit that pre-SET volume metrics have low level of complexity. Still, their ability to capture all facets of human speech must be considered to be limited as outlined by our above example. Top-down approaches typically rely on “pre-manufactured,” non-contextualized word lists, provided by different commercial sources. Such top-down approaches require a medium level of effort in data preparation and computational power. Thus, they have medium level of complexity. However, given the lack of contextualization, they may lead to misinterpret the content as outlined in our example. In contrast, bottom-up approaches efficiently overcome the problem of contextualization. By using case specific training data, machine learning can infer specific word-combinations, which may be unique to a given context. This ability however comes at high costs as training data needs to be carefully collected, maintained and updated. While in some cases, managers could have access to “pre-manufactured” approaches which can be applied in their context, most of the time such on-the-shelf solution might not be available. Some discussion of this is warranted In addition, developing a meaningful machine-learning approach requires substantially more time and computational effort. Accordingly, such approach has a high level of complexity.
Hence, the dilemma:
The marketing literature does not yet provide managers with guidance on which SETs best predict key brand metrics, such as awareness, consideration, purchase intent, satisfaction and recommendation – the traditional survey metrics they are sometimes claimed to replace (Moorman & Day, 2016, p. 18; Pauwels & Ewijk, 2013). Studying the antecedents of these brand metrics is important as they are important predictors of sales and firm value (Colicev, Malshe, Pauwels, & O'Connor, 2018; Srinivasan, Vanhuele, & Pauwels, 2010). For example, while Colicev et al. (2018) extensively studies the effects of social media volume and valence on consumer and stock market metrics, they exclusively rely on a bottom-up Naïve–Bayes classifier to extract sentiment from social media posts. The research gap is especially harmful because marketers give increasing weight to UGC and its derived sentiment metrics in dashboards and decision making (Markets & Markets, 2017). UGC and its text analysis can yield valuable insights about consumer attitudes (Moorman & Day, 2016), but only if done correctly (Humphreys & Wang, 2017). What “done correctly” means could depend on the brand and industry. For example, sophisticated SETS may be more important to lesser-known brands than to well-known brands that professionally manage their social media presence. Likewise, search versus experience goods may experience different benefits from different SETs. Finally, industries with mostly negative UCG sentiment, such as airlines and banking, may only need volume-based metrics that serve as a cheap and fast proxy to explain consumer mindsets. In sum, managers and other decision makers (such as investors) are uncertain as to which SETs are more appropriate for a specific brand in a specific industry.
To address this research gap, we compare the most commonly used SETs in marketing in the extent to which they explain the dynamic variance in consumer mindset metrics across brands and industries. Our unique dataset combines, for several years, daily consumer metrics with Facebook page data for 48 brands in diverse industries, such as airlines, banking, cars, electronics, fashion, food, beverages and restaurants for a total of 27,956 brand-day observations. With an
Research Background and Sentiment Extraction Techniques
Marketing scholars can use several tools to extract sentiments from textual data. Because some of these tools are not known to a broad audience of marketing researchers, we first discuss the range of available tools before focusing on the specific tools that are used in this study.
Different schools of research have aimed to identify and measure sentiments that are hidden in texts. Linguistics and computer science share a long history of analyzing data from textual sources, which is commonly referred to as Natural Language Processing (NLP). Independent from their scientific roots, the vast majority of sentiment and text analysis approaches rely on so called part of speech tagging, where the main text (often referred to as corpus) is divided into tokens, which are sub-parts of the main corpus. Tokens may be single words, complete sentences of even full paragraphs. The tokenized text is then fed into the text analysis tool that infers meaning from it. Part-of-speech tagging procedures assign tokens into categories, which could be word classes (e.g., subjects or verbs). Besides grammatical categories, tokens may also be assigned into pre-defined categories such as e.g. positive or negative emotions, anxiety or arousal. As text data are prone to noisiness and given that many common words do not provide meaningful information, the text data gets often cleaned by removing so-called “stopwords” that do not provide meaning (e.g., articles or numbers) and by reducing words to their stemmed form. To infer sentiment from tokenized text, two main approaches are available. Top-down approaches (e.g., LIWC) rely on dictionaries, which are lists that contain all words assigned to a specific category. By counting how many times a token (e.g., word or word combination) of a specific category occurs, the top-down approaches determine the strength of a specific content dimensions (e.g., positive sentiment).
In the case of bottom-up approaches, a-priori dictionaries do not exist and instead, a machine is trained to build its own list with the help of training data. Training data may origin from different sources. Whereas some studies rely on human coded data (Hartmann, Huppertz, Schamp, & Heitmann, 2019), where multiple coders classify a subsample of texts into categories, such as, e.g., positive or negative sentiment, other studies have used user generated content (see e.g., Pang, Lee, & Vaithyanathan, 2002), such as, e.g., online reviews where the additionally provided star rating provides the likely type of sentiment (i.e., 1 star indicates negative sentiments and 5 star ratings indicate positive sentiment). Then algorithms determine the likelihood that a document belongs to a specific category (e.g., positive emotion) based on the occurrence of a specific tokens from the tokenized text. To determine these likelihoods, the machine needs pre-coded training data (i.e., the human coded or review texts) with documents clearly belonging to each dimension (e.g. documents with only positive or negative sentiments). The machines then estimate the likelihoods of a text belonging to a category given the occurrence of specific tokens.
Top-Down Approaches
Top-down approaches are based on
Researchers may use existing word lists or tailor the lists for the research context, industry or product category. Such tailoring requires a high level of expertise, availability of skilled coders as well as enough material to infer all words that are related with the construct (e.g., Mohammad & Turney, 2013 crowdsource the task). This is the likely reason companies and researchers turned to pre-manufactured, general lexica, which have been developed by commercial companies (e.g., LIWC). To infer the sentiment from a corpus, our study uses word tagging to assign positive and negative categories to words. We calculate the share of positive or negative words in relation to the total word count in a corpus. As an illustration, consider the sentence “
Researchers can use a hierarchical approach by first identifying a key word (such as the brand “Coke”) and then looking around the key word (e.g. words that appear 4 words before the keyword). These approaches are sensitive to the frame size that is included around the key word. Frames that are too small will miss information, while frames that are too large risk the unintended inclusion of non-related words. Moreover, it is difficult for (simpler) dictionaries to understand the meaning of combinations, such as “
Bottom-Up Approaches
Bottom-up approaches typically originate from computer science. They do not rely on a pre-manufactured word-lists and use machine learning to understand which words are related to a specific sentiment in a specific context. In this respect, they use pre-coded “training data” (e.g., data that have been coded to be very positive or negative, for instance because it is associated with 5-star or 1-star customer reviews) that serves as a source for the algorithm to automatically infer which words are more related to a specific dimension of interest (e.g., positive sentiment). Bottom-up approaches automatically prepare de-facto wordlists (even though these lists may not be directly visible) which are inferred from the training data, instead of (limited) human intuition. In other words, bottom-up approaches involve training machines to understand how words and word combinations (almost unlimited) are tied together. This makes them well-suited to understand complex meaning, quick in generating context-dependent classifiers and less prone to human errors (e.g., subjective coding biases). 3 It is not surprising that machine learning is widely applied in an array of fields, such as picture recognition, customer detection, segmentation and targeting (see e.g., for marketing related applications Cui & Curry, 2005; Evgeniou, Micchelli, & Pontil, 2005; Evgeniou, Pontil, & Toubia, 2007; Hauser, Toubia, Evgeniou, Befurt, & Dzyabura, 2010).
However, they do, rely on training data that has been human-coded so to some extent it is subjected to the same subjective coding biases that a dictionary method is subject to. We thank the anonymous reviewer for this clarification.
