
Abstract
Repeated assessments of personality states in daily diary or experience sampling studies have become a more and more common tool in the psychologist's toolbox. However, and contrary to the widely available literature on personality traits, no best practices for the development of personality state measures exist, and personality state measures have been developed in many different ways. To address this, we first define what a personality state is and discuss important components. On the basis of this, we define what a personality state measure is and suggest a general guideline for the development of such measures. Following the ABC of test construction can then guide the strategy for obtaining validity and reliability evidence: (A) What is the construct being measured? (B) What is the intended purpose of the measure? And (C) What is the targeted population of persons and situations? We then conclude with an example by developing an initial item pool for the assessment of conscientiousness personality states. © 2020 The Authors. European Journal of Personality published by John Wiley & Sons Ltd on behalf of European Association of Personality Psychology
Most personality theories suggest that personality can be described using a number of entities that all have a unique stable component, personality traits, and also variable aspects, personality states, that fluctuate from moment to moment (Baumert et al., 2017; Funder, 2001; Wrzus & Mehl, 2015). To put these theories to the test and to disentangle the effects of traits and states, researchers frequently rely on experience sampling methods (Horstmann & Rauthmann, n.d.; Wrzus & Mehl, 2015). In many such cases, participants first respond to a one–time assessment of their personality traits and general characteristics, often based on self–report. Subsequently, participants are invited to report their daily behaviour over a longer period of time, for instance, every 3 hours or whenever certain events occurred (Horstmann, 2020). Based on the data collected, theories regarding the interplay between states and traits can be tested. For example, whole trait theory (Fleeson, 2001) postulates that, on the descriptive side, states, repeatedly assessed within one person, should form density distributions of behaviour and that the average personality state should therefore, roughly, correspond to the personality trait of that person. Testing this theory thus requires a repeated assessment of personality states. Yet despite all the theory and studies already existing, state assessments are often constructed in a rather ad hoc manner. In comparison with the abundance of guidelines to construct trait measures (AERA, APA, & NCME, 2014; Borsboom, 2006; Borsboom, Mellenbergh, & van Heerden, 2004; Cronbach & Meehl, 1955; Loevinger, 1957; Messick, 1980, 1995; Ziegler, 2014), similar literature just begins to emerge for state assessments (Himmelstein, Woods, & Wright, 2019; e.g. Hofmans, De Clercq, Kuppens, Verbeke, & Widiger, 2019; Wright & Zimmermann, 2019; Zimmermann et al., 2019). This does, to our knowledge, apply not only to personality state measures but also to experience sampling items more generally. The current paper aims at providing a first set of such guidelines to further establish quality state assessments and to spur the development of quality standards for state assessments.
Although the construction and psychometric evaluation of global self–reports have been routinely conducted over the past decades, following standard procedures, it is rather unclear how psychometric properties of repeated self–reports of personality states should be constructed and examined and to which benchmarks they should be compared. Although the psychometric properties of scores obtained with the experience sampling method have been discussed at some lengths (e.g. Schönbrodt, Zygar, Nestler, Pusch, & Hagemeyer, n.d.; Furr, 2009; Hektner, Schmidt, & Csikszentmihalyi, 2007; Moskowitz, Russell, Sadikaj, & Sutton, 2009; Nezlek, 2017), some aspects, such as construct validity evidence, were not considered in detail. Additionally, recent technological advancements, such as the ubiquity of smartphones, have increased the usage of experience sampling methods in personality psychology as well as the experience gained from this usage. Although many very interesting and impactful research findings could be obtained using state assessments in daily life, we would argue that there are so far only very limited guidelines regarding the psychometric evaluation as well as theoretical foundation of personality state scores. In the current article, we will first define what a personality state and a state measure is. We will then review current practices of evaluating evidence regarding state score's reliability and validity, and common reporting standards. Subsequently, we will formulate concrete expectations towards the kind of evidence needed to support state scores’ reliability and validity and provide an example for the construction of state items to assess conscientiousness states.
The Definition of a Personality State
In our opinion, the most crucial element for the construction of personality state measures is, first and foremost, the definition of (i) the phenomenon personality state and (ii) the specific personality state at hand. By (i), we refer to broader questions, such as ‘what is a personality state?’, ‘how is it related to a personality trait?’, and ‘under which circumstances does it occur?’. On the other hand, (ii) refers to the definition of a specific personality state, such as ‘extraversion states’ or ‘narcissism states’.
One of the most recent definitions of states (note, not personality states, but states in general) was suggested by Baumert et al. (2017): A state is a ‘quantitative dimension describing the degree/extent/level of coherent behaviors, thoughts and feelings at a particular time’, and a state level is ‘the individual momentary score on a scale measuring a state’ (p. 528). Baumert and colleagues further elaborate that state dimensions could be used to describe differences within a person as well as between persons and that states tend to fluctuate from one moment to another (compared with personality traits, which are rather stable over time). Although this definition of states does not explicitly require that states are linked to personality, we would argue that (i) most
So what constitutes the difference between a personality state and any other state? Personality states are explicitly linked to personality traits. Some have argued that this means that personality states must serve a specific purpose (Denissen & Penke, 2008) or function (M. Schmitt, 2009a) that is used to fulfil the need that arises from a specific standing on a personality trait. Schmitt (2009a) further elaborated that the quality of behavioural assessments (which, for now, we will equate with personality states, but see below for a discussion) depends on how well the definition of behaviour (i.e. personality states) is grounded in theory, that is, in what way it is linked to a well–defined nomological net. For example, a single personality state score such as choosing to agree five out of seven possible points to the statement ‘I am dancing wildly’ is most likely connected to the trait extraversion and thus considered an instance of extraverted behaviour. On the other hand, if a professional dancer in a dancing audition for
Consequently, there must be a distinction between instances of behaviour (Furr, 2009), such as watching TV, laughing, scratching ones nose, drinking tea, talking, and then again personality states, which are clearly located in the nomological net of the corresponding personality trait. Similar to emotions, the same instance of behaviour may have many different causes at different times, which is contrary to the current conception of personality traits (M. Schmitt, 2009a). Concerning personality traits, we assume that each trait is reflected in unidimensional indicators or an item in a trait questionnaire should only load on one single dimension. Contrarily, behaviours can be ‘factorially complex’ (Schmitt, 2009a, 2009b, p. 429). This means that one individual instance of behaviour may be caused by not only one personality trait but by several personality traits at the same time. It could even be argued that the same behaviour can be indicative of different traits in different situations, as exemplified above. Additionally, the expression of a personality trait, that is, the personality state, does not only depend on (multiple) characteristics of the person but may also be influenced by situational factors (Funder, 2006; Horstmann et al., in revision; Mischel & Shoda, 1995; Sherman et al., 2015). This means that a score on a state scale is linked not only to personality traits but also to situational factors. Consequently, state scores comprise several reliable variance sources [Equation 1], which is different to what is usually assumed for trait scores but similar to facet scores that also comprise two reliable variance sources: trait and facet (Ziegler & Bäckström, 2016). Thus, when looking at ways to estimate reliability and validity of behaviour based state scores, there is a need to decompose their variance into its constituents (M. Schmitt, 2009a, 2009b; Schönbrodt et al., submitted). Taken together, one can conclude that personality states are multi–determined. Accepting this definition of personality states has far–reaching consequences for the evaluation of their psychometric properties, as we will discuss below. However, not making things any easier, personality states are not only defined by current overt behaviour but also by thoughts and feelings.
Behaviour, Thoughts, and Feelings?