Bottom-up approaches use training data that can be split into two sets: one that contains strong positive sentiments and one with strong negative sentiments. Then, the machine learning algorithm infers probabilities that are based on the words or word combinations from the two training sets to determine whether a text should be classified as positive or negative. To do so, the training data are commonly transferred into a sparse-matrix format (Wong, Liu, & Chiang, 2014) called document-term matrix (DTM). DTMs are one possible implementation (among others such as, e.g., set implementations which do not rely on matrices) of bag-of-words approaches (Aggarwal & Zhai, 2012). For each word that occurs in the entire training set, the matrix features a single column. Each row represents a document from the training set. Bottom-up approaches commonly try to limit the number of words (i.e., columns) in a sparse matrix. To do so all numeric information and stop words are usually removed from the text. For example, English stop words such as “The,” “That,” “This,” “Me” or “At” are removed from the text. To further reduce the number of columns and reduce any redundancy within the DTM, all words are transformed to lower case before applying word stemming. Word stemming further reduces the number of unique words in the DTM by cutting loose endings from a word root to obtain only one-word stern that then is included in the DTM. 4
Even though these procedures are widely applied in text and sentiment analysis, some studies show that important information may be lost through the removal of stop words and word stemming (Büschken & Allenby, 2016).
In the next step, to categorize text, bottom-up approaches rely on a classification algorithm. For example,
Given the previous critiques of the abovementioned algorithms, this study focuses on SVMs. To date,
Different SVM Operationalizations
Although bottom-up approaches are highly flexible, a key issue is that bottom-up approaches classify a full document (e.g., comment) as positive, negative or neither (i.e., neutral). In contrast, top-down approaches count the number of positive and negative words (or tokens) and do not make such classification. The sentences “I love coke, it is the best soft drink in the world” and “I love coke, it is the greatest, best and most awesome drink in the world” is classified as positive by a bottom-up approach that does not distinguish between the degree of expressed positivity and thus does not consider the strength of the sentiment. A top-down approach assigns a positive sentiment score of 0.17 to the first sentence and a positive sentiment score of 0.28 to the second sentence, making both comparable. 5
These magnitudes may have biases as words within a category (e.g. positive sentiment) may express different degrees of positivity due to the differences between “best”, “greatest” and “most awesome,” which all account for different magnitudes. Bottom-up approaches are also able to account for sentiment magnitude with the help of training data that contain information on the magnitude of sentiment. Even in case of classification orientated machine learning techniques, one may use the classification likelihood as provided by e.g. support vector machines to determine the magnitude of a sentiment within a text file.
To predict consumer mindset data that is only (or at best) available on daily (mostly monthly) level, sentiment data must be aggregated to match the mindset data. Although research has explored different ways to achieve this, the optimal method remains unclear. Therefore, we also test which form of aggregation is most suitable for a given product, brand, and industry setting. First, we can use the number of positive and negative comments per day as separate variables (You, Vadakkepatt, & Joshi, 2015). This method is similar to common social media metrics that sum the number of likes, comments or shares that a post receives per day. Second, the number of sentiment-neutral comments, which typically exceeds that of both positive or negative sentiment comments, may contain valuable information for brand metrics (Pauwels, Aksehirli, & Lackman, 2016). To capture this information, we include the number of neutral comments as a variable in our analysis. However, this approach does not account for the proportion of positive and negative comments relative to the overall volume. Thus, we may misinterpret a change in positive or negative comments because we do not know its relative importance in all comments. We capture this information in our third approach – that divides each of the number of positive and negative comments per day by the total number of comments.
Conceptual Framework: When Would more Effortful SETs Explain Attitudes Better?
Fig. 1 shows our conceptual framework, which combines the contingency factors of brand strength (Keller, 1993) with the search/experience nature of the category (Nelson, 1974) and the pre- versus post-purchase stages in the Consumer Purchase Journey (Lemon & Verhoef, 2016). Our main argument is that the need for sophisticated, effortful SETs increases with the license social media posters perceive to use unclear, sophisticated language in their brand discussions.

Conceptual framework.
Starting at the bottom left quadrant of Fig. 1,
In contrast, brands in
Moving to
Finally,
In sum, we have several expectations, as summarized in Fig. 1, but the picture is complicated by the many stages of the customer decision journey and potential contingency factors. For instance, the relative value of sentiment classification could well depend on whether average sentiment expressed in the industry is mostly negative or positive—a factor that cannot readily be assessed before applying the SETs. Therefore, we set out to estimate the explanatory power of each SET for each stage and to explore the impact of brand and category factors and their interactions in a contingency analysis, as detailed below.
Data
We construct our time series variables by merging two separate data sets that have observations collected for different time frequencies (see Table 1 for details on the data and variables). Social media data are obtained from each brand's official presence on Facebook. Consumer mindset metrics are collected from YouGov group and are available for a daily frequency. As social media data come at a high frequency (any point during a day), we aggregate social media data to the level of daily frequencies prior to merging the two data sets.
Measures and data sources.
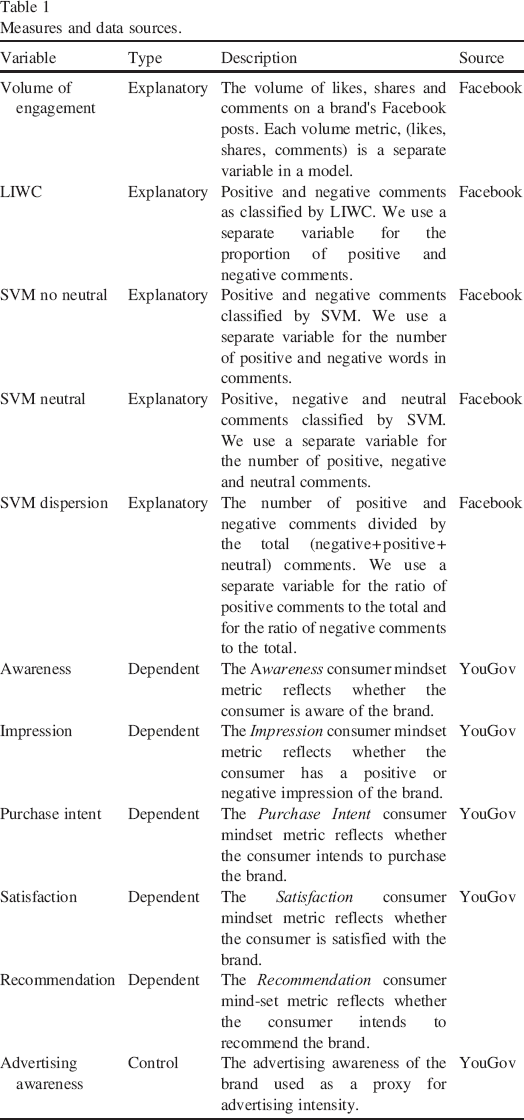
We successfully obtained comprehensive data for the 8 industries (airlines, banking, beverages, cars, consumer electronics, fashion, food and gastronomy) and 48 brands listed in Table 2.
Brand sample.
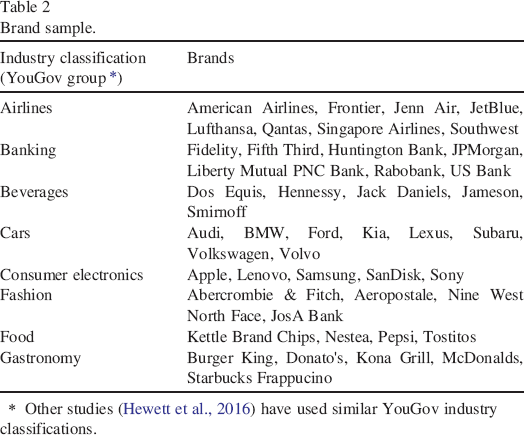
Other studies (Hewett et al., 2016) have used similar YouGov industry classifications.
Although all of the included brands have existed for a while, they differ in consumer awareness (e.g., 91% for American Airlines vs. 33% for Singapore Airlines according to YouGov), just as the industries differ in average sentiment (negative for airlines and banking while neutral or positive for the other industries). The final data set includes the period from November 2012 to June 2014, with 27,956 brand-day observations for the 48 unique brands.
Social Media Data
To collect social media data, we developed a crawler to extract all public information on the official Facebook page of each brand. Although future research may compare SETs on other platforms, Facebook is a good choice for maintaining the focus of the analysis on the same platform. As the largest social media platform, Facebook provides a dynamic environment for brand-consumer interactions. We collect more than 5 million comments on brand posts for our sample of brands and extract the sentiment from this textual data.
SET Application to Social Media Data
We collect classic pre-SET volume-based metrics with the help of Likes, Comments, and Shares of diverse Facebook content directly from Facebook's API. As the number of likes, comments and shares given to corporate posts on a company's Facebook page may also depend on the frequency a company posts, we additionally collect all posts from users on a company's Facebook page and count for these posts also the likes, comments, and shares.
We use the most frequent top-down approach available on the market: LIWC. LIWC provides word lists for 21 standard linguistic dimensions (e.g., affect words, personal concerns). To ensure a balanced set of sentiments we only use the general positive and negative sub-dimensions provided by LIWC. For each brand we export the extracted user posts and comments directly to LIWC that counts for each post and comment the number of positive and negative words and divides each by the number of total words per post or comment.
For our bottom-up approach, we collected 15 million context specific Amazon product reviews as training data. For each industry we construct context-specific training sets with reviews originating from each product category. To ensure that we only include very positive and very negative reviews, we further only rely on reviews with very low star rating (1) and very high star ratings (5). All other reviews are dropped from the training set. Then we proceed with standard NLP procedures as described in “Bottom-up Approaches”. For each product category we train a specific SVM. In addition, we collected for each category more 1- and 5-star reviews as a holdout sample (with 20% size of the training data). To test the accuracy of our category specific SVMs we predicted for the reviews in our hold out sample whether they were positive or negative. Hold out accuracies ranged from 80% to 92%, which we take a strong evidence that our SVMs have sufficient classification power. Web Appendix A and B provide details on brand sample composition, the training data and the hold out prediction accuracy.
To measure sentiment of user comments, we apply each trained category specific SVM to its corresponding user posts and comments. The trained SVM then classifies each post and comment to be either positive or negative. The SVM build into the RTextTool package further provides a classification likelihood for each post and comment. In case that a classification likelihood falls below 70% we follow Joshi and Tekchandani (2016) and believe the post or comment to be neither positive nor negative, but neutral and mark them correspondingly. We then aggregate sentiments by first building the daily sum for positive, negative and neutral comments, and further calculate the share of daily positive to total and negative to total comments, which we refer to as SVM Dispersion, a measure that is comparable to the top-down approaches’ relative sentiment measure that similarly divides the number of positive or negative words in a post or comment by the total number of words in this post or comment.
Consumer Mindset Metrics
We have access to a unique database from the market research company, YouGov group, which provides a nationwide measurement of daily consumer mindset metrics. Through its BrandIndex panel (http://www.brandindex.com), YouGov monitors multiple brands across industries by surveying 5,000 randomly selected consumers (from a panel of 5 million) on a daily basis. To assure representativeness, YouGov weighs the sample by age, race, gender, education, income, and region.
YouGov data have been previously used in the marketing literature (Colicev et al., 2018; Colicev, O'Connor, & Vinzi, 2016; Hewett, Rand, Rust, & van Heerde, 2016) and exhibit at least four advantages. First, such survey data are considered an appropriate analytical tool in marketing research (e.g., Steenkamp & Trijp, 1997) and have been shown to drive brand sales (Hanssens et al., 2014; Pauwels, Aksehirli, & Lackman, 2016; Srinivasan, Vanhuele, & Pauwels, 2010). Second, the YouGov panel has substantial validity, as it uses a large and diverse set of consumers that captures the “wisdom of the crowd” and between-subject variance. In recent comparisons with other online surveys, YouGov emerged as the most successful (FiveThirtyEight, 2016; MacLeod, 2012). Third, YouGov administers the same set of questions for each brand, which assures consistency for each metric, and, in any single survey, an individual is only asked about one measure for each industry; thus, reducing common method bias and measurement error. Finally, YouGov data are collected daily, thereby rapidly incorporating changes in consumer attitudes towards brands. As a result, YouGov data overcomes many of the normal limitations of using survey data, specifically the difficulty and expense of recruiting a sufficient number of participants and the challenges of low frequency and outdated data (Steenkamp & Trijp, 1997).
We use five common mindset metrics that capture the consumer purchase funnel/decision journey: awareness, impression, purchase intent, satisfaction and recommendation (details on the exact items and data collection are provided in Web Appendix C). “Awareness” reflects general brand awareness, “impression” captures brand image, “purchase intent” indicates purchasing intentions, “satisfaction” captures general satisfaction with the brand, and “recommendation” captures brand referrals. Given its importance in prior literature (Srinivasan, Vanhuele, & Pauwels, 2010), we also include a control variable, YouGov's metric, “Advertising Awareness,” as a proxy for brands’ advertising expenditures. At the aggregate brand level, the scores on the measures from YouGov fall within the range of − 100 to + 100. For customer satisfaction, as an example, the extremes are only realized when all respondents agree in their negative or positive perception of the brand relative to its competitors. The daily measures of mindset metrics are based on a large sample of 5,000 responses; this approach helps to reduce sampling error.
Method
Overview of the Approach
As depicted in Fig. 2, our analysis consists of a set of several methodological steps.
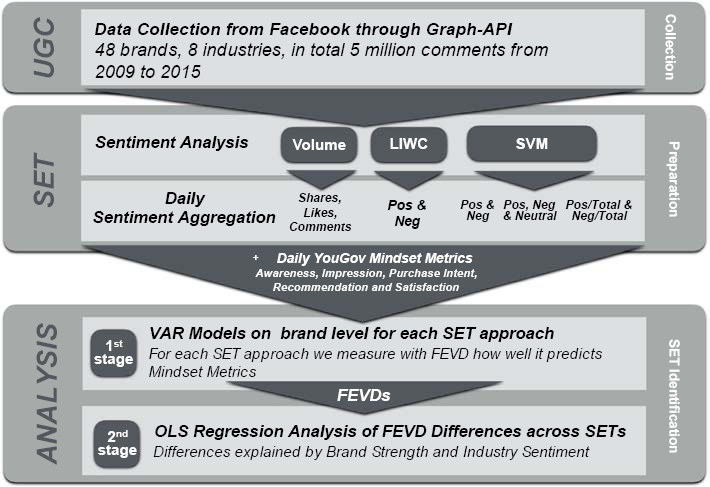
Overview of data and analysis.
Our choice of econometric model is driven by the criteria that it can (1) account for the possibly dynamic nature and dual causality of the relations between SET metrics and the various consumer mindset metrics and (2) uncover which form of SET best explains consumers’ mindset over time for each brand (whose time period of data availability may not completely overlap with that of other brands). Therefore, we estimate a vector autoregressive (VAR) model per brand (Colicev et al., 2018; Ilhan, Kübler, & Pauwels, 2018). VAR accounts for the potential endogeneity between social media and consumer mindset metrics while controlling for the effects of exogenous variables that could potentially affect both metrics (e.g., advertising). In addition, VAR provides a measure of the relative impact of shocks that are initiated by each of the individual endogenous variables in a model through forecast error variance decomposition (FEVD). This measure allows us to compare the relative performance of different SETs for the explained variance in consumer mindset metrics (Srinivasan, Vanhuele, & Pauwels, 2010).