The previous definition by Baumert et al. (2017) defines states as ‘coherent behaviors, thoughts, and feelings’. From there, it follows that one must consider the behaviour, thoughts, and feelings of a person to fully understand the nature of a state. For example, a person may be dancing, thinking about how to dance, and feel stressed. This could mean that this personality state is a function of the trait conscientiousness; on the other hand, if a person danced, thought about how to dance, but felt positive, this might be a function of the trait extraversion. Wilt and Revelle (2015) have examined personality trait scales and concluded that personality traits (at least broad personality traits such as the Big Five) are operationalized with different components, namely, Affect, Behaviour, Cognition, and Desire. They concluded that some personality traits are mostly defined via affect (i.e. neuroticism), overt and observable behaviour (e.g. extraversion or conscientiousness), cognition (i.e. openness), or a mix of affect, behaviour, and cognition (i.e. agreeableness). At the same time, desire was not very present in the content of the examined Big Five items. Yet this means that if a personality state should represent the expression of a personality trait, these components must also be reflected in the state measure. The assessment of a personality state only via the (self–rated) behaviour at a certain point in time will therefore fall short. Instead, and to ensure that the personality state is located in the nomological net of the corresponding trait, the content of the state scale should also correspond to the content of the personality trait. Thus, the inclusion of thoughts and feelings (and potentially desires) imposes conditions on the construction process of personality state items and touches the issue of content validity.
Decomposition of States
What influences any given personality state? Decomposing a personality state score into different sources of variance allows a better interpretation of a personality state score and the derivation of concrete ideas on how to obtain reliability and validity evidence. For example, if the influences of different personality traits on the same score were consistent, this would mean that this score is not multi–determined. On the other hand, if the state score was highly influenced by momentary situational experiences, but consistently so, as well as by its corresponding personality trait, this would corroborate its interpretation as a valid state score. In Equation 1, we have highlighted different influences on personality states that could potentially be examined. Note that this equation only considers states (

Here,
To further explain the formula, we come back to the dancing behaviour from above. Dancing at a specific occasion
What is a State Measure?
Before going into details about the construction of personality state measures and the estimation of evidence supporting the reliability and validity of personality state scores, it is necessary to define what a (personality) state measure is:
As an example, one could think about the assessment of extraverted or conscientious behaviour. Note that there are instances of personality assessment that may not fall under this definition, such as the repeated assessment, say, every 6 months, of developing or changing traits. In other words, the assessment of
Current Practices
Before engaging in a broader discussion about the development of personality state measures, we sought to examine how personality states are currently used and reported in the literature. We therefore reviewed several major personality journals
1
and extracted all studies since 1990 that examined personality states. For each journal, we used the search string ‘(ESM OR Experience Sampling OR Daily Diary) AND (State* OR Behavior OR Trait Manifestation)’ and found
On the basis of feedback from an anonymous reviewer, we supplemented the initial search by the search term ‘EMA’ and ‘Ecological Momentary Assessment’. We identified 46 additional articles. These were coded by the first author. Six additional articles were included in the review.
Overview of personality state measures used in published literature since 1990
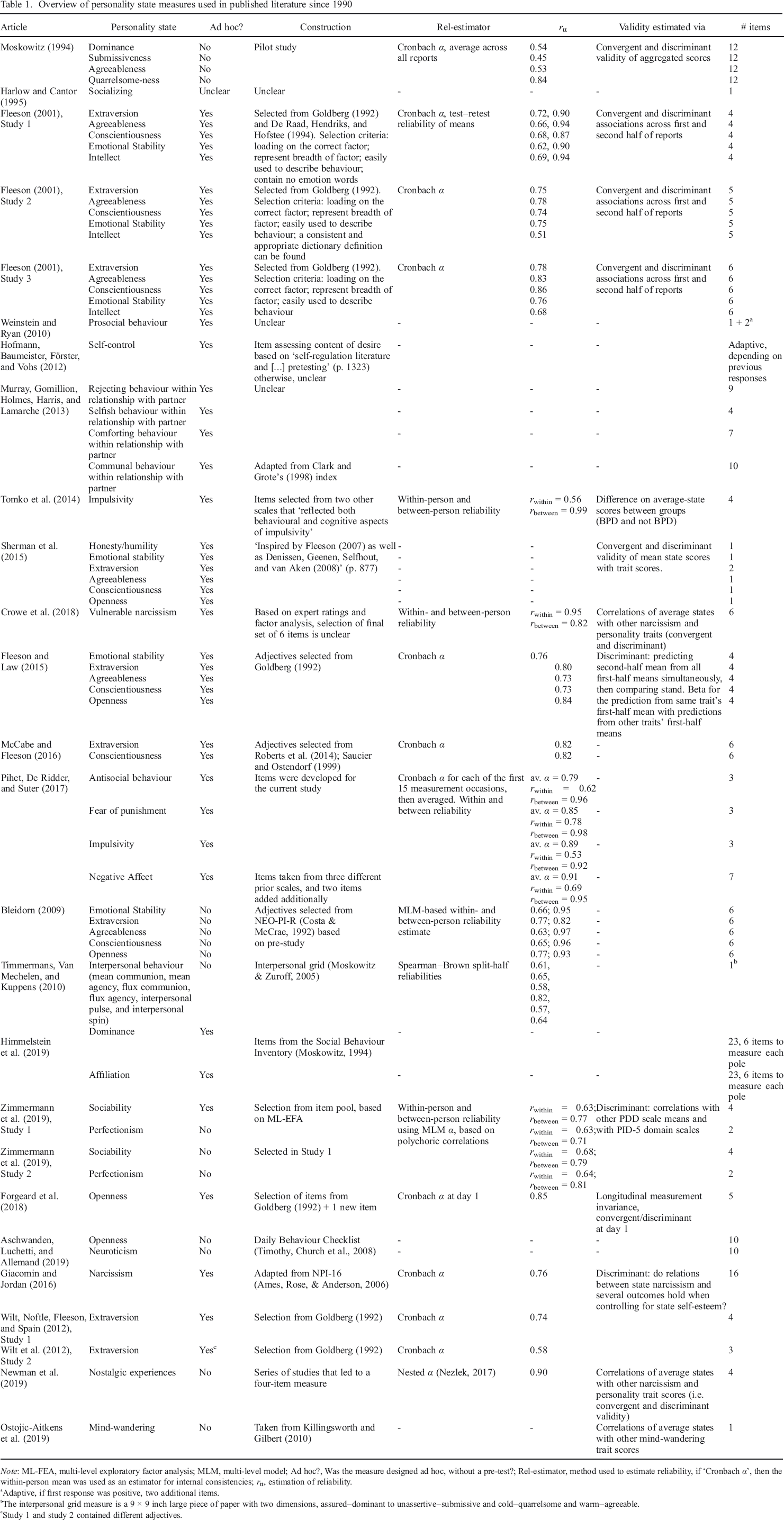
Adaptive, if first response was positive, two additional items.
The interpersonal grid measure is a 9 × 9 inch large piece of paper with two dimensions, assured–dominant to unassertive–submissive and cold–quarrelsome and warm–agreeable.
Study 1 and study 2 contained different adjectives.
As the results from our literature overview show, a large variability exists in the way measures for personality states have been developed, what scores were formed, and how evidence regarding the scores’ reliability and validity has been reported. Most strikingly, the most common way of establishing evidence for the validity and reliability of state score interpretations is by averaging state scores within participants and treating the so–resulting scores as person variables. Subsequently, internal consistencies are reported as estimates of reliability (Fleeson, 2001; McCabe & Fleeson, 2016; Moskowitz, 1994). However, this approach does not estimate the reliability of the state score but the reliability of the average–state score, and these two scores can represent entirely different constructs (Fisher, Medaglia, & Jeronimus, 2018; Hektner et al., 2007; Schönbrodt et al., submitted). A similar approach has been taken to showcase evidence supporting the validity of state scores. Some studies reported the correlation of average–state scores with one–time trait self–reports (Fleeson, 2001; Moskowitz, 1994; Sherman et al., 2015). However, as Hektner and colleagues pointed out, an aggregate of a person–level variable, assessed during experience sampling, must not necessarily measure the same as a one–time trait assessment of the ‘same’ construct (Hektner et al., 2007). In other words, a correlation or internal consistency of an aggregated state score must not necessarily represent an adequate estimate of the individual state score's validity or reliability.