For the sentiment variables, we have five different SETs to assess sentiment: (1) the Volume (number) of likes, comments and shares of brand posts, and, for the comments, the sentiment analysis of (2) LIWC, (3) SVM (without the neutral sentiment comments), (4) SVM Dispersion (adjusted for sentiment dispersion), and (5) SVM Neutral (with the neutral sentiment comments). We estimate a separate VAR model for each brand that relates one SET at a time to five mindset metrics: awareness, impression, purchase intent, satisfaction and recommendation. We also estimate SET combinations in Models 6–9, with Model 6 combining Volume and SVM Neutral, Model 7 Volume and LIWC, Model 8 LIWC and SVM Neutral and Model 9 Volume, LIWC and SVM Neutral. Finally, we check the per-metric performance and combine them into a unifying model, Model 10. Thus, in total, we estimate 10 different models for each of the 48 brands, which results in 480 VAR models.
To evaluate how each SET explains the dynamic variation in each mindset metric for each brand, we use FEVD, as in Srinivasan, Vanhuele, and Pauwels (2010). Next, we aggregate the FEVD across all five consumer mindset metrics to form an aggregated measure of performance of the SETs across both brands and mindset metrics. Thus, in this step, we can assess (a) the performance of SETs individually for each brand and (b) the performance of SETs aggregated across all brands.
In the second step, we use the brand-level FEVD scores in a second-stage regression to establish the brand and industry characteristics that can explain the relative performance (FEVD) of SETs. Our dependent variable is the
We compute the brand strength as the average of the studied mindset metrics over our period of investigation. For example, when the quality score that was mentioned above is assessed for the explanatory power of the awareness mindset metric, we use the average awareness score for the brands over the investigation period. We note that our sample is mostly composed of strong brands and thus our brand strength metric is relative. For industry sentiment, we compute the average industry sentiment for each industry over the investigation period. This results in a measure that reflects whether the sentiment in the industry is more negative (e.g., banks) or positive (e.g., fashion). For search/experience nature of the category we split the sample into search (airlines, beverages, consumer electronics and clothes) and experience categories (banking, cars, food and gastronomy) – following the taxonomy in Zeithaml (1981).
Econometric Model Specification
Based on the unit root tests, we specify a VAR in levels for each brand/SET combination. Eq. (1) shows the specification for SET Volume, which is captured by three variables: number of likes, comments and shares:

For the model specification for the other SETs, we replace the three volume metrics in Eq. (1) with the corresponding metrics in the SET. In this respect, Model 2 has SVM without neutral comments, Model 3 LIWC, Model 4 SVM Dispersion, Model 5 SVM with neutral comments. Then, we combine different SETs in the same model estimation. Accordingly, Model 6 has Volume and SVM Neutral (6 variables), Model 7 Volume and LIWC (5 variables), Model 8 LIWC and SVM Neutral (5 variables), Model 9 Volume and LIWC and SVM Neutral (8 variables) and Model 10 Best predictive combination of three variables.
Note that the SETs Volume (Model 1) and SVM Neutral (Model 5) have 3, while the others have 2 variables. A larger number of variables typically implies an advantage for in-sample fit (R2 and FEVD) and a disadvantage for out-of-sample predictions (Armstrong, 2001). Thus, we also display the FEVD results of the model after dividing by the number of variables. Please refer to Web Appendix D for details on model specification.
Impulse Response Functions (IRF) and Forecast Error Variance Decomposition (FEVD)
From the VAR estimates, we derive the two typical outputs of IRFs; tracking the over-time effect of a 1 unit change to a SET metric on the attitude of interest; and the attitude's FEVD, i.e., the extent to which it is dynamically explained by each SET metric (see Colicev, Kumar, & O'Connor 2019). To obtain prototypes of IRFs that account for similar and consistent patterns across companies and contexts, we use a shape-based time series clustering approach that highlights an average, centroid IRF for each identified cluster (for more details see Mori, Mendiburu, & Lozano, 2016). While IRFs are not central to our study, they still provide a good metric on the direction and significance of the effects of SETs on mindset metrics.
The central metric for our study is the FEVD which allows us to compare the variance explained by each SETs in each mindset metric. First, FEVDs fit well with the purpose of the study which is to generate comparative results across SETs and mindset metrics. Second, previous research has used FEVD for similar purposes (see for e.g., Srinivasan, Vanhuele, & Pauwels, 2010 where they compare the explanatory power of different metrics). Third, FEVDs also allow us to abstain from directions of the effects (as in IRFs) and focus on explanatory power over time. Indeed, we evaluate FEVDs at 30 days to reduce sensitivity to short-term fluctuations.
We use the Cholesky ordering based on the results from the Granger causality tests to impose a causal ordering of the variables. To prevent the effects of this ordering on the results, we rotate the order of the endogenous variables and compute averages over the different responses as a consequence of one standard deviation shocks (e.g., Dekimpe & Hanssens, 1995). To assess the statistical significance of the FEVD estimates, we obtain standard errors using Monte Carlo simulations with 1,000 runs (Nijs, Srinivasan, & Pauwels, 2007). For each SET, we sum the variance of its metrics to calculate the total percentage of the mindset metric that is explained by the SET. Moreover, as some SETs have more variables than others, we also calculate and compare the FEVD per SET variable.
Second-Stage Regressions
In Eq. (2) below, we show the second-stage estimation for the difference between SVM Neutral (best performing SET) and Volume metrics for each consumer mindset metric:
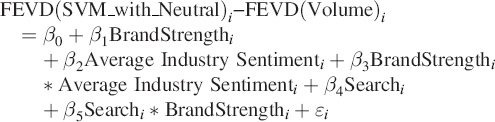
Results
Descriptive Statistics
In Table 3, we present the correlations among the variables (averaged across brands).
Correlations among model variables (average across brands and SET variables).
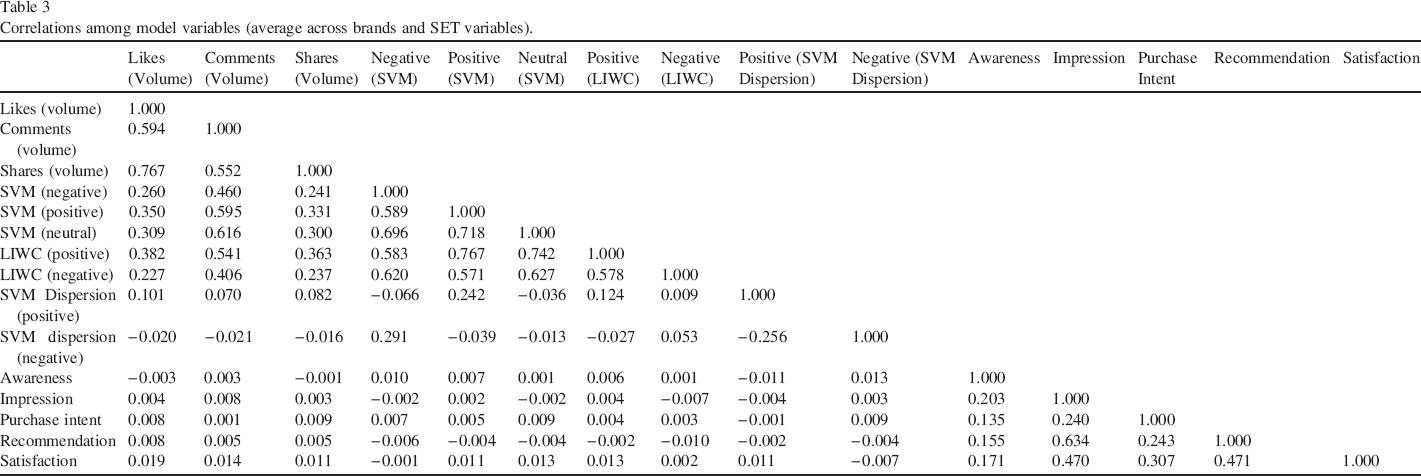
First, the volume and sentiment variables have a moderate correlation with the mindset metrics, with the strongest correlation being between satisfaction and volume (0.019). This reflects previous research that online sentiment does not fully overlap with mindset metrics in the broader consumer population (Baker, Donthu, & Kumar, 2016; Lovett, Peres, & Shachar, 2013; Ruths & Pfeffer, 2014). The correlation among SET metrics is higher (up to 0.767 for LIWC positive and SVM positive) but not perfect, which highlights the importance of researchers’ SET choice. Finally, the correlations among the pre-purchase mindset metrics is moderate (0.14–0.24), which reflects their divergent validity. Naturally, the post-purchase metrics satisfaction and recommendation have a higher correlation.
VAR Model Fit and Lag Selection
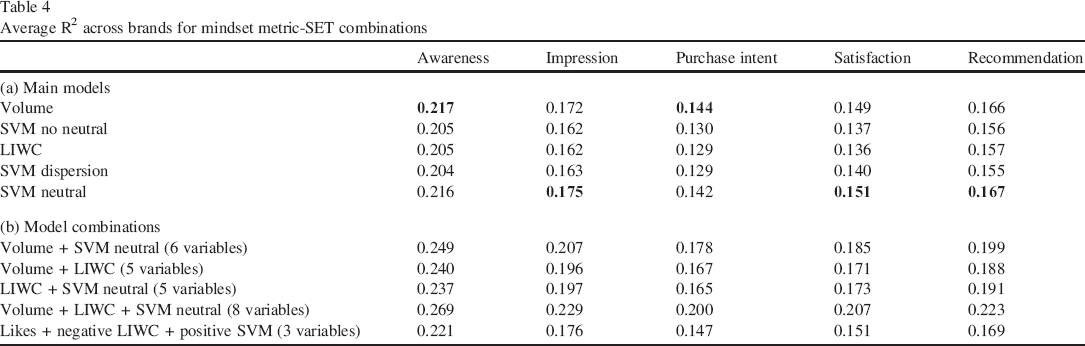
All VAR models passed the tests for descriptive models according to Franses (2005), and the SETs explained between 13% and 22% of the daily variation (R2) for each mindset metric (Table 4). As expected, SETs have a tougher time explaining purchase intent than awareness. As shown in Table 4a, SVM Neutral and Volume have the highest average R2 across all mindset metrics. Table 4b shows how explanatory power improves by combining different SETs, with the Model 9 combination (volume metrics + LIWC + SVM with neutral) explaining at least 20% of each mindset metric. All brand level-results are available in Web Appendix E.
Average R2 across brands for mindset metric-SET combinations
The Impact of SET Metrics on Consumer Mindset Metrics: Impulse Response Functions
The IRFs show that all effects of SET metrics on consumer attitudes stabilize within a month, most within 10 days. As an illustration, Fig. 3 contrasts the impact of volume metric Likes with that positive top-down (LIWC) on each consumer attitude for the major clusters.
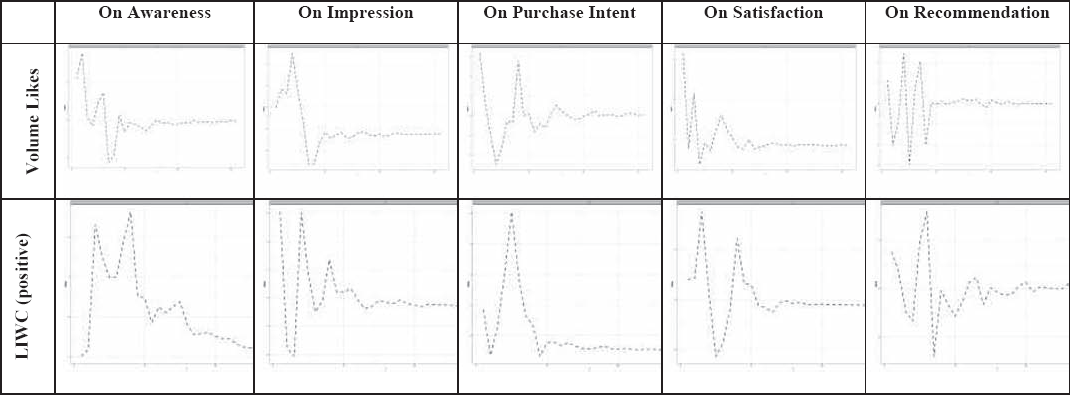
Impulse response functions of sentiment extraction metrics on attitudes.
For first four of stages Awareness, Impression, Purchase Intent and Satisfaction, Likes have a strong initial effect and a fairly typical decay pattern. In contrast, the effect on Recommendation oscillates wildly from first day, indicating that Likes have little explanatory power for this post-purchase stage (as verified in the FEVD). Meanwhile, positive sentiment (as classified by LIWC) shows the typical over-time impact on Recommendation. Across consumer attitude metrics, the peak impact of positive LIWC sentiment occurs later than the peak impact of Likes. This points to the key importance of assessing
Relative Importance of Metrics: Forecast Error Variance Decomposition (FEVD)
We aggregate the results across brands in Table 5.
FEVD results for main models.
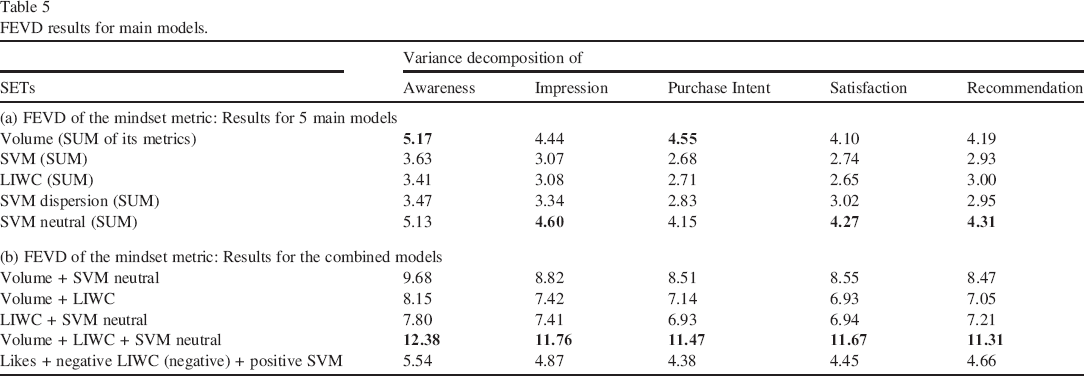
Across all analyzed brands, we find that SET Volume and SVM Neutral have the highest FEVD for all mindset metrics. SVM Dispersion performs well for impression, and LIWC for recommendation. These findings indicate that contingency factors may affect the explanatory power of SETs. For the combination of SET models, Table 5b shows that Model 9 (Volume + LIWC + SVM Neutral) obtains the highest averaged FEVD across brands. Table 6 further provides a summary of our main findings for each mindset metric and industry highlighting that different SETs might be suitable for different industries and metrics.
Summary of the main findings.