Secondly, huge differences exist in how state measures have been developed. With few exceptions (Bleidorn, 2009; Himmelstein et al., 2019; Moskowitz, 1994; Newman, Sachs, Stone, & Schwarz, 2019; Ostojic–Aitkens, Brooker, & Miller, 2019; Zimmermann et al., 2019, Study 2), the state measures were not tested and validated in an independent sample, before the data collection of the substantive study. The most common way to developing state measures thus far seems to be to take items or adjectives that were used to assess personality traits and transform them into state measures (e.g. Horstmann et al., in revision; Ziegler, Schroeter, Lüdtke, & Roemer, 2018). Fleeson (2001), for example, described how he developed the measures on the basis of existing adjective lists that were used to describe personality traits (Goldberg, 1992). Specifically, he extracted items that (i) loaded on the correct factor (at trait level), (ii) represented the content of the factor, (iii) could be used to describe behaviour, and (iv) did not contain ‘emotion words’. This approach has indeed led to high cross–temporal stability of average–state scores (
Validity Evidence for State Scores and Validity Evidence for Average–State Scores
It has been noted several times throughout this article that validity of the average–state scores (i.e. evidence, that the interpretation of average–state scores is valid) does not imply validity of the individual, underlying state scores. Why is that? This problem has previously been described using different terminology, namely, ergodicity, ecological fallacy, or the Simpson paradox (Fisher, Medaglia, & Jeronimus, 2018). These terms simply relate to the problem that statistics obtained at group level (such as the distribution of trait scores or the variance of aggregate state scores) must not generalize to the level of the individual. For example, it may be possible that the assumed structure of constructs at trait level (between person) is different compared with the structure at the individual level (within person). Dejonckheere et al. (2018), for example, compared the structure of positive and negative affect. Whereas positive affect and negative affect are independent at the trait level, they are not independent at the state level (Bleidorn & Peters, 2011; Dejonckheere et al., 2018). Although people high on positive affect may similarly experience high levels of negative affect on average, positive affect and negative affect are negatively correlated at the individual level. This may of course also be true for personality traits and states, and thus, the between person structure must not correspond to the within–person level.
Alternative Scores Estimated on Experience Sampling Data
In the current article, we focus on the validity of individual state scores and average–state scores. Whereas an individual state score is the score
Purposes, Validity, and Reliability of State Measures
Before constructing or using any measure to assess personality states, it is important to ask which purpose the measure will serve (Moskowitz et al., 2009; Moskowitz & Russell, 2009; Ziegler, 2014). With respect to the assessment of personality states, at least two purposes come to mind: (i) the use of average–state scores as alternative measures of a person's trait level or (ii) the use of individual states as an assessment of a person's daily experiences. An overview of the different methods and possibilities for the examination of reliability and validity of personality state scores is presented in Table 2.
Recommendations for assessing validity and reliability of state measures
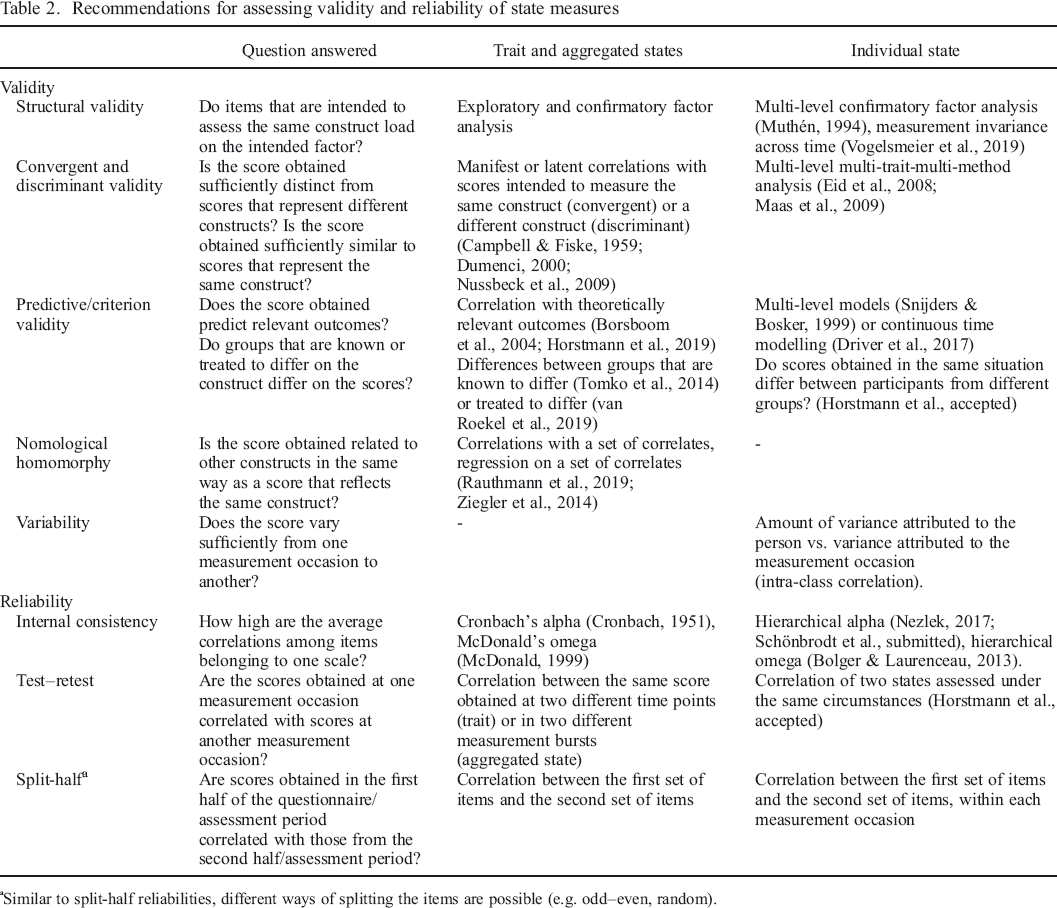
Similar to split–half reliabilities, different ways of splitting the items are possible (e.g. odd–even, random).
Average–State Scores
Purpose
First, personality states could be assessed to obtain a proxy for the corresponding personality trait. Based on whole trait theory, the average of personality states should correlate with the trait of this person (Fleeson, 2001; Fleeson & Jayawickreme, 2015; Jayawickreme, Zachry, & Fleeson, 2019). Examples of such research include the examination of incremental validity of average–state scores across self–reported personality trait scores to predict informant reports (Finnigan & Vazire, 2018; Vazire & Mehl, 2008) or affect (Augustine & Larsen, 2012).
In case the purpose of the measure is the assessment of stable personality characteristics, the validity of the obtained score depends mostly on (i) the breadth of the construct reflected in the state items and (b) the sampling procedure during the experience sampling phase. If, for example, the personality trait contains strong components of affect and behaviour (e.g. extraversion), the state items should reflect this content. This could mean that several items are assessed at each measurement occasion, or that items are sampled at random at each measurement occasion in a planned missingness design. Planned missingness designs can perform well in experience sampling studies, given a reasonable number of participants and measurement occasions (Silvia, Kwapil, Walsh, & Myin–Germeys, 2014). It is furthermore important to sample states throughout the day, across the whole week. If, for example, participants were only assessed in the morning during work hours, it could result in a bias of assessments at the individual level and, therefore, in a biased person–level estimate of the average personality state (Horstmann & Rauthmann, in preparation).
Validity Evidence
Evidence for the validity of aggregated state measures can be obtained similarly to the evidence that is obtained for self–reported or informant–reported personality traits (Table 2). First, structural validity can be obtained by averaging items across measurement occasions and fitting confirmatory factor models with items averaged across assessments, within persons, as indicators. 4 This model then indicates if the average response of the participants per item loads on the same latent factor. Second, further validity evidence can be obtained from multi–trait–multi–method analyses (Campbell & Fiske, 1959). The underlying idea is that correlations of scores obtained to represent the same construct (convergent correlations) should be higher compared with correlations of scores obtained to represent different constructs (discriminant validity). At the same time, correlations of scores obtained with similar methods can give an estimate of the method (co–)variance, if the underlying constructs of these scores are theoretically independent. Furthermore, it is possible to represent the multi–trait–multi–method matrix in a latent model, which allows comparing latent correlations (Campbell & Fiske, 1959; Dumenci, 2000; Nussbeck, Eid, Geiser, Courvoisier, & Lischetzke, 2009). This provides the direct advantage that all scores are estimated without measurement error, which directly corrects for attenuation of correlations (i.e. correction for reliability of obtained scores). Concerning personality states, one would expect, for example, that the average of personality state scores of one domain correlates at least with the corresponding personality trait as a convergent measure. Average extraverted behaviour should, for example, correlate the highest with self–reported or informant–reported trait extraversion. At the same time, one could expect that the correlations with scores obtained to represent other domains should be substantially lower. Currently, this approach to validating personality state scores is probably used most often, and the findings are generally as expected, that is, high convergent correlations and lower discriminant correlations (Horstmann & Rauthmann, in preparation).
Note that it is still an empirical question if ignoring the multi–level structure in experience sampling structure is tolerable. See Sengewald and Vetterlein (2015) for an empirical examination in the context of student evaluation.
Third, evidence for the validity of the score's interpretation can be obtained by examining the extent to which the score predicts theoretically meaningful and relevant outcomes (Borsboom, Mellenbergh, & van Heerden, 2004; Horstmann, Knaut, & Ziegler, 2019). For example, if the average–state score of extraversion correlates with the number of parties one has visited during the last months, this may be seen as evidence for the score's interpretation as an estimate of the person's extraversion. Note that the criterion must not necessarily be obtained at the same time as the average–state score. The average–state score is usually interpreted as a time–invariant characteristic of the person and therefore as stable (Fleeson, 2001; Jones et al., 2017). The average–state score should therefore be related to other person characteristics, regardless of the time of their assessment. However, this is of course only true if the period during which states are assessed is representative for the criterion focused.
Fourth, one can gather evidence for the average–state score's validity by examining its nomological network, specifically its nomological homomorphy with trait scores (Rauthmann et al., 2019). The idea is that trait scores are related to other correlates in their nomological net, and that if the average–state score and the trait score indeed reflect the same construct (Fleeson & Jayawickreme, 2015), the average–state score should be related to the nomological correlates in a similar way. The congruence of this relation then describes the nomological homomorphy of trait and average–state scores. Note that this is an extension to the examination of construct and criterion validity, as this approach employs regression models to examine the relation of average personality state scores to multiple correlates simultaneously. This approach is also similar to the suggestions for constructing personality short scales (Ziegler et al., 2014).
Finally, average–state measures should also capture differences in average daily experiences between saliently different groups. First, it is possible to manipulate states between groups. Using experience sampling in an experimental design where one group receives treatment to change behaviour and the other does not should be reflected in the average level of behaviour difference between groups, all else being equal (Hudson, Briley, Chopik, & Derringer, 2018; van Roekel, Heininga, Vrijen, Snippe, & Oldehinkel, 2019). Average–state scores should thus be sensitive to manipulations that target an individual's average experience. Second, it is also possible to examine groups that differ in their known levels of personality states and examine if the measure reflects upon these known differences (Tomko et al., 2014).
Reliability
There are many ways to examine an average–state score's reliability each with advantages and disadvantages. Once the items at state level have been averaged within persons, across measurement occasions, they could technically be treated similarly to items from trait questionnaires. First, it is possible to examine the internal consistency of these scales. Note that averaging items across measurement occasions will lead to indicators that are much more unidimensional, as the unique, occasion–specific variance will be minimized, and the application of Cronbach's alpha as an estimator of the internal consistency of the average–state scale is much more appropriate (Cronbach, 1951; Nezlek, 2017). However, a more suitable measure of internal consistency would be McDonald's Omega (McDonald, 1999). In both cases, the underlying assumption is, however, that a latent variable is assessed. If the average–state score is assumed to reflect the personality trait of the person, then this may be appropriate. However, if the purpose of the reliability estimation were to gauge the amount of reliable variance traceable to the specific trait, this procedure would be inappropriate because the state score could be multidimensional as highlighted above. Additionally, if one–item indicators are used, as it is regularly the case (Horstmann et al., in revision; Sherman et al., 2015), an estimation of internal consistency of the aggregate state scores is not possible.
Alternatively, and especially suited for one–item state measures, one can estimate the stability of the average–state score across several measurement occasions (Moskowitz et al., 2009). Correlating the average measurement of the first half of the experience sampling phase with that from the second half of the experience sampling phase yields an estimator of the average scores test–retest reliability. 5 Note, however, that this procedure confounds the stability of the aggregate state score with the reliability of the aggregate state score (which is a common problem when estimating test–retest correlations). The estimation of the reliability via the score's stability will therefore result in lower and more conservative estimates.
Instead of splitting first with second half of t the states, one can also split (i) at random, (ii) by every other measurement occasion (e.g. ‘odd–even’), (iii) by time of assessment (e.g. divide split by every third hour) or theoretically guided (e.g. split by weekdays vs. weekends).
Individual State Scores
Purpose
If, however, state scores are obtained to examine within–person processes, state measures should be able to validly capture the daily experiences of a person. In other words, it is important to examine ‘whether explanations other than the participants’ natural experience could account for their [participants'] […] responses’ during experience sampling (Hektner et al., 2007). Individual state scores can, for example, be used to get a picture of a patient's everyday life or about within–person effects of situations on behaviour or vice versa.
Validity Evidence
To test these assumptions, one can first examine the structural validity of the state items. For state items, one can do this using multi–level confirmatory factor analysis (ML–CFA). ML–CFA simultaneously considers the within–person and between–person structure and allows testing a model that considers between–person and within–person variance at the same time (Muthén, 1994). Second, if more than one construct is assessed during the experience sampling phase, preferably with multiple methods, multi–level multi–method analysis (Maas, Lensvelt–Mulders, & Hox, 2009) allows examining discriminant and convergent validity of the state scores. For example, Bleidorn and Peters (2011) showed that positive affect and negative affect are unrelated at the between level but correlated at the within–person level. Concerning state measures, one could, for example, investigate if the structure of personality (e.g. uncorrelated domain scores) also holds within person or if, as suggested, different tendencies to behave and thus actions (i.e. personality states) inhibit each other (Revelle & Condon, 2015), which must necessarily mean that personality states at the within–person level could not be independent from each other.
Recently, Vogelsmeier, Vermunt, van Roekel, and De Roover (2019) suggested latent Markov (exploratory) factor analysis (LMEFA) to examine the within–person structure of psychological constructs. Specifically, they suggested that the structure of measurement models may change across time and between individuals. For example, it could be assumed that the Big Five personality states are usually represented by five independent domains. Yet it could be possible that, under certain circumstances, for example, stress, the structure of the measurement models for the corresponding Big Five states changed. Under those circumstances, it would no longer be possible to compare means or covariances of individual states across time. LMEFA allows exploring the structure of measurement models across time, within models, and identifying occasions at which measurement models are invariant and state scores are thus comparable. This approach therefore addresses the challenges of state assessment in a very sophisticated manner. At the same time, software for the implementation of such models is not yet openly available, and an implementation of this approach in open source software is needed.
Third, personality state scores should be related to specific, theoretically plausible outcomes at state level, even after controlling for potentially overlapping, other constructs. State scores and correlates can be assessed prior to the state, at the same time as the state, or after the state. Depending on the research question at hand and the structure of the data, these associations can, for example, be examined using multi–level regression models (Snijders & Bosker, 1999), or in case of outcomes that are assessed at a different time, continuous time models (Driver, Oud, & Voelkle, 2017; Voelkle, Oud, Davidov, & Schmidt, 2012). These analyses should reveal that (i) state scores can be used to predict theoretically plausible outcomes, (ii) that the state scores are linked to only these outcomes and not to all outcomes that were assessed at state level, and (iii) that these links remain substantial, even after controlling for potential covariates.