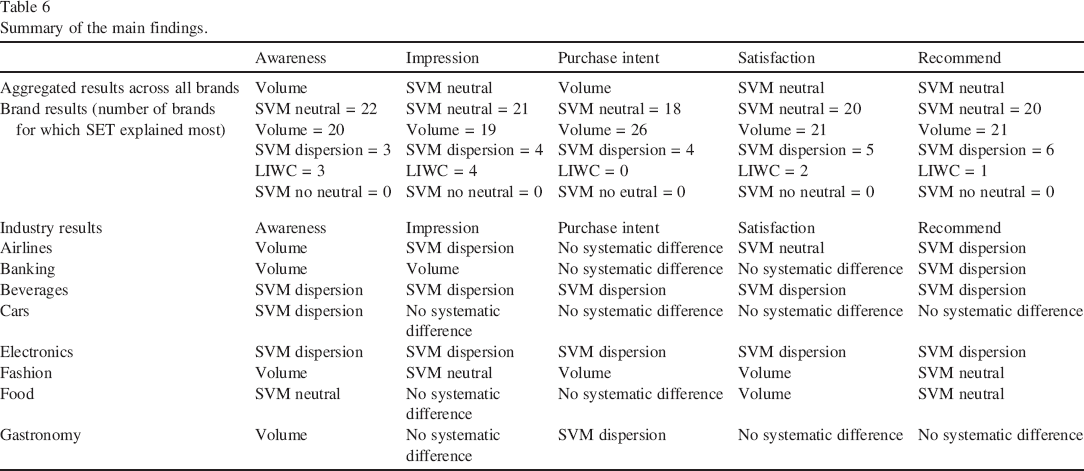
Beyond these average results, we observe heterogeneity across brands for which SETs explain the most variance. For example, for awareness, SVM Neutral has the highest explanatory power for 22 brands, Volume for 20 brands, SVM Dispersion for three brands and LIWC for three brands. Therefore, we further investigate the results by (1) relating them to brand and industry factors in our second stage and (2) reporting them by industry.
Second-Stage Analysis
The coefficient estimates and standard errors for the second-stage analysis are shown in Table 7.
Second-stage regressions of forecast error variance decompositions (FEVD).
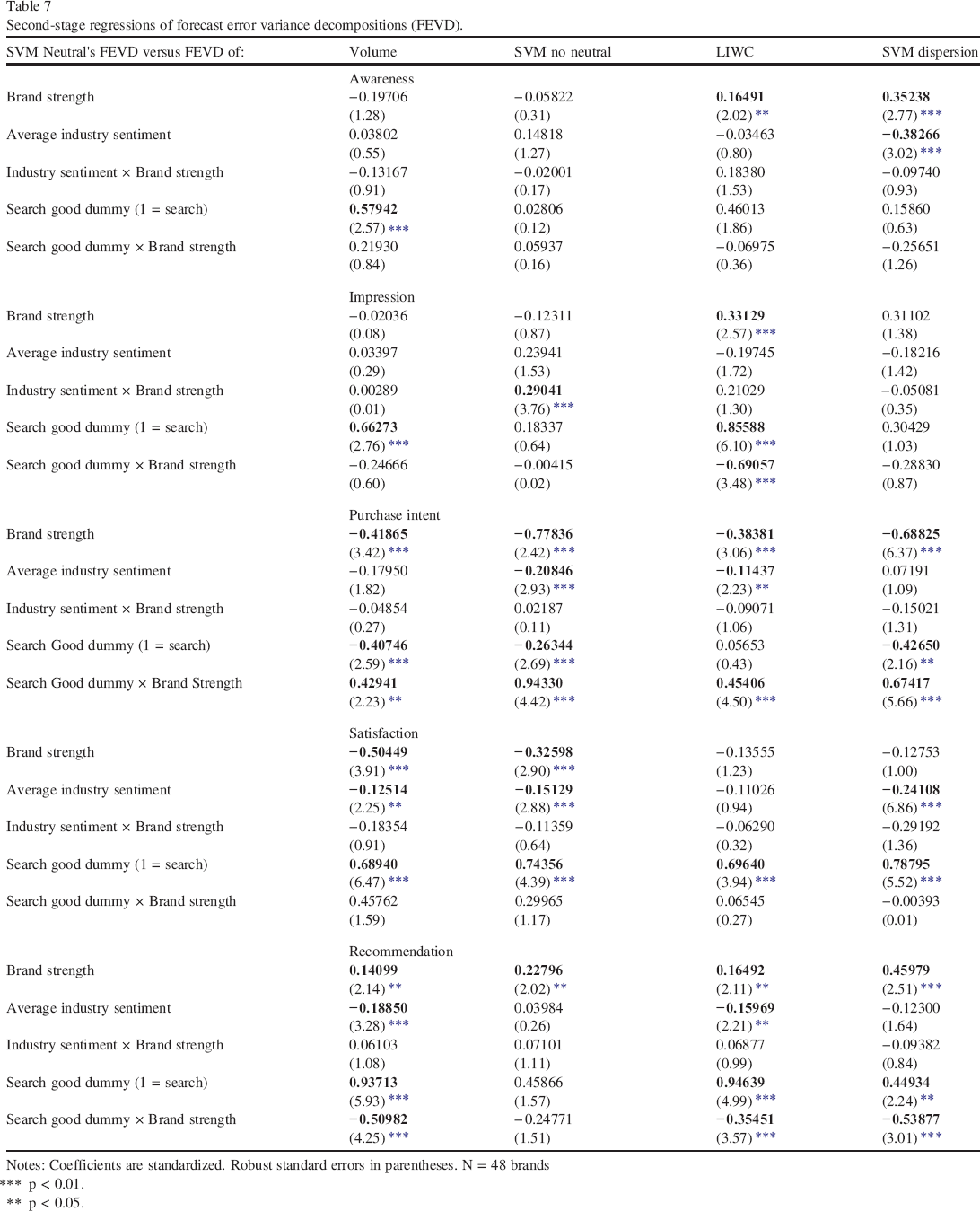
Notes: Coefficients are standardized. Robust standard errors in parentheses. N = 48 brands
p < 0.01.
p < 0.05.
The results vary across the four quality difference scores and mindset metrics, thus enhancing the ability to predict tactical decisions for the advantage of various SETs. Brand Strength and the Search/Experience nature of the category appear as the most important moderators for the explanatory power of SVM Neutral over alternatives. As to the former, Awareness over LIWC (0.16, p < 0.05) and SVM dispersion (0.35, p < 0.05); Impression over LIWC (0.33, p < 0.05); Recommendation over all SET alternatives (0.14, 0.23, 0.16 and 0.46, respectively).
In contrast,
As to the nature of the category, SVM Neutral has a higher explanatory power over alternative SETs for
When
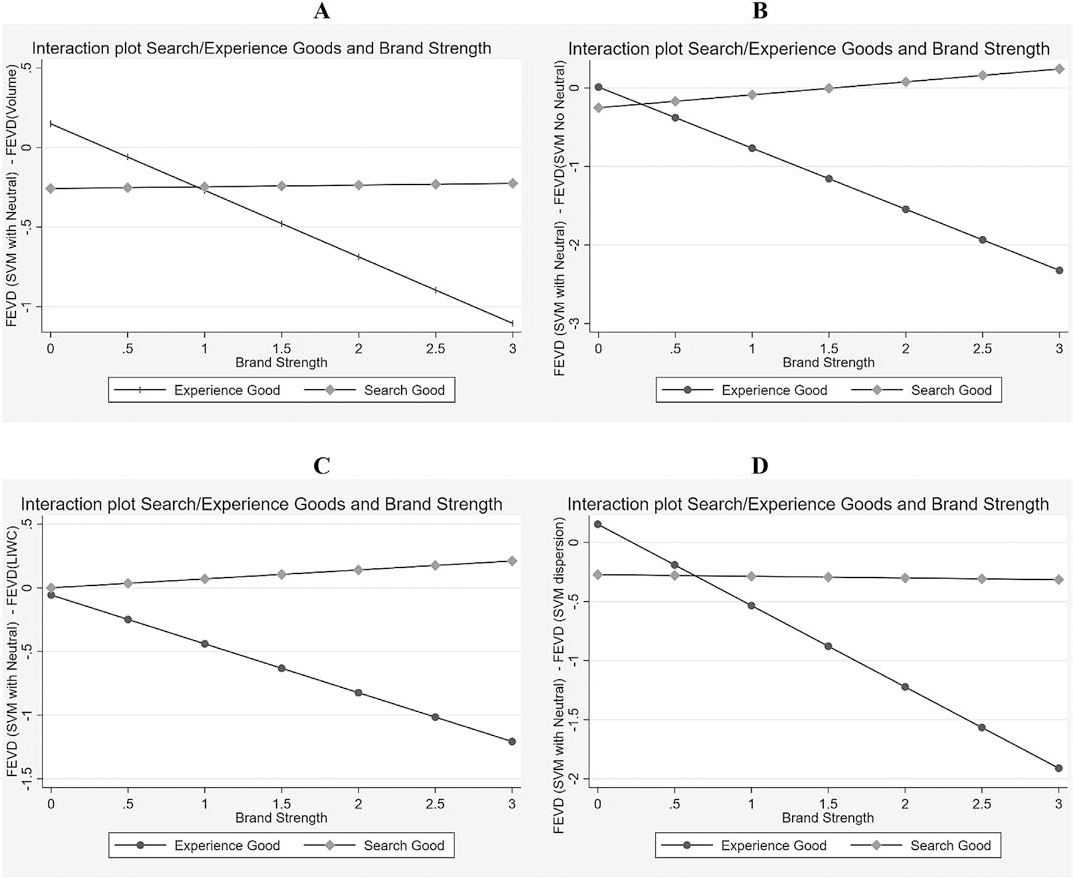
Interaction plots of the second-stage regression. Purchase intent.
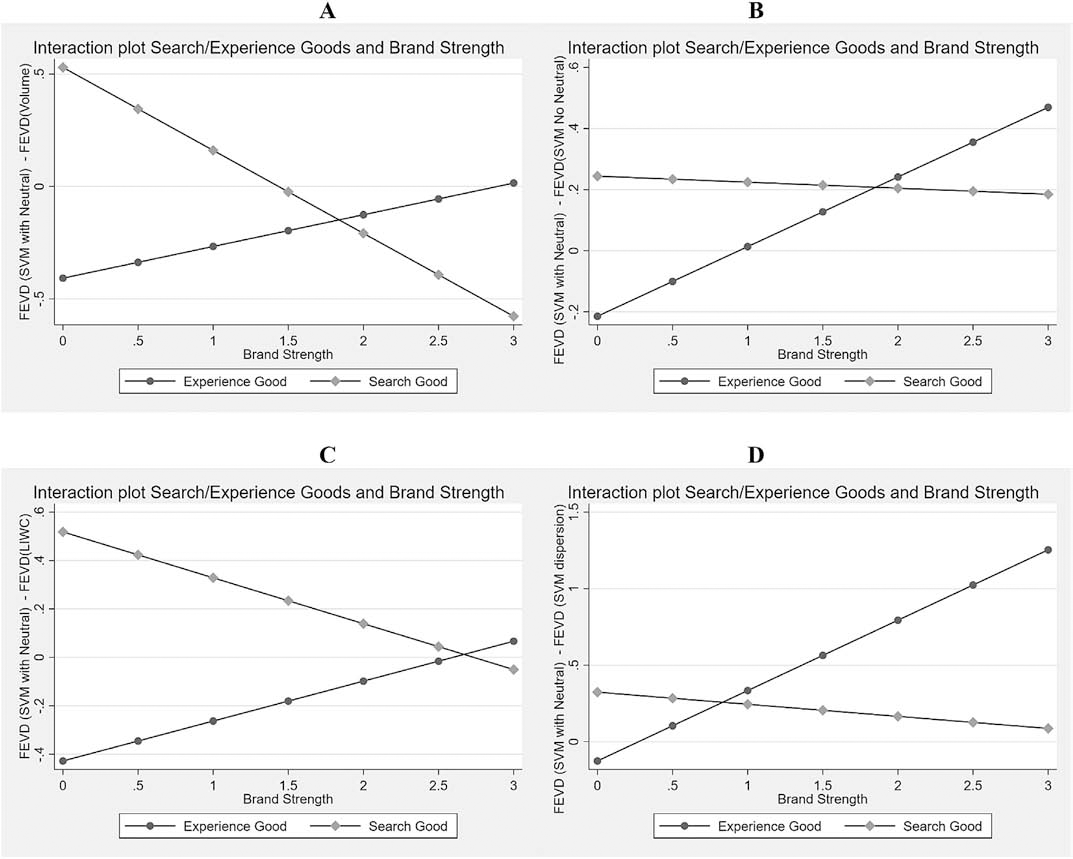
Interaction plots of the second-stage regression. Recommendations.
For purchase intent, results indicate that relatively stronger brands of experience goods should not use SVM No Neutral as their SET. In contrast, SVM No Neutral dominates over other alternatives for relatively weaker brands of experience goods and for stronger brands of search goods. For example, Panel 3A shows that SVM Neutral improves over Volume only for relatively weaker brands of experience goods. Panel 3B shows that SVM Neutral dominates SVM No Neutral for strong brands of search goods. Panel 3C shows the dominance of LIWC over SVM Neutral for Experience goods, especially when the brand is strong. For Recommendation, panel 4A shows a higher benefit of SVM Neutral for relatively weaker brands of search goods, but a higher benefit of Volume metrics for both relatively weaker brands of experience goods and relatively stronger brands of search goods. Finally (panel 4C), LIWC explains more of Recommendation when the relatively weaker brand is an experience good, while SVM Neutral does better when the relatively weaker brand is a search good. For the relatively stronger brands, LIWC and SVM Neutral have a similar power to explain Recommendation.
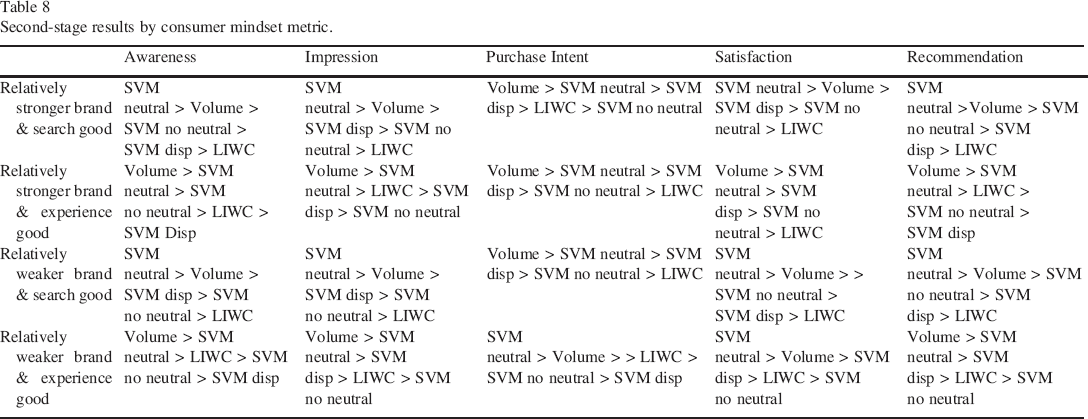
To give concrete managerial insights into these conditions, we display the rank order of the analyzed SET tools in the 20 cells of Table 8 and summarize the latter insights in a 2 × 2 in Table 9.
Second-stage results by consumer mindset metric.
Overview and brand examples of the contingency findings.