Recently, Sun and Vazire (2019) presented evidence for the validity of momentary state scores by means of structural equation modelling. Coming back to the claim that a state score is valid if it covers the momentary experiences of a participant, Sun and Vazire examined the convergence of self–reported personality states and informant–reported personality states. The informant reports were obtained by having coders rate audio snippets recorded during participants’ daily lives, which were matched to the momentary self–reports. Thus, it was possible to examine the extent to which self–reported personality states were congruent with participants’ momentary experiences. Although this is probably the most sophisticated way to examine the validity of personality state scores, Sun and Vazire's study shows how taxing such an undertaking can be. Additionally, it has to be noted that the validation of a measure and its use for answering a substantial research question should, technically, be separated. However, given the complexity of required study designs in ESM studies, it is understandable that this is very rarely the case.
Finally, state scores should show reasonable fluctuation from one measurement occasion to another to justify the examination of within–person processes (Ilies et al., 2007; Sherman et al., 2015). Variance of state measures should be attributable not only to the person but also to the measurement occasion or situation. This ratio of variance is usually expressed as an intra–class correlation (ICC; Bliese, 1998). If the ICC of state scores was near one, this would mean that all variances could be attributed to the person and that the measure was not sensitive to situational changes (or that no situational changes occurred, of course). On the other hand, if the ICC were near zero, this would mean that close to all variances had to be attributed to the situation or measurement occasion. However, if personality states are understood as the manifestation of stable personality traits, this would be counterintuitive and in opposition to the theoretical assumptions. Note, however, that the proportion of within–person variance, and thus the ICC, does depend not only on the construct that is examined but also on methodological considerations and study design (Podsakoff, Spoelma, Chawla, & Gabriel, 2019). ICCs for state measures can be expected to be between 0.20 and 0.50 (Horstmann et al., in revision; Podsakoff et al., 2019; Sherman et al., 2015; Sun & Vazire, 2019).
Reliability
Reliability refers to the precision with which a certain score is obtained and can be estimated using either internal consistency or test–retest correlations. For test–retest correlations, this means that if a score was to be assessed with perfect reliability, it would follow that the next time the score is assessed under the exact same circumstances, the same result would have to be obtained,
First, one could aim to estimate a test–retest reliability of state scores. The estimation of test–retest reliability is essentially a question of consistency. Fleeson and Noftle (2008) alert us to the fact that consistency of behaviour can be estimated across many different components, though. Although Fleeson and Noftle suggested a total of 36 different forms of consistency (different enactments: single, aggregate, contingent, and patterned, which were crossed with different definitions of similarity: absolute, relative, and ipsative, which were crossed with different competing determinants: time, situations, or behavioural content), test–retest reliability of state scores would be the examination of
A second way to estimate reliability would be to treat each measurement occasion (or other unit in which several measurements occurred) as a separate study (Nezlek, 2017). In case of one–item measures, one could, for example, treat days or hours as separate studies (i.e. all assessments from Monday are assumed to be from one study, assessing the same construct). For each ‘study’, one can then estimate the reliability and finally aggregate all reliability estimates (Nezlek, 2017; O'Brien, 1990).
A third possibility to estimate the reliability of state scores is to assess the internal consistency of scales, while simultaneously modelling the nested structure of the data (Nezlek, 2017). To obtain an estimate of item–level reliability, a three–level model must be specified, with items nested in measurement occasions (e.g. days and time intervals), nested in persons. The item–level reliability is then defined as the occasion level variance divided by the occasion level variance plus the item–level variance (Nezlek, 2017, p. 152).
6
If all persons responded differently across occasions, but in the same way to all items
Code for running these analyses can be found in the OSM of Nezlek (2017) for the program HLM or at https://github.com/kthorstmann/horst/blob/master/R/nestedAlpha.R for the program R.
To summarize, it is possible to estimate within–person–level estimates of reliability, similar to test–retest reliability or internal consistency. However, as our literature overview has indicated (Table 1), this is very rare in the current published literature. We therefore recommend publishing these estimates along with descriptive statistics of the scales. At the same time, it is currently (to our knowledge) unknown which effects the reliability of state scores has on the estimation of effects at the between and within levels. For person–level scores, for example, it is long known how the increase of the score's reliability would lead to an increase in its correlation with another score (Spearman, 1904, 1910). Although the same logic clearly applies to within–person estimates, the power to detect effects that are typically examined in an experience sampling study (e.g. fixed effects, random effects, and cross–level interactions) depends on much more than just the reliability of the level 1 score (e.g. the sample size at different levels, the reliability of the level 2 predictors, and the ICC; Bliese, 1998; Mathieu, Aguinis, Culpepper, & Chen, 2012). It is thus still an open question which level of reliability suffices to examine which effects in experience sampling studies, contingent on other study details.
The Abc of Test Construction for Personality States
Before engaging in the construction of any psychometric measure, there are at least three different questions that should be answered (Ziegler, 2014): First, what is the construct being measured? Second, what is the intended purpose of the measure? And third, what is the targeted population? Answering these questions, both during the construction of any measure and also during their application, can help with the interpretation of the results.
What is the Construct Being Measured
If constructing state measures, the first question that should be answered is ‘what is the construct being measured?’ Although this can at times seem straightforward and possible answers may be something like ‘personality state of conscientiousness’, one should explicitly look at the specific definition of the personality trait (that is expressed). Here, well fleshed–out definitions of personality traits can provide the first and most useful source of information. These definitions should provide descriptions of the personality trait manifestations (i.e. personality states).
Second, the items that are then selected for the state measure should be (i) linked as well as possible to only one facet or trait and (ii) applicable to most situations that participants could encounter during their lives. This can, for example, be answered by asking participants how they did understand or interpret individual questions or by employing think–aloud–techniques (Ziegler, Kemper, & Lenzner, 2015). Note that items that are developed
What is the Intended Purpose of the Measure?
Similar to the previous point, the purpose of the measure should clearly be considered. Many different purposes come to mind. First, the measure could be put to use in a purely scientific context, that is, for the examination and testing of personality theories, such as hypotheses derived from whole trait theory (Fleeson & Jayawickreme, 2015; Jayawickreme et al., 2019) or the TESSERA framework (Wrzus & Roberts, 2017). In these cases, personality state measures must be
The TESSERA framework, for example, suggests that certain expectations in a situation will lead to trait manifestations. If, for example, this hypothesis was to be tested in an experience sampling study, both the expectations and the states had to be assessed. A test of this hypothesis would only be possible if those two entities (expectations and states) were not correlated ‘by default’, for example, due to common method variance. As Bäckström, Björklund, and Larsson (2009) reported, formulating items in trait measures more neutrally (e.g. ‘I swim regularly’ vs. ‘I love swimming’) reduces their interrelatedness, or their common method variance (Bäckström & Björklund, 2013). Similarly, items that are developed for testing specific hypotheses about state–state relations must have sufficient discriminant validity. Otherwise, findings that, upon first sight, corroborate such theories as whole trait theory could turn out to be of lesser value than initially hoped (Horstmann et al., in revision). As a consequence, for providing reliability and validity evidence, the decomposition of variance is again vital [Equation 1]. Moreover, it is also important to gauge discriminant validity evidence while paying attention to such potential overlaps. Thus, statistical models need not only be able to decompose the variance sources within states for one trait but also to relate those variance sources to each other.
Second, state measures could be used to test the effectiveness of interventions in clinical studies (Magidson, Roberts, Collado–Rodriguez, & Lejuez, 2014; van Roekel et al., 2019). State measures should be sensitive to changes in the targeted variable. For example, Horstmann and colleagues (under review) assessed how consistent participants would behave in hypothetical, dissimilar situations. However, the authors used an altered version of the Big Five Aspect Scale (DeYoung, Quilty, & Peterson, 2007) to test mean changes in personality states. It could be argued that the Big Five Aspect Scale items are not sensitive to momentary changes in behaviour and are therefore unsuitable to capture changes owing to interventions at the state level. This means that state items intended to capture change must reach strong internal consistencies within each situation. Consequently, the statistical modelling approach must be able to decompose variance sources for each state measure occasion and relate those estimates across occasions within persons.