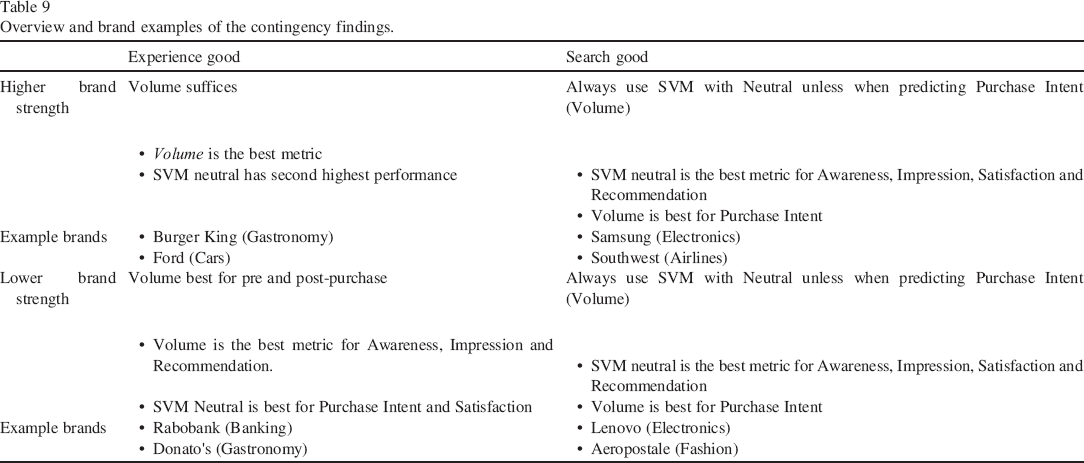
Table 8 shows the dominance of SVM Neutral and Volume SET alternatives for all attitude metrics and brand/category split-half combinations. SVM Neutral is better than Volume for search goods, with the exception of explaining Purchase Intent. For experience goods, Volume metrics typically yield the highest explanatory power, with the exception of Purchase Intent and Satisfaction for relatively weaker brands. This is consistent with a general “sentiment clarity” explanation: social media commenters use clear language when talking about recommendation and purchase intent for experience product—especially for relatively weaker brands that are less known to the public. In contrast, they can use subtle innuendos for relatively stronger brands and for search products.
Consistent with our conceptual framework in Fig. 1, but now more detailed thanks to empirical evidence, Table 9 further summarizes the results in a 2 × 2 matrix. For managers in search categories, bottom-up approaches such as SVM-with neural yield the highest explanatory power for each attitude measure apart from Purchase Intent for which they are advised to use the pre-SET volume metrics. In contrast, managers of relatively stronger brands in the experience goods category get the highest explanatory power for volume SETs. For relatively weaker brands in such category, managers should Volume to predict Awareness, Impression and Recommendation and use SVM with neutral to predict Purchase Intent and Satisfaction. Our findings thus allow brand managers in such conditions to focus on the most appropriate metrics in explaining brand attitudes.
Additional Analysis
Conclusions
This paper is the first to compare how different SETs perform in explaining consumer mindset metrics. Thus, it guides marketing academic researchers and company analysts in their SET choices. We reviewed the origins and algorithms of these SETs and compared the most prominent versions for 48 unique brands in 8 industries. Using the most readily available pre-SET volume-based metrics, we collected the number of likes, comments and shares of brand posts. Next, we employed the frequently used dictionary top-down approach (LIWC) and a in the industry frequently used bottom-up approach (SVM) to extract
We show that there is no single method that always predicts attitudes best – a finding consistent with our expectations and the general conclusion by Ribeiro, Araújo, Gonçalves, André Gonçalves, and Benevenuto (2016) comparing among top-down approaches. On average, the most elaborate bottom-up approach of SVM Neutral has the highest R2 and FEVD (dynamic R2) for brand impression, satisfaction and recommendation, while SET Volume of likes, comments, and shares has the highest R2 and FEVD for awareness and purchase intent. Combining SETs yields a higher explanatory power and dynamic R2.
Our findings systematically vary by mindset metrics, by brand strength, by the type of good (search vs experience good) and by industry sentiment. Volume metrics explain the most for brand awareness and Purchase Intent (Table 5) while bottom-up Support Vector Machines excel at explaining and forecasting the brand impression to satisfaction and recommendation.
When brands are both relatively stronger and part of experience goods category, they should use pre-SET volume metrics for explaining all consumer mindset metrics. For relatively weaker brands of experience goods, it is still worth using SVM with neutral comments to predict Purchase Intent and Satisfaction. In contrast, if relatively weaker brands are part of a search good category, they should invest resources for adding neutral comments to their SVM. This is particularly important for Recommendation metric. Given that product recommendations are key for search goods, relatively weaker brands can largely benefit from more complex bottom-up SETs.
Summing up, the most nuanced version of bottom-up SETs (SVM with Neutral) performs best for search goods for all consumer mind-set metrics but Purchase Intent for which Volume metrics works best. For experience goods, Volume outperforms SVM with Neutral.
How could these insights be operationalized in a company environment? First, managers should decide how precisely they want to explain and forecast customer mindset metrics. Previous studies have shown the substantial impact of these metrics on brand sales and company stock performance (e.g., Colicev et al., 2018; Srinivasan, Vanhuele, & Pauwels, 2010), but the extent to which better explanations and forecasts improve decisions is up to each company. This knowledge will help managers make cost–benefit tradeoffs among the different metrics. Volume metrics are the least expensive to obtain and perform well for explaining awareness and purchase intent. Likewise, the language dictionary of LIWC efficiently explains brand recommendation, especially for relatively stronger brands. However, both SETs are outperformed by more sophisticated machine learning techniques for explaining other metrics, especially for smaller brands. Managers of these brands should make an informed tradeoff between cost and a more nuanced understanding of sentiment in social media.
The limitations of the current study also provide avenues for future research. First, the data should be expanded to marketplace performance metrics, such as brand sales and/or financial market metrics, including abnormal stock returns (KatsikeasMorgan, Leonidou, & Hult, 2016; Hanssens & Pauwels, 2016). We expect that our results can be generalized to these ‘hard’ performance metrics because they have been quantitatively related to consumer mindset metrics in previous research (Hanssens, Pauwels, Srinivasan, Vanhuele, & Gokhan, 2014; Srinivasan, Vanhuele, & Pauwels, 2010). Second, researchers can include other social media platforms, such as blogs, microblogs and image-based platforms (e.g., Instagram). Third, newly emerging versions of our studied SETs as well as other specifications should be compared against existing options. We encourage future research to examine the suitability of more distinguished top-down approaches that rely on finer and richer dictionaries (e.g., NRC) or to focus on nuances within existing dictionaries. Likewise, though results across studies about the suitability of Random Forests and Deep Learning remain inconsistent, we encourage future research to benchmark these new and upcoming methods with the ones used in this study. Furthermore, a broader set of brands and countries would facilitate the testing of further contingencies. At a deeper level, we encourage further research to directly infer customer attitude from the underlying text, which would require either training data with a direct link between attitude and text (for bottom-up approaches), or a dictionary with synonyms of “purchase intent,” “aware,” etc. (for top-down approaches). Finally, the creation of user generated content is not equally distributed among brand-owned Facebook pages. Some brands (e.g., Audi) allow users to post on their official presence, while other brands (e.g., JP Morgan) only allow users to comment (and not post) in reply to the brand's posts. Future research might investigate how these differences in posting rights can affect the distribution of positive and negative content on brand's Facebook pages.
Social media has become an important data source for organizations to monitor how they are perceived by key constituencies. Gaining useful and consistent information for these data requires a careful selection of the appropriate sentiment extraction tool.
Footnotes
Supplementary data
Supplementary data to this article can be found online at https://doi.org/10.1016/j.intmar.2019.08.001.