To summarize, when paying attention to the rather abstract purpose question while constructing a personality state measure, two specific questions have to be answered: ‘What is the goal of this study?’ And, ‘Is the measure able to provide sufficient evidence to achieve this goal?’ Future experience sampling studies can rely on previous measures that have been successful in providing answers to substantive questions (Table 1). For example, if the scores obtained with a specific measure clearly fit into a specific theory (e.g. the correlations were as expected), then it could be a valid strategy to use the existing tool instead of constructing a new one—especially if resources are scarce. However, the question whether a measure has indeed been successful has to be evaluated using many different criteria, which we aim to develop in the current paper. Alternatively, if no previous measure exists, one needs to construct a new one.
What is the Targeted Population?
Different from the use of most trait measures, state measures always target two populations: (i) the population of the participants and (ii) the population of situations in which participants are observed (Horstmann, Rauthmann, & Sherman, 2018; Horstmann, Ziegler, & Ziegler, 2018; Ziegler, Horstmann, & Ziegler, 2019).
Considering the population of participants is extremely relevant for the formulation of state items and their applicability to the participants’ daily experiences. For example, experience sampling studies that target very young or older participants (e.g. Quintus, Egloff, & Wrzus, n.d.) must consider that their daily experiences are different from the average daily experience of college students. So far, only very few studies have targeted personality states in older participants, and evidence for the applicability of personality state measures in these populations is therefore scarce. Although elderly participants have been assessed during experience sampling (e.g. Carstensen et al., 2011; Drewelies et al., 2018; Hülür et al., 2016), none of the published studies have examined personality states (defined as the manifestation of personality traits) in particular. Similarly, item difficulty needs to be adjusted for different populations. One can easily see that an item that has been used for the assessment of neuroticism states ‘During the last hour, how worried were you?’ (Finnigan & Vazire, 2018; Sun & Vazire, 2019) will result in very low scores in a healthy, young population. If the same item was used in a clinical sample, this might be very different. Items with extreme item difficulties can potentially lead to attenuated correlations owing to restricted variance (Sim & Rasiah, 2006) and can make it therefore harder to test hypotheses at the within–person level.
Second, the item content also depends on the targeted population of situations. Consider a regular college student, who is asked ‘if, in the last 30 minutes, they talked to strangers’. If this student's life is assessed under normal circumstances, this item will most likely show some variance. If, on the other hand, the experience sampling phase falls into the exam period, the student may not be speaking to strangers as much. Of course, the very reason for examining how much someone spent time talking to strangers is to find out if they do it at all; in other words, it might not always be possible to know in advance which period or population of situations will be targeted. However, in some cases, it is clear that circumstances will be somewhat special (e.g. around Christmas and during holidays or exam periods). As a remedy, one can offer participants the option to indicate when they would like to participate (Roemer, Horstmann, & Ziegler, n.d.).
Practical Recommendations and Example: An Item Pool for Conscientiousness
Throughout the article, we have highlighted some major theoretical differences between the construction of trait versus state measures. However, these can sometimes be abstract and hard to grasp when they are put to practice. Specifically, it can be difficult to generate an initial set of items to assess states in a systematic way. In this section, we will therefore aim to give practical recommendations for the development of state measures, focusing explicitly on those aspects that are substantially different from the construction of trait measures. We will exemplify this process by developing an initial item pool for conscientiousness states.
For the development of a state measure, one needs to first generate the item content that should be captured with the measure. Moving on, one has to develop potential items. Then the appropriate instructions need to be selected, items need to be finalized, and an appropriate response format has to be selected. Here, we will exemplify how one can go through these stages, especially focusing on the generation of items and the item content. Initially, the generation of item content and the items should only be guided by theoretical principles and not hindered by practical considerations. This means that, at first, an extensive list of potential items should be created. These are then later pruned to a practically manageable size. However, the practical considerations should be ignored at first to come up with the most appropriate measure of the state at hand.
Abc: State Measure of Conscientiousness
What is the Construct Being Measured?
Conscientiousness at trait level is a very well–researched construct at the between–person level (Bogg & Roberts, 2004; Roberts, Chernyshenko, Stark, & Goldberg, 2005; Roberts, Jackson, Edmonds, & Meints, 2009; Roberts, Lejuez, Krueger, Richards, & Hill, 2014; Soto, 2019; Watson, 2001) and also at the within–person level (Chapman & Goldberg, 2017; Church, Katigbak, Miramontes, del Prado, & Cabrera, 2007; Hudson et al., 2018; Hudson & Fraley, 2015; Jackson et al., 2010; Magidson et al., 2014). It is therefore not surprising to find many slightly varying definitions of the construct in the published literature. Roberts et al. (2014) defined conscientiousness as the ‘propensity to be self–controlled, responsible to others, hardworking, orderly, and rule abiding’ (p. 1315). This shows, on the one hand, the many different states that may be seen as manifestations of conscientiousness (i.e. self–controlled, responsible, hardworking, and rule abiding). On the other hand, this alerts us to the breadth of the construct, and the fact that it may therefore not be possible to assess conscientiousness at state level with only one or two items.
What is the Intended Use of the Measure?
The state measure for conscientiousness that we envision here is meant to be used for the assessment of conscientiousness states (as opposed to a conscientiousness trait that is based on averaged conscientiousness traits). The measure should furthermore be used by participants several times per day to indicate their momentary levels of conscientiousness states. This means that the state measure must be applicable to a variety of states in different situations as well as a range of conscientiousness states, depending on the targeted population of persons who enact conscientiousness states, and the anticipated situations in which conscientiousness states are enacted.
What is the Targeted Population?
As argued before, the targeted population of (i) persons and (ii) situations informs the item format, the item content, and the item difficulties. For this conscientiousness state measure, meant for research, we would primarily target students. Fortunately (and, yes, we deliberately chose a comparatively simple case), a lot is known about students’ everyday lives. First, most scholars have once been students themselves and have an intuitive understanding of students’ lives. Second, there is some research that has examined personality states or manifest behaviours of either the general population (Chapman & Goldberg, 2017) or student populations (Harari et al., 2017; Stachl et al., 2017). This means that it is possible to build on the available literature to get an understanding of participants’ lives, which can inform the relevant content of the items.
Defining the Item Content and Designing the Items
After the construct, the intended use of the obtained scores, and the targeted populations are defined, it is first necessary to generate item content that reflects the intended personality states. Generally speaking, this means that—ideally—a very long list of trait manifestations of conscientiousness should be assembled. In a second step, this content will then be transformed into items.
Item Content
The search for item content generally benefits from an ever–growing nomological net. In some cases, as it is the case with conscientiousness, the nomological net is already very well established (e.g. Roberts et al., 2005, 2009). When organizing the literature and thinking about the enactments of conscientiousness, it is helpful to think in terms of
On the basis of existing literature, we collected a number of possible antecedents, correlates, and consequences of the targeted trait conscientiousness (Table 3). For example, Hudson et al. (2018) showed that completing certain weekly challenges can lead to higher conscientiousness in participants. These challenges are then an antecedent of conscientiousness, and the enactment of pursuing the challenge can be considered a conscientiousness state. Enacting this state over and over again then leads to higher conscientiousness. Similarly, Church, Katigbak, Miramontes, del Prado, and Cabrera (2007) listed correlates of conscientiousness, such as getting a good grade. Here, getting the grade itself (e.g. the moment one sees the grade) clearly has nothing to do with conscientiousness, but some intermediate process, such as learning for the exam, could have led to the good grade. Finally, there are consequences of conscientiousness. Bogg and Roberts (2004), for example, show that persons who score high on conscientiousness drink less alcohol than do low–scoring persons. Note that Bogg and Roberts explicitly assume that drinking less is a consequence of conscientiousness, although the effect might also occur in the opposite direction (i.e. drinking over an extended period of time leads to lower conscientiousness after a while).
Item content and items for a potential scale to assess state conscientiousness
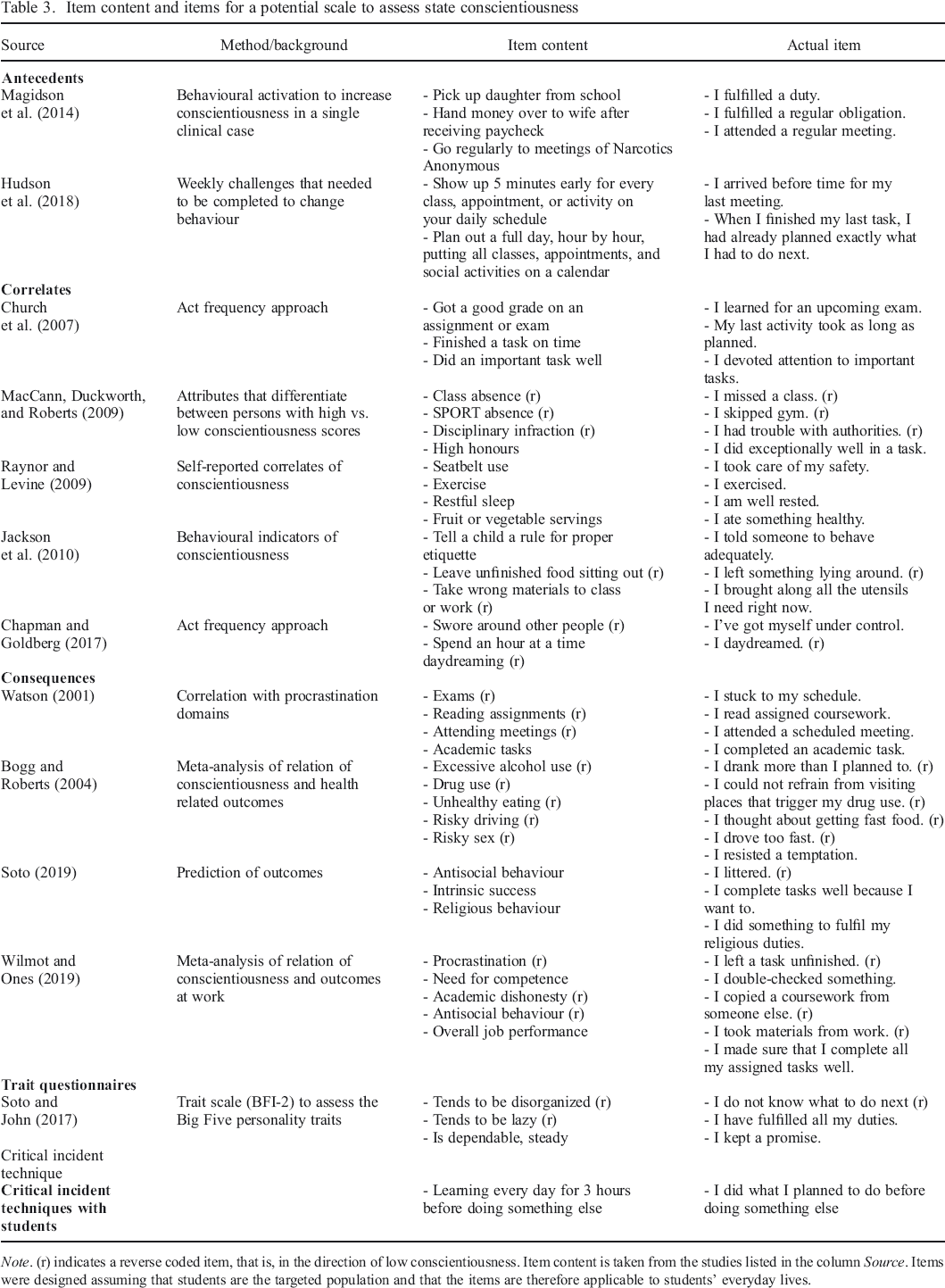
Abcds
With respect to conscientiousness, most states have a behavioural content. This is very similar to what Wilt and Revelle (2015) observed in their analysis of Big Five trait items. Nevertheless, Chapman and Goldberg (2017) also reported that participants who scored high on conscientiousness spent less time daydreaming. Not daydreaming can therefore be seen as one of the rare cognitive components of conscientiousness. Similarly, the item ‘I complete tasks well because I want to’ can be seen as a desire rather than a behaviour. These items, if correctly identified, can broaden the representation of the construct.
Additional Ways to Generate Item Content
It may not always be possible to rely on such a well–developed nomological net as we did here. In such cases, it may be more difficult to come up with a list of potential item contents. To overcome this problem, one may of course first develop such a nomological net and conduct studies that are similar to those listed in Table 3 (especially studies that resemble Hudson et al., 2018; Jackson et al., 2010; or Magidson et al., 2014, as these have provided much detailed information about what conscientious people do). Alternatively, one may be inspired by items from already published trait questionnaires.
Item Content from Trait Questionnaires
Another source of inspiration for item content for state measures is the trait measures of the corresponding trait. For example, the BFI–2 (Soto & John, 2017) contains items such as ‘Tends to be disorganized’ (reverse coded), ‘Tends to be lazy’ (reverse coded), or ‘Is dependable, steady’ (Soto & John, 2017, p. 142). Being organized, not lazy, or dependable is therefore seen as qualities of the conscientious person. This approach may of course be supplemented with items from other sources, especially if the items are freely available (i.e. non–proprietary), as in the International Personality Item Pool (IPIP, 2015), or the Synthetic Aperture Personality Assessment project (Condon, 2018; Condon & Revelle, 2015; Condon, Roney, & Revelle, 2017).
Critical Incident Technique
The critical incident technique is described as a ‘procedure for gathering certain important facts concerning behavior in defined situations’ (Flanagan, 1954, p. 9). Although initially designed to define behaviours that were critical for either the failure or the success of a person in a specific situation, this technique can be used to generate descriptions of personality states. For example, to obtain descriptions of the personality state conscientiousness, an interviewer can ask the interviewee (who should, at best, be a member of the population that is later assessed, in this case, a student) to think about typical situations in their everyday life. It is important that the situation is appropriate for the personality state. Appropriateness means that the trait can be manifested in this situation; that is, the situation must be relevant to the expression of the trait (Tett & Burnett, 2003; Tett & Guterman, 2000). The appropriateness must be assessed by the interviewer, who therefore needs to be an expert on the construct. Again, the nomological net, especially the assumed consequences of the corresponding personality trait, can be helpful in guiding this decision. If, for example, highly conscientious persons are more successful in their job than are less conscientious persons, what exactly was a critical situation at work that might have led to success or failure? For example, a student could suggest a situation such as ‘studying for an exam’. One can now proceed and ask the student about behaviours, thoughts, feelings, and so forth that they experienced that have led to success in this situation. Note that at this stage, the interviewee may name a number of different states that may or may not be classified as manifestations of conscientiousness, such as ‘was open to suggestions on how to improve learning’, ‘learning every day for 3 hours before doing something else’, ‘partying less during exam period’, ‘saying no to invitations from others’, or ‘did not worry about missing out on positive experiences’. Although all of these are manifestations of the Big Five personality traits (i.e. openness to experience, conscientiousness, extraversion, agreeableness, and neuroticism), only the second one can be classified as a manifestation of conscientiousness.
Item Wording
When choosing a wording for the items, one should always keep in mind the responses to the questions ‘what is the targeted population?’ and ‘what is the intended use of the measure?’ The actual items are developed based on the extracted item content. Sometimes, this is very straightforward, as the item wording is very similar to its content. For example, the correlate ‘exercise’ can be transformed into an item such as ‘I exercised’. Other content, which is very specific, has to be made broader in order to apply to several different occasions. For example, the content ‘hand over money to wife after receiving paycheck’ is too specific to apply to many occasions, as a paycheck is only obtained once a week or once a month. This content may be transformed into a more general item such as ‘I fulfilled a regular obligation’. Finally, some content may be so abstract that it does not reflect a state and must therefore be made more specific. For example, the content ‘antisocial behaviour’ could be transformed into an item such as ‘I littered’ or ‘I've done something inappropriate’. These items would then be more applicable to a broad range of participants and daily situations.
When developing items based on content from previously published trait scales, one has to keep in mind that the content is typically rather broad (e.g. being disorganized, lazy or dependable, see Table 3). These comparatively general qualities will then also have to be ‘translated’ into more specific behaviours, thoughts, or feelings that could have occurred in several occasions. Being disorganized, for example, would mean, among other things, ‘not knowing what to do next’. This would then be applicable to nearly all potential measurement occasions in daily life.
The item content obtained during the critical incident technique can be transformed to state items in a very similar way. Similar to other content, ‘I learned for about three hours before I did something else’ might be much too specific. Integrating this statement with statements from the same person as well as other interviewees can however result in general principles such as ‘I did what I planned to do before doing something else’, or ‘I have stuck to my plans’, or even more specific with respect to the reference period ‘Right now, I am sticking to my plans’.
Items, Scales, and Instructions
Not only is it necessary to define the wording of the items, but it is also necessary to adhere to general principles of item design, choosing the most adequate rating scale, and to choose the correct instructions.
Item Design
Throughout the history of psychology, much has been said about the way items in questionnaires should be designed (e.g. Krosnick & Presser, 2010). For example, items should be written in simple syntax, using familiar words, and the wording should be specific and concrete as opposed to general and abstract. Here it is assumed, however, that the respondent will most likely only take the survey once or, if more than once, with some longer time interval in between assessments, and that a general characteristic of the person is being assessed, such as their personality traits. Both do not apply to the assessment of personality states. The first consequence is that the time to which the item refers (e.g. ‘within the last hour’, ‘just now’, ‘today’, and ‘recently’) should not refer to a period that is longer than the time between two adjacent measurement occasions. Empirical evidence that can inform this decision more concretely is, to our knowledge, not available, though.
Secondly, a state item does not asses general and time–invariant characteristics of the person, but a momentary state. This is reflected in the level of hierarchy of the construct that it refers to. Therefore, the content to which it relates should be reasonably concrete but, at the same time, applicable to as many assessment situations as possible. On the one hand, items can be worded such that they are broadly applicable in everyday life. At the broadest level, such an item could be ‘I behaved conscientiously’ or a little less broad ‘I did what I planned to do’. Note that these items, although very broad in their description, already focus solely on the behavioural aspect of conscientiousness (i.e. ‘behaved’ and ‘did’), and not on any other aspect, such as thoughts (e.g. the planning itself) or possibly related feelings (e.g. the satisfaction when having followed through with ones plans). On the other hand, items can be worded very narrowly, such as ‘I checked my manuscript for spelling errors’. This very specific behaviour is, however, so concrete that it may not readily apply to all possible situations, and certainly only to a very specific population (i.e. those who write their own manuscripts).
Items can now be crafted in line with these two dimensions: reference period and breadth of construct. The reference period can be very short (i.e. ‘just now’) or indefinitely long (e.g. ‘in the last year’, ‘in general’). For state items, one should aim for a very short interval. How low one can go, is, however also determined by the item content. Some states may simply not occur that often and asking the participant whether this state was recently manifested may not be applicable. Concerning the breadths of the construct, one should aim to formulate items such that they can be as specific as possible. Again, the content may limit the specificity of the item, depending on the targeted population of persons and situations.
Note that if an event–contingent plan is used, the reference period as well as the content of the items can of course be much shorter and more specific. If, for example, a signal to participate is triggered whenever a person writes on their manuscript, the reference period can be very short, as the item refers to exactly this particular moment (e.g. the item ‘I am checking my spelling’ will always be applicable if the event ‘writing a manuscript’ has triggered the signal—we just know that the person was writing right now). Similarly, the content can be much more specific (e.g. ‘I was revising what I wrote yesterday’ vs. ‘I was writing’), as it is already known that the person was writing a manuscript.
Generally speaking, items can be written to combine any reference period with any breadth of item content. The decision should be informed by the anticipated precision with which items
Number of Response Options
A number of research articles have examined the effect of the response format of an item on basic psychometric properties of the item and the resulting scale score (e.g. Lee & Paek, 2014; Simms, Zelazny, Williams, & Bernstein, 2019). However, with respect to state measures, such research is practically non–existent (Wright & Zimmermann, 2019). On the one hand, the offered response options should allow a differentiation between a range of state levels. Similar to trait measures, offering between five to eight response options seems reasonable. On the other hand, providing too many response options may confuse participants and lead to longer response rates or additional measurement error. Another factor that may only be relevant for state items is the available screen width of the device that is used during data collection (usually a smartphone). If the screen is narrow, having too many response options may result in each response option being also displayed narrow, which again could result in wrongly selected responses. Similarly, a narrow screen may not allow naming each response option, and a label may only be given to the endpoints and potentially the mid–point of the scale. Alternatively, one can choose sliders for collecting responses from participants. However, these sliders have a particular drawback, namely, that in most cases, a certain response is pre–selected (i.e. the slider has to start somewhere). Whether or not any of the decisions made with respect to answer format affect the psychometric properties of items remains, ultimately, an empirical question yet to be examined.
Instructions
In an experience sampling study, there are two instructions that can, but do not have to be, the same. First, at the initial assessment, participants may be informed on how to respond to the questionnaire and receive detailed instructions. Second, during the experience sampling, participants should receive a short instruction on how to respond to each item. Here, it should be pointed out which aspects of the states the items refer to (e.g. thoughts, feelings, and behaviour) and to which reference period (unless these elements are present in the items themselves). The instructions, especially those during the experience sampling, should be kept reasonably brief to avoid unnecessary participant burden.
Further Steps
After the initial item pool has been constructed, the items will have to be presented to members of the targeted population. Note that for an initial test of this item pool, it may not be required to do this in a full–experience sampling study but can also be achieved by asking participants to rate only their current situation once, by means of experimental manipulation of a situation, and so on (Table 2). After the first sample of respondents has been collected, the item statistics, intercorrelations, and estimates of validity and reliability have to be computed. Although the technique may be different compared with trait measures, the principles are comparatively similar, as laid out before.
Conclusion and Outlook
Taking a look back at the rapid development of the experience sampling method, from booklets being handed out to participants, answers being recorded with SMS, to palm–held computers and finally to smartphones that are now readily available, it is clear that data obtained from experience sampling will become more and more important for (personality) psychologists. Additionally, newer methods such as life logging (e.g. Brown, Blake, & Sherman, 2017) or the electronically activated recorder (Mehl, Pennebaker, Crow, Dabbs, & Price, 2001; Sun & Vazire, 2019) further extend the psychologists’ toolbox and provide us with a very powerful repertoire to examine personality dynamics. Although research on experience sampling methods and psychometric evaluation of data obtained in experience sampling has come a long way, many challenges remain. We argue that is important to accept that personality state scores are multidimensional. If this idea is accepted, it will help in guiding the interpretation of scores and results obtained using experience sampling.
Next, it is important, as indicated above, to develop quality guidelines for the examination of personality state measures. Not all psychometric evidence reported for a specific measure is useful, and not all evidence is required, providing exactly the evidence that the purpose of the measure requires should be the goal of each test construction (Ziegler, 2014). We assume that our first overview of current practices, options, and methods will be somewhat outdated in a few years, but we look forward to the broad application of methods that only very few are currently thinking (or, via Twitter, heavily arguing) about.
Psychologists have learned a great deal during the development of theories such as the Big Five and the herein embedded development of trait measures. As a consequence, agreed–upon guidelines exist, and methods for the construction and evaluation of trait questionnaires are (hopefully) included in every undergraduate curriculum. This also means that we have the chance to avoid making the same mistakes that were made during the construction of trait measures. As one of the most outstanding practices, alpha maximization comes to mind (N. Schmitt, 1996). This describes the poor practice of selecting items for a questionnaire such that its internal consistency is maximized often at the cost of heterogeneity and content validity.
Finally, many open questions, mostly of methodological nature, remain unanswered. Given the importance of data from experience sampling for the examination of recent personality theories, we hope that these questions, some of which are listed in this paper, will spur new research. Data on personality states are already widely available and only waits to be analysed. Similar to the beginning of trait research when factor analytical methods were developed to explore personality structure, we may now hope for a new era of method development fostering the examination of dynamic personality.
Acknowledgements
We thank our three student assistants, Lilly Buck, Maximilian Ernst, and Aaron Peikert, for their help with the literature review. We also thank Clemens Stachl for helpful suggestions.